Dual-Learning based Penalized Multi-Align Clustering for Multi-View Incomplete and Disorderly Data
Pith reviewed 2026-06-29 05:12 UTC · model grok-4.3
The pith
DLPMAC uses dual learning of modality priors and a penalized multi-align module to achieve sample-level pairing in incomplete multimodal data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
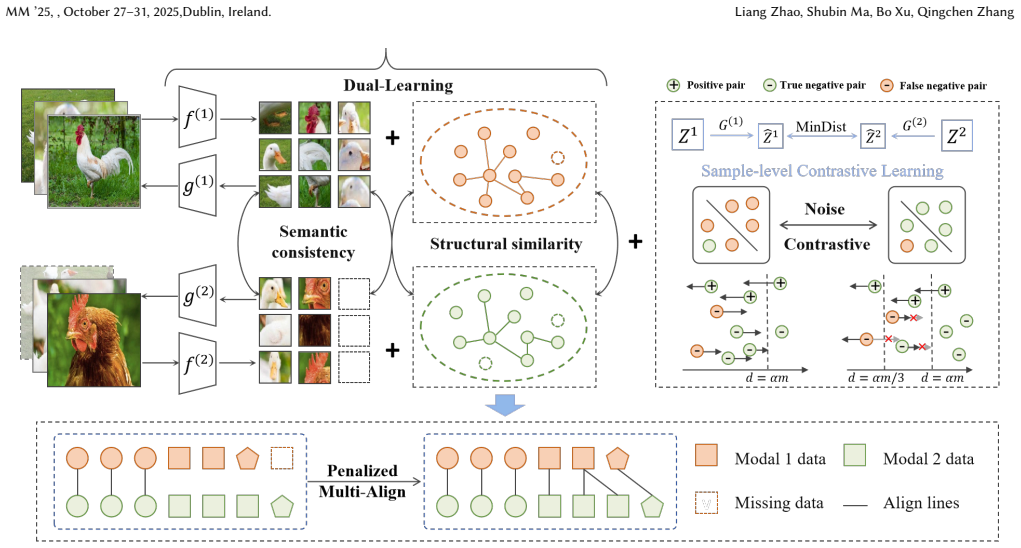
The dual-learning mechanism learns prior knowledge from each modality separately to preserve semantic consistency and structural similarity at local and global levels, while the penalized multi-align module performs multi-to-multi data alignment that improves data-pair accuracy and prevents data aggregation.
What carries the argument
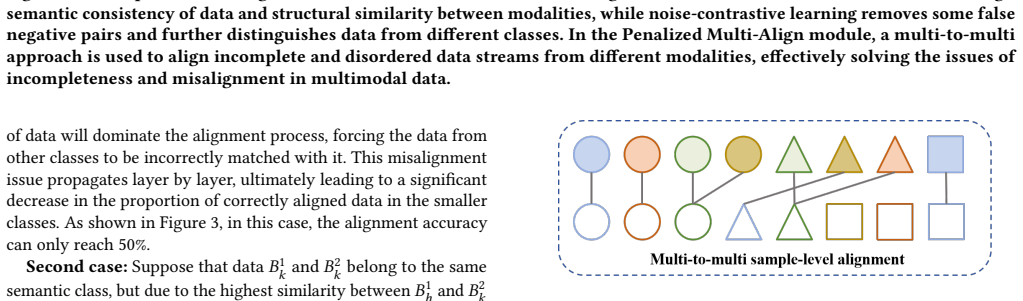
Penalized multi-align module that enables one sample to pair with different samples across modalities under a penalty that limits over-association.
If this is right
- Accurate sample-level alignment of data pairs across modalities becomes possible.
- Excessive linking of many samples to one sample is avoided.
- Discrepancies in class sizes across modalities are handled during alignment.
- Semantic and structural consistency is maintained locally and globally.
- Fusion performance improves for applications with incomplete sensor data.
Where Pith is reading between the lines
- The same penalty logic could be tested on streaming data where asynchrony changes over time rather than appearing as fixed disorder.
- Separate prior learning might reduce error carry-over compared with joint training when one modality is heavily corrupted.
- The approach could be combined with explicit temporal modeling to address the network-delay source of disorder mentioned in the motivating applications.
Load-bearing premise
Learning priors separately from each modality will keep semantic consistency and structural similarity intact without creating misalignments the penalty cannot correct.
What would settle it
A controlled experiment on data with known ground-truth sample pairings that shows the model produces lower alignment accuracy or higher aggregation rates than cluster-center baselines when missing rates or asynchrony increase.
Figures



read the original abstract
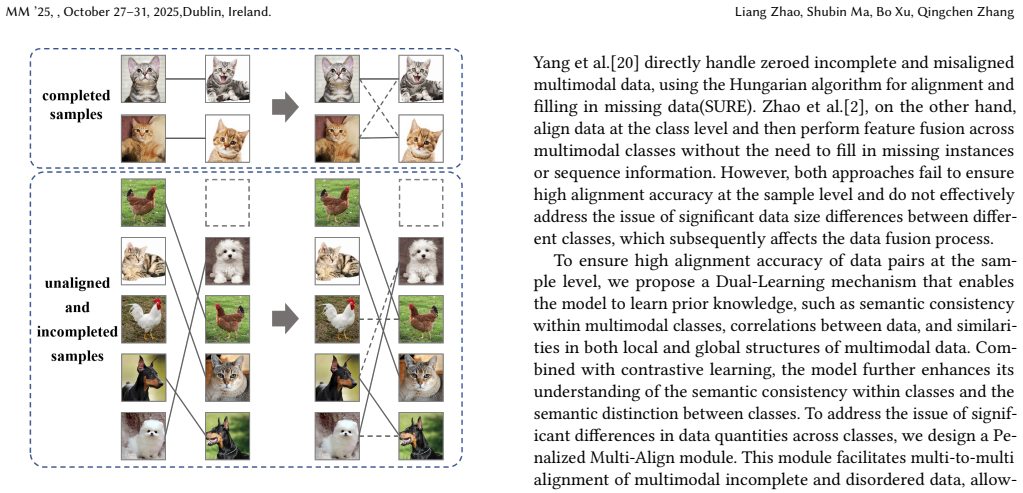
Multimodal feature fusion can effectively capture complex patterns in real-world data by integrating complementary information from different modalities. However, in many applications, such as boiler combustion monitoring, equipment failure, inconsistent sensor sampling frequencies, and network delays often cause missing modalities and temporal asynchrony. These issues lead to incomplete and disorderly multimodal data. To address them, previous studies have proposed several data fusion methods that align cluster centers before fusion. However, these methods have two key limitations. First, they cannot guarantee accurate sample-level alignment of data pairs. Second, they do not address significant discrepancies in data sizes across different classes, which may affect subsequent fusion performance. To address these problems, we propose a dual-learning based penalized multi-align clustering model, named DLPMAC. The dual-learning mechanism enables the model to learn prior knowledge from each modality, including semantic and structural information. This helps preserve semantic consistency and structural similarity across modalities at both local and global levels. In addition, the penalized multi-align module performs multi-to-multi data alignment through a penalty mechanism. It allows one sample to form data pairs with different samples from other modalities, thereby improving data-pair alignment accuracy. The penalty mechanism also prevents data aggregation, avoiding the case where excessive samples are linked to a single sample. Experimental results demonstrate the effectiveness of DLPMAC in addressing data alignment and fusion challenges from both sampling and clustering perspectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DLPMAC, a dual-learning based penalized multi-align clustering model for multi-view incomplete and disorderly data arising from missing modalities and temporal asynchrony. It claims that learning semantic and structural priors independently per modality preserves local/global consistency, while a penalty-based multi-to-multi alignment module improves sample-pair accuracy and prevents aggregation, outperforming prior cluster-center alignment methods.
Significance. If the empirical claims hold with proper validation, the work could provide a targeted solution for fusion in applications with inconsistent sampling (e.g., sensor networks), by addressing sample-level alignment and class-size imbalance. However, the absence of any quantitative results, baselines, ablations, or mathematical formulation in the supplied text makes it impossible to assess whether the dual-learning plus penalty combination actually enforces cross-modal consistency under differing missingness patterns.
major comments (3)
- [Abstract] Abstract: the central claim that 'Experimental results demonstrate the effectiveness of DLPMAC' is unsupported by any numerical results, baselines, ablation studies, or dataset descriptions, which is load-bearing for the effectiveness assertion.
- [Throughout] No equations or objective function are visible anywhere in the manuscript; without the explicit form of the dual-learning loss or the penalty term it is impossible to verify whether the multi-to-multi alignment corrects (rather than merely limits cardinality of) semantic drift when per-modality priors encode inconsistent cluster structures.
- [Abstract (model description)] The description of the penalized multi-align module asserts it 'prevents data aggregation' and 'improves data-pair alignment accuracy,' but supplies neither a derivation nor a bound showing that the combined objective forces consistency when input supports are misaligned across views (the skeptic concern).
minor comments (1)
- [Abstract] The abstract is overly long and contains repeated phrasing about 'data alignment and fusion challenges'; a shorter version focused on the two claimed limitations and how DLPMAC addresses them would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for explicit mathematical details and empirical support. We agree that the current manuscript version lacks these elements and will revise accordingly to address all points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experimental results demonstrate the effectiveness of DLPMAC' is unsupported by any numerical results, baselines, ablation studies, or dataset descriptions, which is load-bearing for the effectiveness assertion.
Authors: We acknowledge that the submitted manuscript does not include numerical results, baselines, ablation studies, or dataset descriptions to support the effectiveness claim in the abstract. This omission prevents proper evaluation. In the revised manuscript, we will add a full experimental section containing quantitative results on relevant datasets, comparisons against baselines, ablation studies, and dataset descriptions. revision: yes
-
Referee: [Throughout] No equations or objective function are visible anywhere in the manuscript; without the explicit form of the dual-learning loss or the penalty term it is impossible to verify whether the multi-to-multi alignment corrects (rather than merely limits cardinality of) semantic drift when per-modality priors encode inconsistent cluster structures.
Authors: We agree that no equations or objective function appear in the provided manuscript text. The dual-learning loss and penalty term must be explicitly defined to allow verification of the alignment behavior. We will include the complete mathematical formulation, including the dual-learning objective and penalized multi-align term, in the revised manuscript. revision: yes
-
Referee: [Abstract (model description)] The description of the penalized multi-align module asserts it 'prevents data aggregation' and 'improves data-pair alignment accuracy,' but supplies neither a derivation nor a bound showing that the combined objective forces consistency when input supports are misaligned across views (the skeptic concern).
Authors: The current abstract provides only a high-level description without derivation or bounds for the penalized multi-align module. We will add a dedicated section in the revised manuscript containing the mathematical derivation and any supporting bounds or analysis demonstrating how the objective enforces cross-modal consistency and prevents aggregation under misaligned inputs. revision: yes
Circularity Check
No circularity: derivation chain not reducible to inputs by construction
full rationale
The provided abstract and description contain no equations, fitting procedures, or self-citations that define the output in terms of the input. The dual-learning and penalized multi-align modules are described at a high level as mechanisms that learn priors and apply penalties, without any visible reduction where a claimed prediction or alignment result is forced by construction from the objective itself. No load-bearing self-citation, ansatz smuggling, or renaming of known results is exhibited in the text. The central claims rest on empirical effectiveness rather than a closed mathematical derivation that collapses to its own assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ahmed Abbas and Paul Swoboda. 2023. ClusterFuG: clustering fully connected graphs by multicut. InInternational Conference on Machine Learning. PMLR, 19–30
2023
-
[2]
Anonymous. 2024. Incomplete and Unpaired Multi-view Graph Clustering with Cross-view Feature Fusion. InThe 39th Annual AAAI Conference on Artificial Intelligence. https://openreview.net/forum?id=o8NR2rcS47
2024
-
[3]
Jie Chen, Hua Mao, Wai Lok Woo, and Xi Peng. 2023. Deep multiview clustering by contrasting cluster assignments. InProceedings of the IEEE/CVF international conference on computer vision. 16752–16761
2023
-
[4]
Yu Chen, Yanan Wu, Na Han, Xiaozhao Fang, Bingzhi Chen, and Jie Wen. 2024. Partial Multi-label Learning Based On Near-Far Neighborhood Label Enhance- ment And Nonlinear Guidance. InProceedings of the 32nd ACM International Conference on Multimedia. 3722–3731
2024
-
[5]
Hao Dai, Yang Liu, Peng Su, Hecheng Cai, Shudong Huang, and Jiancheng Lv
-
[6]
In Forty-first International Conference on Machine Learning
Multi-view clustering by inter-cluster connectivity guided reward. In Forty-first International Conference on Machine Learning
-
[7]
Yangshen Deng, Ted Shaowang, and Tapan Srivastava. 2025. Reproducibility Report for ACM SIGMOD 2024 Paper:’PECJ: Stream Window Join on Disorder Data Streams with Proactive Error Compensation’. InReproducibility Reports of the 2024 International Conference on Management of Data. 5–7
2025
-
[8]
Zhibin Dong, Siwei Wang, Jiaqi Jin, Xinwang Liu, and En Zhu. 2023. Cross-view topology based consistent and complementary information for deep multi-view clustering. InProceedings of the IEEE/CVF International Conference on Computer Vision. 19440–19451
2023
-
[9]
Liang Du, Yukai Shi, Yan Chen, Peng Zhou, and Yuhua Qian. 2024. Fast and scalable incomplete multi-view clustering with duality optimal graph filtering. In Proceedings of the 32nd ACM International Conference on Multimedia. 8893–8902
2024
-
[10]
Ruiming Guo, Mouxing Yang, Yijie Lin, Xi Peng, and Peng Hu. 2024. Robust Contrastive Multi-view Clustering against Dual Noisy Correspondence.Advances in Neural Information Processing Systems37 (2024), 121401–121421
2024
-
[11]
Changhao He, Hongyuan Zhu, Peng Hu, and Xi Peng. 2024. Robust Variational Contrastive Learning for Partially View-unaligned Clustering. InProceedings of the 32nd ACM International Conference on Multimedia. 4167–4176
2024
-
[12]
Zhenyu Huang, Peng Hu, Joey Tianyi Zhou, Jiancheng Lv, and Xi Peng. 2020. Partially view-aligned clustering.Advances in Neural Information Processing Systems33 (2020), 2892–2902
2020
-
[13]
Jing Li, Quanxue Gao, Qianqian Wang, Ming Yang, and Wei Xia. 2023. Orthogonal non-negative tensor factorization based multi-view clustering.Advances in neural information processing systems36 (2023), 18186–18202
2023
-
[14]
Zheng Lian, Lan Chen, Licai Sun, Bin Liu, and Jianhua Tao. 2023. Gcnet: Graph completion network for incomplete multimodal learning in conversation.IEEE Transactions on pattern analysis and machine intelligence45, 7 (2023), 8419–8432. Dual-Learning based Penalized Multi-Align Clustering for Multi-View Incomplete and Disorderly Data MM ’25, , October 27–31...
2023
- [15]
-
[16]
Yiqiao Mao, Xiaoqiang Yan, Jiaming Liu, and Yangdong Ye. 2023. ConGMC: Consistency-Guided Multimodal Clustering via Mutual Information Maximin. IEEE Transactions on Multimedia26 (2023), 5131–5146
2023
-
[17]
Shengsheng Qian, Dizhan Xue, Jun Hu, Huaiwen Zhang, and Changsheng Xu
-
[18]
Nonparametric Clustering-Guided Cross-View Contrastive Learning for Partially View-Aligned Representation Learning.IEEE Transactions on Image Processing(2024)
2024
-
[19]
Yazhou Ren, Xinyue Chen, Jie Xu, Jingyu Pu, Yonghao Huang, Xiaorong Pu, Ce Zhu, Xiaofeng Zhu, Zhifeng Hao, and Lifang He. 2024. A novel federated multi- view clustering method for unaligned and incomplete data fusion.Information Fusion108 (2024), 102357
2024
-
[20]
Jinping Wang, Jun Li, Yanli Shi, Jianhuang Lai, and Xiaojun Tan. 2022. AM3Net: Adaptive mutual-learning-based multimodal data fusion network.IEEE Transac- tions on Circuits and Systems for Video Technology32, 8 (2022), 5411–5426
2022
-
[21]
Yi Wen, Siwei Wang, Ke Liang, Weixuan Liang, Xinhang Wan, Xinwang Liu, Suyuan Liu, Jiyuan Liu, and En Zhu. 2023. Scalable incomplete multi-view clustering with structure alignment. InProceedings of the 31st ACM International Conference on Multimedia. 3031–3040
2023
-
[22]
Mouxing Yang, Yunfan Li, Peng Hu, Jinfeng Bai, Jiancheng Lv, and Xi Peng. 2022. Robust multi-view clustering with incomplete information.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 1 (2022), 1055–1069
2022
-
[23]
Mouxing Yang, Yunfan Li, Zhenyu Huang, Zitao Liu, Peng Hu, and Xi Peng. 2021. Partially view-aligned representation learning with noise-robust contrastive loss. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1134–1143
2021
-
[24]
Hong Yu, Jia Tang, Guoyin Wang, and Xinbo Gao. 2021. A novel multi-view clus- tering method for unknown mapping relationships between cross-view samples. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 2075–2083
2021
-
[25]
Honglin Yuan, Shiyun Lai, Xingfeng Li, Jian Dai, Yuan Sun, and Zhenwen Ren
-
[26]
In Proceedings of the 32nd ACM International Conference on Multimedia
Robust Prototype Completion for Incomplete Multi-view Clustering. In Proceedings of the 32nd ACM International Conference on Multimedia. 10402– 10411
-
[27]
Pengxin Zeng, Mouxing Yang, Yiding Lu, Changqing Zhang, Peng Hu, and Xi Peng. 2023. Semantic invariant multi-view clustering with fully incomplete information.IEEE Transactions on Pattern Analysis and Machine Intelligence (2023)
2023
- [28]
-
[29]
Xiaotong Zhang, Xianchao Zhang, Han Liu, and Xinyue Liu. 2016. Multi-task multi-view clustering.IEEE Transactions on Knowledge and Data Engineering28, 12 (2016), 3324–3338
2016
-
[30]
Fei Zhao, Chengcui Zhang, and Baocheng Geng. 2024. Deep multimodal data fusion.ACM computing surveys56, 9 (2024), 1–36
2024
-
[31]
Liang Zhao, Pingda Huang, Tengtuo Chen, Chunjiang Fu, Qinghao Hu, and Yangqianhui Zhang. 2023. Multi-sentence complementarily generation for text- to-image synthesis.IEEE Transactions on Multimedia(2023)
2023
-
[32]
Liang Zhao, Xiao Wang, Zhenjiao Liu, Ziyue Wang, and Zhikui Chen. 2024. Learn- able Graph Guided Deep Multi-view Representation Learning via Information Bottleneck.IEEE Transactions on Circuits and Systems for Video Technology(2024)
2024
-
[33]
Liang Zhao, Zihao Wang, Yukun Yuan, and Feng Ding. 2023. Unrestricted anchor graph based gcn for incomplete multi-view clustering. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[34]
Liang Zhao, Qiongjie Xie, Zhengtao Li, Songtao Wu, and Yi Yang. 2024. Dynamic Graph Guided Progressive Partial View-Aligned Clustering.IEEE Transactions on Neural Networks and Learning Systems(2024)
2024
-
[35]
Liang Zhao, Qiongjie Xie, Sontao Wu, and Shubin Ma. 2023. An end-to-end framework for partial view-aligned clustering with graph structure. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[36]
Lihua Zhou, Guowang Du, Kevin Lü, Lizheng Wang, and Jingwei Du. 2024. A Survey and an Empirical Evaluation of Multi-view Clustering Approaches. Comput. Surveys56, 7 (2024), 1–38
2024
-
[37]
Ye Zhu, Yu Wu, Nicu Sebe, and Yan Yan. 2024. Vision+ x: A survey on multimodal learning in the light of data.IEEE Transactions on Pattern Analysis and Machine Intelligence(2024)
2024
-
[38]
Linlin Zong, Xianchao Zhang, and Xinyue Liu. 2018. Multi-view clustering on unmapped data via constrained non-negative matrix factorization.Neural Networks108 (2018), 155–171
2018
-
[39]
Yongshuo Zong, Oisin Mac Aodha, and Timothy Hospedales. 2024. Self- supervised multimodal learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence(2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.