AdaBoosting Text Prompts for Vision-Language Models
Pith reviewed 2026-07-02 16:21 UTC · model grok-4.3
The pith
Text Prompt Boosting builds ensembles of text prompts by targeting misclassified examples to improve few-shot accuracy and enable transfer across vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
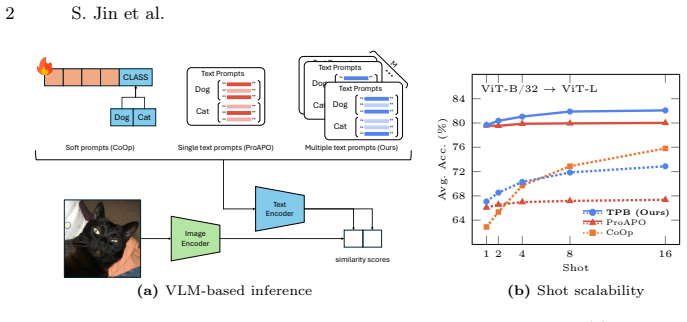
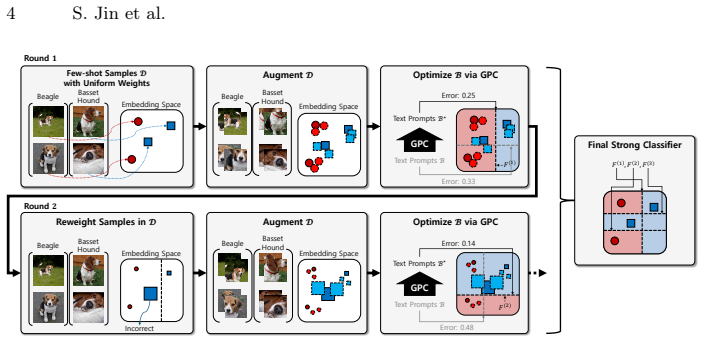
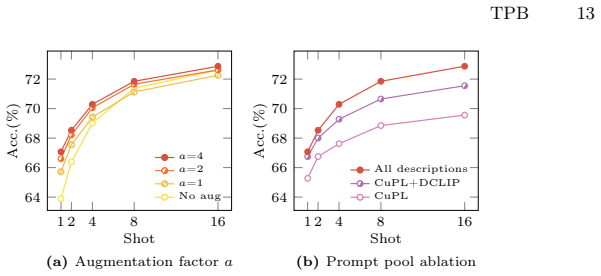
TPB treats each text-prompt-based classifier as a weak learner and sequentially aggregates them into a strong ensemble by explicitly targeting hard, misclassified examples. Extensive experiments show that TPB preserves task-intrinsic, model-agnostic cues in text space, enabling robust cross-model transfer. Across eleven classification benchmarks, TPB improves accuracy on the source model and preserves shot-driven gains when transferred to larger, more capable VLMs, where existing methods struggle to sustain such improvements.
What carries the argument
The AdaBoost-inspired sequential aggregation of text-prompt classifiers, each trained to correct errors of the previous ensemble.
If this is right
- TPB raises classification accuracy on the original VLM with few-shot supervision.
- The same prompt ensemble transfers performance gains to larger VLMs without retraining.
- Prompts stay interpretable because they remain in text space rather than model-specific weights.
- Existing few-shot methods show marginal gains that do not hold up on model transfer.
Where Pith is reading between the lines
- This approach could allow prompt ensembles to serve as portable task adapters across evolving VLM families.
- Error-driven prompt selection might reveal which visual distinctions are hardest for current models to capture in text.
- Applying similar boosting to other prompt types, such as those for generation tasks, could be tested.
Load-bearing premise
Sequentially focusing new text prompts on misclassified examples will yield an ensemble whose combined decisions remain independent of the specific VLM used for training and thus transfer intact.
What would settle it
Measuring accuracy on a larger target VLM with the TPB ensemble versus a single prompt or prior few-shot method; if the relative gain disappears or reverses, the transfer claim would be falsified.
Figures
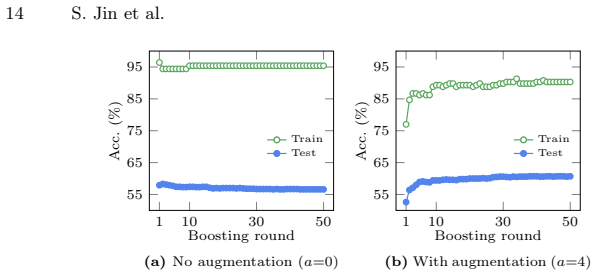
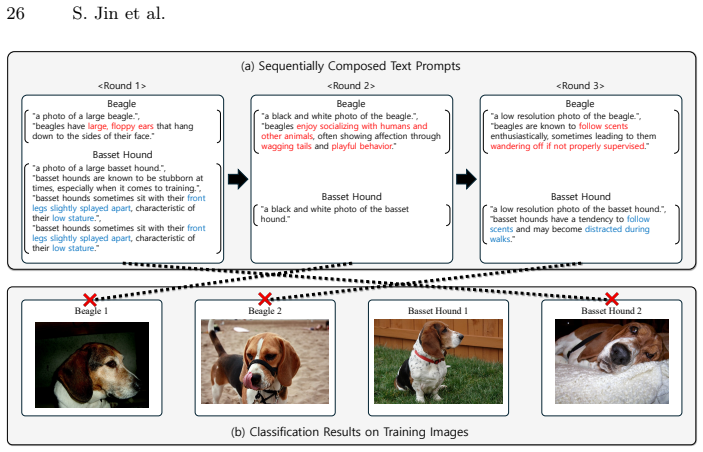
read the original abstract
The classification accuracy of pretrained Vision-Language Models (VLMs) relies on the quality of the text prompts. Handcrafted templates and Large Language Model (LLM)-generated descriptions not only make predictions more interpretable, but also enable reuse of the same prompts across heterogeneous VLMs. Recent works construct task-adapted text prompts with a small number of labeled images. However, existing few-shot text prompting methods do not explicitly focus on misclassified examples during prompt construction, leading to only marginal improvements even as more shots become available. To fully exploit few-shot supervision, we propose Text Prompt Boosting (TPB), an AdaBoost-inspired framework that treats each text-prompt-based classifier as a weak learner and sequentially aggregates them into a strong ensemble by explicitly targeting hard, misclassified examples. Extensive experiments show that TPB preserves task-intrinsic, model-agnostic cues in text space, enabling robust cross-model transfer. Across eleven classification benchmarks, TPB improves accuracy on the source model and preserves shot-driven gains when transferred to larger, more capable VLMs, where existing methods struggle to sustain such improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Text Prompt Boosting (TPB), an AdaBoost-inspired framework that treats text-prompt classifiers as weak learners and sequentially aggregates them by reweighting misclassified examples from few-shot data. It claims that the resulting ensemble improves accuracy on the source VLM while preserving shot-driven gains under transfer to larger heterogeneous VLMs across eleven classification benchmarks, with the prompts remaining task-intrinsic and model-agnostic.
Significance. If the transfer claim holds without source-specific bias leakage, the work would offer a concrete algorithmic route to more effective few-shot text prompting that scales across VLMs, addressing a limitation of prior handcrafted or LLM-generated prompt methods. The multi-benchmark evaluation and explicit focus on misclassified examples constitute a clear empirical contribution.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central transfer claim requires that boosting weights derived from source-VLM errors remain decoupled from architecture-specific failure modes, yet no derivation, control experiment, or ablation is supplied showing that the reweighting objective produces model-agnostic cues rather than embedding source inductive biases (e.g., texture vs. shape preferences).
- [§4] §4 (experiments): the reported preservation of gains on target VLMs is load-bearing for the model-agnostic premise, but the abstract and available description supply no error bars, statistical significance tests, exact number of weak learners, or ensemble construction details, preventing verification that improvements exceed marginal gains of prior methods.
minor comments (2)
- [§3] Clarify in §3 how the final ensemble prediction is formed (weighted sum or majority vote) and whether prompt weights are normalized after each boosting round.
- [Table 1] Table 1 or equivalent: report the number of shots used per benchmark and the exact source/target VLM pairs to allow direct comparison with prior few-shot prompting baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the transfer claim and experimental reporting. We address each major comment below and will revise the manuscript to strengthen the presentation where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central transfer claim requires that boosting weights derived from source-VLM errors remain decoupled from architecture-specific failure modes, yet no derivation, control experiment, or ablation is supplied showing that the reweighting objective produces model-agnostic cues rather than embedding source inductive biases (e.g., texture vs. shape preferences).
Authors: We acknowledge that the manuscript does not include a dedicated derivation or control ablation isolating the reweighting from source-specific inductive biases. The current evidence for model-agnostic cues rests on the observed preservation of gains when transferring the learned prompts to heterogeneous target VLMs. To directly address this point, we will add a new ablation in the revision that compares source-derived weights against target-model-derived weights and random reweighting, quantifying whether the cues remain effective across architectures. revision: yes
-
Referee: [§4] §4 (experiments): the reported preservation of gains on target VLMs is load-bearing for the model-agnostic premise, but the abstract and available description supply no error bars, statistical significance tests, exact number of weak learners, or ensemble construction details, preventing verification that improvements exceed marginal gains of prior methods.
Authors: Section 4 of the full manuscript reports results averaged over three random seeds with standard deviation error bars, applies paired t-tests for significance against baselines, uses exactly five weak learners, and constructs the ensemble as a weighted linear combination of the prompt classifiers with AdaBoost-derived weights. These details are present in the experimental section but are not summarized in the abstract. We will revise the abstract to include the number of weak learners and note the use of error bars and significance testing. revision: partial
Circularity Check
No circularity; algorithmic framework evaluated empirically on benchmarks.
full rationale
The paper describes TPB as an AdaBoost-inspired sequential aggregation of text-prompt classifiers targeting misclassified examples, with claims of improved accuracy and cross-model transfer supported solely by experimental results across eleven benchmarks. No derivation step reduces by construction to fitted parameters, self-definitions, or self-citation chains; the method is presented as a standard boosting procedure whose outputs are validated externally rather than tautologically. The model-agnostic transfer premise is asserted as an empirical outcome, not derived from source-specific error patterns by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: European conference on computer vision
Bossard, L., Guillaumin, M., Van Gool, L.: Food-101–mining discriminative com- ponents with random forests. In: European conference on computer vision. pp. 446–461. Springer (2014)
2014
-
[2]
Byeon, M., Park, B., Kim, H., Lee, S., Baek, W., Kim, S.: Coyo-700m: Image-text pair dataset (2022)
2022
-
[3]
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A.J., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., et al.: Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J.: Reproducible scaling laws for contrastive language-image learning. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 2818–2829 (2023)
2023
-
[5]
arXiv preprint arXiv:2507.22062 (2025)
Chuang, Y.S., Li, Y., Wang, D., Yeh, C.F., Lyu, K., Raghavendra, R., Glass, J., Huang, L., Weston, J., Zettlemoyer, L., et al.: Meta clip 2: A worldwide scaling recipe. arXiv preprint arXiv:2507.22062 (2025)
-
[6]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3606–3613 (2014)
2014
-
[7]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[8]
In: Bmvc
Dollár, P., Tu, Z., Perona, P., Belongie, S.J.: Integral channel features. In: Bmvc. vol. 2, p. 5. London, UK (2009)
2009
-
[9]
arXiv preprint arXiv:2309.17425 , year=
Fang, A., Jose, A.M., Jain, A., Schmidt, L., Toshev, A., Shankar, V.: Data filtering networks. arXiv preprint arXiv:2309.17425 (2023)
-
[10]
In: 2004 conference on computer vision and pattern recognition workshop
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object cate- gories. In: 2004 conference on computer vision and pattern recognition workshop. pp. 178–178. IEEE (2004)
2004
-
[11]
Journal of machine learning research4(Nov), 933–969 (2003)
Freund, Y., Iyer, R., Schapire, R.E., Singer, Y.: An efficient boosting algorithm for combining preferences. Journal of machine learning research4(Nov), 933–969 (2003)
2003
-
[12]
Journal of computer and system sciences55(1), 119–139 (1997)
Freund, Y., Schapire, R.E.: A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences55(1), 119–139 (1997)
1997
-
[13]
The annals of statistics28(2), 337–407 (2000)
Friedman, J., Hastie, T., Tibshirani, R.: Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The annals of statistics28(2), 337–407 (2000)
2000
-
[14]
Advances in Neural Information Processing Systems36, 27092–27112 (2023)
Gadre, S.Y., Ilharco, G., Fang, A., Hayase, J., Smyrnis, G., Nguyen, T., Marten, R., Wortsman, M., Ghosh, D., Zhang, J., et al.: Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems36, 27092–27112 (2023)
2023
-
[15]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[16]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing12(7), 2217– 2226 (2019) TPB 17
Helber, P., Bischke, B., Dengel, A., Borth, D.: Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing12(7), 2217– 2226 (2019) TPB 17
2019
-
[17]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
2021
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19113–19122 (2023)
2023
-
[19]
In: Pro- ceedings of the IEEE/CVF international conference on computer vision
Khattak, M.U., Wasim, S.T., Naseer, M., Khan, S., Yang, M.H., Khan, F.S.: Self- regulating prompts: Foundational model adaptation without forgetting. In: Pro- ceedings of the IEEE/CVF international conference on computer vision. pp. 15190– 15200 (2023)
2023
-
[20]
In: Proceedings of the IEEE international conference on computer vision workshops
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine- grained categorization. In: Proceedings of the IEEE international conference on computer vision workshops. pp. 554–561 (2013)
2013
-
[21]
In: R0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models (2023)
Li, X., Wang, Z., Xie, C.: Clipa-v2: Scaling clip training with 81.1% zero-shot imagenet accuracy within a $10,000 budget. In: R0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models (2023)
2023
-
[22]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Liu, S., Yu, S., Lin, Z., Pathak, D., Ramanan, D.: Language models as black-box optimizers for vision-language models. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 12687–12697 (2024)
2024
-
[23]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Fine-Grained Visual Classification of Aircraft
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
arXiv preprint arXiv:2210.07183 (2022)
Menon, S., Vondrick, C.: Visual classification via description from large language models. arXiv preprint arXiv:2210.07183 (2022)
-
[26]
arXiv preprint arXiv:2310.12962 (2023)
Mitchell, E., Rafailov, R., Sharma, A., Finn, C., Manning, C.D.: An emulator for fine-tuning large language models using small language models. arXiv preprint arXiv:2310.12962 (2023)
-
[27]
In: 2008 Sixth Indian conference on computer vision, graphics & image processing
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large number of classes. In: 2008 Sixth Indian conference on computer vision, graphics & image processing. pp. 722–729. IEEE (2008)
2008
-
[28]
arXiv preprint arXiv:2508.08604 (2025)
Park, J., Lee, S., Choi, M., Kim, H.J., et al.: Transferable model-agnostic vision-language model adaptation for efficient weak-to-strong generalization. arXiv preprint arXiv:2508.08604 (2025)
-
[29]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Park, J., Ko, J., Kim, H.J.: Prompt learning via meta-regularization. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26940–26950 (2024)
2024
-
[30]
In: 2012 IEEE conference on computer vision and pattern recognition
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.: Cats and dogs. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 3498–3505. IEEE (2012)
2012
-
[31]
Journal of Machine Learning Research12, 2825–2830 (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine learning in Python. Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[32]
In: Proceedings of the IEEE/CVF international conference on computer vision
Pratt, S., Covert, I., Liu, R., Farhadi, A.: What does a platypus look like? gener- ating customized prompts for zero-shot image classification. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 15691–15701 (2023)
2023
-
[33]
In: Proceed- 18 S
Qu, X., Gou, G., Zhuang, J., Yu, J., Song, K., Wang, Q., Li, Y., Xiong, G.: Proapo: Progressively automatic prompt optimization for visual classification. In: Proceed- 18 S. Jin et al. ings of the Computer Vision and Pattern Recognition Conference. pp. 25145–25155 (2025)
2025
-
[34]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[35]
Advances in neural information processing systems36, 69706–69718 (2023)
Ren, Z., Su, Y., Liu, X.: Chatgpt-powered hierarchical comparisons for image clas- sification. Advances in neural information processing systems36, 69706–69718 (2023)
2023
-
[36]
In: Proceedings of the IEEE/CVF international conference on computer vision
Roth, K., Kim, J.M., Koepke, A., Vinyals, O., Schmid, C., Akata, Z.: Waffling around for performance: Visual classification with random words and broad con- cepts. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 15746–15757 (2023)
2023
-
[37]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Saha, O., Van Horn, G., Maji, S.: Improved zero-shot classification by adapting vlms with text descriptions. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 17542–17552 (2024)
2024
-
[38]
Machine learning39(2), 135–168 (2000)
Schapire, R.E., Singer, Y.: Boostexter: A boosting-based system for text catego- rization. Machine learning39(2), 135–168 (2000)
2000
-
[39]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[40]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[41]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Sun, Q., Fang, Y., Wu, L., Wang, X., Cao, Y.: Eva-clip: Improved training tech- niques for clip at scale. arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition
Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple fea- tures. In: Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001. vol. 1, pp. I–I. Ieee (2001)
2001
-
[44]
Advances in Neural Information Processing Systems36, 51008–51025 (2023)
Wen,Y.,Jain,N.,Kirchenbauer,J.,Goldblum,M.,Geiping,J.,Goldstein,T.:Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. Advances in Neural Information Processing Systems36, 51008–51025 (2023)
2023
- [45]
-
[46]
In: 2010 IEEE computer society conference on computer vision and pattern recognition
Xiao, J., Hays, J., Ehinger, K.A., Oliva, A., Torralba, A.: Sun database: Large-scale scene recognition from abbey to zoo. In: 2010 IEEE computer society conference on computer vision and pattern recognition. pp. 3485–3492. IEEE (2010)
2010
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16816–16825 (2022)
2022
-
[48]
International Journal of Computer Vision130(9), 2337–2348 (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision130(9), 2337–2348 (2022)
2022
-
[49]
Zhu, J., Zou, H., Rosset, S., Hastie, T., et al.: Multi-class adaboost. Tech. Rep. 430, Department of Statistics, University of Michigan (2005) TPB 19
2005
-
[50]
a photo of a large beagle
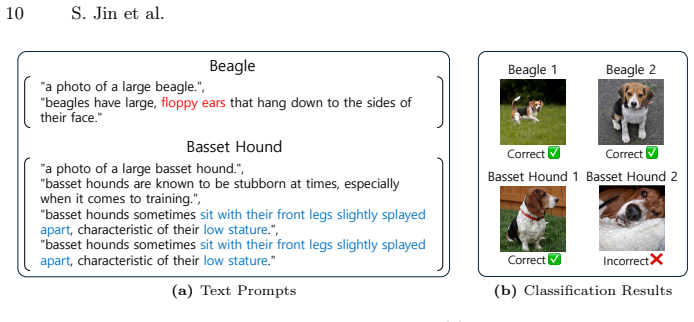
Zhu, Y., Ji, Y., Zhao, Z., Wu, G., Wang, L.: Awt: Transferring vision-language models via augmentation, weighting, and transportation. Advances in Neural In- formation Processing Systems37, 25561–25591 (2024) 20 S. Jin et al. Algorithm 1Our weak learning algorithm, Greedy Prompt Composition (GPC). In Line 9,SelectBestdenotes prompt selection process, whic...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.