Autoencoder Architectures for Athlete Performance Scoring from Wearable Telemetry
Pith reviewed 2026-06-29 04:50 UTC · model grok-4.3
The pith
Deep autoencoders achieve the lowest reconstruction error and highest composite interpretability score when reducing nine wearable sensor features to a single latent performance indicator for runners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
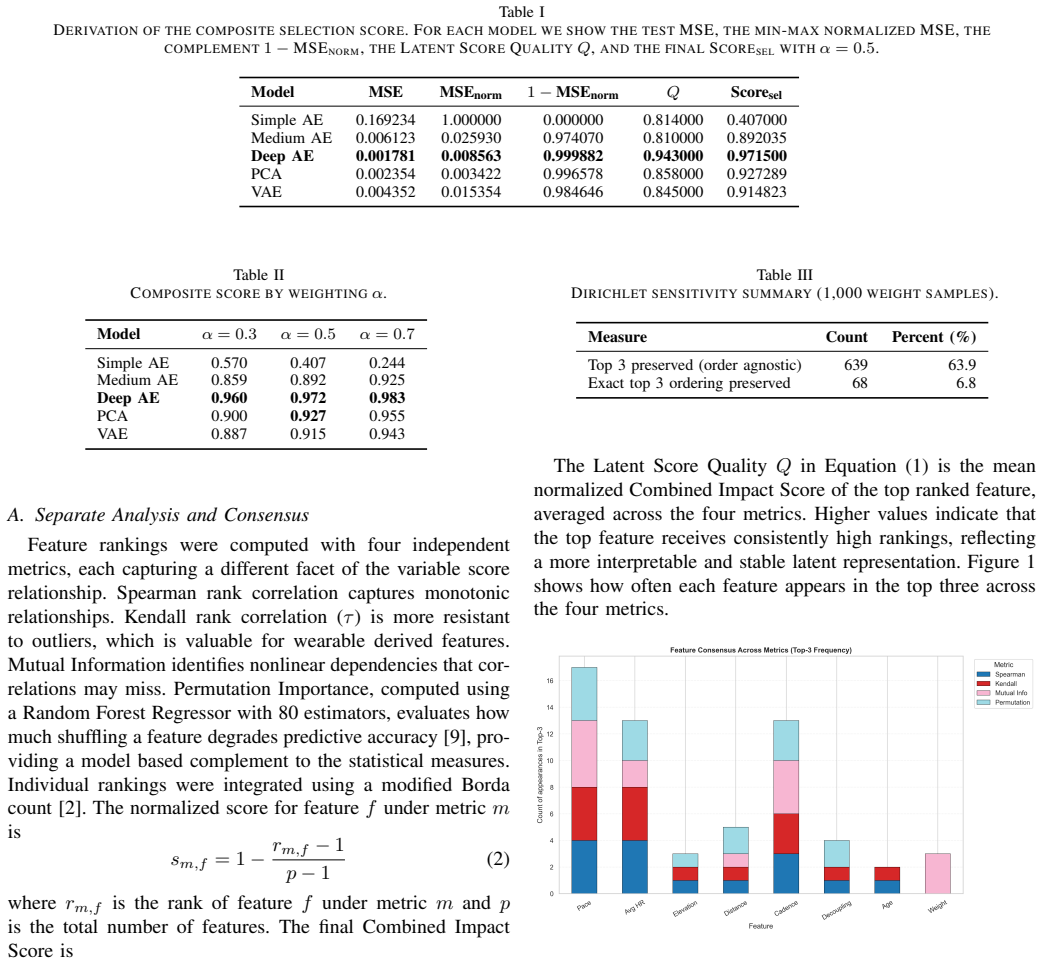
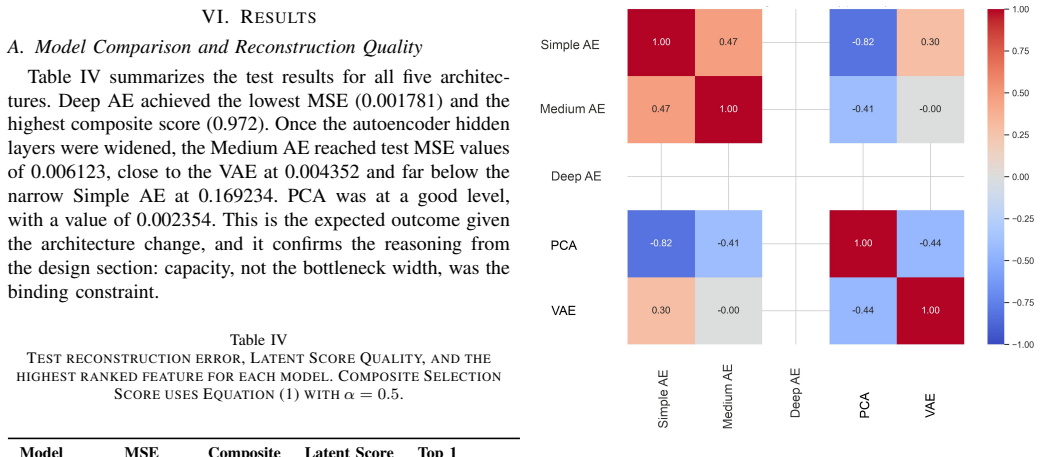
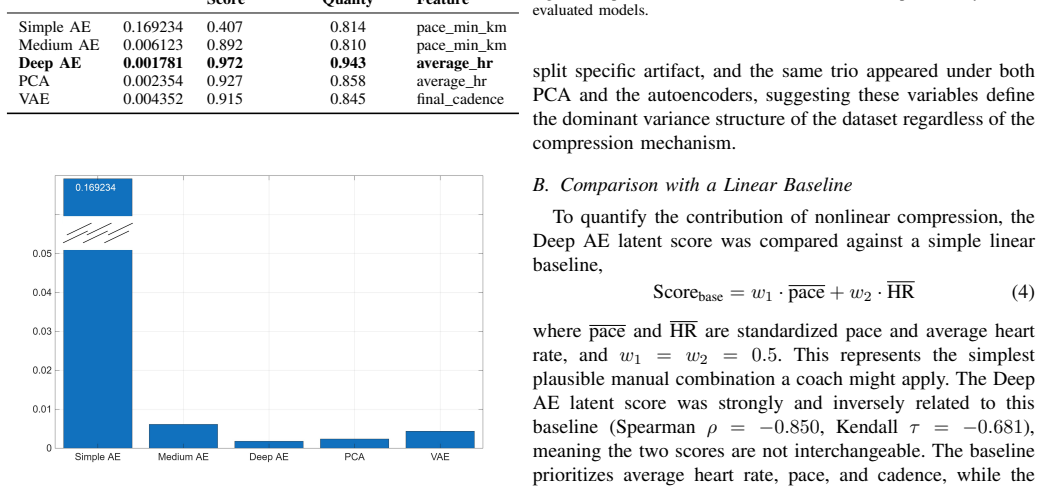
Deep autoencoder achieved the lowest reconstruction error and the highest composite score. Once the PCA hidden layers were widened, the deeper variants became closely competitive with Deep AE on the composite criterion, indicating that the limiting factor was hidden layer capacity rather than the one dimensional bottleneck. Running pace, aerobic decoupling, and average heart rate emerged as the dominant latent score drivers across all models and resampling runs, consistent with established physiology.
What carries the argument
The composite selection criterion that aggregates reconstruction MSE, Spearman and Kendall correlations, mutual information, and permutation importance via modified Borda count to choose among unsupervised models.
If this is right
- The deep autoencoder provides the best balance of accurate reconstruction and interpretable latent scores.
- Hidden layer capacity, not the bottleneck dimension, limits performance in these models.
- Running pace, aerobic decoupling, and average heart rate are the primary physiological drivers of the derived performance score.
- Bootstrap validation confirms the stability of the feature rankings and model selection.
- A simple two-feature linear baseline underperforms the neural models on the composite criterion.
Where Pith is reading between the lines
- If the latent score proves stable over time, it could serve as a real-time training load monitor without needing race results.
- The same approach might generalize to other endurance sports where multiple sensors produce unlabeled data streams.
- Widening layers in other reduction methods could close the gap further if computational resources allow.
- The dominance of pace and heart rate metrics suggests the latent score largely rediscovers known training principles rather than uncovering new ones.
Load-bearing premise
The composite selection criterion selects models that produce a physiologically meaningful latent performance score even without any ground-truth labels.
What would settle it
Observing that the top-ranked model on the composite criterion produces latent scores that show no correlation with actual changes in runner fitness over a training season would falsify the claim that the method yields meaningful performance indicators.
Figures
read the original abstract
Wearable devices produce large, high dimensional training logs for everyday runners, and interpretation rather than data collection is now the limiting step. This paper evaluates five dimensionality reduction models, three autoencoder variants, PCA, and a Variational Autoencoder, on their ability to compress nine sensor runner profiles into a single scalar performance indicator, the latent score. Because the setting is fully unsupervised, model quality is assessed along two complementary axes: reconstruction error (Mean Squared Error) and latent score interpretability, measured via Spearman and Kendall rank correlations, Mutual Information, and Permutation Importance. These are combined into a composite selection criterion that prevents selecting models on reconstruction accuracy alone. Feature rankings from the four metrics are aggregated via a modified Borda count, and their stability is confirmed by bootstrap validation. A two feature linear baseline is included to anchor the comparison. Deep autoencoder achieved the lowest reconstruction error and the highest composite score. Once the PCA hidden layers were widened, the deeper variants became closely competitive with Deep AE on the composite criterion, indicating that the limiting factor was hidden layer capacity rather than the one dimensional bottleneck. Running pace, aerobic decoupling, and average heart rate emerged as the dominant latent score drivers across all models and resampling runs, consistent with established physiology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates five dimensionality reduction models (three autoencoder variants, PCA, and VAE) for compressing nine-dimensional wearable sensor data from runners into a one-dimensional latent performance score. Quality is assessed via reconstruction MSE together with interpretability metrics (Spearman and Kendall rank correlations, mutual information, permutation importance) that are aggregated by a modified Borda count; bootstrap resampling confirms stability of the ranking. A two-feature linear baseline is included. The deep autoencoder is reported to achieve the lowest MSE and highest composite score; widening the PCA layers renders deeper variants competitive, leading to the conclusion that hidden-layer capacity rather than the 1-D bottleneck is the limiting factor. Running pace, aerobic decoupling, and average heart rate are identified as the dominant drivers across models.
Significance. If the composite internal-consistency criterion reliably identifies models whose latent scores track athletic performance, the work would offer a practical unsupervised tool for wearable telemetry analysis. The bootstrap validation protocol and the explicit linear baseline are methodological strengths that improve reproducibility. However, because all four interpretability axes are computed from the same unlabeled sensor features and model internals, the significance is currently limited to internal compression quality rather than demonstrated physiological validity.
major comments (1)
- [Abstract] Abstract and evaluation protocol: the central claim that the latent score constitutes a physiologically meaningful performance indicator rests on the modified Borda aggregation of reconstruction MSE, Spearman/Kendall correlations, mutual information, and permutation importance. All four axes are derived solely from the unlabeled telemetry and model internals; none are validated against external performance outcomes (e.g., race times, training logs, or physiological markers). This makes the superiority of the deep autoencoder an internal-consistency result rather than evidence that the 1-D latent variable tracks actual athletic performance.
minor comments (2)
- [Methods] The exact functional form of the modified Borda count and the weighting of the four interpretability metrics should be stated with an equation in the methods section.
- [Results] The phrase 'PCA hidden layers' is unclear because PCA is a linear method; clarify whether this refers to an autoencoder-style implementation of PCA or to the number of retained components.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We agree that the evaluation protocol relies exclusively on internal consistency metrics computed from unlabeled telemetry and model internals, without external validation against ground-truth performance outcomes. This limits the strength of claims regarding physiological validity of the latent score. We will revise the manuscript accordingly to clarify the scope of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation protocol: the central claim that the latent score constitutes a physiologically meaningful performance indicator rests on the modified Borda aggregation of reconstruction MSE, Spearman/Kendall correlations, mutual information, and permutation importance. All four axes are derived solely from the unlabeled telemetry and model internals; none are validated against external performance outcomes (e.g., race times, training logs, or physiological markers). This makes the superiority of the deep autoencoder an internal-consistency result rather than evidence that the 1-D latent variable tracks actual athletic performance.
Authors: We acknowledge the validity of this observation. The manuscript is framed as an unsupervised dimensionality-reduction study, and the composite criterion (reconstruction MSE + interpretability metrics aggregated by modified Borda count) is explicitly internal. The abstract and introduction do use the term “performance indicator,” which can be read as implying external validity that is not demonstrated. We will revise the abstract, introduction, and conclusion to state that the latent score is a data-driven scalar that (i) minimizes reconstruction error while (ii) aligning with physiologically plausible feature rankings according to the four internal metrics, and (iii) that external validation against race times or training logs remains future work. We will also add an explicit limitations paragraph on the absence of labeled performance outcomes. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper evaluates five dimensionality reduction models using independent external metrics (reconstruction MSE, Spearman/Kendall rank correlations, mutual information, permutation importance) that are aggregated via modified Borda count into a composite criterion. These metrics are computed from the data and model outputs without reducing to a self-referential definition or fitted parameter; the claim that Deep AE achieves the highest composite score follows directly from applying these standard, non-derived criteria rather than any equation or self-citation that forces the result by construction. A linear baseline is included for anchoring, and no load-bearing step invokes uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Unsupervised compression of sensor streams yields a latent variable whose value correlates with established physiological performance markers
- ad hoc to paper A modified Borda count aggregation of four interpretability metrics plus reconstruction error produces a stable model ranking
invented entities (1)
-
latent score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Effective injury forecasting in soccer with GPS training data and machine learning,
A. Rossi, L. Pappalardo, P. Cintia, F. M. Iaia, J. Fernández, and D. Medina, “Effective injury forecasting in soccer with GPS training data and machine learning,”PLOS ONE, vol. 13, no. 7, p. e0201264,
-
[2]
DOI: https://doi.org/10.1371/journal.pone.0201264
-
[3]
Rank aggregation methods for the web,
C. Dwork, R. Kumar, M. Naor, and D. Sivakumar, “Rank aggregation methods for the web,” inProc. 10th Int. Conf. World Wide Web, 2001, pp. 613–622. DOI: https://doi.org/10.1145/371920.372165
-
[4]
Reducing the dimensionality of data with neural networks,
G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,”Science, vol. 313, no. 5786, pp. 504–507,
-
[5]
DOI: https://doi.org/10.1126/science.1127647
-
[6]
Auto-encoding variational Bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in Proc. Int. Conf. Learn. Representations (ICLR), 2014. arXiv: https:// arxiv.org/abs/1312.6114
Pith/arXiv arXiv 2014
-
[7]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inAdvances in Neural Information Processing Systems 30, 2017, pp. 4765–4774
2017
-
[8]
M. Buchheit and P. B. Laursen, “High-intensity interval training, solu- tions to the programming puzzle: Part II: anaerobic energy, neuromus- cular load and practical applications,”Sports Medicine, vol. 43, no. 10, pp. 927–954, 2013. DOI: https://doi.org/10.1007/s40279-013-0066-5
-
[9]
Autoencoders, unsupervised learning, and deep architectures,
P. Baldi, “Autoencoders, unsupervised learning, and deep architectures,” Proc. ICML Workshop on Unsupervised and Transfer Learning, 2012, pp. 37–49
2012
-
[10]
L. Breiman, “Random forests,”Machine Learning, vol. 45, no. 1, pp. 5– 32, 2001. DOI: https://doi.org/10.1023/A:1010933404324
-
[11]
Permutation importance: a corrected feature importance measure,
A. Altmann, L. Tolo¸ si, O. Sander, and T. Lengauer, “Permutation importance: a corrected feature importance measure,”Bioinformatics, vol. 26, no. 10, pp. 1340–1347, 2010. DOI: https://doi.org/10.1093/ bioinformatics/btq134
2010
-
[12]
Smartwatch telemetry validation for physiological assessment in ambulatory environments,
J. Alemany et al., “Smartwatch telemetry validation for physiological assessment in ambulatory environments,”IEEE Sensors Journal, vol. 21, no. 14, pp. 15890–15901, 2021. DOI: https://doi.org/10.1109/JSEN. 2021.3072114
-
[13]
Monitoring training status with heart rate measures: do all roads lead to Rome?
M. Buchheit, “Monitoring training status with heart rate measures: do all roads lead to Rome?”Frontiers in Physiology, vol. 5, p. 73, 2014. DOI: https://doi.org/10.3389/fphys.2014.00073
-
[14]
Molnar,Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed., 2022
C. Molnar,Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed., 2022. URL: https://christophm.github. io/interpretable-ml-book/
2022
-
[15]
D. J. Plews, P. B. Laursen, A. E. Kilding, and M. Buchheit, “Heart rate variability in elite triathletes: is variation in variability the key to effective training? A case comparison,”European Journal of Applied Physiology, vol. 112, no. 11, pp. 3729–3741, 2012. DOI: https://doi. org/10.1007/s00421-011-2317-6
-
[16]
Efron and R
B. Efron and R. J. Tibshirani,An Introduction to the Bootstrap. New York, NY: Chapman and Hall/CRC, 1993. DOI: https://doi.org/10.1201/ 9780429246593
1993
-
[17]
The training-injury prevention paradox: should athletes be training smarter and harder?
T. J. Gabbett, “The training-injury prevention paradox: should athletes be training smarter and harder?”British Journal of Sports Medicine, vol. 50, no. 5, pp. 273–280, 2016. DOI: https://doi.org/10.1136/ bjsports-2015-095788
2016
-
[18]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. DOI: https://doi.org/ 10.1162/neco.1997.9.8.1735
-
[19]
E. E. Cust, A. J. Sweeting, K. Ball, and S. Robertson, “Machine and deep learning for sport-specific movement recognition: a systematic review of model development and performance,”Journal of Sports Sciences, vol. 37, no. 5, pp. 568–600, 2019. DOI: https://doi.org/10. 1080/02640414.2018.1521769
arXiv 2019
-
[20]
2009.The Elements of Statistical Learning: Data Mining, Inference, and Prediction(2 ed.)
T. Hastie, R. Tibshirani, and J. Friedman,The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. New York, NY: Springer, 2009. DOI: https://doi.org/10.1007/978-0-387-84858-7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.