An Introduction to Causal Reinforcement Learning
Pith reviewed 2026-06-26 00:16 UTC · model grok-4.3
The pith
Reinforcement learning environments implicitly encode structural causal models that unify online, off-policy, and counterfactual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
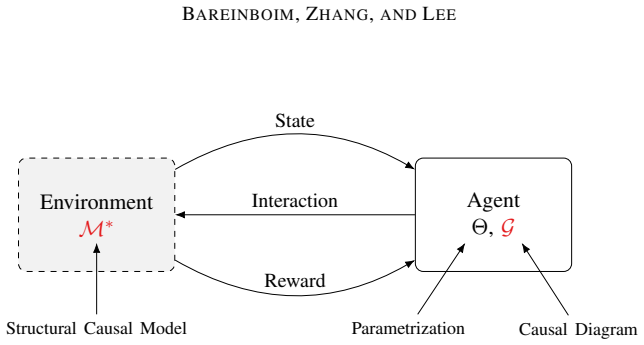
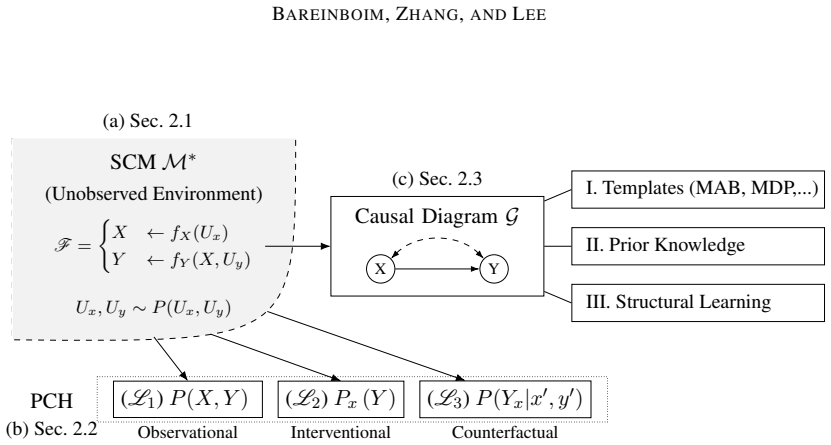
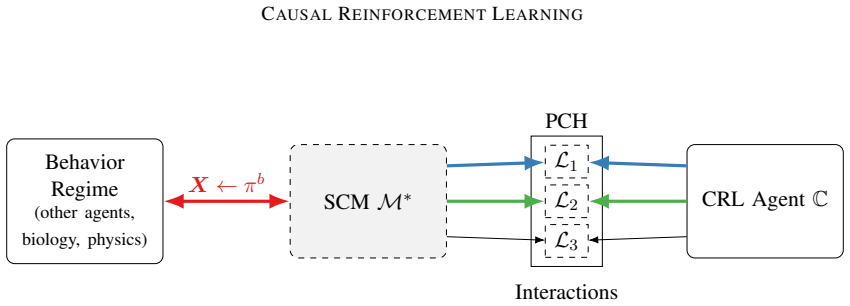
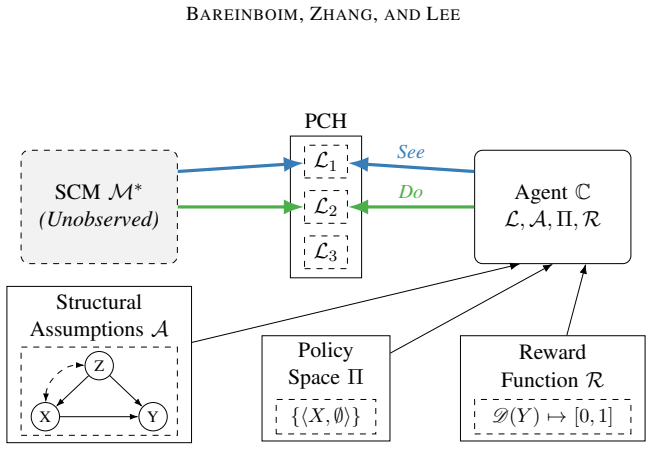
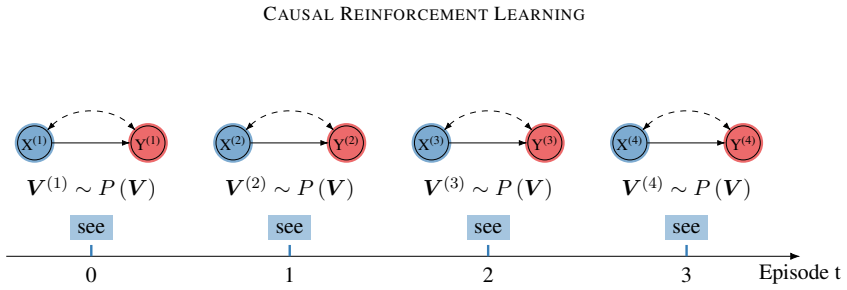
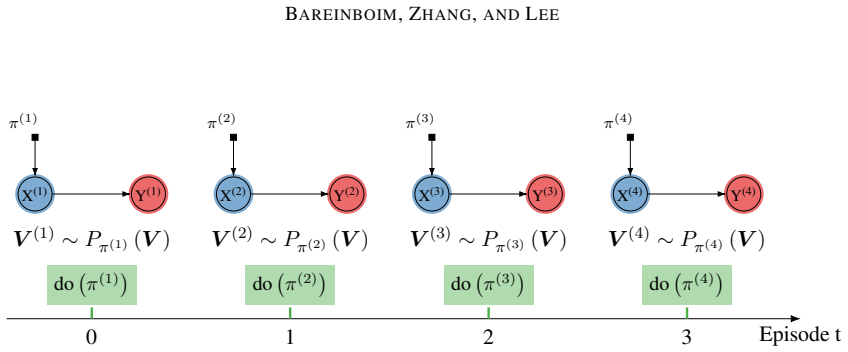
The paper states that any RL environment decomposes as a collection of autonomous mechanisms with different causal invariances, parsimoniously modeled as a structural causal model; every standard RL setting therefore implicitly encodes such a model. This formalization places online learning, off-policy learning, and causal-calculus learning under a single treatment and introduces generalized policy learning, imitation learning, and counterfactual learning as natural extensions.
What carries the argument
The structural causal model of the environment, which represents autonomous mechanisms and their causal invariances to enable joint analysis of different learning modes.
If this is right
- Online trial-and-error, reuse of logged data, and explicit counterfactual queries become instances of the same causal process.
- Policy learning extends to settings that require choosing where to intervene and how to imitate under causal constraints.
- Counterfactual learning becomes a well-defined task that reasons about outcomes under actions never taken.
- A broader view of counterfactual learning emerges that treats causal inference and reinforcement learning as two sides of the same structure.
Where Pith is reading between the lines
- Agents could be designed to maintain an explicit causal model of the environment and update it from both observed and hypothetical trajectories.
- Transfer across tasks may reduce to identifying which mechanisms remain invariant when the agent moves to a new environment.
- Standard regret bounds could be refined by separating the cost of learning mechanisms from the cost of learning their combination.
Load-bearing premise
Every standard reinforcement learning setting already encodes a structural causal model whose mechanisms can unify online, off-policy, and causal-calculus learning without further assumptions on what is observable or identifiable.
What would settle it
An RL environment in which the standard online or off-policy update rules cannot be recovered as special cases of operations on the implied causal mechanisms.
Figures
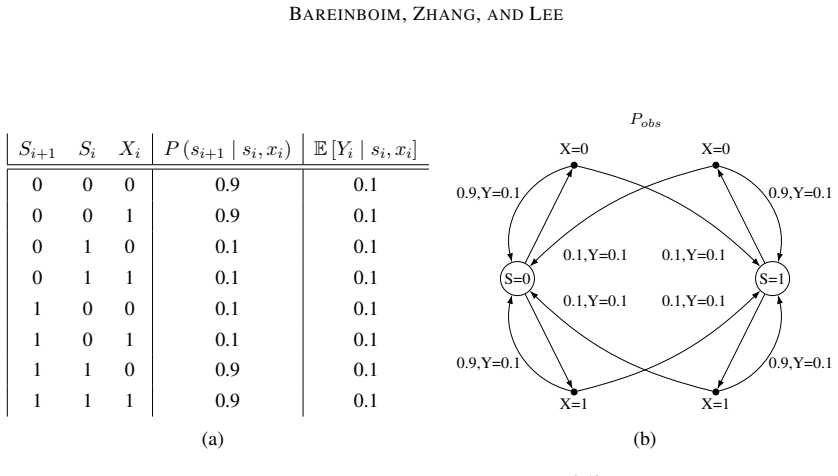
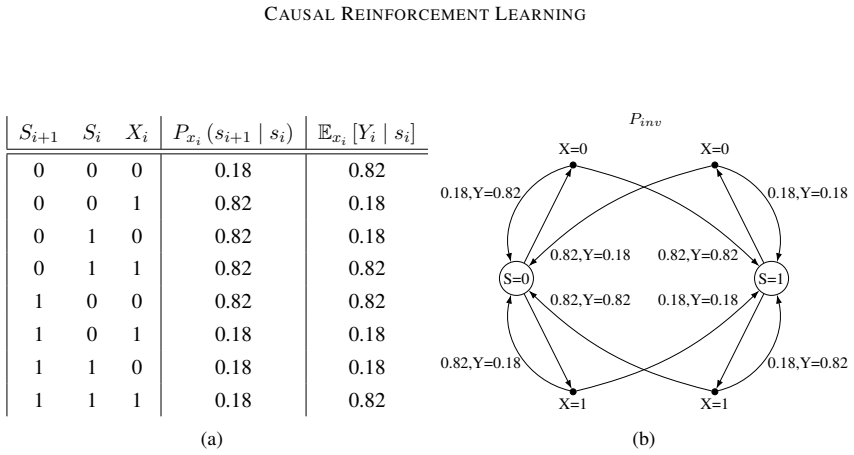

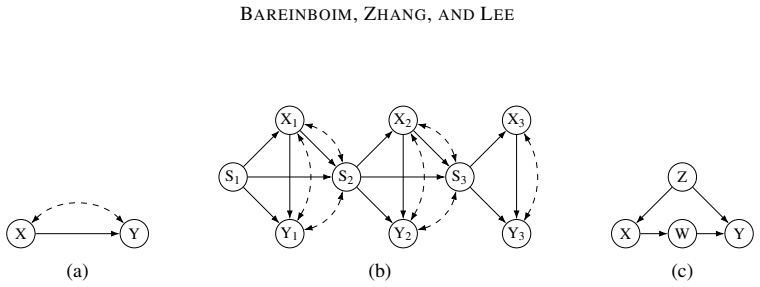

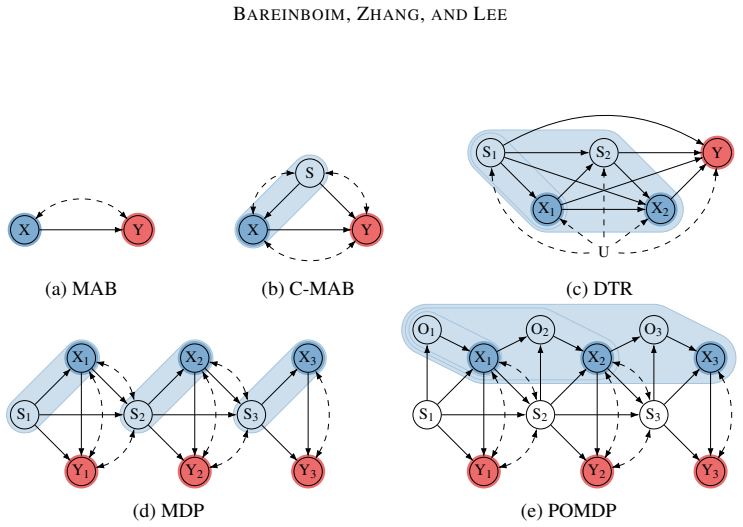
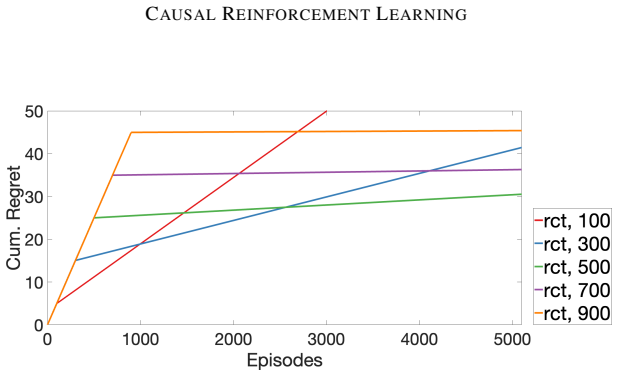
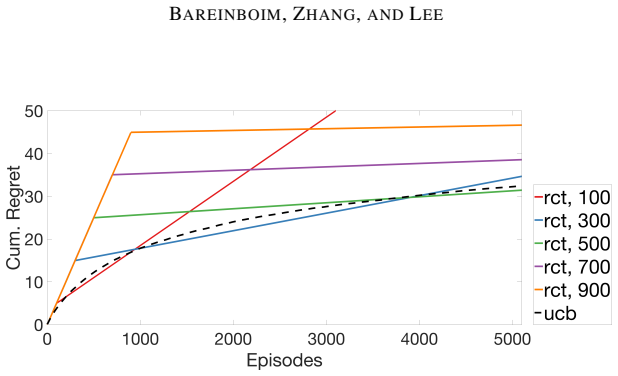
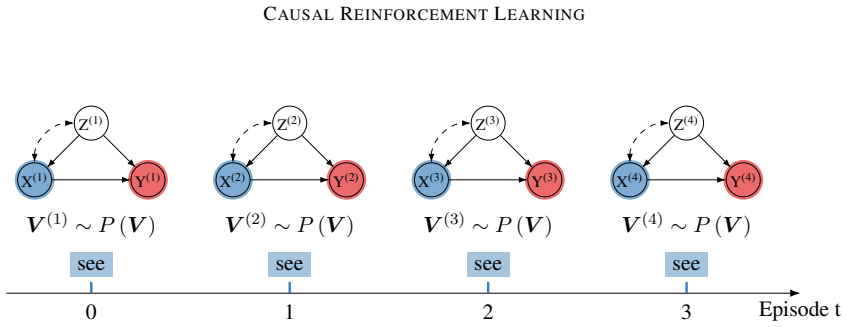
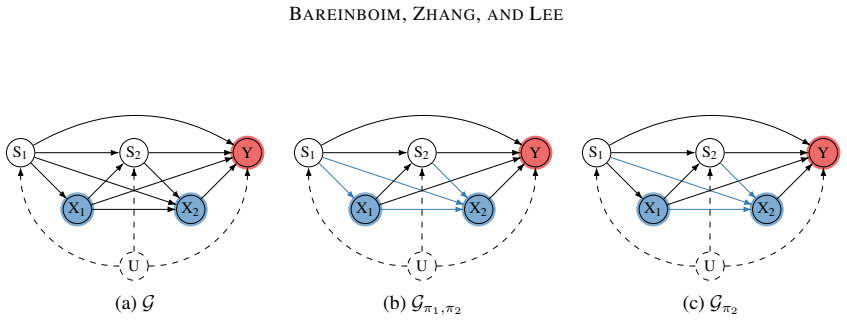
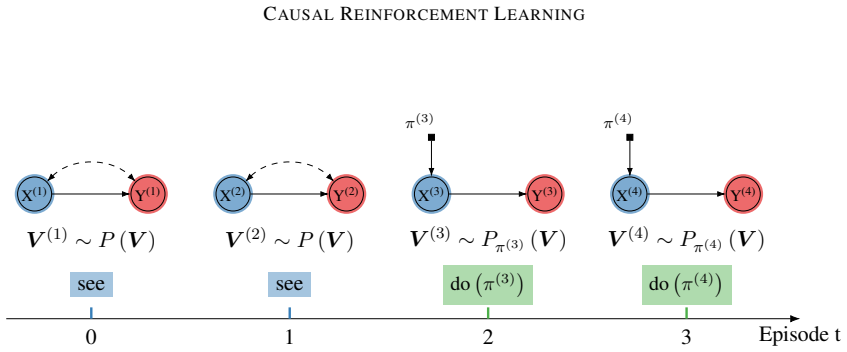
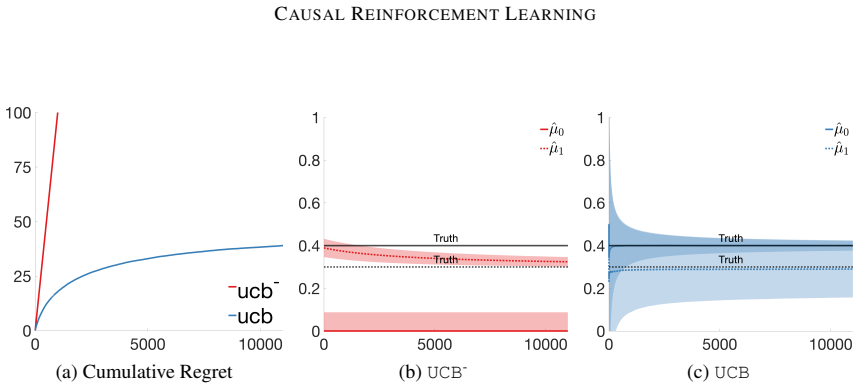
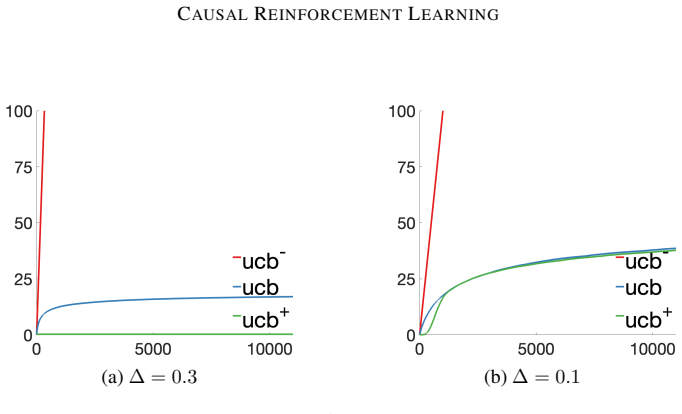
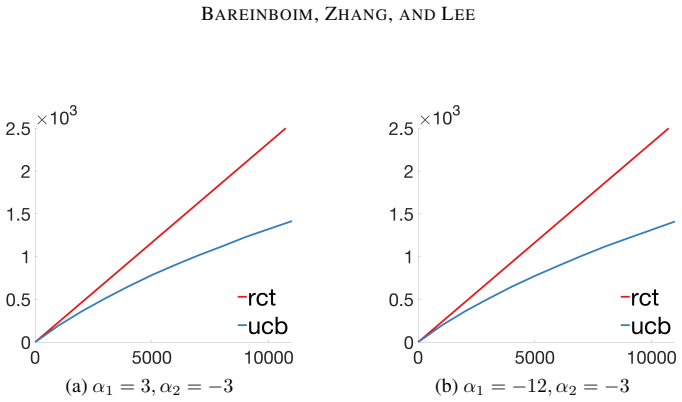
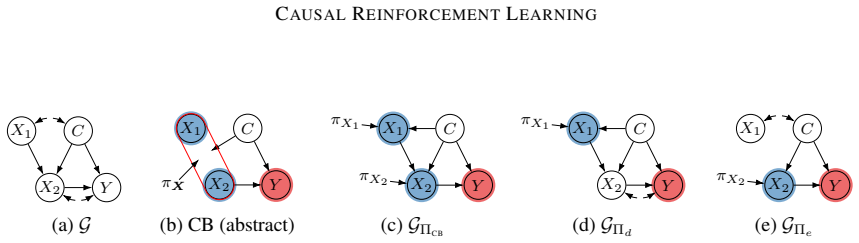

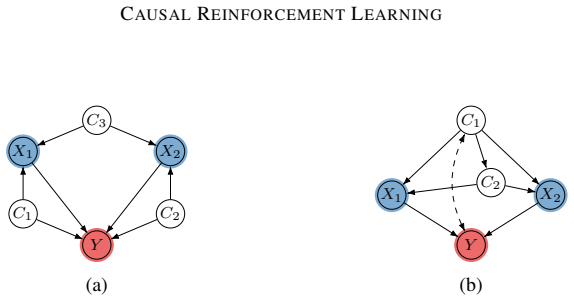
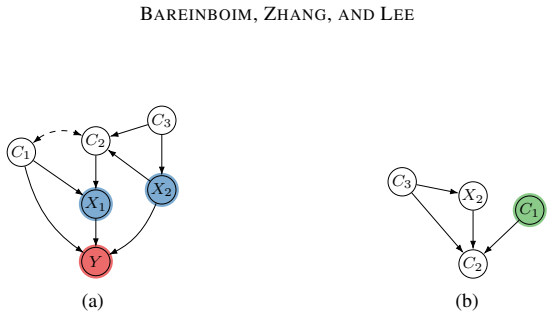

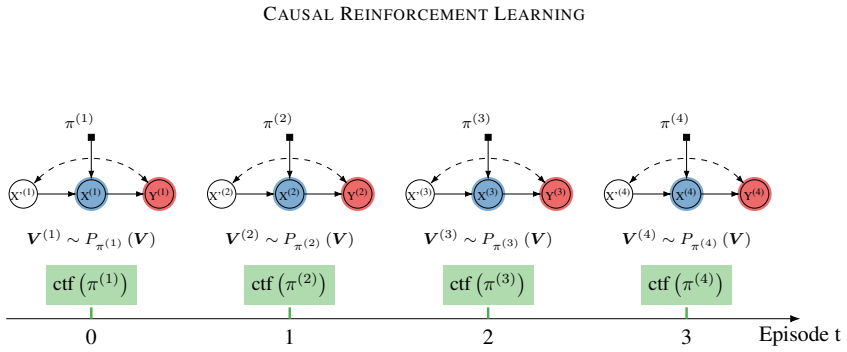

read the original abstract
Causal inference provides a set of principles and tools that allow one to combine data and knowledge about an environment to reason with questions of counterfactual nature, i.e., what would have happened had reality been different, even when no data of this unrealized reality is currently available. Reinforcement learning provides methods to learn a policy that optimizes a specific measure (e.g., reward, regret) when the agent is deployed in an environment and pursues an exploratory, trial-and-error approach. These two disciplines have evolved independently and with virtually no interaction between them. We note that they operate over different aspects of the same building block, counterfactual relations, which makes them umbilically connected. Based on these observations, novel learning opportunities arise when this connection is explicitly acknowledged and mathematized. To realize this potential, we note that any environment where the RL agent is deployed can be decomposed as a collection of autonomous mechanisms with different causal invariances, parsimoniously modeled as a structural causal model; any standard RL setting implicitly encodes such a model. This formalization allows us to put under a unifying treatment different modes of learning, including online, off-policy, and causal calculus learning, which appear unrelated in the literature. However, these modalities are not exhaustive: we introduce several natural and pervasive classes of learning settings that entail novel dimensions of analysis. Specifically, we introduce and discuss through causal lenses generalized policy learning, where to intervene, imitation learning, and counterfactual learning. These tasks lead to a broader view of counterfactual learning and suggest great potential for studying causal inference and reinforcement learning side by side, which we call causal reinforcement learning (CRL).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that any RL environment can be decomposed as a collection of autonomous mechanisms with different causal invariances and parsimoniously modeled as a structural causal model (SCM); any standard RL setting implicitly encodes such a model. This formalization unifies online, off-policy, and causal-calculus learning modes under one treatment. The authors further introduce and analyze through causal lenses several new task classes—generalized policy learning, intervention-based learning (where to intervene), imitation learning, and counterfactual learning—arguing that these open a broader view of counterfactual reasoning and motivate the joint study of causal inference and RL, termed causal reinforcement learning (CRL).
Significance. If the proposed modeling perspective is adopted, the work supplies a useful conceptual unification that makes explicit the shared counterfactual substrate of the two fields. By treating the SCM decomposition as a modeling lens rather than a derived theorem, the paper organizes existing RL modalities and surfaces new task dimensions that exploit causal invariances, providing a clear roadmap for future CRL research without requiring additional observability or identifiability assumptions beyond the framing itself.
minor comments (1)
- [Abstract] Abstract: the phrasing 'generalized policy learning, where to intervene, imitation learning, and counterfactual learning' leaves ambiguous whether 'where to intervene' denotes a distinct task or a sub-component of generalized policy learning; a brief clarifying clause would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript and the recommendation to accept. The review accurately captures the core contribution of framing RL environments as structural causal models to unify learning modalities and surface new task classes under the CRL lens.
Circularity Check
No significant circularity identified
full rationale
The manuscript is an explicit conceptual introduction that frames the decomposition of any RL environment into an SCM as a modeling perspective rather than a theorem or first-principles derivation. The unification of online, off-policy, and causal-calculus learning follows directly from adopting this framing by definition, with no claimed prediction, fitted parameter, or uniqueness result that reduces to its own inputs. No load-bearing self-citation chains or ansatzes smuggled via prior work appear in the argument; the central claim is presented as a choice of representation that enables the subsequent taxonomy, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any environment where the RL agent is deployed can be decomposed as a collection of autonomous mechanisms with different causal invariances, parsimoniously modeled as a structural causal model.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 34th AAAI Conference on Artificial Intelligence , year=
A Calculus for Stochastic Interventions: Causal Effect Identification and Surrogate Experiments , author =. Proceedings of the 34th AAAI Conference on Artificial Intelligence , year=
-
[2]
2020 , eprint=
Combining Observational and Experimental Datasets Using Shrinkage Estimators , author=. 2020 , eprint=
2020
-
[3]
and Bareinboim, E
Plecko, D. and Bareinboim, E. Causal Fairness Analysis. 2022
2022
-
[4]
ACM Transactions on Mathematical Software (TOMS) , volume=
Algorithm 883: Sparsepop---a sparse semidefinite programming relaxation of polynomial optimization problems , author=. ACM Transactions on Mathematical Software (TOMS) , volume=. 2008 , publisher=
2008
-
[5]
Management Science , volume=
A probabilistic production and inventory problem , author=. Management Science , volume=. 1963 , publisher=
1963
-
[6]
Trends in Cognitive Sciences , volume=
How Rich is Consciousness? The Partial Awareness Hypothesis , author=. Trends in Cognitive Sciences , volume=. 2010 , publisher=
2010
-
[7]
2013 , publisher=
A reformulation-linearization technique for solving discrete and continuous nonconvex problems , author=. 2013 , publisher=
2013
-
[8]
and Tian, J
Jung, Y. and Tian, J. and Bareinboim, E. Estimating Joint Treatment Effects by Combining Multiple Experiments. Proceedings of the 40th International Conference on Machine Learning. 2023
2023
-
[9]
MC Tracts , year=
Linear programming and finite Markovian control problems , author=. MC Tracts , year=
-
[10]
and Diaz, I
Jung, Y. and Diaz, I. and Tian, J. and Bareinboim, E. Estimating Causal Effects Identifiable from Combination of Observations and Experiments. 2023
2023
-
[11]
1998 , publisher=
Convex analysis and global optimization , author=. 1998 , publisher=
1998
-
[12]
2022 , publisher=
Introduction to algorithms , author=. 2022 , publisher=
2022
-
[13]
Mathematics of operations research , volume=
The complexity of Markov decision processes , author=. Mathematics of operations research , volume=. 1987 , publisher=
1987
-
[14]
Journal of Computer and System Sciences , volume=
An analysis of model-based interval estimation for Markov decision processes , author=. Journal of Computer and System Sciences , volume=. 2008 , publisher=
2008
-
[15]
SIAM Journal on Optimization , volume=
Global optimization with polynomials and the problem of moments , author=. SIAM Journal on Optimization , volume=. 2001 , publisher=
2001
-
[16]
JAMA internal medicine , volume=
Estimated costs of pivotal trials for novel therapeutic agents approved by the US Food and Drug Administration, 2015-2016 , author=. JAMA internal medicine , volume=. 2018 , publisher=
2015
-
[17]
Optimization methods and software , volume=
Using SeDuMi 1.02, a MATLAB toolbox for optimization over symmetric cones , author=. Optimization methods and software , volume=. 1999 , publisher=
1999
-
[18]
Journal of Machine Learning Research , volume=
Causal reasoning with ancestral graphs , author=. Journal of Machine Learning Research , volume=. 2008 , publisher=
2008
-
[19]
Science , volume=
Judgment under Uncertainty: Heuristics and Biases , author=. Science , volume=. 1974 , publisher=
1974
-
[20]
American Psychologist , volume=
The Unbearable Automaticity of Being , author=. American Psychologist , volume=. 1999 , publisher=
1999
-
[21]
Perspectives on Psychological Science , volume=
A Theory of Unconscious Thought , author=. Perspectives on Psychological Science , volume=. 2006 , publisher=
2006
-
[22]
On the application of probability theory to agricultural experiments
Neyman, J. On the application of probability theory to agricultural experiments. E ssay on principles. S ection 9. Statistical Science
-
[23]
1985 , journal =
Lai, Tze Leung and Robbins, Herbert , number =. 1985 , journal =
1985
-
[24]
Proceedings of the National Academy of Sciences , volume=
Causal inference and the data-fusion problem , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
2016
-
[25]
arXiv preprint arXiv:2304.02339 , year=
Many Data: Combine Experimental and Observational Data through a Power Likelihood , author=. arXiv preprint arXiv:2304.02339 , year=
-
[26]
2022 , publisher=
Robust Causal Inference Methods for Using Randomized Clinical Trial and Observational Study , author=. 2022 , publisher=
2022
-
[27]
Jama , volume=
Pharmacologic treatments for coronavirus disease 2019 (COVID-19): a review , author=. Jama , volume=. 2020 , publisher=
2019
-
[28]
arXiv preprint arXiv:2011.08047 , year=
Causal inference methods for combining randomized trials and observational studies: a review , author=. arXiv preprint arXiv:2011.08047 , year=
arXiv 2011
-
[29]
2008 , publisher=
Dataset shift in machine learning , author=. 2008 , publisher=
2008
-
[30]
Science , volume=
Structural basis for inhibition of the RNA-dependent RNA polymerase from SARS-CoV-2 by remdesivir , author=. Science , volume=. 2020 , publisher=
2020
-
[31]
New England Journal of Medicine , volume=
Remdesivir for 5 or 10 days in patients with severe Covid-19 , author=. New England Journal of Medicine , volume=. 2020 , publisher=
2020
-
[32]
, author=
Estimating causal effects of treatments in randomized and nonrandomized studies. , author=. Journal of educational Psychology , volume=. 1974 , publisher=
1974
-
[33]
2010 , publisher=
Artificial intelligence a modern approach , author=. 2010 , publisher=
2010
-
[34]
IEEE Spectrum , volume=
IBM Watson, heal thyself: How IBM overpromised and underdelivered on AI health care , author=. IEEE Spectrum , volume=. 2019 , publisher=
2019
-
[35]
arXiv preprint arXiv:1912.06680 , year=
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
Pith/arXiv arXiv 1912
-
[36]
The Eleventh International Conference on Learning Representations , year =
Causal Imitation Learning via Inverse Reinforcement Learning , author =. The Eleventh International Conference on Learning Representations , year =
-
[37]
Springer
Observational studies , author =. Springer. First citation in articleRosenbaum, PR, & Rubin, DB (1983). The central role of the propensity score in observational studies for causal effects. Biometrika , volume =
1983
-
[38]
Games and Economic Behavior , volume=
Adaptive game playing using multiplicative weights , author=. Games and Economic Behavior , volume=. 1999 , publisher=
1999
-
[39]
Conference on Robot Learning , pages =
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble , author =. Conference on Robot Learning , pages =. 2022 , organization =
2022
-
[40]
, author =
Experimental design and primary data analysis methods for comparing adaptive interventions. , author =. Psychological methods , volume =. 2012 , publisher =
2012
-
[41]
Bellman, Richard , publisher =
-
[42]
Uncertainty in Artificial Intelligence , pages=
Finding minimal d-separators in linear time and applications , author=. Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
2020
-
[43]
Journal of Machine Learning Research , volume =
Tree-based batch mode reinforcement learning , author =. Journal of Machine Learning Research , volume =. 2005 , publisher =
2005
-
[44]
Machine learning , volume =
Kernel-based reinforcement learning , author =. Machine learning , volume =. 2002 , publisher =
2002
-
[45]
, author=
Learning to Drive a Bicycle Using Reinforcement Learning and Shaping. , author=. ICML , volume=. 1998 , organization=
1998
-
[46]
Icml , volume=
Policy invariance under reward transformations: Theory and application to reward shaping , author=. Icml , volume=
-
[47]
Yang and Karthikeyan Shanmugam and Caroline Uhler , title=
Raj Agrawal and Chandler Squires and Karren D. Yang and Karthikeyan Shanmugam and Caroline Uhler , title=. 2019 , cdate=
2019
-
[48]
Mooij and Sara Magliacane and Tom Claassen , title =
Joris M. Mooij and Sara Magliacane and Tom Claassen , title =. Journal of Machine Learning Research , year =
-
[49]
Annual Review of Neuroscience , volume =
Rizzolatti, Giacomo and Craighero, Laila , title =. Annual Review of Neuroscience , volume =
-
[50]
Mirror neurons
Keysers, Christian , address =. Mirror neurons. , volume =. Current biology , lccn =
-
[51]
and Salehkaleybar, S
Ghassami, A. and Salehkaleybar, S. and Kiyavash, N. and Bareinboim, E. Budgeted Experiment Design for Causal Structure Learning. Proceedings of the 35th International Conference on Machine Learning. 2018
2018
-
[52]
Philip and Geneletti, Sara , title =
Didelez, Vanessa and Dawid, A. Philip and Geneletti, Sara , title =. Proceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence , pages =. 2006 , publisher =
2006
-
[53]
the great leap forward
Mirror neurons and imitation learning as the driving force behind "the great leap forward" in human evolution , author=
-
[54]
The New York Times, January 10 , author=
Cells that read minds. The New York Times, January 10 , author=
-
[55]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[56]
and Ribeiro, A
Anand, T. and Ribeiro, A. and Tian, J. and Bareinboim, E. Effect Identification in Causal Diagrams with Clustered Variables. 2021
2021
-
[57]
Journal of artificial intelligence research , volume=
Hierarchical reinforcement learning with the MAXQ value function decomposition , author=. Journal of artificial intelligence research , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
On explore-then-commit strategies , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Approximate planning in large POMDPs via reusable trajectories , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Brain , volume =
Gallese, Vittorio and Fadiga, Luciano and Fogassi, Leonardo and Rizzolatti, Giacomo , title = ". Brain , volume =. 1996 , month =
1996
-
[61]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[62]
arXiv preprint arXiv:1710.11248 , year=
Learning robust rewards with adversarial inverse reinforcement learning , author=. arXiv preprint arXiv:1710.11248 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Infogail: Interpretable imitation learning from visual demonstrations , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
International Conference on Machine Learning , pages=
Intrinsic reward driven imitation learning via generative model , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[65]
International Conference on Machine Learning , pages=
Sensitivity analysis of linear structural causal models , author=. International Conference on Machine Learning , pages=
-
[66]
Advances in Neural Information Processing Systems , volume=
General transportability of soft interventions: Completeness results , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
IJCAI , year=
From Statistical Transportability to Estimating the Effect of Stochastic Interventions , author=. IJCAI , year=
-
[68]
Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages=
Confounding-robust policy improvement , author=. Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages=
-
[69]
Journal of the American Statistical Association , volume=
Probability Inequalities for Sums of Bounded Random Variables , author=. Journal of the American Statistical Association , volume=
-
[70]
General Transportability of Soft Interventions: Completeness Results , url =
Correa, Juan and Bareinboim, Elias , booktitle =. General Transportability of Soft Interventions: Completeness Results , url =
-
[71]
Stabilizing Off-Policy
Kumar, Aviral and Fu, Justin and Tucker, George and Levine, Sergey , booktitle =. Stabilizing Off-Policy. 2019 , publisher =
2019
-
[72]
Advances in Neural Information Processing Systems , volume=
Characterizing Optimal Mixed Policies: Where to Intervene and What to Observe , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
and Bareinboim, E
Zhang, J. and Bareinboim, E. Can Humans Be Out of the Loop?. 2022
2022
-
[74]
Proceedings of the 36th International Conference on Machine Learning , pages =
Off-Policy Deep Reinforcement Learning without Exploration , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[75]
In Proceedings of the 35th Conference on Uncertainty in Artificial Intelligence , year=
Sanghack Lee and Juan David Correa and Elias Bareinboim , title=. In Proceedings of the 35th Conference on Uncertainty in Artificial Intelligence , year=
-
[76]
, title =
Quionero-Candela, Joaquin and Sugiyama, Masashi and Schwaighofer, Anton and Lawrence, Neil D. , title =. 2009 , isbn =
2009
-
[77]
Dawid, A. Philip and Didelez, Vanessa. Identifying the consequences of dynamic treatment strategies: A decision-theoretic overview. Statist. Surv. 2010. doi:10.1214/10-SS081
-
[78]
Cassel, Claes M. and S. Some results on generalized difference estimation and generalized regression estimation for finite populations. Biometrika , volume =. 1976 , month =
1976
-
[79]
2018 21st International Conference on Intelligent Transportation Systems (ITSC) , pages=
The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems , author=. 2018 21st International Conference on Intelligent Transportation Systems (ITSC) , pages=. 2018 , doi=
2018
-
[80]
Proceedings of the National Conference on Artificial Intelligence , volume=
Identification of joint interventional distributions in recursive semi-Markovian causal models , author=. Proceedings of the National Conference on Artificial Intelligence , volume=. 2006 , organization=
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.