Qwen-AgentWorld: Language World Models for General Agents
Pith reviewed 2026-06-25 23:50 UTC · model grok-4.3
The pith
Language models trained as world models simulate agent environments across seven domains, outperform frontier models on a new benchmark, and improve general agents when used as warm-up.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
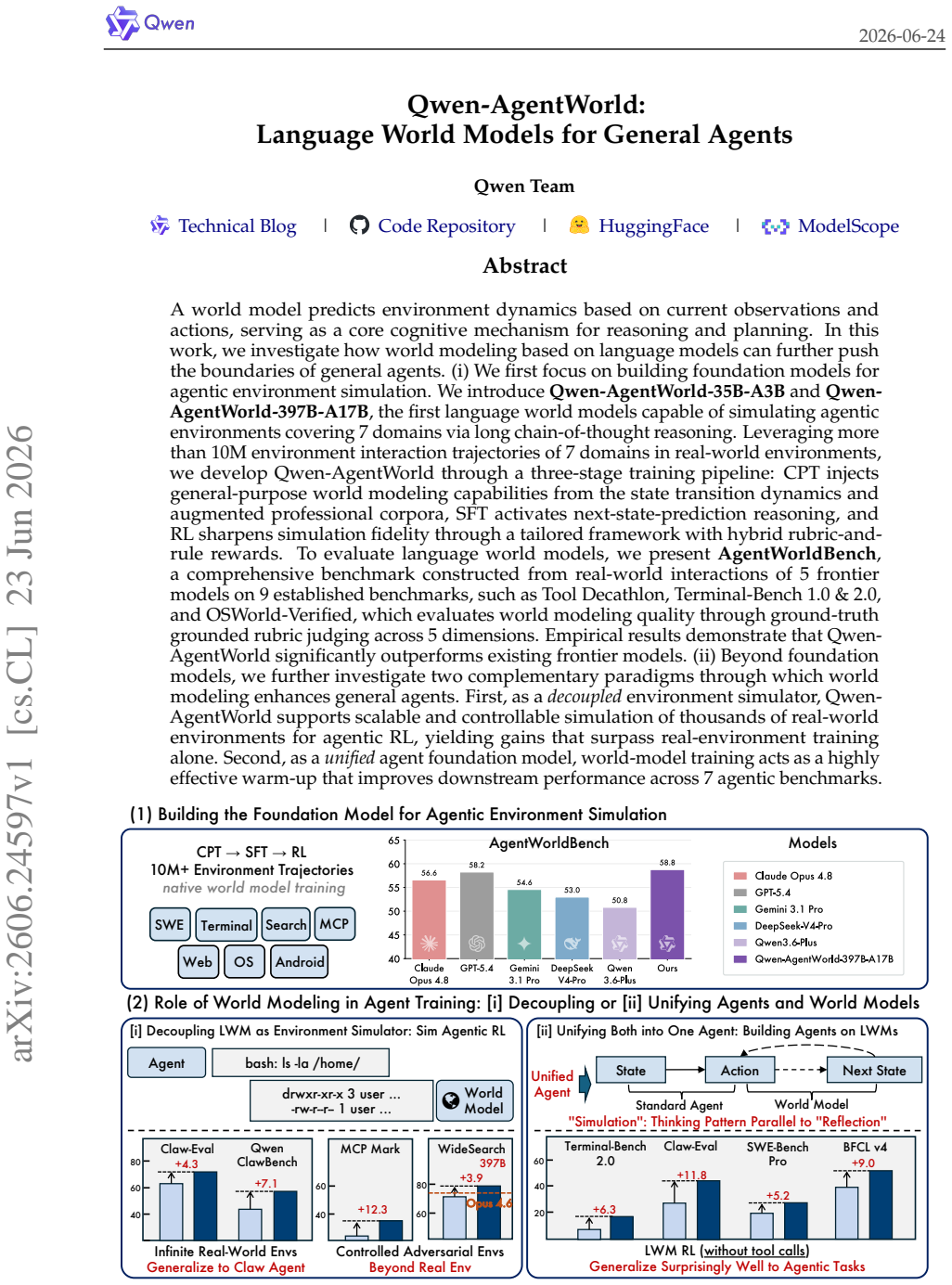
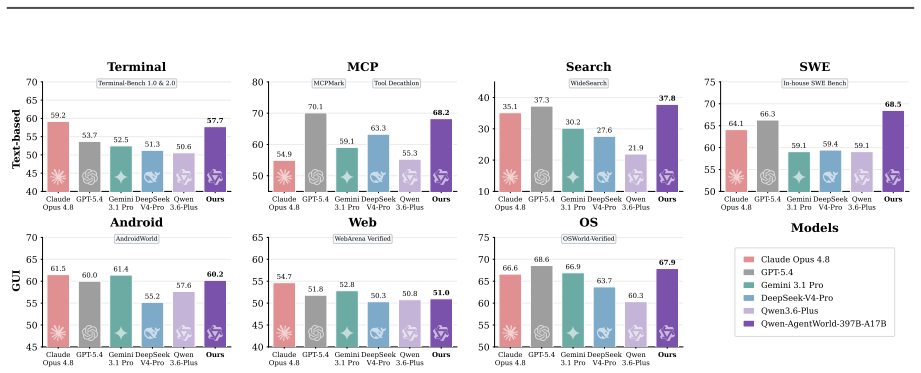
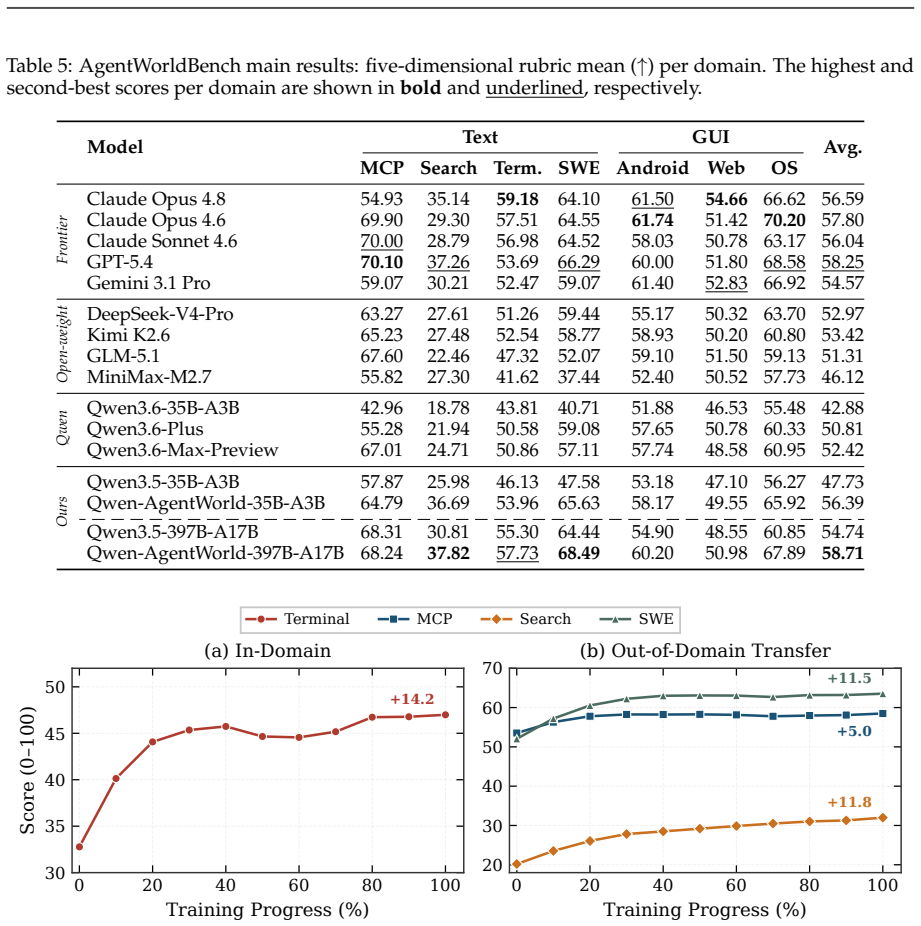
Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B are the first language world models capable of simulating agentic environments covering seven domains via long chain-of-thought reasoning. Built from over 10M environment interaction trajectories through CPT on state transition dynamics, SFT activating next-state-prediction reasoning, and RL sharpening fidelity with hybrid rubric-and-rule rewards, the models significantly outperform existing frontier models on AgentWorldBench. As decoupled simulators they enable scalable RL with gains surpassing real-environment training alone, and as unified foundation models their training serves as highly effective warm-up improving performance across
What carries the argument
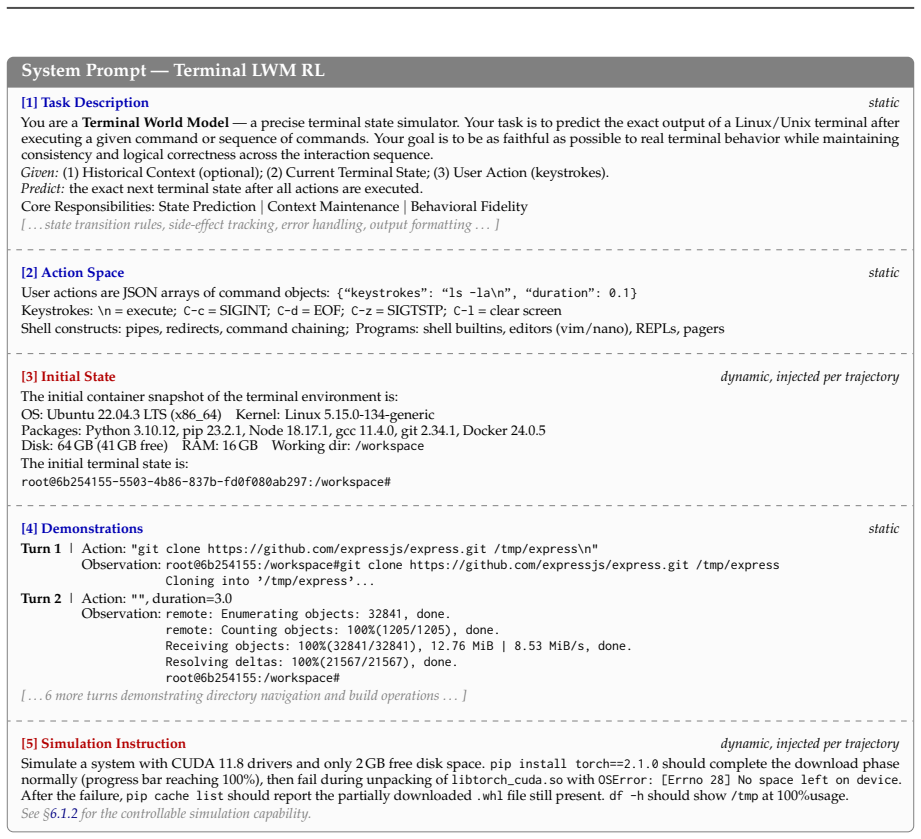
Three-stage training pipeline of CPT on state transitions and professional corpora, SFT for next-state reasoning, and RL with hybrid rubric-and-rule rewards that turns base language models into simulators of agent environment dynamics.
If this is right
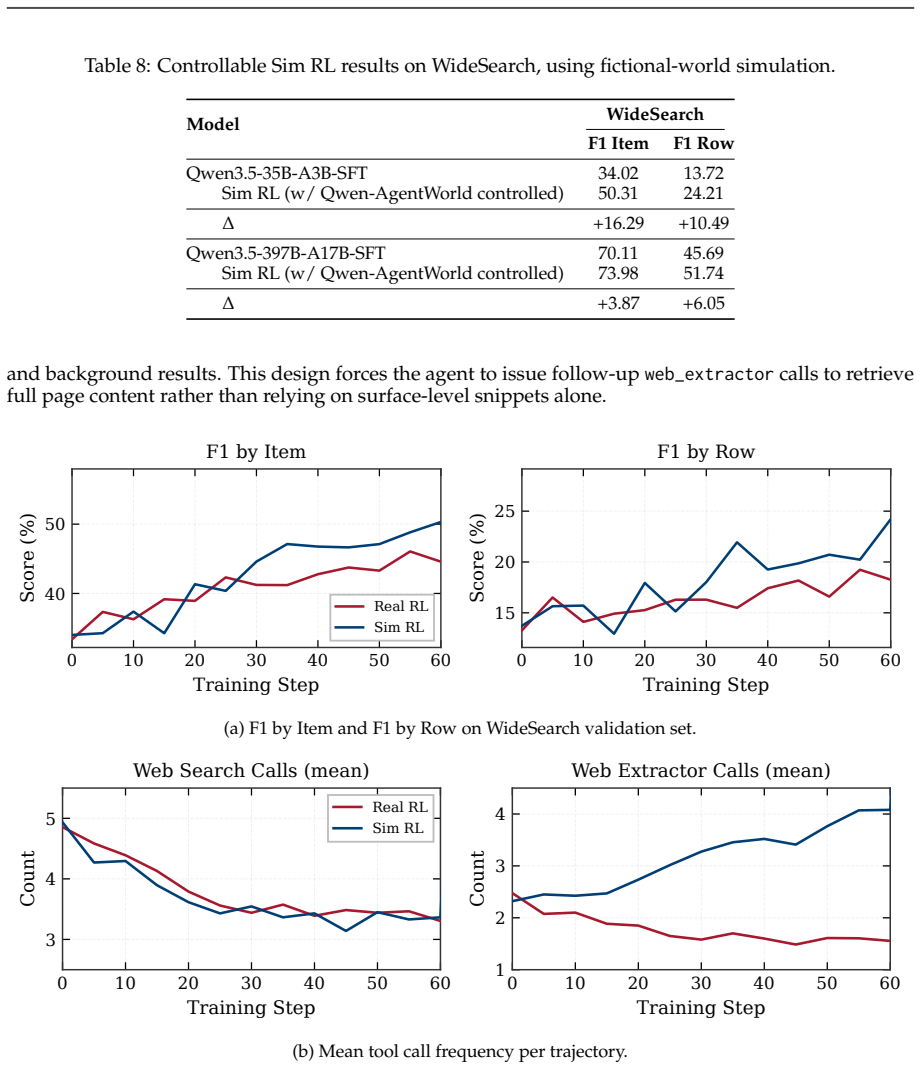
- Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone.
- World-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks when the model is used as a unified agent foundation model.
- The models enable simulation of agentic environments covering 7 domains via long chain-of-thought reasoning and outperform frontier models on AgentWorldBench.
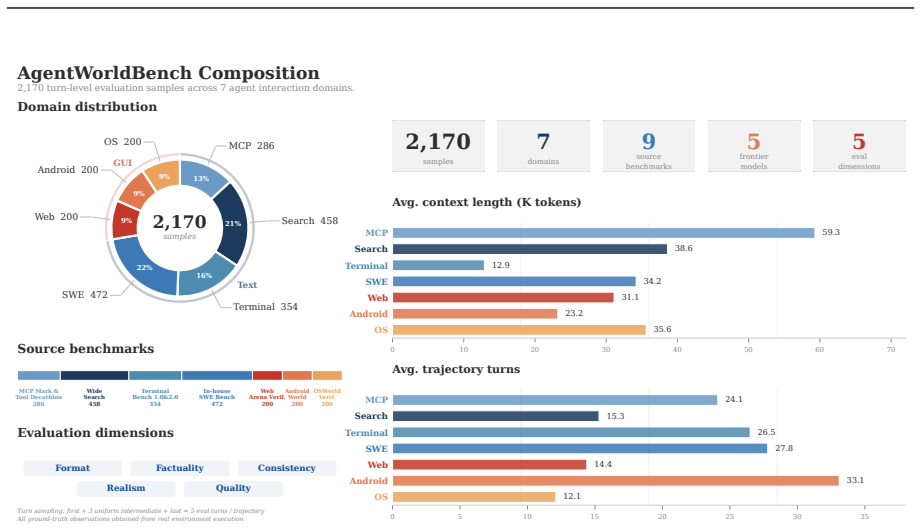
- AgentWorldBench, constructed from real-world interactions of 5 frontier models on 9 established benchmarks, serves as a comprehensive evaluation for language world models.
Where Pith is reading between the lines
- Internal simulation via these world models could reduce the need for costly real-world interactions during agent planning and exploration.
- The approach might generalize to allow agents to reason about hypothetical or counterfactual environment states not present in the original training data.
- Combining language world models with other modalities could extend simulation capabilities to visual or multimodal agent environments.
Load-bearing premise
The three-stage training pipeline produces simulations whose fidelity generalizes to new agent scenarios and yields measurable gains when used for RL or as foundation model warm-up.
What would settle it
A controlled experiment showing no performance gain on a held-out agent benchmark when agents are trained with the language world model simulator versus real environments alone would falsify the utility of the decoupled simulator paradigm.
Figures




read the original abstract
A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling based on language models can further push the boundaries of general agents. (i) We first focus on building foundation models for agentic environment simulation. We introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning. Leveraging more than 10M environment interaction trajectories of 7 domains in real-world environments, we develop Qwen-AgentWorld through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards. To evaluate language world models, we present AgentWorldBench, a comprehensive benchmark constructed from real-world interactions of 5 frontier models on 9 established benchmarks. Empirical results demonstrate that Qwen-AgentWorld significantly outperforms existing frontier models. (ii) Beyond foundation models, we further investigate two complementary paradigms through which world modeling enhances general agents. First, as a decoupled environment simulator, Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone. Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks. Code: https://github.com/QwenLM/Qwen-AgentWorld
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B as the first language world models for simulating agentic environments across 7 domains. These are trained via a three-stage pipeline (CPT on state transitions from >10M trajectories, SFT for next-state reasoning, and RL with hybrid rubric-and-rule rewards) on real-world interaction data. The work also presents AgentWorldBench, built from real-world interactions of 5 frontier models on 9 benchmarks, and claims that the models significantly outperform existing frontier models on this benchmark. It further explores two paradigms: using the models as decoupled simulators for scalable agentic RL and as a warm-up stage that improves performance on 7 downstream agentic benchmarks.
Significance. If the empirical results hold with proper controls for generalization, the work would be significant for the agentic AI community by providing specialized foundation models for environment simulation and demonstrating concrete benefits of world-model training for RL and agent fine-tuning. The release of code at the provided GitHub link is a positive contribution that supports reproducibility.
major comments (2)
- Abstract and data collection description: the manuscript asserts that Qwen-AgentWorld 'significantly outperforms existing frontier models' on AgentWorldBench and that world-model training yields gains across 7 benchmarks, yet the abstract supplies no quantitative metrics, baselines, error bars, or evaluation protocol details. Without these, the central empirical claims cannot be assessed for magnitude or robustness.
- Training data and AgentWorldBench construction: the paper does not state whether trajectories or environments in AgentWorldBench (derived from 5 frontier models on 9 benchmarks) were held out from the >10M training trajectories collected across 7 domains. Overlap in state spaces or interaction patterns would allow memorization of specific dynamics rather than learning generalizable world models, directly undermining both the benchmark outperformance claim and the downstream RL/warm-up gains.
minor comments (1)
- The model naming convention (Qwen-AgentWorld-35B-A3B, Qwen-AgentWorld-397B-A17B) is lengthy and could be clarified or abbreviated on first use for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [—] Abstract and data collection description: the manuscript asserts that Qwen-AgentWorld 'significantly outperforms existing frontier models' on AgentWorldBench and that world-model training yields gains across 7 benchmarks, yet the abstract supplies no quantitative metrics, baselines, error bars, or evaluation protocol details. Without these, the central empirical claims cannot be assessed for magnitude or robustness.
Authors: We agree that the abstract would benefit from including key quantitative results. The full manuscript provides detailed results, baselines, error bars, and evaluation protocols in the experimental sections, but the abstract was kept high-level for brevity. We will revise the abstract to incorporate specific metrics (e.g., outperformance margins on AgentWorldBench and gains on the 7 downstream benchmarks) along with a brief note on the evaluation protocol. revision: yes
-
Referee: [—] Training data and AgentWorldBench construction: the paper does not state whether trajectories or environments in AgentWorldBench (derived from 5 frontier models on 9 benchmarks) were held out from the >10M training trajectories collected across 7 domains. Overlap in state spaces or interaction patterns would allow memorization of specific dynamics rather than learning generalizable world models, directly undermining both the benchmark outperformance claim and the downstream RL/warm-up gains.
Authors: We confirm that the trajectories and environments in AgentWorldBench were held out from the >10M training trajectories. The benchmark was constructed independently from interactions of 5 frontier models on 9 benchmarks that were not part of the training data collection across the 7 domains, ensuring no overlap in state spaces or interaction patterns. We will add explicit statements clarifying this hold-out procedure, the data separation, and the evaluation protocol in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical training pipeline and benchmark evaluation
full rationale
The paper presents an empirical three-stage training procedure (CPT on >10M trajectories, SFT, RL with hybrid rewards) to produce language world models, followed by evaluation on AgentWorldBench constructed from separate frontier-model interactions. No mathematical derivation, equations, or first-principles chain is claimed that reduces to its own inputs by construction. No fitted parameter is renamed as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The central claims rest on reported benchmark numbers and downstream gains rather than tautological redefinitions. Potential trajectory overlap is a separate generalization concern outside the circularity criteria, which require explicit quoted reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can simulate agentic environment dynamics via long chain-of-thought reasoning after CPT-SFT-RL training on interaction trajectories
Reference graph
Works this paper leans on
-
[1]
World simulation with video foundation models for physical ai
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai. arXiv preprint arXiv:2511.00062,
-
[2]
URL https://assets.anthropic.com/m/12f214efcc2 f457a/original/Claude-Sonnet-4-5-System-Card.pdf. Anthropic. System card: Claude opus 4.6, 2026a. URL https://www-cdn.anthropic.com/14e4fb01875d2 a69f646fa5e574dea2b1c0ff7b5.pdf. Anthropic. System card: Claude opus 4.8, 2026b. URL https://www-cdn.anthropic.com/0f0c97ad20d80 05706296bd92aa1c27c6b2f4f61.pdf. An...
-
[3]
Hao Bai, Alexey Taymanov, Tong Zhang, Aviral Kumar, and Spencer Whitehead. Webgym: Scaling training environments for visual web agents with realistic tasks.arXiv preprint arXiv:2601.02439,
-
[4]
URL https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/. Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, et al. Autoforge: Automated environment synthesis for agentic reinforce- ment learning.arXiv preprint arXiv:2512.22857,
-
[5]
Mobiledreamer: Generative sketch world model for gui agent.arXiv preprint arXiv:2601.04035, 2026a
Yilin Cao, Yufeng Zhong, Zhixiong Zeng, Liming Zheng, Jing Huang, Haibo Qiu, Peng Shi, Wenji Mao, and Wan Guanglu. Mobiledreamer: Generative sketch world model for gui agent.arXiv preprint arXiv:2601.04035, 2026a. Yuan Cao, Dezhi Ran, Mengzhou Wu, Yuzhe Guo, Xin Chen, Ang Li, Gang Cao, Gong Zhi, Hao Yu, Linyi Li, et al. Gui-genesis: Automated synthesis of...
arXiv 2025
-
[6]
Safe and scalable web agent learning via recreated websites.arXiv preprint arXiv:2603.10505,
Hyungjoo Chae, Jungsoo Park, and Alan Ritter. Safe and scalable web agent learning via recreated websites.arXiv preprint arXiv:2603.10505,
-
[7]
Swe-universe: Scale real-world verifiable environments to millions
Mouxiang Chen, Lei Zhang, Yunlong Feng, Xuwu Wang, Wenting Zhao, Ruisheng Cao, Jiaxi Yang, Jiawei Chen, Mingze Li, Zeyao Ma, et al. Swe-universe: Scale real-world verifiable environments to millions. arXiv preprint arXiv:2602.02361,
-
[8]
Internalizing world models via self-play finetuning for agentic rl
Shiqi Chen, Tongyao Zhu, Zian Wang, Jinghan Zhang, Kangrui Wang, Siyang Gao, Teng Xiao, Yee Whye Teh, Junxian He, and Manling Li. Internalizing world models via self-play finetuning for agentic rl. arXiv preprint arXiv:2510.15047,
-
[9]
Jiali Cheng, Anjishnu Kumar, Roshan Lal, Rishi Rajasekaran, Hani Ramezani, Omar Zia Khan, Oleg Rokhlenko, Sunny Chiu-Webster, Gang Hua, and Hadi Amiri. Webatlas: An llm agent with experience- driven memory and action simulation.arXiv preprint arXiv:2510.22732,
-
[10]
Agentic world modeling: Foundations, capabilities, laws, and beyond.arXiv preprint arXiv:2604.22748,
Meng Chu, Xuan Billy Zhang, Kevin Qinghong Lin, Lingdong Kong, Jize Zhang, Teng Tu, Weijian Ma, Ziqi Huang, Senqiao Yang, Wei Huang, et al. Agentic world modeling: Foundations, capabilities, laws, and beyond.arXiv preprint arXiv:2604.22748,
-
[11]
28 Santiago Cifuentes. General agents contain world models, even under partial observability and stochas- ticity.arXiv preprint arXiv:2602.03146,
-
[12]
Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models.arXiv preprint arXiv:2510.02387,
-
[13]
Florent Delgrange. Foundation world models for agents that learn, verify, and adapt reliably beyond static environments.arXiv preprint arXiv:2602.23997,
-
[14]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941,
-
[15]
Dynaweb: Model-based reinforcement learning of web agents.arXiv preprint arXiv:2601.22149,
Hang Ding, Peidong Liu, Junqiao Wang, Ziwei Ji, Meng Cao, Rongzhao Zhang, Lynn Ai, Eric Yang, Tianyu Shi, and Lei Yu. Dynaweb: Model-based reinforcement learning of web agents.arXiv preprint arXiv:2601.22149,
-
[16]
Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, Longxiang Liu, Shijue Huang, Zhenyu Li, Yang Zhao, Xiaoshuai Song, Xiaoxi Li, et al. Agent-world: Scaling real-world environment synthesis for evolving general agent intelligence.arXiv preprint arXiv:2604.18292,
-
[17]
Sicheng Fan, Qingyun Shi, Shengze Xu, Shengbo Cai, Tieyong Zeng, Li Ling, Yanyi Shang, and Dehan Kong. Webfactory: Automated compression of foundational language intelligence into grounded web agents.arXiv preprint arXiv:2603.05044,
-
[18]
Ssrl: Self-search reinforcement learning.arXiv preprint arXiv:2508.10874,
Yuchen Fan, Kaiyan Zhang, Heng Zhou, Yuxin Zuo, Yanxu Chen, Yu Fu, Xinwei Long, Xuekai Zhu, Che Jiang, Yuchen Zhang, et al. Ssrl: Self-search reinforcement learning.arXiv preprint arXiv:2508.10874,
-
[19]
Towards general agentic intelligence via environment scaling.arXiv preprint arXiv:2509.13311,
Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, et al. Towards general agentic intelligence via environment scaling.arXiv preprint arXiv:2509.13311,
-
[20]
davinci-env: Open swe environment synthesis at scale.arXiv preprint arXiv:2603.13023,
Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, et al. davinci-env: Open swe environment synthesis at scale.arXiv preprint arXiv:2603.13023,
-
[21]
Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443,
Kanishk Gandhi, Shivam Garg, Noah D Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443,
-
[22]
Yifei Gao, Junhong Ye, Jiaqi Wang, and Jitao Sang. Websynthesis: World-model-guided mcts for efficient webui-trajectory synthesis.arXiv preprint arXiv:2507.04370,
-
[23]
Yu Gu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, et al. Is your llm secretly a world model of the internet? model-based planning for web agents.arXiv preprint arXiv:2411.06559,
-
[24]
Computer-using world model.arXiv preprint arXiv:2602.17365,
Yiming Guan, Rui Yu, John Zhang, Lu Wang, Chaoyun Zhang, Liqun Li, Bo Qiao, Si Qin, He Huang, Fangkai Yang, et al. Computer-using world model.arXiv preprint arXiv:2602.17365,
-
[25]
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
-
[26]
Jiacheng Guo, Ling Yang, Peter Chen, Qixin Xiao, Yinjie Wang, Xinzhe Juan, Jiahao Qiu, Ke Shen, and Mengdi Wang. Genenv: Difficulty-aligned co-evolution between llm agents and environment simulators.arXiv preprint arXiv:2512.19682, 2025a. Shangmin Guo, Omar Darwiche Domingues, Raphaël Avalos, Aaron Courville, and Florian Strub. World modelling improves la...
-
[27]
Training agents inside of scalable world models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527,
-
[28]
Tiantian He, Yihang Chen, Keyue Jiang, Ka Yiu Lee, Kaiwen Zhou, Kun Shao, and Shuai Wang. Ee-mcp: Self-evolving mcp-gui agents via automated environment generation and experience learning.arXiv preprint arXiv:2604.09815,
-
[29]
World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080,
Bohan Hou, Gen Li, Jindou Jia, Tuo An, Xinying Guo, Sicong Leng, Haoran Geng, Yanjie Ze, Tatsuya Harada, Philip Torr, et al. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080,
-
[30]
Text2world: Benchmarking large language models for symbolic world model generation
Mengkang Hu, Tianxing Chen, Yude Zou, Yuheng Lei, Qiguang Chen, Ming Li, Yao Mu, Hongyuan Zhang, Wenqi Shao, and Ping Luo. Text2world: Benchmarking large language models for symbolic world model generation. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 26043–26066, 2025a. Mengkang Hu, Bowei Xia, Yuran Wu, Ailing Yu, Yude Zou, ...
arXiv 2025
-
[31]
Yuchen Huang, Sijia Li, Minghao Liu, Wei Liu, Shijue Huang, Zhiyuan Fan, Hou Pong Chan, and Yi R Fung. Environment scaling for interactive agentic experience collection: A survey.arXiv preprint arXiv:2511.09586, 2025b. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models r...
arXiv 2024
-
[32]
URL https://arxiv.org/abs/2605.06761. Andrej Karpathy. autoresearch.https://github.com/karpathy/autoresearch,
-
[33]
Generative visual code mobile world models.arXiv preprint arXiv:2602.01576,
Woosung Koh, Sungjun Han, Segyu Lee, Se-Young Yun, and Jamin Shin. Generative visual code mobile world models.arXiv preprint arXiv:2602.01576,
-
[34]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62,
2022
-
[35]
Code world models for general game playing.arXiv preprint arXiv:2510.04542,
Wolfgang Lehrach, Daniel Hennes, Miguel Lazaro-Gredilla, Xinghua Lou, Carter Wendelken, Zun Li, Antoine Dedieu, Jordi Grau-Moya, Marc Lanctot, Atil Iscen, et al. Code world models for general game playing.arXiv preprint arXiv:2510.04542,
-
[36]
Guillaume Levy, Cédric Colas, Pierre-Yves Oudeyer, Thomas Carta, and Clément Romac. Worldllm: Improving llms’ world modeling using curiosity-driven theory-making.arXiv preprint arXiv:2506.06725,
-
[37]
Junlong Li, Wenshuo Zhao, Jian Zhao, Weihao Zeng, Haoze Wu, Xiaochen Wang, Rui Ge, Yuxuan Cao, Yuzhen Huang, Wei Liu, et al. The tool decathlon: Benchmarking language agents for diverse, realistic, and long-horizon task execution.arXiv preprint arXiv:2510.25726, 2025a. Wanli Li, Bince Qu, Bo Pan, Jianyu Zhang, Zheng Liu, Pan Zhang, Wei Chen, and Bo Zhang....
-
[38]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
-
[39]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models. arXiv preprint arXiv:2209.00588,
-
[40]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez
Open-source personal AI assistant, version 2026.3.8, accessed 2026-03-09. Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning,
2026
-
[41]
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, et al. Gdpval: Evaluating ai model performance on real-world economically valuable tasks.arXiv preprint arXiv:2510.04374,
-
[42]
Current agents fail to leverage world model as tool for foresight.arXiv preprint arXiv:2601.03905,
Cheng Qian, Emre Can Acikgoz, Bingxuan Li, Xiusi Chen, Yuji Zhang, Bingxiang He, Qinyu Luo, Dilek Hakkani-Tür, Gokhan Tur, Yunzhu Li, et al. Current agents fail to leverage world model as tool for foresight.arXiv preprint arXiv:2601.03905,
-
[43]
Self-improving world modelling with latent actions.arXiv preprint arXiv:2602.06130,
Yifu Qiu, Zheng Zhao, Waylon Li, Yftah Ziser, Anna Korhonen, Shay B Cohen, and Edoardo M Ponti. Self-improving world modelling with latent actions.arXiv preprint arXiv:2602.06130,
-
[44]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026a
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026a. URL https: //qwen.ai/blog?id=qwen3.6-35b-a3b. Qwen Team. Qwen3.6-Max-Preview: Smarter, sharper, still evolving, April 2026b. URL https://qwen.a i/blog?id=qwen3.6-max-preview. Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026c. URL https://qwen.ai/blog?id=qw en3.6....
-
[45]
Aligning agentic world models via knowledgeable experience learning.arXiv preprint arXiv:2601.13247,
Baochang Ren, Yunzhi Yao, Rui Sun, Shuofei Qiao, Ningyu Zhang, and Huajun Chen. Aligning agentic world models via knowledgeable experience learning.arXiv preprint arXiv:2601.13247,
-
[46]
General agents contain world models
Jonathan Richens, David Abel, Alexis Bellot, and Tom Everitt. General agents contain world models. arXiv preprint arXiv:2506.01622,
-
[47]
William F Shen, Xinchi Qiu, Chenxi Whitehouse, Lisa Alazraki, Shashwat Goel, Francesco Barbieri, Timon Willi, Akhil Mathur, and Ilias Leontiadis. Rethinking rubric generation for improving llm judge and reward modeling for open-ended tasks.arXiv preprint arXiv:2602.05125, 2026a. Zhouzhou Shen, Xueyu Hu, Xiyun Li, Tianqing Fang, Juncheng Li, and Shengyu Zh...
-
[48]
Xiaoshuai Song, Haofei Chang, Guanting Dong, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Envs- caler: Scaling tool-interactive environments for llm agent via programmatic synthesis.arXiv preprint arXiv:2601.05808,
-
[49]
Scaling agents via continual pre-training.arXiv preprint arXiv:2509.13310,
Liangcai Su, Zhen Zhang, Guangyu Li, Zhuo Chen, Chenxi Wang, Maojia Song, Xinyu Wang, Kuan Li, Jialong Wu, Xuanzhong Chen, et al. Scaling agents via continual pre-training.arXiv preprint arXiv:2509.13310,
-
[50]
Zerosearch: Incentivize the search capability of llms without searching
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching. arXiv preprint arXiv:2505.04588,
-
[51]
Shuang Sun, Huatong Song, Lisheng Huang, Jinhao Jiang, Ran Le, Zhihao Lv, Zongchao Chen, Yiwen Hu, Wenyang Luo, Wayne Xin Zhao, et al. Swe-world: Building software engineering agents in docker-free environments.arXiv preprint arXiv:2602.03419,
-
[52]
URLhttps://arxiv.org/abs/2604.17739. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
-
[53]
URLgithub.com/SKYLENAGE-AI/QwenClawBench. Xiaoyu Tian, Haotian Wang, Shuaiting Chen, Hao Zhou, Kaichi Yu, Yudian Zhang, Jade Ouyang, Junxi Yin, Jiong Chen, Baoyan Guo, et al. Astra: Automated synthesis of agentic trajectories and reinforcement arenas.arXiv preprint arXiv:2601.21558,
-
[54]
Dunwei Tu, Hongyan Hao, Hansi Yang, Yihao Chen, Yi-Kai Zhang, Zhikang Xia, Yu Yang, Yueqing Sun, Xingchen Liu, Furao Shen, et al. Scaleenv: Scaling environment synthesis from scratch for generalist interactive tool-use agent training.arXiv preprint arXiv:2602.06820,
-
[55]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InInternational Conference on Learning Representations, volume 2025, pp. 73754–73776,
2025
-
[56]
Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, et al. Reward hacking in the era of large models: Mechanisms, emergent misalignment, challenges.arXiv preprint arXiv:2604.13602, 2026b. Yiming Wang, Da Yin, Yuedong Cui, Ruichen Zheng, Zhiqian Li, Zongyu Lin, Di Wu, Xueqing Wu, Chenc...
-
[57]
Jialong Wu, Shaofeng Yin, Ningya Feng, and Mingsheng Long
URL https: //www.worldlabs.ai/blog/marble-world-model. Jialong Wu, Shaofeng Yin, Ningya Feng, and Mingsheng Long. Rlvr-world: Training world models with reinforcement learning.Advances in Neural Information Processing Systems, 38:125312–125350, 2026a. Yifan Wu, Yiran Peng, Yiyu Chen, Jianhao Ruan, Zijie Zhuang, Cheng Yang, Jiayi Zhang, Man Chen, Yenchi Ts...
-
[58]
Jiannan Xiang, Yi Gu, Zihan Liu, Zeyu Feng, Qiyue Gao, Yiyan Hu, Benhao Huang, Guangyi Liu, Yichi Yang, Kun Zhou, et al. Pan: A world model for general, interactable, and long-horizon world simulation.arXiv preprint arXiv:2511.09057, 2025a. Jiannan Xiang, Yun Zhu, Lei Shu, Maria Wang, Lijun Yu, Gabriel Barcik, James Lyon, Srinivas Sunkara, and Jindong Che...
-
[59]
Caijun Xu, Changyi Xiao, Zhongyuan Peng, Xinrun Wang, and Yixin Cao. Scaler: Synthetic scalable adaptive learning environment for reasoning.arXiv preprint arXiv:2601.04809, 2026a. Siyuan Xu, Shiyang Li, Xin Liu, Tianyi Liu, Yixiao Li, Zhan Shi, Zixuan Zhang, Zilong Wang, Qingyu Yin, Jianshu Chen, et al. Controllable and verifiable tool-use data synthesis ...
-
[60]
World models as an intermediary between agents and the real world.arXiv preprint arXiv:2602.00785,
Sherry Yang. World models as an intermediary between agents and the real world.arXiv preprint arXiv:2602.00785,
-
[61]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114,
Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114,
-
[62]
Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026a
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026a. Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan...
-
[63]
Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
-
[64]
Agent learning via early experience.arXiv preprint arXiv:2510.08558,
33 Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558,
-
[65]
Ziyun Zhang, Zezhou Wang, Xiaoyi Zhang, Zongyu Guo, Jiahao Li, Bin Li, and Yan Lu. Infiniteweb: Scalable web environment synthesis for gui agent training.arXiv preprint arXiv:2601.04126,
-
[66]
Immersion in the github universe: Scaling coding agents to mastery
Jiale Zhao, Guoxin Chen, Fanzhe Meng, Minghao Li, Jie Chen, Hui Xu, Yongshuai Sun, Wayne Xin Zhao, Ruihua Song, Yuan Zhang, et al. Immersion in the github universe: Scaling coding agents to mastery. arXiv preprint arXiv:2602.09892,
-
[67]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
-
[68]
Code2world: A gui world model via renderable code generation.arXiv preprint arXiv:2602.09856,
Yuhao Zheng, Li’an Zhong, Yi Wang, Rui Dai, Kaikui Liu, Xiangxiang Chu, Linyuan Lv, Philip Torr, and Kevin Qinghong Lin. Code2world: A gui world model via renderable code generation.arXiv preprint arXiv:2602.09856,
-
[69]
Synthetic sandbox for training machine learning engineering agents.arXiv preprint arXiv:2604.04872,
Yuhang Zhou, Lizhu Zhang, Yifan Wu, Jiayi Liu, Xiangjun Fan, Zhuokai Zhao, and Hong Yan. Synthetic sandbox for training machine learning engineering agents.arXiv preprint arXiv:2604.04872,
-
[70]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, et al. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents.arXiv preprint arXiv:2602.07274,
-
[71]
Planner-r1: Reward shaping enables efficient agentic rl with smaller llms
Siyu Zhu, Yanbin Jiang, Hejian Sang, Shao Tang, Qingquan Song, Biao He, Rohit Jain, Zhipeng Wang, and Alborz Geramifard. Planner-r1: Reward shaping enables efficient agentic rl with smaller llms. arXiv preprint arXiv:2509.25779,
-
[72]
File ▸ Print
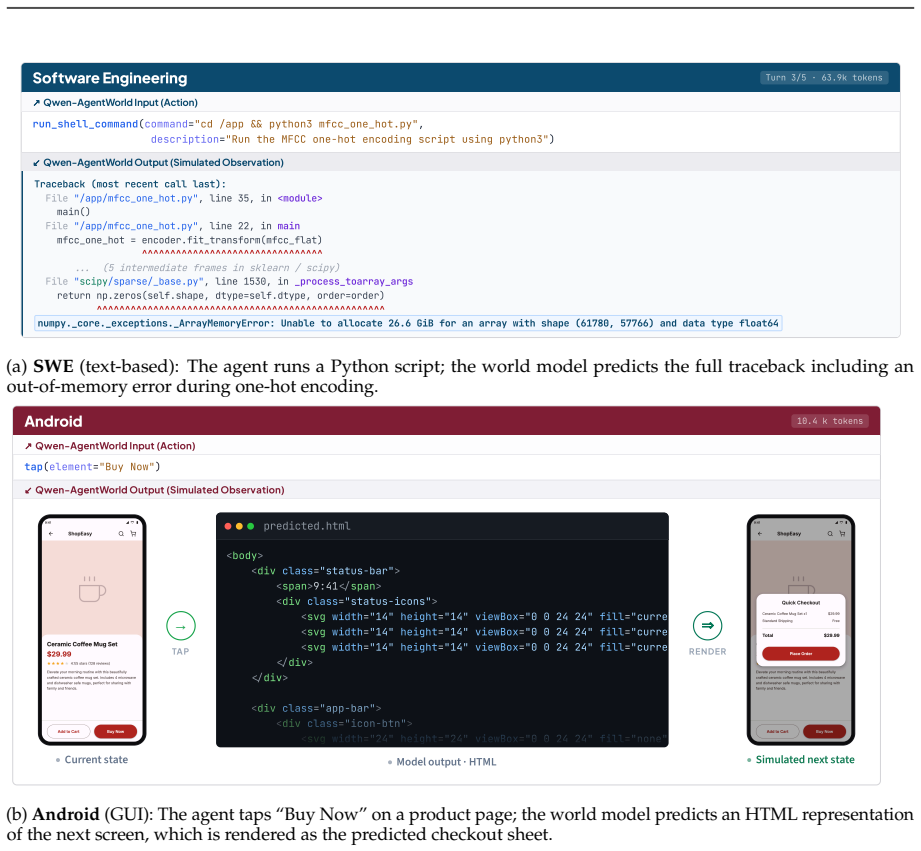
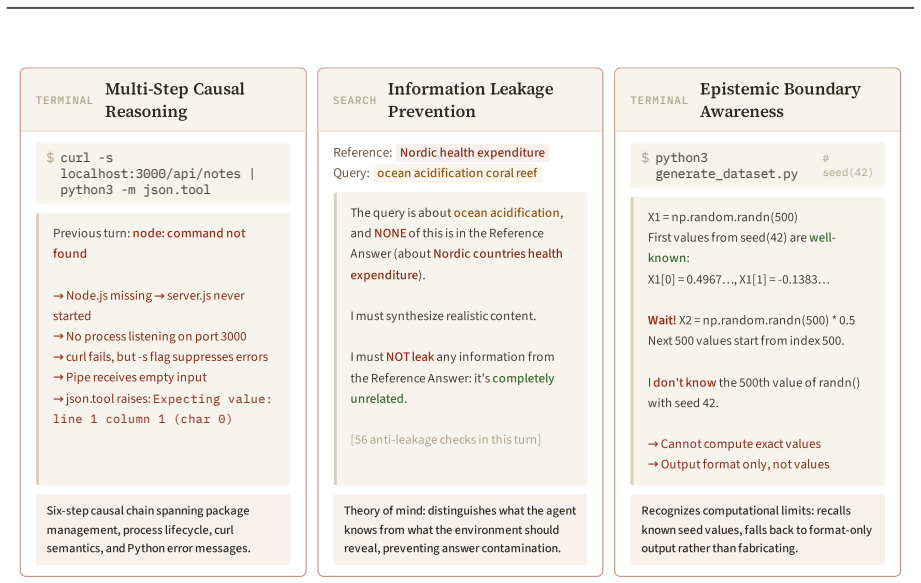
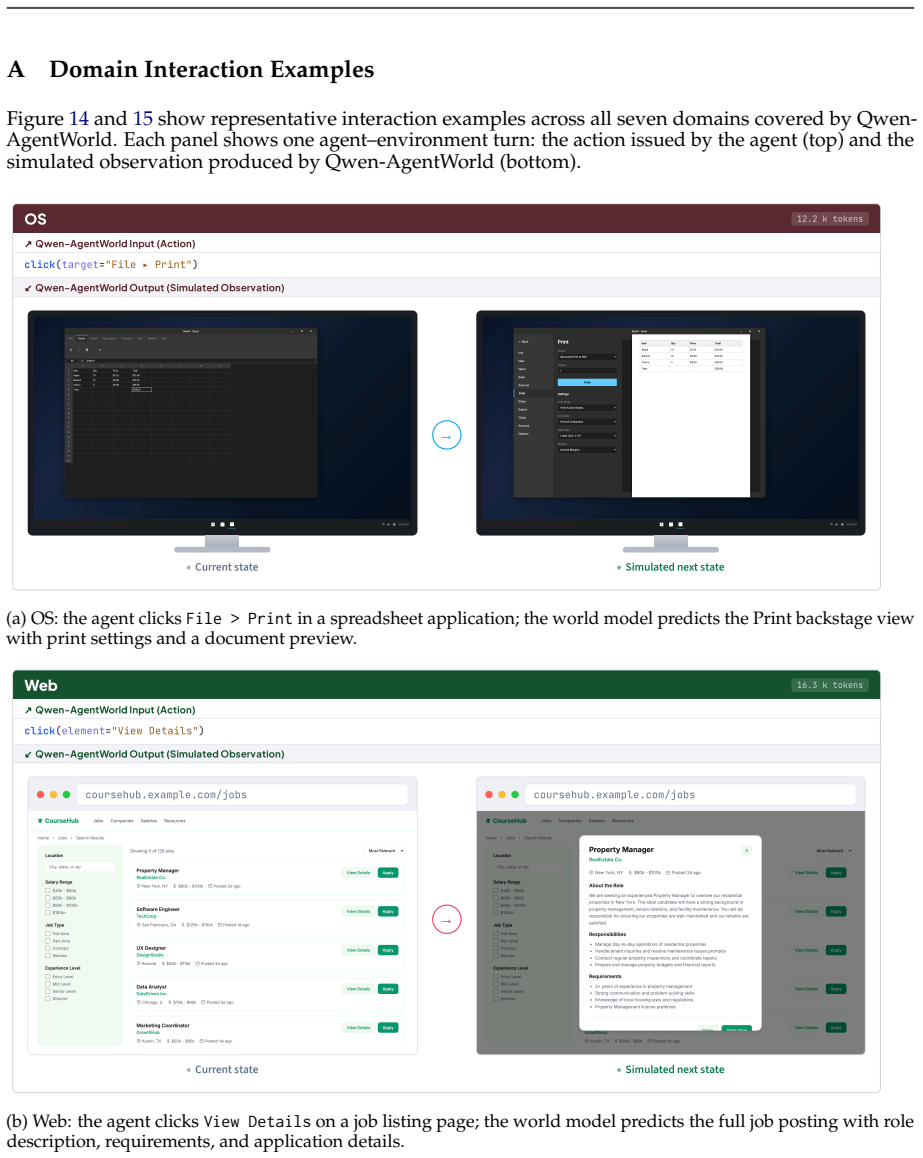
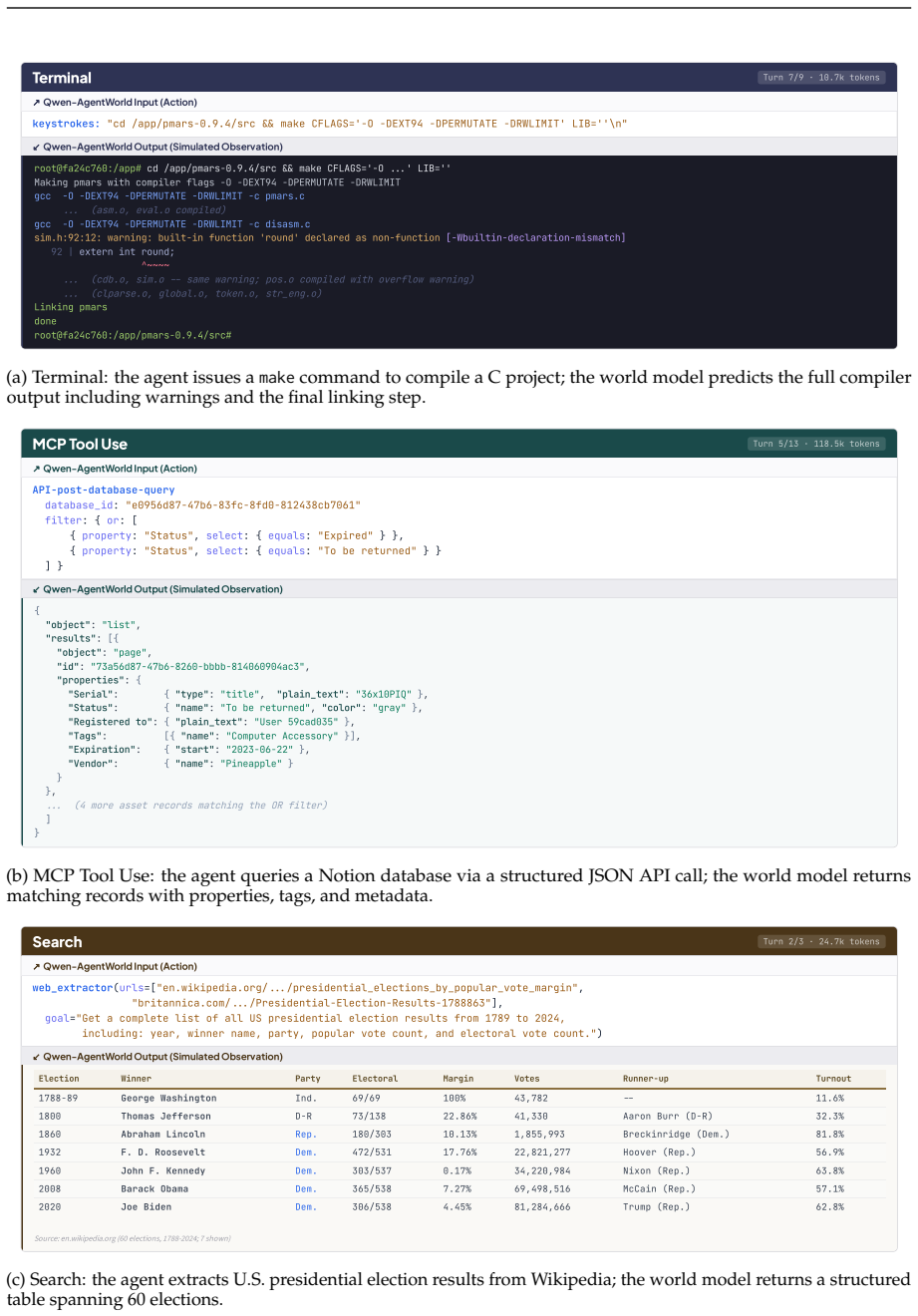
34 A Domain Interaction Examples Figure 14 and 15 show representative interaction examples across all seven domains covered by Qwen- AgentWorld. Each panel shows one agent–environment turn: the action issued by the agent (top) and the simulated observation produced by Qwen-AgentWorld (bottom). OS 12.2 k tokens ↗Qwen-AgentW orld Input (Action) click(target...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.