FlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
Pith reviewed 2026-06-26 18:15 UTC · model grok-4.3
The pith
FlowBender trains conditional flow models to correct their outputs by conditioning on alignment error computed from the task forward operator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
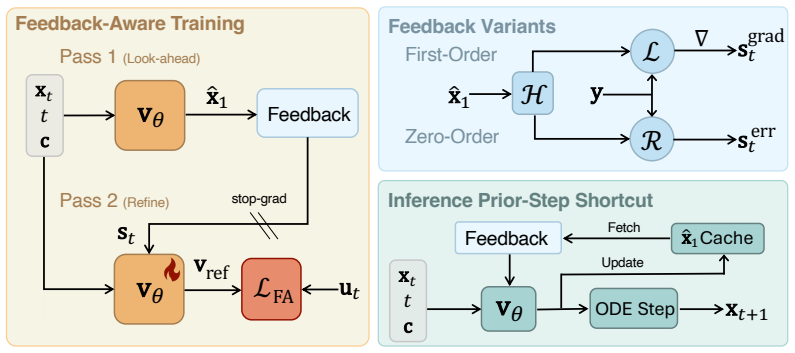
FlowBender is a closed-loop training framework in which an unguided look-ahead pass estimates the clean signal, a task-specific deviation is computed via the forward operator, and a refinement pass consumes this signal to produce a corrected velocity. Several variants support both differentiable and non-differentiable operators, and a prior-step shortcut keeps the added cost low during sampling.
What carries the argument
The closed-loop correction mechanism that feeds the alignment error, obtained by applying the forward operator to an unguided estimate, back into the velocity prediction as an additional conditioning input.
If this is right
- The trained model satisfies the input condition more accurately than standard supervised or guidance-based baselines.
- Fidelity and plausibility improve together instead of trading off against each other.
- The method works for both differentiable operators and non-differentiable ones such as JPEG compression.
- A prior-step shortcut keeps the closed-loop correction computationally cheap at sampling time.
Where Pith is reading between the lines
- The same feedback-training pattern could be applied to diffusion models that share similar conditional sampling dynamics.
- Tasks whose forward operators are themselves learned networks rather than fixed functions become feasible once the error signal is treated as conditioning.
- Deployment becomes simpler because hand-tuned guidance schedules are replaced by a learned correction policy.
Load-bearing premise
The forward operator that defines the task constraint must be available and usable during both training and inference so the model can learn from the resulting alignment error.
What would settle it
An ablation that removes the alignment-error input from the refinement pass and shows the performance advantage over baselines disappears on the same image-translation, restoration, and texturing benchmarks.
Figures
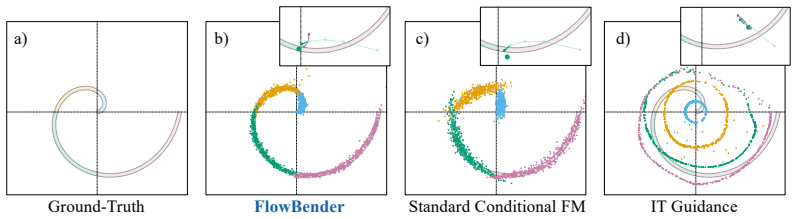

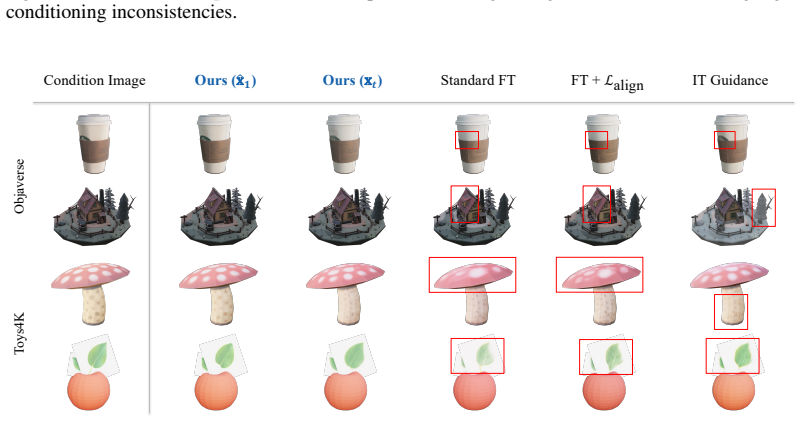

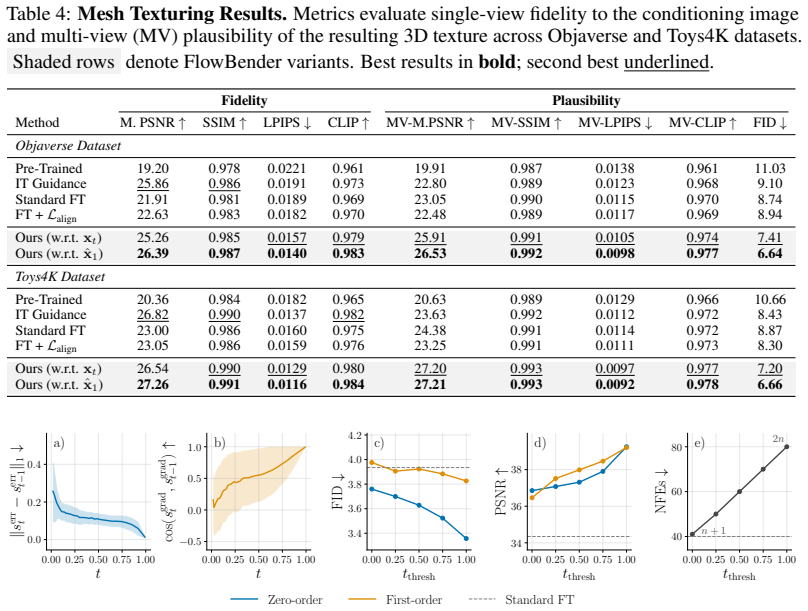




read the original abstract
Conditional diffusion and flow models routinely fail to satisfy the very constraints that define their task. For instance, a depth-conditioned model often produces images whose re-extracted depth disagrees with the input, even though the forward operator--the depth predictor defining the constraint--is available during both training and inference. Existing approaches generally fall into two categories: supervised models that treat the conditioning signal as a static cue and ignore alignment information at inference, and guidance-based methods that consult it through hand-tuned linear updates, typically trading fidelity to the condition against the plausibility of the generated sample. We argue that the fundamental gap in both paradigms is that the model is never trained to utilize its own alignment error. We introduce FlowBender, a closed-loop framework that treats this error as a first-class input, training the network to learn a correction policy conditioned on inference-time feedback. At each step, an unguided look-ahead pass estimates the clean signal, a task-specific deviation is computed via the forward operator, and a refinement pass consumes this signal to produce a corrected velocity. We propose several variants of FlowBender, including a gradient-based formulation for differentiable operators and a zero-order variant for non-differentiable settings such as JPEG compression. For efficient sampling, we introduce a prior-step shortcut that enables closed-loop correction at a minimal additional computational cost. Across image-to-image translation, restoration, and 3D mesh texturing, FlowBender consistently outperforms standard supervised baselines, alignment-loss-augmented training, and state-of-the-art inference-time guidance, improving fidelity and plausibility simultaneously rather than trading them against each other. Project page: https://flow-bender.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
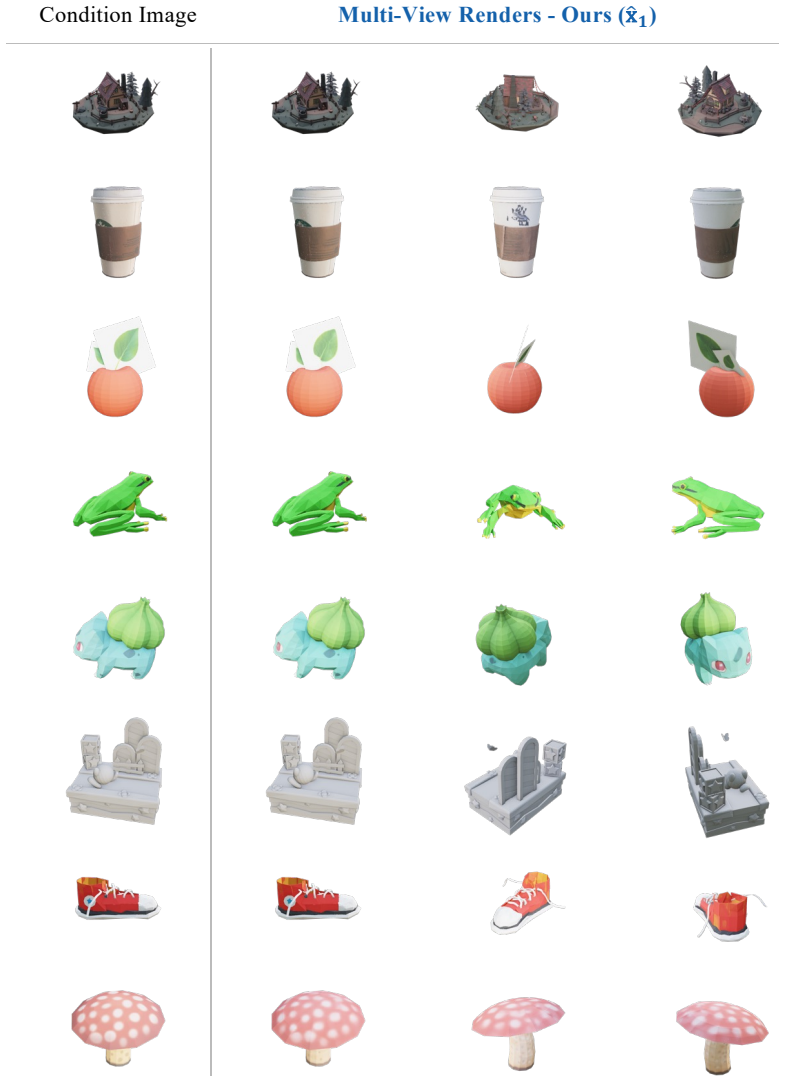
Summary. The manuscript introduces FlowBender, a closed-loop training framework for conditional flow models. At each step an unguided look-ahead pass produces an estimate, the task forward operator computes an alignment deviation, and a refinement pass consumes this deviation as conditioning to produce a corrected velocity field. Variants are proposed for differentiable and non-differentiable operators; a prior-step shortcut is introduced for efficiency. The central empirical claim is that the resulting models simultaneously improve fidelity to the conditioning signal and sample plausibility over supervised baselines, alignment-loss training, and inference-time guidance across image-to-image translation, restoration, and 3D mesh texturing.
Significance. If the empirical results and the mechanistic premise both hold, the work would supply a training-time mechanism that internalizes constraint satisfaction rather than relying on hand-tuned guidance or static conditioning, potentially removing the usual fidelity-plausibility trade-off in constrained conditional generation.
major comments (2)
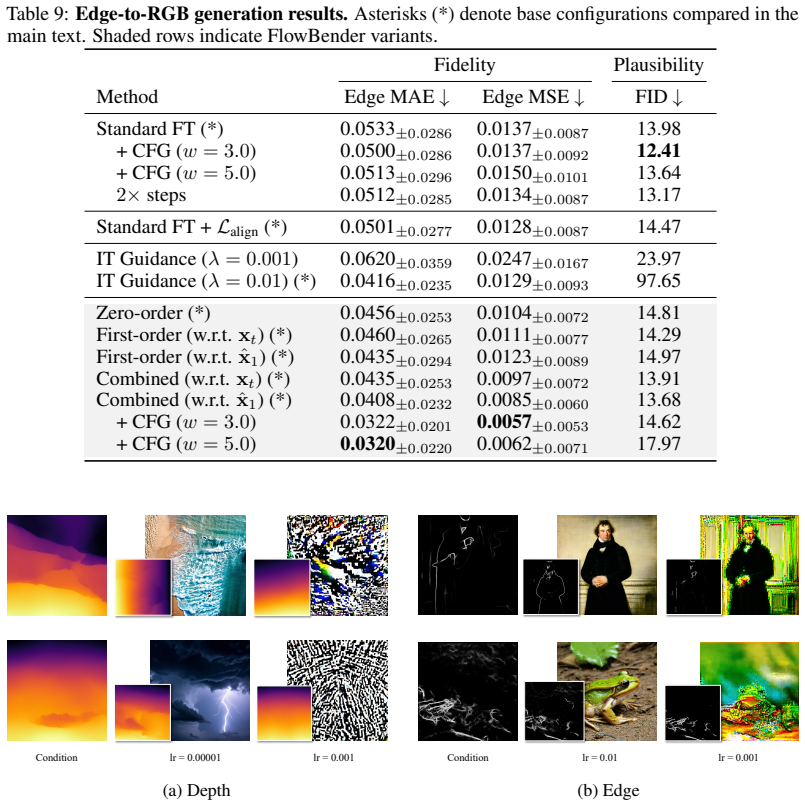
- [Abstract] Abstract: the claim of 'consistent outperformance' across three distinct task families is stated without any quantitative metrics, error bars, dataset sizes, or ablation tables. This absence prevents assessment of effect size and directly undermines verification of the central empirical claim.
- [Method] Method description (no numbered section or equation supplied): the manuscript asserts that the closed-loop procedure causes the network to internalize a correction policy conditioned on the alignment error, yet supplies neither the explicit loss formulation nor any ablation (e.g., attention maps, channel-ablation, or comparison against a model that receives the same extra channel but without the look-ahead/refinement structure) demonstrating that the deviation signal is attended to rather than treated as noise. This premise is load-bearing for attributing reported gains to the proposed mechanism rather than to overfitting or to the mere presence of an extra input channel.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The two major comments identify clear opportunities to strengthen the presentation of our empirical claims and the mechanistic evidence for the proposed closed-loop mechanism. We address each point below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' across three distinct task families is stated without any quantitative metrics, error bars, dataset sizes, or ablation tables. This absence prevents assessment of effect size and directly undermines verification of the central empirical claim.
Authors: We agree that the abstract would be more informative if it included representative quantitative results. In the revised manuscript we will insert concise numerical highlights (e.g., relative improvements in fidelity and plausibility metrics with standard deviations) drawn from the main experimental tables, while preserving the abstract’s length constraints. revision: yes
-
Referee: [Method] Method description (no numbered section or equation supplied): the manuscript asserts that the closed-loop procedure causes the network to internalize a correction policy conditioned on the alignment error, yet supplies neither the explicit loss formulation nor any ablation (e.g., attention maps, channel-ablation, or comparison against a model that receives the same extra channel but without the look-ahead/refinement structure) demonstrating that the deviation signal is attended to rather than treated as noise. This premise is load-bearing for attributing reported gains to the proposed mechanism rather than to overfitting or to the mere presence of an extra input channel.
Authors: The full manuscript contains a Method section with algorithmic pseudocode and loss definitions; however, we acknowledge that the loss equations are not numbered and that targeted ablations isolating the role of the alignment-deviation conditioning are absent. We will (i) number and explicitly display the closed-loop training objective, (ii) add a controlled ablation that supplies the deviation channel without the look-ahead/refinement structure, and (iii) include attention-map visualizations and channel-ablation results to demonstrate that the model attends to the deviation signal rather than treating it as noise. revision: yes
Circularity Check
No significant circularity; derivation is self-contained algorithmic proposal
full rationale
The paper presents FlowBender as a training procedure that augments conditional flow models with closed-loop feedback from a task-specific forward operator. No equations, loss formulations, or derivations are supplied that reduce the claimed performance gains to a quantity defined by the method itself (e.g., no fitted parameter renamed as prediction, no self-definitional loop, and no load-bearing self-citation chain). The central mechanism is an independent algorithmic change whose validity rests on empirical comparison rather than algebraic identity with its inputs. The reader's assessment of score 2.0 is consistent with this; the absence of any quoted reduction meeting the enumerated circularity patterns warrants a 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The forward operator defining the constraint is available during both training and inference.
Reference graph
Works this paper leans on
-
[1]
Solving ill-posed inverse problems using iterative deep neural networks.Inverse Problems, 33(12):124007, 2017
Jonas Adler and Ozan Öktem. Solving ill-posed inverse problems using iterative deep neural networks.Inverse Problems, 33(12):124007, 2017
2017
-
[2]
Learned primal-dual reconstruction.IEEE transactions on medical imaging, 37(6):1322–1332, 2018
Jonas Adler and Ozan Öktem. Learned primal-dual reconstruction.IEEE transactions on medical imaging, 37(6):1322–1332, 2018
2018
-
[3]
Unsplash.https://github.com/unsplash/ datasets, 2023
Zahid Ali, Chesser Luke, and Carbone Timothy. Unsplash.https://github.com/unsplash/ datasets, 2023
2023
-
[4]
Learning to learn by gradient descent by gradient descent.Advances in neural information processing systems, 29, 2016
Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent.Advances in neural information processing systems, 29, 2016
2016
-
[5]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 843–852, 2023
2023
-
[6]
Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606, 2021
Georgios Batzolis, Jan Stanczuk, Carola-Bibiane Schönlieb, and Christian Etmann. Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606, 2021
arXiv 2021
-
[7]
Human pose estimation with iterative error feedback
Joao Carreira, Pulkit Agrawal, Katerina Fragkiadaki, and Jitendra Malik. Human pose estimation with iterative error feedback. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4733–4742, 2016
2016
-
[8]
Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views
Tianyu Chen, Wei Xiang, Kang Han, Yu Lu, Di Wu, Gaowen Liu, and Ramana Rao Kompella. Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views. arXiv preprint arXiv:2602.22571, 2026
arXiv 2026
-
[9]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202, 2022
arXiv 2022
-
[10]
G3r: Gradient guided generalizable reconstruction
Yun Chen, Jingkang Wang, Ze Yang, Sivabalan Manivasagam, and Raquel Urtasun. G3r: Gradient guided generalizable reconstruction. InEuropean Conference on Computer Vision, pages 305–323. Springer, 2024
2024
-
[11]
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffu- sion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
Pith/arXiv arXiv 2022
-
[12]
Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35:25683–25696, 2022
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints.Advances in Neural Information Processing Systems, 35:25683–25696, 2022. 10
2022
-
[13]
A survey on diffusion models for inverse problems.arXiv preprint arXiv:2410.00083, 2024
Giannis Daras, Hyungjin Chung, Chieh-Hsin Lai, Yuki Mitsufuji, Jong Chul Ye, Peyman Milanfar, Alexandros G Dimakis, and Mauricio Delbracio. A survey on diffusion models for inverse problems.arXiv preprint arXiv:2410.00083, 2024
Pith/arXiv arXiv 2024
-
[14]
Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813, 2023
2023
-
[15]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[16]
Noam Elata, Hyungjin Chung, Jong Chul Ye, Tomer Michaeli, and Michael Elad. Inv- fusion: Bridging supervised and zero-shot diffusion for inverse problems.arXiv preprint arXiv:2504.01689, 2025
arXiv 2025
-
[17]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[18]
Deepview: View synthesis with learned gradient descent
John Flynn, Michael Broxton, Paul Debevec, Matthew DuVall, Graham Fyffe, Ryan Overbeck, Noah Snavely, and Richard Tucker. Deepview: View synthesis with learned gradient descent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2367–2376, 2019
2019
-
[19]
Learn to guide your diffusion model.arXiv preprint arXiv:2510.00815, 2025
Alexandre Galashov, Ashwini Pokle, Arnaud Doucet, Arthur Gretton, Mauricio Delbracio, and Valentin De Bortoli. Learn to guide your diffusion model.arXiv preprint arXiv:2510.00815, 2025
arXiv 2025
-
[20]
A closer look at learned optimization: Stability, robustness, and inductive biases.Advances in neural information processing systems, 35:3758–3773, 2022
James Harrison, Luke Metz, and Jascha Sohl-Dickstein. A closer look at learned optimization: Stability, robustness, and inductive biases.Advances in neural information processing systems, 35:3758–3773, 2022
2022
-
[21]
Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J Zico Kolter, Ruslan Salakhutdinov, et al. Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
arXiv 2023
-
[22]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[23]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[24]
Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
2022
-
[25]
ilrm: An iterative large 3d reconstruction model.arXiv preprint arXiv:2507.23277, 2025
Gyeongjin Kang, Seungtae Nam, Seungkwon Yang, Xiangyu Sun, Sameh Khamis, Abdelrahman Mohamed, and Eunbyung Park. ilrm: An iterative large 3d reconstruction model.arXiv preprint arXiv:2507.23277, 2025
Pith/arXiv arXiv 2025
-
[26]
Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
2024
-
[27]
Snips: Solving noisy inverse problems stochastically.Advances in neural information processing systems, 34:21757–21769, 2021
Bahjat Kawar, Gregory Vaksman, and Michael Elad. Snips: Solving noisy inverse problems stochastically.Advances in neural information processing systems, 34:21757–21769, 2021
2021
-
[28]
Denoising diffusion restoration models.Advances in neural information processing systems, 35:23593–23606, 2022
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models.Advances in neural information processing systems, 35:23593–23606, 2022
2022
-
[29]
Flowdps: Flow-driven posterior sampling for inverse problems
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. Flowdps: Flow-driven posterior sampling for inverse problems. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12328–12337, 2025. 11
2025
-
[30]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[31]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[32]
Controlnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen. Controlnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai. github. io/controlnet_plus_plus. InEuropean Conference on Computer Vision, pages 129–147. Springer, 2024
2024
-
[33]
Deepim: Deep iterative matching for 6d pose estimation
Yi Li, Gu Wang, Xiangyang Ji, Yu Xiang, and Dieter Fox. Deepim: Deep iterative matching for 6d pose estimation. InProceedings of the European conference on computer vision (ECCV), pages 683–698, 2018
2018
-
[34]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[35]
Quicksplat: Fast 3d surface reconstruction via learned gaussian initialization
Yueh-Cheng Liu, Lukas Höllein, Matthias Nießner, and Angela Dai. Quicksplat: Fast 3d surface reconstruction via learned gaussian initialization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27851–27861, 2025
2025
-
[36]
Yueh-Cheng Liu, Jozef Hladk `y, Matthias Nießner, and Angela Dai. Diff3r: Feed-forward 3d gaussian splatting with uncertainty-aware differentiable optimization.arXiv preprint arXiv:2604.01030, 2026
arXiv 2026
-
[37]
Wei Long, Haifeng Wu, Shiyin Jiang, Jinhua Zhang, Xinchun Ji, and Shuhang Gu. Idesplat: Iterative depth probability estimation for generalizable 3d gaussian splatting.arXiv preprint arXiv:2601.03824, 2026
arXiv 2026
-
[38]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations
-
[39]
Readout guidance: Learning control from diffusion features
Grace Luo, Trevor Darrell, Oliver Wang, Dan B Goldman, and Aleksander Holynski. Readout guidance: Learning control from diffusion features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8217–8227, 2024
2024
-
[40]
Deep feedback inverse problem solver
Wei-Chiu Ma, Shenlong Wang, Jiayuan Gu, Sivabalan Manivasagam, Antonio Torralba, and Raquel Urtasun. Deep feedback inverse problem solver. InEuropean conference on computer vision, pages 229–246. Springer, 2020
2020
-
[41]
Luke Metz, Niru Maheswaranathan, C Daniel Freeman, Ben Poole, and Jascha Sohl-Dickstein. Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves.arXiv preprint arXiv:2009.11243, 2020
arXiv 2009
-
[42]
Velo: Training versatile learned optimizers by scaling up.arXiv preprint arXiv:2211.09760, 2022
Luke Metz, James Harrison, C Daniel Freeman, Amil Merchant, Lucas Beyer, James Bradbury, Naman Agrawal, Ben Poole, Igor Mordatch, Adam Roberts, et al. Velo: Training versatile learned optimizers by scaling up.arXiv preprint arXiv:2211.09760, 2022
arXiv 2022
-
[43]
Extracting triangular 3d models, materials, and lighting from images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, and Sanja Fidler. Extracting triangular 3d models, materials, and lighting from images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8280–8290, 2022
2022
-
[44]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021
Pith/arXiv arXiv 2021
-
[45]
Flowchef: Steering of rectified flow models for controlled generations
Maitreya Patel, Song Wen, Dimitris N Metaxas, and Yezhou Yang. Flowchef: Steering of rectified flow models for controlled generations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15308–15318, 2025
2025
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 12
2023
-
[47]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[48]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022
2022
-
[49]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[50]
Zero-to-hero: Enhancing zero-shot novel view synthesis via attention map filtering.Advances in Neural Information Processing Systems, 37: 30522–30553, 2024
Ido Sobol, Chenfeng Xu, and Or Litany. Zero-to-hero: Enhancing zero-shot novel view synthesis via attention map filtering.Advances in Neural Information Processing Systems, 37: 30522–30553, 2024
2024
-
[51]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[52]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational Conference on Learning Representations, 2023
2023
-
[53]
Using shape to categorize: Low-shot learning with an explicit shape bias
Stefan Stojanov, Anh Thai, and James M Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1798–1808, 2021
2021
-
[54]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[55]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/ diffusers, 2022
2022
-
[56]
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot image restoration using denoising diffusion null-space model.arXiv preprint arXiv:2212.00490, 2022
arXiv 2022
-
[57]
Life-gom: Generalizable human rendering with learned iterative feedback over multi-resolution gaussians-on-mesh
Jing Wen, Alexander G Schwing, and Shenlong Wang. Life-gom: Generalizable human rendering with learned iterative feedback over multi-resolution gaussians-on-mesh. In13th International Conference on Learning Representations, ICLR 2025, pages 40453–40472. Inter- national Conference on Learning Representations, ICLR, 2025
2025
-
[58]
Learned optimizers that scale and generalize
Olga Wichrowska, Niru Maheswaranathan, Matthew W Hoffman, Sergio Gomez Colmenarejo, Misha Denil, Nando Freitas, and Jascha Sohl-Dickstein. Learned optimizers that scale and generalize. InInternational conference on machine learning, pages 3751–3760. PMLR, 2017
2017
-
[59]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Pith/arXiv arXiv 2025
-
[60]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4818–4829, 2024
2024
-
[61]
Holistically-nested edge detection
Saining Xie and Zhuowen Tu. Holistically-nested edge detection. InProceedings of the IEEE international conference on computer vision, pages 1395–1403, 2015
2015
-
[62]
Resplat: Learning recurrent gaussian splats.arXiv preprint arXiv:2510.08575, 2025
Haofei Xu, Daniel Barath, Andreas Geiger, and Marc Pollefeys. Resplat: Learning recurrent gaussian splats.arXiv preprint arXiv:2510.08575, 2025. 13
arXiv 2025
-
[63]
Yifeng Xu, Zhenliang He, Shiguang Shan, and Xilin Chen. Ctrlora: An extensible and efficient framework for controllable image generation.arXiv preprint arXiv:2410.09400, 2024
arXiv 2024
-
[64]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Anything V2. pages 21875–21911. doi: 10.52202/079017-0688
-
[65]
Tfg: Unified training-free guidance for diffusion models.Advances in Neural Information Processing Systems, 37:22370–22417, 2024
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models.Advances in Neural Information Processing Systems, 37:22370–22417, 2024
2024
-
[66]
Navigating with annealing guidance scale in diffusion space
Shai Yehezkel, Omer Dahary, Andrey V oynov, and Daniel Cohen-Or. Navigating with annealing guidance scale in diffusion space. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[67]
Geofusionlrm: Geometry-aware self-correction for consistent 3d reconstruction
Ahmet Burak Yildirim, Tuna Saygin, Duygu Ceylan, and Aysegul Dundar. Geofusionlrm: Geometry-aware self-correction for consistent 3d reconstruction. InComputer Graphics Forum, page e70325. Wiley Online Library, 2026
2026
-
[68]
Improving diffusion inverse problem solving with decoupled noise annealing
Bingliang Zhang, Wenda Chu, Julius Berner, Chenlin Meng, Anima Anandkumar, and Yang Song. Improving diffusion inverse problem solving with decoupled noise annealing. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 20895–20905, 2025
2025
-
[69]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 14 A Implementation Details ALGORITHM1: FEEDBACK-AWARETRAINING Require:DatasetD, modelv θ, prob.p un 1:whilenot convergeddo 2:Sample(x 1,c)∼ Dwherey∈c 3...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.