SAGE: An LLM-driven Self Reflective Agentic Framework for Fraud Detection
Pith reviewed 2026-06-27 19:47 UTC · model grok-4.3
The pith
SAGE coordinates three LLM agents through a six-layer diagnostic tree and natural-language gradients to detect fraud more accurately than existing methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
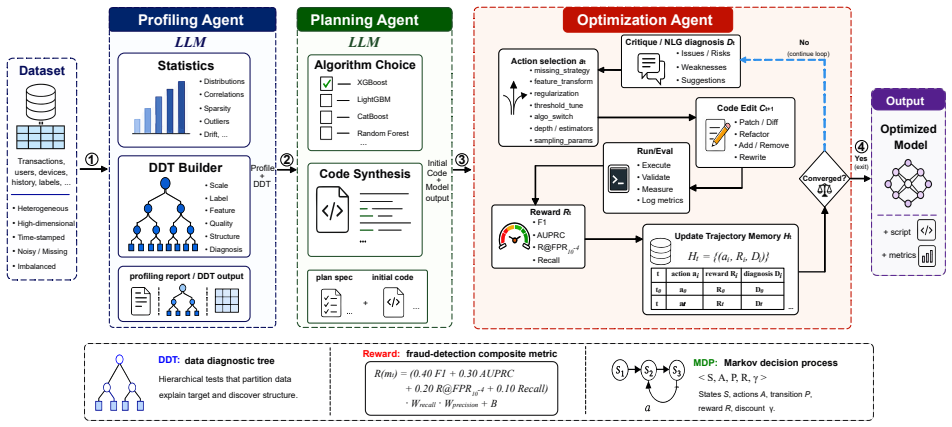
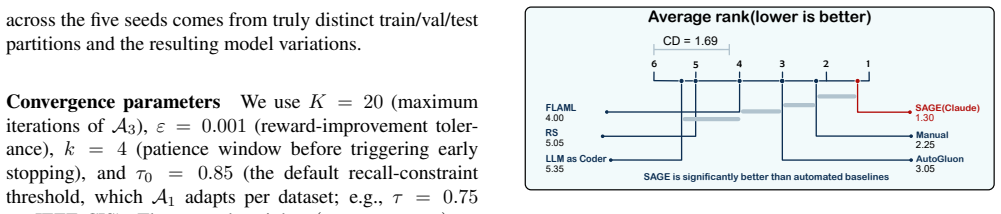
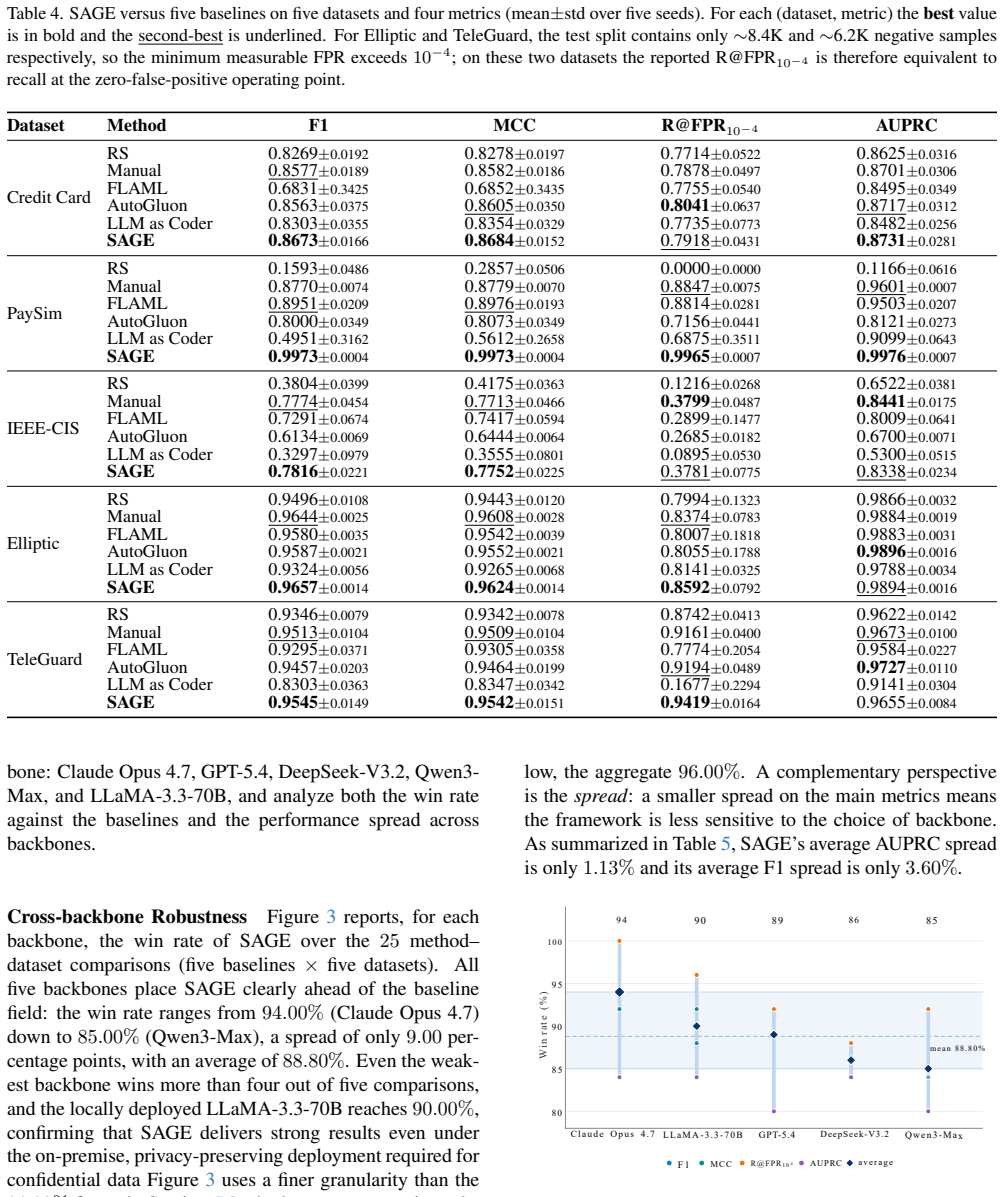
SAGE is the first end-to-end LLM-driven multi-agent framework for fraud detection. Three dedicated agents coordinate decisions via a six-layer Data Diagnostic Tree and a Markov decision process that uses natural-language gradients, automatically optimizing performance under a fraud-specific reward function. On five fraud datasets and five LLM backbones the framework wins 96.00 percent of method-dataset comparisons and improves F1 by an average of 40.86 percent over baselines.
What carries the argument
Three dedicated agents operating on a six-layer Data Diagnostic Tree inside a Markov decision process guided by natural-language gradients.
If this is right
- Individual-level fraud decisions become directly explainable in natural language for risk managers.
- The same three-agent structure with the diagnostic tree can be applied to any tabular fraud dataset without building a graph in advance.
- Automatic optimization via natural-language gradients removes the need for manual hyper-parameter search in fraud pipelines.
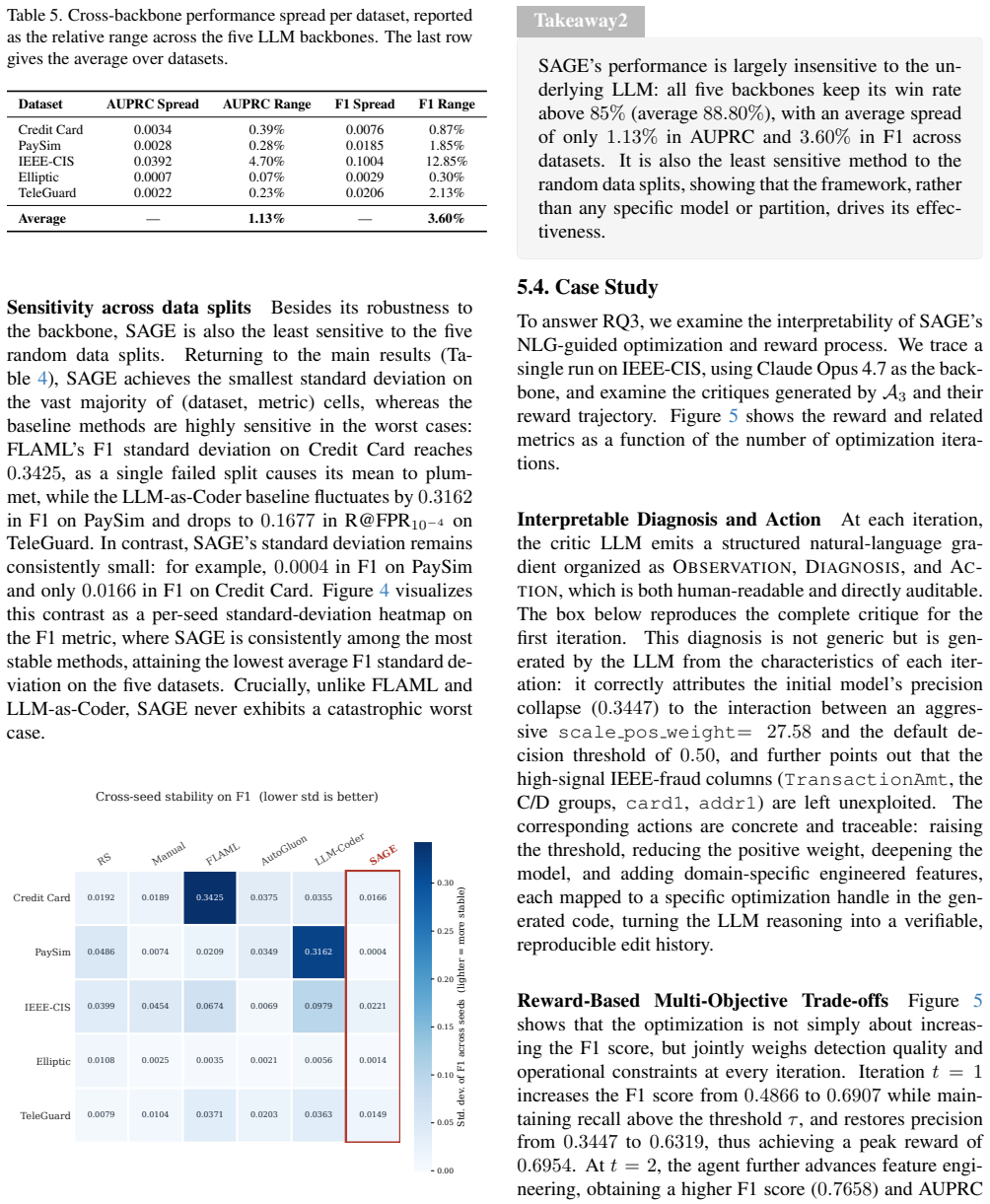
- Performance gains hold across multiple LLM backbones, suggesting the framework is not tied to one model family.
Where Pith is reading between the lines
- The approach could extend to other high-stakes tabular classification tasks that require both accuracy and human-readable explanations.
- If the coordination mechanism proves robust, similar agent trees might reduce prompt-engineering effort in other domain-specific LLM applications.
- A direct comparison on the same datasets with non-LLM multi-agent systems would clarify how much of the gain comes from the LLM components versus the tree structure.
Load-bearing premise
The three agents can coordinate reliably through the diagnostic tree and natural-language feedback without the framework creating new errors from LLM hallucinations or prompt sensitivity.
What would settle it
A controlled test in which one of the three agents produces a hallucinated feature explanation that the other agents accept, causing the overall F1 to drop below the best baseline on at least one of the five datasets.
Figures

read the original abstract
Fraud detection in payment, e-commerce, and telecommunications systems requires accuracy at the individual level, robustness under severe class imbalance, and ease of understanding for risk managers. Existing methods fall at least one of these requirements: automated machine learning systems search a fixed numerical space without semantic awareness of the dataset; graph neural network-based methods require pre-defined relational graphs and remain opaque at the individual-decision level; and the design of general-purpose large language model (LLM) agents does not consider the recall and precision constraints specific to real-world fraud detection. In this paper, we propose SAGE, the first end-to-end LLM-driven multi-agent framework for fraud detection. SAGE coordinates three dedicated agents that make decisions based on a six-layer Data Diagnostic Tree (DDT) and a Markov decision process guided by natural-language gradients, automatically optimizing the model under a fraud-specific reward. On five fraud datasets and five LLM backbones, SAGE wins $96.00\%$ of method--dataset comparisons and improves F1 by an average of $40.86\%$ over baselines. The code is available at https://github.com/yichenC1c/SAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGE, the first end-to-end LLM-driven multi-agent framework for fraud detection. It coordinates three dedicated agents using a six-layer Data Diagnostic Tree (DDT) and a Markov decision process guided by natural-language gradients, with automatic optimization under a fraud-specific reward. On five fraud datasets and five LLM backbones, it reports winning 96.00% of method-dataset comparisons and an average 40.86% F1 improvement over baselines. Code is released at the provided GitHub link.
Significance. If the empirical results prove robust, SAGE would offer a meaningful advance by combining semantic awareness from LLMs with fraud-specific structures (DDT, reward function) that address gaps in automated ML (lack of semantics) and GNNs (opacity, pre-defined graphs). The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] Abstract: The headline claims of a 96.00% win rate and 40.86% average F1 improvement are presented without error bars, dataset statistics (e.g., imbalance ratios or sizes), baseline identities, or statistical significance tests. These details are load-bearing for the central empirical contribution.
- [Abstract (and implied evaluation)] Framework and evaluation description: No ablation or error analysis is reported on the stability of the three-agent coordination through the six-layer DDT and natural-language gradients inside the MDP. This leaves unaddressed the risk that performance gains could arise from prompt-specific artifacts or hallucination propagation rather than the framework itself.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, with clarifications from the manuscript and proposed revisions where the comments identify gaps in presentation or analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of a 96.00% win rate and 40.86% average F1 improvement are presented without error bars, dataset statistics (e.g., imbalance ratios or sizes), baseline identities, or statistical significance tests. These details are load-bearing for the central empirical contribution.
Authors: The abstract provides a concise summary of the primary results. Full supporting details—including per-dataset F1 scores with standard deviations (error bars), dataset sizes and imbalance ratios, the five baseline methods, and statistical significance via paired t-tests—are reported in Section 4 (Experiments) with accompanying tables. To improve self-containment of the abstract without exceeding length limits, we will add a short clause noting that results are averaged across runs with verified significance and span datasets of varying imbalance. revision: yes
-
Referee: [Abstract (and implied evaluation)] Framework and evaluation description: No ablation or error analysis is reported on the stability of the three-agent coordination through the six-layer DDT and natural-language gradients inside the MDP. This leaves unaddressed the risk that performance gains could arise from prompt-specific artifacts or hallucination propagation rather than the framework itself.
Authors: The manuscript describes the self-reflective agent design and natural-language gradient mechanism intended to limit hallucination propagation, but we agree that dedicated ablations and error analysis on coordination stability are absent. We will add these in the revision: an ablation removing individual agents or DDT layers, plus variance analysis across prompt variations, to quantify whether gains derive from the framework structure. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical multi-agent LLM framework evaluated via direct held-out comparisons on five fraud datasets across five backbones, reporting win rates and F1 deltas without any equations, fitted parameters, or derivations that reduce the reported metrics to quantities defined inside the same loop. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions are constructed by renaming inputs. The central claims rest on standard experimental protocols that remain externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-Max.https://qwen.ai/ research, 2025
Alibaba Qwen Team. Qwen3-Max.https://qwen.ai/ research, 2025. 10
2025
-
[2]
Claude code.https://www.anthropic
Anthropic. Claude code.https://www.anthropic. com/claude-code, 2025. 3
2025
-
[3]
Claude opus 4.7 system card.https://www
Anthropic. Claude opus 4.7 system card.https://www. anthropic.com/claude/opus, 2026. 10
2026
-
[4]
Data mining for credit card fraud: A comparative study.Decision support systems, pages 602–613, 2011
Siddhartha Bhattacharyya, Sanjeev Jha, Kurian Tharakun- nel, and J Christopher Westland. Data mining for credit card fraud: A comparative study.Decision support systems, pages 602–613, 2011. 3
2011
-
[5]
Smote: synthetic minority over- sampling technique.Journal of artificial intelligence re- search, pages 321–357, 2002
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over- sampling technique.Journal of artificial intelligence re- search, pages 321–357, 2002. 4
2002
-
[6]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InKDD, pages 785–794, 2016. 3
2016
-
[7]
Tlk: An in- dustrial internet of things attack detection method based on transformer-lstm-kelm
Yichen Chen, Lijun Wang, and Xiaomin Xie. Tlk: An in- dustrial internet of things attack detection method based on transformer-lstm-kelm. InCCNS, pages 61–65, 2025. 15
2025
-
[8]
Graph neural networks for financial fraud detection: a re- view.Frontiers of Computer Science, page 199609, 2025
Dawei Cheng, Yao Zou, Sheng Xiang, and Changjun Jiang. Graph neural networks for financial fraud detection: a re- view.Frontiers of Computer Science, page 199609, 2025. 3
2025
-
[9]
Learned lessons in credit card fraud detection from a practitioner perspective
Andrea Dal Pozzolo, Olivier Caelen, Yann-Ael Le Borgne, Serge Waterschoot, and Gianluca Bontempi. Learned lessons in credit card fraud detection from a practitioner perspective. Expert systems with applications, pages 4915–4928, 2014. 3, 4
2014
-
[10]
Credit card fraud de- tection: a realistic modeling and a novel learning strategy
Andrea Dal Pozzolo, Giacomo Boracchi, Olivier Caelen, Ce- sare Alippi, and Gianluca Bontempi. Credit card fraud de- tection: a realistic modeling and a novel learning strategy. IEEE transactions on neural networks and learning systems, pages 3784–3797, 2017. 2
2017
-
[11]
The relationship between precision-recall and roc curves
Jesse Davis and Mark Goadrich. The relationship between precision-recall and roc curves. InICML, pages 233–240,
-
[12]
DeepSeek-V3.2.https : / / www
DeepSeek-AI. DeepSeek-V3.2.https : / / www . deepseek.com, 2025. 10
2025
-
[13]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, pages 1–30, 2006
Janez Dem ˇsar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, pages 1–30, 2006. 11
2006
-
[14]
Telecom fraud detection based on large language models: A multi-role, multi-layer prompting strategy.Applied Sciences, page 544, 2026
Jianpeng Ding and Houpan Zhou. Telecom fraud detection based on large language models: A multi-role, multi-layer prompting strategy.Applied Sciences, page 544, 2026. 2
2026
-
[15]
Enhancing graph neural network-based 15 fraud detectors against camouflaged fraudsters
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S Yu. Enhancing graph neural network-based 15 fraud detectors against camouflaged fraudsters. InCIKM, pages 315–324, 2020. 3
2020
-
[16]
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander J. Smola. Autogluon-tabular: Robust and accurate automl for struc- tured data.arXiv preprint arXiv:2003.06505, 2020. 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[17]
Efficient and robust automated machine learning
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. InNeurIPS, 2015. 3
2015
-
[18]
The global state of scams 2025 report.https://www.gasa.org/, 2025
Global Anti-Scam Alliance and Feedzai. The global state of scams 2025 report.https://www.gasa.org/, 2025. 2
2025
-
[19]
Why do tree-based models still outperform deep learning on typi- cal tabular data? InNeurIPS, pages 507–520, 2022
L ´eo Grinsztajn, Edouard Oyallon, and Ga¨el Varoquaux. Why do tree-based models still outperform deep learning on typi- cal tabular data? InNeurIPS, pages 507–520, 2022. 3
2022
-
[20]
Fraud dataset benchmark and applications.arXiv preprint arXiv:2208.14417, 2022
Prince Grover, Julia Xu, Justin Tittelfitz, Anqi Cheng, Zheng Li, Jakub Zablocki, Jianbo Liu, and Hao Zhou. Fraud dataset benchmark and applications.arXiv preprint arXiv:2208.14417, 2022. 3
-
[21]
Learning from imbalanced data.IEEE Transactions on knowledge and data engineer- ing, pages 1263–1284, 2009
Haibo He and Edwardo A Garcia. Learning from imbalanced data.IEEE Transactions on knowledge and data engineer- ing, pages 1263–1284, 2009. 3
2009
-
[22]
FACTGUARD: event-centric and commonsense-guided fake news detection
Jing He, Han Zhang, Yuanhui Xiao, Wei Guo, Shaowen Yao, and Renyang Liu. FACTGUARD: event-centric and commonsense-guided fake news detection. InAAAI, pages 363–371, 2026. 2
2026
-
[23]
Data interpreter: An llm agent for data sci- ence
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jin- lin Wang, et al. Data interpreter: An llm agent for data sci- ence. InACL, pages 19796–19821, 2025. 3
2025
-
[24]
Sequence classification for credit-card fraud detection.Expert systems with applica- tions, pages 234–245, 2018
Johannes Jurgovsky, Michael Granitzer, Konstantin Ziegler, Sylvie Calabretto, Pierre-Edouard Portier, Liyun He- Guelton, and Olivier Caelen. Sequence classification for credit-card fraud detection.Expert systems with applica- tions, pages 234–245, 2018. 3
2018
-
[25]
Pick and choose: A gnn-based imbalanced learning approach for fraud detection
Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. Pick and choose: A gnn-based imbalanced learning approach for fraud detection. InWWW, pages 3168–3177, 2021. 3
2021
-
[26]
Paysim: A financial mobile money simulator for fraud de- tection
Edgar Lopez-Rojas, Ahmad Elmir, and Stefan Axelsson. Paysim: A financial mobile money simulator for fraud de- tection. InEMSS, pages 249–255, 2016. 3, 9
2016
-
[27]
Credit card fraud de- tection using machine learning: A survey.arXiv preprint arXiv:2010.06479, 2020
Yvan Lucas and Johannes Jurgovsky. Credit card fraud de- tection using machine learning: A survey.arXiv preprint arXiv:2010.06479, 2020. 3, 4
-
[28]
Comparison of the predicted and ob- served secondary structure of t4 phage lysozyme.Biochim- ica et Biophysica Acta (BBA)-Protein Structure, pages 442– 451, 1975
Brian W Matthews. Comparison of the predicted and ob- served secondary structure of t4 phage lysozyme.Biochim- ica et Biophysica Acta (BBA)-Protein Structure, pages 442– 451, 1975. 10
1975
-
[29]
LLaMA-3.3-70B.https://www.llama.com,
Meta AI. LLaMA-3.3-70B.https://www.llama.com,
-
[30]
GPT-5.4.https://openai.com, 2026
OpenAI. GPT-5.4.https://openai.com, 2026. 10
2026
-
[31]
Johnson, and Gianluca Bontempi
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson, and Gianluca Bontempi. Calibrating probability with undersam- pling for unbalanced classification. InSSCI, pages 159–166,
-
[32]
Automatic prompt optimization with ”gradient descent” and beam search
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with ”gradient descent” and beam search. InEMNLP, pages 7957–7968, 2023. 3, 5
2023
-
[33]
Sequential fraud de- tection for prepaid cards using hidden markov model diver- gence.Expert Systems with Applications, pages 235–251,
William N Robinson and Andrea Aria. Sequential fraud de- tection for prepaid cards using hidden markov model diver- gence.Expert Systems with Applications, pages 235–251,
-
[34]
Digital deception: Genera- tive artificial intelligence in social engineering and phishing
Marc Schmitt and Ivan Flechais. Digital deception: Genera- tive artificial intelligence in social engineering and phishing. Artificial Intelligence Review, page 324, 2024. 3
2024
-
[35]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InNeurIPS, 2023. 3
2023
-
[36]
Tabular data: Deep learning is not all you need.Information fusion, pages 84– 90, 2022
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need.Information fusion, pages 84– 90, 2022. 3
2022
-
[37]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998. 5
1998
-
[38]
FLAML: A fast and lightweight automl library
Chi Wang, Qingyun Wu, Markus Weimer, and Erkang Zhu. FLAML: A fast and lightweight automl library. InMLSys,
-
[39]
A semi-supervised graph attentive network for financial fraud detection
Daixin Wang, Jianbin Lin, Peng Cui, Quanhui Jia, Zhen Wang, Yanming Fang, Quan Yu, Jun Zhou, Shuang Yang, and Yuan Qi. A semi-supervised graph attentive network for financial fraud detection. InICDM, pages 598–607, 2019. 3
2019
-
[40]
Weidele, Claudio Bellei, Tom Robinson, and Charles E
Mark Weber, Giacomo Domeniconi, Jie Chen, Daniel Karl I. Weidele, Claudio Bellei, Tom Robinson, and Charles E. Leiserson. Anti-money laundering in bitcoin: Experiment- ing with graph convolutional networks for financial foren- sics.arXiv preprint arXiv:1908.02591, 2019. 3, 9
-
[41]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversation framework.arXiv preprint arXiv:2308.08155, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Semi- supervised credit card fraud detection via attribute-driven graph representation
Sheng Xiang, Mingzhi Zhu, Dawei Cheng, Enxia Li, Ruihui Zhao, Yi Ouyang, Ling Chen, and Yefeng Zheng. Semi- supervised credit card fraud detection via attribute-driven graph representation. InAAAI, pages 14557–14565, 2023. 2
2023
-
[43]
Fei Xiao, Shaofeng Cai, Gang Chen, H. V . Jagadish, Beng Chin Ooi, and Meihui Zhang. Vecaug: Unveiling cam- ouflaged frauds with cohort augmentation for enhanced de- tection. InKDD, pages 6025–6036, 2024. 2
2024
-
[44]
Random forest for credit card fraud detection
Shiyang Xuan, Guanjun Liu, Zhenchuan Li, Lutao Zheng, Shuo Wang, and Changjun Jiang. Random forest for credit card fraud detection. InICNSC, pages 1–6, 2018. 3
2018
-
[45]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2023. 5, 7
2023
-
[46]
Niloofar Yousefi, Marie Alaghband, and Ivan Garibay. A comprehensive survey on machine learning techniques and user authentication approaches for credit card fraud detec- tion.arXiv preprint arXiv:1912.02629, 2019. 3, 4 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.