Benchmarking on Tasks That Matter: Dataset Selection for Preserving Model Rankings
Pith reviewed 2026-06-29 05:09 UTC · model grok-4.3
The pith
Small carefully chosen subsets of datasets can preserve model performance rankings nearly as well as full benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
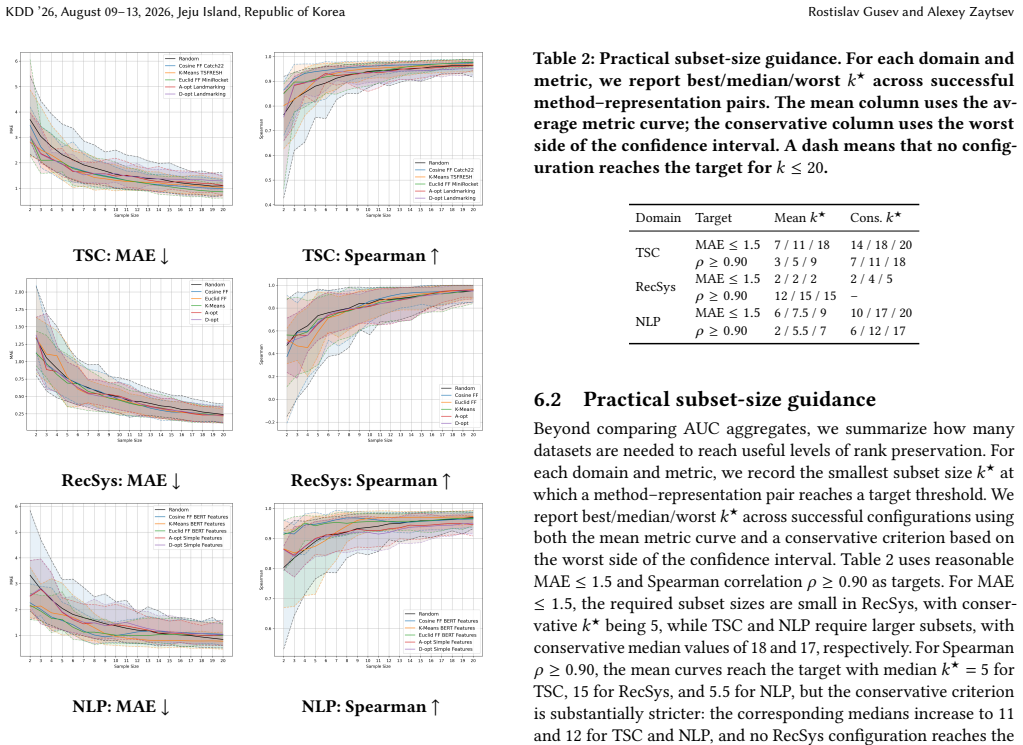
We introduce a framework for selecting dataset subsets that preserve global model rankings, incorporating bootstrap aggregation for confidence intervals and deriving upper bounds on ranking errors for farthest-first selection. Empirically, several strategies outperform random selection in preserving rankings, with the best achieving 0.95 Spearman correlation on time series classification using five datasets.
What carries the argument
The dataset selection strategies, particularly greedy farthest-first and clustering, evaluated by their effect on Spearman rank correlation with full-benchmark model rankings.
If this is right
- Model evaluations on large benchmarks can be approximated with much smaller selected subsets while retaining high rank fidelity.
- In time series classification, as few as five datasets may suffice for Spearman correlations around 0.95.
- Bootstrap aggregation supplies valid confidence intervals that enable principled statistical comparison among selection strategies.
- Upper bounds on ranking errors can be stated for farthest-first selection as a function of the number of chosen datasets.
Where Pith is reading between the lines
- The same selection logic could be tested on benchmarks outside the three domains examined here to check whether high rank preservation holds more generally.
- If better dataset representations become available, the correlation achieved by the same number of selected datasets could rise further.
- Applying the selected subsets to entirely new models that were not part of the original ranking would test whether the preservation extends beyond the models used to choose the subsets.
Load-bearing premise
The dataset representations used for clustering and selection must accurately capture the performance differences that determine model rankings across the full set.
What would settle it
Finding that the selected five datasets in the time series classification benchmark produce a Spearman correlation below 0.7 with the full set of 112 datasets would contradict the reported level of rank preservation.
Figures
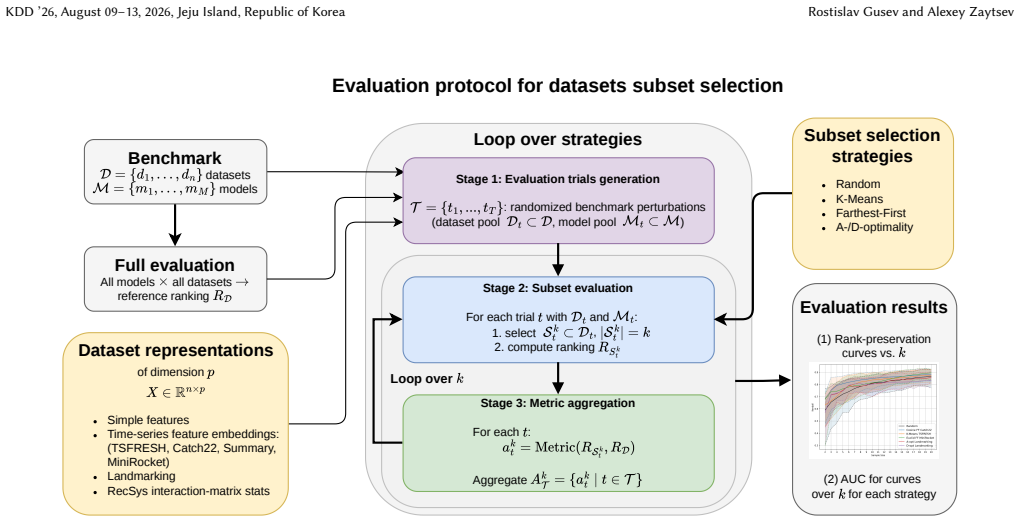
read the original abstract
Benchmarks of machine learning models often include many datasets, making evaluation expensive. For efficiency, it is preferable to perform evaluations on small, representative datasets instead. The selection of such subsets typically relies on heuristics and is rarely analyzed for the robustness of the resulting model rankings. We introduce a framework to perform the task of selecting datasets subsets with an evaluation of how different selection strategies preserve the global model rankings. Our framework includes bootstrap aggregation, which provides valid confidence intervals, allowing a principled comparison of selection strategies. We consider clustering, design criteria (A/D-optimality), random baselines, and greedy farthest-first (FAFI). For the latter, we derive upper bounds on selection quality in terms of ranking errors as a function of the number of selected datasets. Empirically, in time series classification (TSC, 112 datasets) and in a supplementary natural language processing benchmark derived from MTEB (57 tasks), several selection strategies improve rank preservation compared with random subsets, including simple FAFI. In contrast, in recommender systems (30 datasets), the improvement of strategies over random selection is small and typically statistically insignificant. For TSC, our best-performing strategy achieves a Spearman correlation of 0.95 with the full benchmark model rankings using only five selected datasets. Additional experiments indicate that the effectiveness of selection approaches depends on both the quality of dataset representations and the scale of the benchmarking regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for selecting small, representative subsets of datasets from large ML benchmarks such that model rankings (measured by Spearman correlation) are preserved relative to the full set. The framework incorporates bootstrap aggregation to produce valid confidence intervals for comparing selection strategies, including clustering, A/D-optimality criteria, greedy farthest-first (FAFI), and random baselines. Upper bounds on ranking errors are derived for FAFI as a function of the number of selected datasets. Empirical evaluation on time series classification (112 datasets), an MTEB-derived NLP benchmark (57 tasks), and recommender systems (30 datasets) shows that several non-random strategies outperform random selection, with the best TSC result reaching 0.95 Spearman correlation using only five datasets; gains are smaller and often insignificant in recommender systems. The paper explicitly states that effectiveness depends on the quality of dataset representations and benchmark scale.
Significance. If the empirical results and bounds hold under the stated dependence on representations, the work supplies a statistically grounded method for reducing the cost of model evaluation while preserving reliable rankings. The bootstrap procedure for independent confidence intervals, the explicit multi-domain evaluation, and the derivation of FAFI bounds are concrete strengths that distinguish this from purely heuristic subset selection. The acknowledgment that performance hinges on representation quality avoids overclaiming generality and provides a clear direction for future refinement.
minor comments (3)
- [Abstract and §3] Abstract and §3 (framework): the description of how dataset representations are obtained for clustering and FAFI is referenced but not detailed enough to assess whether they capture the performance differences that drive rankings; a short paragraph or table listing the representation features used would strengthen reproducibility.
- [§4] §4 (experiments): the exact procedure for constructing the MTEB-derived 57-task benchmark (task filtering, representation construction) is mentioned only in passing; adding a brief appendix table or paragraph would allow readers to verify that the reported 0.95 correlation is not sensitive to that construction.
- [Figures and tables] Figure captions and Table 1: axis labels and legend entries for the bootstrap confidence intervals should explicitly state whether intervals are percentile or BCa and whether they are adjusted for multiple comparisons across strategies.
Simulated Author's Rebuttal
We thank the referee for their constructive summary of the paper and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical framework for selecting dataset subsets and evaluates strategies (clustering, A/D-optimality, FAFI, random) by their ability to preserve model rankings via Spearman correlation, using bootstrap aggregation for independent confidence intervals. Upper bounds on FAFI selection quality are derived as a function of the number of datasets. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citations; comparisons rely on external random baselines and bootstrap resampling rather than internal fitting to the target ranking metric. The central claims are self-contained empirical demonstrations whose validity does not presuppose the reported improvements.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bootstrap aggregation yields valid confidence intervals for the ranking preservation metrics.
Reference graph
Works this paper leans on
-
[1]
David Arthur and Sergei Vassilvitskii. 2007. k-means++: The Advantages of Careful Seeding. InProceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms(New Orleans, Louisiana, USA)(SODA ’07). 1027–1035. doi:10.1145/1283383.1283494
-
[2]
Anthony Bagnall et al. 2017. The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. 606–660 pages
2017
-
[3]
Alessio Benavoli et al . 2016. Should We Really Use Post-Hoc Tests Based on Mean-Ranks? 10 pages
2016
-
[4]
Bernd Bischl et al. 2021. OpenML Benchmarking Suites
2021
-
[5]
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, Assya Trofimov, Brennan Nichyporuk, Justin Szeto, Nazanin Mohammadi Sepahvand, Edward Raff, Kanika Madan, Vikram Voleti, Samira Ebrahimi Kahou, Vincent Michalski, Tal Arbel, Chris Pal, Gaël Varoquaux, and Pascal Vincent. 2021. Accounting for Variance in Machine Learning Benchmarks. 747–769 pages
2021
-
[6]
Bowman and George E
Samuel R. Bowman and George E. Dahl. 2021. What Will it Take to Fix Bench- marking in Natural Language Understanding? 4843–4855 pages. doi:10.18653/ v1/2021.naacl-main.385
2021
-
[7]
Pablo Castells and Alistair Moffat. 2022. Offline recommender system evaluation: Challenges and new directions.AI Mag.43, 2 (June 2022), 225–238. doi:10.1002/ aaai.12051
2022
-
[8]
Jin Yao Chin, Yile Chen, and Gao Cong. 2022. The Datasets Dilemma: How Much Do We Really Know About Recommendation Datasets?. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining(Virtual Event, AZ, USA)(WSDM ’22). Association for Computing Machinery, New York, NY, USA, 141–149. doi:10.1145/3488560.3498519
-
[9]
Maximilian Christ et al. 2018. Time Series Feature Extraction on basis of Scalable Hypothesis tests (tsfresh – A Python package).Neurocomputing307 (2018), 72–77. doi:10.1016/j.neucom.2018.03.067
-
[10]
Anh Dau et al. 2019. The UCR time series archive.IEEE/CAA Journal of Automatica Sinica6 (nov 2019), 1293–1305. doi:10.1109/JAS.2019.1911747
-
[11]
Mostafa Dehghani et al. 2021. The Benchmark Lottery. arXiv:2107.07002 [cs.LG] https://arxiv.org/abs/2107.07002
arXiv 2021
-
[12]
Yashar Deldjoo et al. 2021. Explaining recommender systems fairness and accu- racy through the lens of data characteristics.Information Processing & Manage- ment58, 5 (2021), 102662. doi:10.1016/j.ipm.2021.102662
-
[13]
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. 2021. MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’21). ACM, 248–257. doi:10.1145/3447548.3467231
-
[14]
Janez Demšar. 2006. Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research7, 1 (2006), 1–30. doi:10.5555/1248547. 1248548
-
[15]
Ismail Fawaz et al. 2019. Deep learning for time series classification: a review.Data Mining and Knowledge Discovery33, 4 (March 2019), 917–963. doi:10.1007/s10618- 019-00619-1
-
[16]
Maurizio Ferrari Dacrema et al. 2019. Are we really making much progress? A worrying analysis of recent neural recommendation approaches. InProceedings of the 13th ACM Conference on Recommender Systems (RecSys ’19). ACM, 101–109. doi:10.1145/3298689.3347058
-
[17]
‘An equilibrium existence result for an economy with land’
Teofilo F. Gonzalez. 1985. Clustering to minimize the maximum intercluster distance.Theoretical Computer Science38 (1985), 293–306. doi:10.1016/0304- 3975(85)90224-5
-
[18]
Eamonn Keogh and Shruti Kasetty. 2003. On the Need for Time Series Data Mining Benchmarks: A Survey and Empirical Demonstration.Data Min. Knowl. Discov.7, 4 (Oct. 2003), 349–371. doi:10.1023/A:1024988512476
-
[19]
J. Kiefer and J. Wolfowitz. 1959. Optimum Designs in Regression Problems. The Annals of Mathematical Statistics30, 2 (1959), 271 – 294. doi:10.1214/aoms/ 1177706252
-
[20]
Zhihang Li et al. 2020. GP-NAS: Gaussian Process Based Neural Architecture Search. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11930–11939. doi:10.1109/CVPR42600.2020.01195
-
[21]
Carl H Lubba et al. 2019. catch22: CAnonical Time-series CHaracteristics: Selected through highly comparative time-series analysis. 1821–1852 pages
2019
-
[22]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2014–2037
2023
-
[23]
Christina Nießl, Moritz Herrmann, Chiara Wiedemann, Giuseppe Casalic- chio, and Anne-Laure Boulesteix. 2022. Over-optimism in benchmark stud- ies and the multiplicity of design and analysis options when interpreting their results.WIREs Data Mining and Knowledge Discovery12, 2 (2022), e1441. arXiv:https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/widm....
-
[24]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. Do ImageNet Classifiers Generalize to ImageNet?. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 5389–5400. https://proceedings.mlr.press/v97/rech...
2019
-
[25]
John R. Rice. 1976. The Algorithm Selection Problem. Advances in Computers, Vol. 15. Elsevier, 65–118. doi:10.1016/S0065-2458(08)60520-3
-
[26]
Rebecca Roelofs, Vaishaal Shankar, Benjamin Recht, Sara Fridovich-Keil, Moritz Hardt, John Miller, and Ludwig Schmidt. 2019. A Meta-Analysis of Overfitting in Machine Learning. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Associates, Inc. http...
2019
-
[27]
Alan Said and Alejandro Bellogín. 2014. Comparative recommender system evaluation: benchmarking recommendation frameworks. InProceedings of the 8th ACM Conference on Recommender Systems(Foster City, Silicon Valley, California, USA)(RecSys ’14). Association for Computing Machinery, New York, NY, USA, 129–136. doi:10.1145/2645710.2645746
-
[28]
Valeriy Shevchenko et al. 2024. From Variability to Stability: Advancing RecSys Benchmarking Practices. InACM SIGKDD Conference(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 5701–5712. doi:10.1145/3637528.3671655
-
[29]
Jasper Snoek, Hugo Larochelle, and Ryan Adams. 2012. Practical Bayesian Optimization of Machine Learning Algorithms. InAdvances in Neural Information Processing Systems, F. Pereira, C.J. Burges, L. Bottou, and K. Weinberger (Eds.), Vol. 25. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/ 2012/file/05311655a15b75fab86956663e1819cd...
arXiv 2012
-
[30]
Kakade, and Matthias W
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger
-
[31]
Information-Theoretic Regret Bounds for Gaussian Process Optimization in the Bandit Setting.IEEE Transactions on Information Theory58, 5 (2012), 3250–3265. doi:10.1109/TIT.2011.2182033
-
[32]
Jeyan Thiyagalingam, Mallikarjun Shankar, Geoffrey Fox, and Tony Hey. 2022. Scientific machine learning benchmarks.Nature Reviews Physics4, 6 (2022), 413–420
2022
-
[33]
Jan van Rijn et al . 2013. OpenML: A Collaborative Science Platform.Lecture Notes in Computer Science8190, 645–649. doi:10.1007/978-3-642-40994-3_46
-
[34]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. SuperGLUE: A Stick- ier Benchmark for General-Purpose Language Understanding Systems. 3261– 3275 pages. http://papers.nips.cc/paper/8589-superglue-a-stickier-benchmark- for-general-purpose-language-understanding-systems
2019
-
[35]
Mark Wilkinson et al . 2016. The FAIR Guiding Principles for scientific data management and stewardship.Scientific Data3 (03 2016)
2016
-
[36]
Chhavi Yadav and Léon Bottou. 2019. Cold Case: The Lost MNIST Digits. 13443– 13452 pages
2019
-
[37]
Xiaohua Zhai et al. 2020. A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark. (2020). arXiv:1910.04867 [cs.CV] https: //arxiv.org/abs/1910.04867 A Proofs of the statements in Section 4.1 A.1 Notation and preliminary remarks This appendix provides the auxiliary statements and proofs sup- porting Section 4.1, in particu...
Pith/arXiv arXiv 2020
-
[38]
Thus farthest-first with 𝑑𝑘 is equivalent to Euclidean farthest-first on the normalized set {𝑢𝑥 : 𝑥∈𝐷} , since the square function is monotone and there- fore does not change the maximizer in the greedy step. Conse- quently, the Euclidean covering bound applies to the normalized points: if Δ𝑢 =diam({𝑢 𝑥 : 𝑥∈𝐷}) , then 𝑟 (𝑒) 𝑡 ≤ 2Δ𝑢 /(𝑡 1/𝑝 − 1) and the co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.