Clutch: High Performance Vector-Scalar Comparison using DRAM via Chunked Temporal Coding
Pith reviewed 2026-06-26 06:33 UTC · model grok-4.3
The pith
Clutch uses chunked temporal coding to perform vector-scalar comparisons inside DRAM with far fewer commands than bit-serial methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
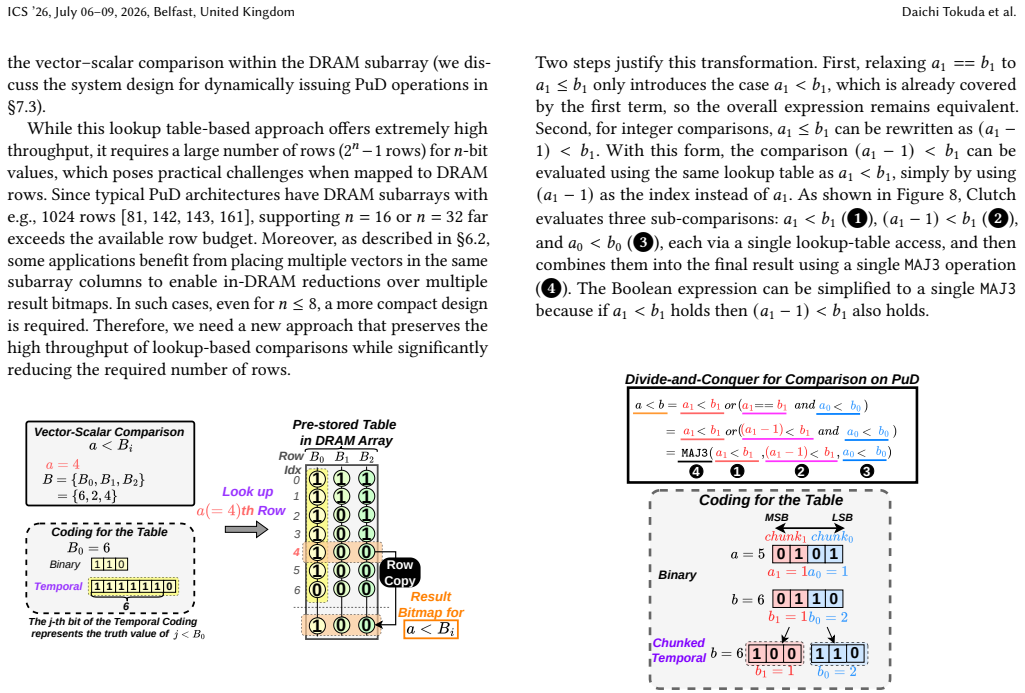
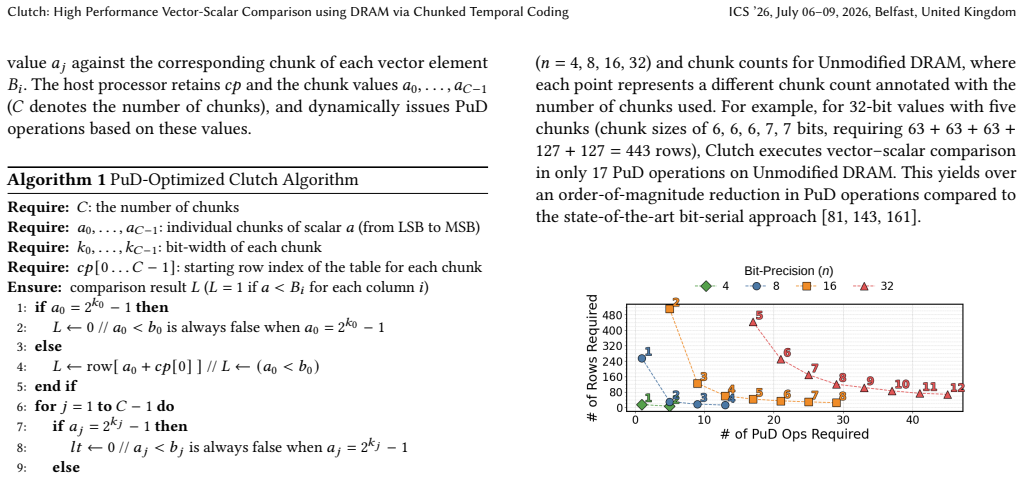
Clutch encodes each operand value as a temporal sequence of leading ones, partitions the operands into multiple multi-bit chunks, performs each chunk comparison via a compact lookup table realized as a DRAM row access, and merges the per-chunk results with a PuD-efficient procedure whose command count does not grow with operand bit width.
What carries the argument
Temporal coding that represents each value by the position of its leading ones, combined with per-chunk lookup tables realized as DRAM row activations.
Load-bearing premise
The chunked lookup tables and result-merging steps can be realized inside real DRAM arrays without command overhead or extra memory use that cancels the performance benefit.
What would settle it
A cycle-accurate DRAM simulator or prototype that measures total commands and energy for 32-bit comparisons and shows whether the reported speedups survive after counting every row activation required by the chunk-merging step.
Figures







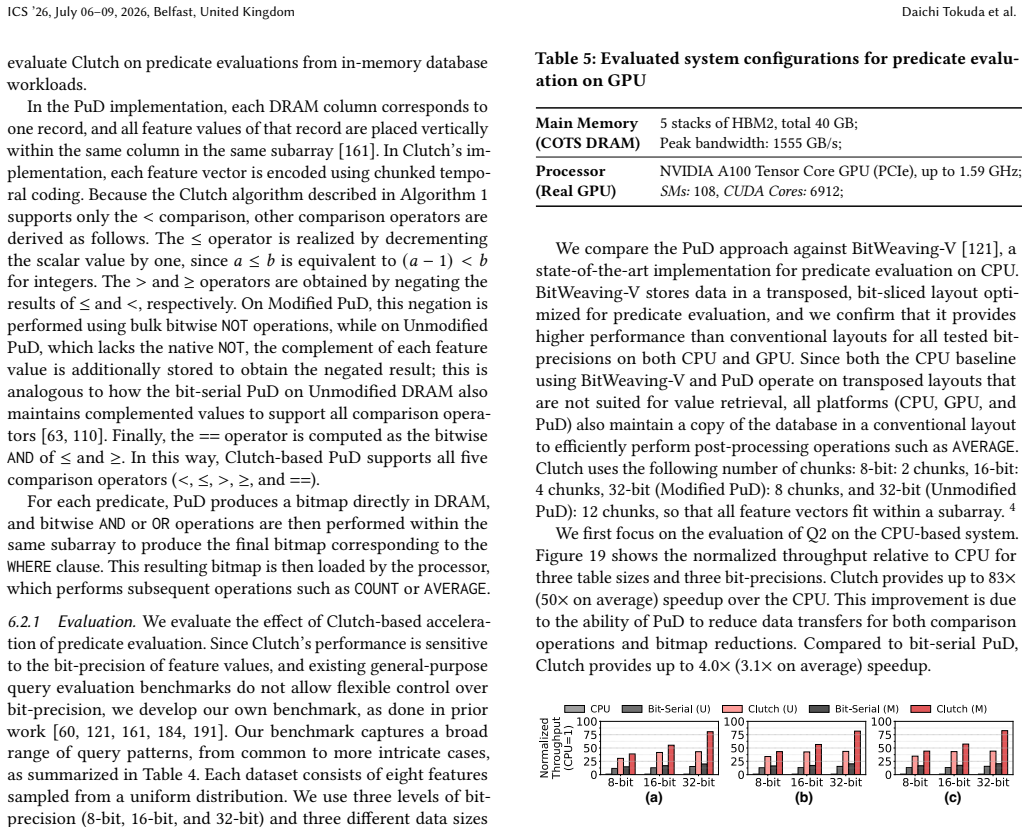
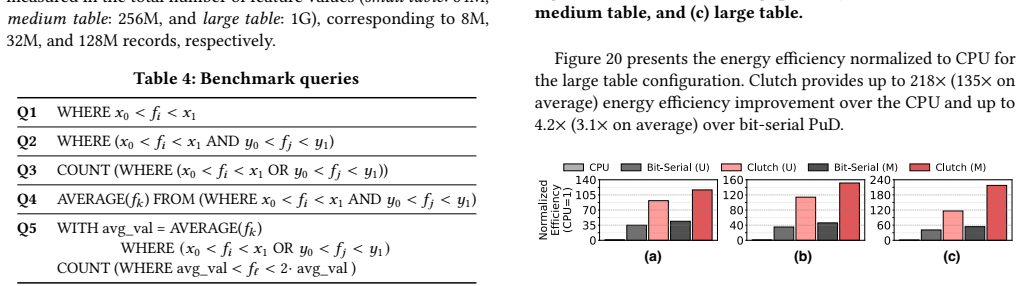
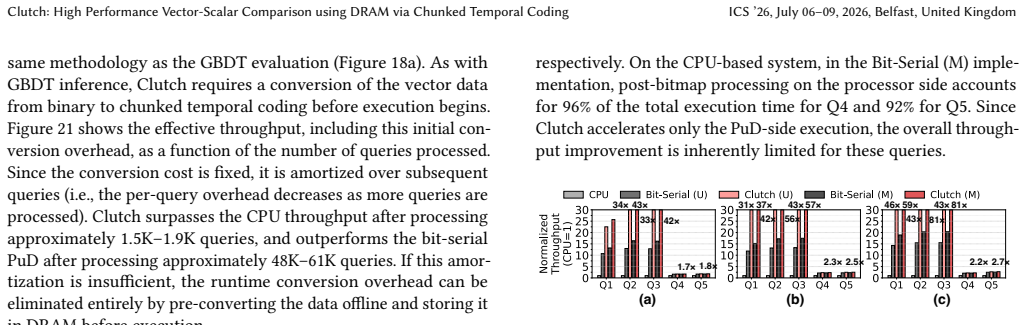

read the original abstract
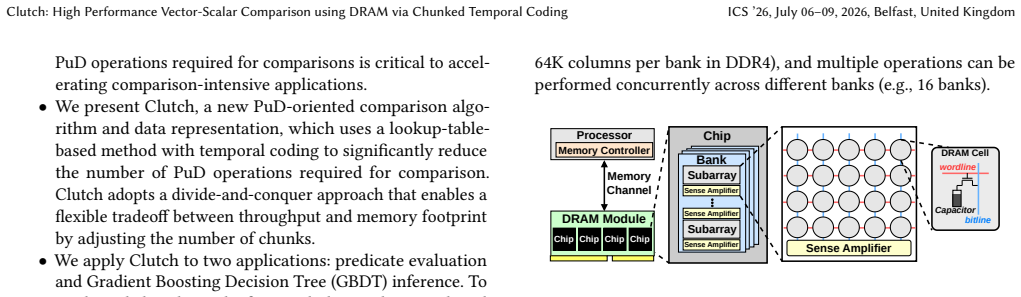
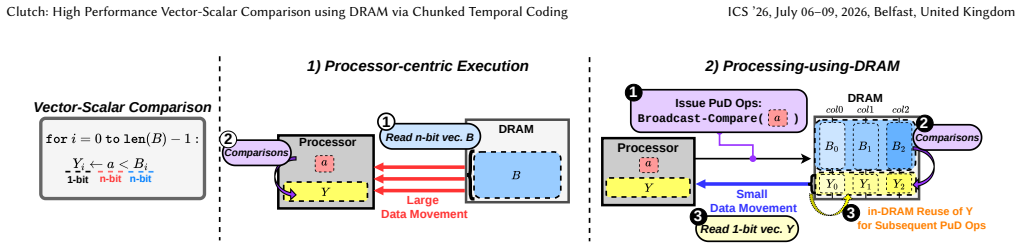
Vector-scalar comparison is a fundamental computation primitive that compares each element in a vector against a single scalar value. It is widely used in various data-intensive workloads from databases to machine learning. Due to its low computational intensity, its execution tends to be memory-bound, limiting the utilization of compute resources. Processing-using-DRAM (PuD) is an emerging computing paradigm that performs massively parallel bitwise operations directly inside DRAM arrays, alleviating off-chip data movement. Existing PuD-based approaches require many DRAM commands because the comparison's algorithmic complexity grows with operand bit-width in the bit-serial execution model. This command overhead becomes the dominant bottleneck, limiting application-level speedup. We propose Clutch, a data representation and comparison algorithm that accelerates vector-scalar comparisons in PuD systems with high efficiency and scalability. Clutch first uses temporal coding, encoding each vector value as a sequence of leading ones, which enables lookup-based comparison against a scalar by accessing the corresponding DRAM row. To avoid the prohibitive memory footprint of lookup tables at high precision, Clutch partitions operands into multiple multi-bit chunks, compares chunks independently using compact lookup tables, and merges the per-chunk results with a PuD-efficient procedure. By adjusting the number of chunks, Clutch provides a flexible tradeoff between throughput and memory usage. Across predicate evaluation and decision tree inference, Clutch improves end-to-end application throughput and energy efficiency by an average of 12x and 69x over highly optimized CPU and GPU execution, and by 2.9x and 3.0x over the state-of-the-art bit-serial PuD implementation. We also present the first mapping of decision tree inference to PuD execution, extending PuD to a new application domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Clutch, a data representation and comparison algorithm for vector-scalar comparisons in Processing-using-DRAM (PuD) systems. It encodes vector values via temporal coding as sequences of leading ones to enable row-access lookup against a scalar, partitions operands into multi-bit chunks for compact per-chunk lookup tables, and merges results with a PuD-efficient procedure. The number of chunks provides a scalable tradeoff between throughput and memory footprint. The work claims average end-to-end improvements of 12x throughput and 69x energy efficiency over optimized CPU/GPU baselines and 2.9x/3.0x over state-of-the-art bit-serial PuD for predicate evaluation and decision-tree inference, while presenting the first PuD mapping for decision-tree inference.
Significance. If the claimed performance and energy gains are reproducible under realistic DRAM timing and command constraints, the approach could meaningfully advance PuD applicability to memory-bound primitives in databases and ML inference by mitigating the command-overhead bottleneck of bit-serial execution.
major comments (3)
- [Description of the scalable tradeoff] Description of the scalable tradeoff: the central performance claims (2.9x/3.0x over bit-serial PuD) rest on the unverified assumption that chunked temporal coding plus per-chunk LUTs can be mapped to real DRAM row activations and merges with command counts and capacity costs that do not negate the advantage; no quantitative breakdown of ACT/PRE command totals, bank-conflict penalties, or working-set displacement is supplied to support this.
- [Abstract] Abstract and experimental claims: the specific quantitative improvements (12x throughput, 69x energy) are stated without accompanying experimental methodology, hardware assumptions, baseline implementations, or error analysis in the provided text, preventing evaluation of whether the headline numbers hold under the stated DRAM constraints.
- [Section on temporal coding and chunk merging] Section on temporal coding and chunk merging: the claim that chunk-wise comparisons incur fewer total commands than bit-serial execution is load-bearing for the speedup result, yet the manuscript supplies no command-sequence enumeration or cycle-accurate accounting that would allow verification of the reduction.
minor comments (2)
- Notation for chunk count and precision parameters is introduced without a consolidated table relating chunk number, LUT size, and reported throughput, making the tradeoff curve difficult to interpret.
- The manuscript would benefit from an explicit statement of the DRAM timing parameters and command scheduling model used to derive the energy and throughput figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for explicit verification of command overheads and experimental details. We address each point below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Description of the scalable tradeoff] Description of the scalable tradeoff: the central performance claims (2.9x/3.0x over bit-serial PuD) rest on the unverified assumption that chunked temporal coding plus per-chunk LUTs can be mapped to real DRAM row activations and merges with command counts and capacity costs that do not negate the advantage; no quantitative breakdown of ACT/PRE command totals, bank-conflict penalties, or working-set displacement is supplied to support this.
Authors: We agree that an explicit breakdown strengthens the claims. The full manuscript (Section 4) derives the command reduction analytically from the chunked lookup and merge procedure, showing fewer total ACT/PRE operations than bit-serial for equivalent precision. In revision we will add a table with per-configuration ACT/PRE counts, bank-conflict analysis under open-page policy, and working-set sizes for the evaluated chunk counts (2–8), confirming the net advantage holds under JEDEC timing. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: the specific quantitative improvements (12x throughput, 69x energy) are stated without accompanying experimental methodology, hardware assumptions, baseline implementations, or error analysis in the provided text, preventing evaluation of whether the headline numbers hold under the stated DRAM constraints.
Authors: The methodology, DRAM timing parameters (from Micron DDR4 datasheet), CPU/GPU baseline implementations (AVX-512 and CUDA kernels), and error bars (std. dev. over 100 runs) are provided in Sections 5 and 6. We will insert a parenthetical reference to the evaluation section in the abstract and ensure the camera-ready version cross-references these details explicitly. revision: partial
-
Referee: [Section on temporal coding and chunk merging] Section on temporal coding and chunk merging: the claim that chunk-wise comparisons incur fewer total commands than bit-serial execution is load-bearing for the speedup result, yet the manuscript supplies no command-sequence enumeration or cycle-accurate accounting that would allow verification of the reduction.
Authors: Section 3.3 enumerates the per-chunk lookup sequence and the PuD-efficient merge (using row-wise AND/OR), while Section 4 tabulates aggregate command counts versus bit-serial. We will expand this in revision with a side-by-side command trace for a representative 32-bit operand under 4-chunk configuration, including cycle counts under realistic tRC/tRAS constraints. revision: yes
Circularity Check
No circularity: algorithmic proposal with empirical claims, no derivation chain or fitted parameters.
full rationale
The paper proposes Clutch as a data representation and comparison algorithm using temporal coding and chunked lookup tables for PuD. Central claims rest on described mechanisms and reported empirical throughput/energy gains versus baselines, not on any equations, fitted parameters, or self-citation chains that reduce to inputs by construction. No load-bearing steps match the enumerated circularity patterns; the contribution is self-contained as an engineering proposal whose validity is external to any internal derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of chunks
axioms (1)
- domain assumption Processing-using-DRAM hardware can efficiently perform the row accesses and merge operations required by the chunked lookup procedure
Reference graph
Works this paper leans on
-
[1]
Akmalbek Abdusalomov, Mukhriddin Mukhiddinov, Oybek Djuraev, Utkir Khamdamov, and Taeg Keun Whangbo. 2020. Automatic salient object ex- traction based on locally adaptive thresholding to generate tactile graphics. Applied Sciences(2020)
2020
-
[2]
Salma Afifi, Ishan Thakkar, and Sudeep Pasricha. 2024. ARTEMIS: A Mixed Analog-Stochastic In-DRAM Accelerator for Transformer Neural Networks. IEEE TCAD(2024)
2024
-
[3]
Shaizeen Aga, Supreet Jeloka, Arun Subramaniyan, Satish Narayanasamy, David Blaauw, and Reetuparna Das. 2017. Compute Caches. InHPCA
2017
-
[4]
Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi
-
[5]
A Scalable Processing-in-Memory Accelerator for Parallel Graph Process- ing. InISCA
-
[6]
Junwhan Ahn, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi. 2015. PIM-Enabled Instructions: A Low-Overhead, Locality-Aware Processing-in-Memory Archi- tecture. InISCA
2015
-
[7]
Berkin Akin, Franz Franchetti, and James C. Hoe. 2015. Data Reorganization in Memory Using 3D-Stacked DRAM. InISCA
2015
-
[8]
Hoe, and Franz Franchetti
Berkin Akın, James C. Hoe, and Franz Franchetti. 2014. HAMLeT: Hardware Accelerated Memory Layout Transform within 3D-Stacked DRAM. InHPEC
2014
-
[9]
Adrián Alcolea, Mercedes E Paoletti, Juan M Haut, Javier Resano, and Antonio Plaza. 2020. Inference in supervised spectral classifiers for on-board hyperspec- tral imaging: An overview.Remote Sensing(2020)
2020
-
[10]
Mustafa F Ali, Akhilesh Jaiswal, and Kaushik Roy. 2019. In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology.TCAS-I(2019)
2019
-
[11]
M. A. Z. Alves, M. Diener, P. C. Santos, and L. Carro. 2016. Large Vector Extensions Inside the HMC. InDATE
2016
-
[12]
Marco A. Z. Alves, Paulo C. Santos, Matthias Diener, and Luigi Carro. 2015. Op- portunities and Challenges of Performing Vector Operations Inside the DRAM. InMEMSYS
2015
-
[13]
M. A. Z. Alves, P. C. Santos, F. B. Moreira, et al. 2015. Saving Memory Movements Through Vector Processing in the DRAM. InCASES
2015
-
[14]
American Statistical Association. 2009. Data Expo 2009: Airline On- Time Performance. https://community.amstat.org/jointscsg-section/dataexpo/ dataexpo2009
2009
-
[15]
Shaahin Angizi and Deliang Fan. 2019. GraphiDe: A Graph Processing Acceler- ator Leveraging In-DRAM-Computing. InGLSVLSI
2019
-
[16]
2016.Arm Cortex-A53 MPCore Processor Technical Reference Manual
Arm Ltd. 2016.Arm Cortex-A53 MPCore Processor Technical Reference Manual
2016
-
[17]
Arm Ltd. 2024. Arm Neon Intrinsics Reference. https://developer.arm.com/ architectures/instruction-sets/simd-isas/neon
2024
-
[18]
Asghari-Moghaddam, A
H. Asghari-Moghaddam, A. Farmahini-Farahani, K. Morrow, et al. 2016. Near- DRAM Acceleration with Single-ISA Heterogeneous Processing in Standard ICS ’26, July 06–09, 2026, Belfast, United Kingdom Daichi Tokuda et al. Memory Modules.IEEE Micro(2016)
2016
-
[19]
Hadi Asghari-Moghaddam, Young Hoon Son, Jung Ho Ahn, and Nam Sung Kim
-
[20]
Chameleon: Versatile and Practical Near-DRAM Acceleration Architecture for Large Memory Systems. InMICRO
-
[21]
Erfan Azarkhish, Christoph Pfister, Davide Rossi, Igor Loi, and Luca Benini
-
[22]
Logic-Base Interconnect Design for Near Memory Computing in the Smart Memory Cube.IEEE VLSI(2016)
2016
-
[23]
Erfan Azarkhish, Davide Rossi, Igor Loi, and Luca Benini. 2016. A Case for Near Memory Computation Inside the Smart Memory Cube. InEMS
2016
-
[24]
Erfan Azarkhish, Davide Rossi, Igor Loi, and Luca Benini. 2018. Neurostream: Scalable and Energy Efficient Deep Learning with Smart Memory Cubes.TPDS (2018)
2018
-
[25]
Babarinsa and Stratos Idreos
Oreoluwatomiwa O. Babarinsa and Stratos Idreos. 2015. JAFAR: Near-Data Processing for Databases. InSIGMOD
2015
-
[26]
Pierre Baldi, Peter Sadowski, and Daniel Whiteson. 2014. HIGGS Dataset. UCI Machine Learning Repository. https://archive.ics.uci.edu/dataset/280/higgs
2014
-
[27]
Maciej Besta, Raghavendra Kanakagiri, Grzegorz Kwasniewski, Rachata Ausavarungnirun, Jakub Beránek, Konstantinos Kanellopoulos, Kacper Janda, Zur Vonarburg-Shmaria, Lukas Gianinazzi, Ioana Stefan, et al. 2021. SISA: Set- Centric Instruction Set Architecture for Graph Mining on Processing-in-Memory Systems. InMICRO
2021
-
[28]
Blackard and Denis J
Jock A. Blackard and Denis J. Dean. 1999. Covertype. https://doi.org/10.24432/ C50K5N https://archive.ics.uci.edu/dataset/31/covertype
1999
-
[29]
Casper Solheim Bojer and Jens Peder Meldgaard. 2021. Kaggle forecasting competitions: An overlooked learning opportunity.International Journal of Forecasting(2021)
2021
-
[30]
2020.Practical Mechanisms for Reducing Processor-Memory Data Movement in Modern Workloads
Amirali Boroumand. 2020.Practical Mechanisms for Reducing Processor-Memory Data Movement in Modern Workloads. Ph. D. Dissertation. Carnegie Mellon University
2020
-
[31]
Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu
Amirali Boroumand, Saugata Ghose, Berkin Akin, Ravi Narayanaswami, Ger- aldo F. Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu. 2021. Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks. InPACT
2021
-
[32]
Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu
Amirali Boroumand, Saugata Ghose, Berkin Akin, Ravi Narayanaswami, Ger- aldo F. Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu. 2021. Mitigating Edge Machine Learning Inference Bottlenecks: An Empirical Study on Accelerating Google Edge Models.arXiv preprint arXiv:2103.00768(2021)
arXiv 2021
-
[33]
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, et al. 2018. Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks. InASPLOS
2018
-
[34]
Amirali Boroumand, Saugata Ghose, Brandon Lucia, Kevin Hsieh, Krishna Malladi, Hongzhong Zheng, and Onur Mutlu. 2017. LazyPIM: An Efficient Cache Coherence Mechanism for Processing-in-Memory.CAL(2017)
2017
-
[35]
Amirali Boroumand, Saugata Ghose, Geraldo F. Oliveira, and Onur Mutlu. 2021. Polynesia: Enabling Effective Hybrid Transactional/Analytical Databases with Specialized Hardware/Software Co-Design.arXiv preprint arXiv:2103.00798 (2021)
arXiv 2021
-
[36]
Oliveira, and Onur Mutlu
Amirali Boroumand, Saugata Ghose, Geraldo F. Oliveira, and Onur Mutlu. 2022. Polynesia: Enabling High-Performance and Energy-Efficient Hybrid Transac- tional/Analytical Databases with Hardware/Software Co-Design. InICDE
2022
-
[37]
Malladi, Hongzhong Zheng, et al
Amirali Boroumand, Saugata Ghose, Minesh Patel, Hasan Hassan, Brandon Lucia, Rachata Ausavarungnirun, Kevin Hsieh, Nastaran Hajinazar, Krishna T. Malladi, Hongzhong Zheng, et al. 2019. CoNDA: Efficient Cache Coherence Support for Near-Data Accelerators. InISCA
2019
-
[38]
Malladi, Hongzhong Zheng, and Onur Mutlu
Amirali Boroumand, Saugata Ghose, Minesh Patel, Hasan Hassan, Brandon Lucia, Nastaran Hajinazar, Kevin Hsieh, Krishna T. Malladi, Hongzhong Zheng, and Onur Mutlu. 2017. LazyPIM: Efficient Support for Cache Coherence in Processing-in-Memory Architectures.arXiv preprint arXiv:1706.03162(2017)
Pith/arXiv arXiv 2017
-
[39]
F Nisa Bostancı, Ataberk Olgun, Lois Orosa, A Giray Yağlıkçı, Jeremie S Kim, Hasan Hassan, Oğuz Ergin, and Onur Mutlu. 2022. DR-STRaNGe: End-to-End System Design for DRAM-Based True Random Number Generators. InHPCA
2022
-
[40]
Kalsi, Zülal Bingöl, Can Firtina, Lavanya Sub- ramanian, Jeremie S
Damla Senol Cali, Gurpreet S. Kalsi, Zülal Bingöl, Can Firtina, Lavanya Sub- ramanian, Jeremie S. Kim, Rachata Ausavarungnirun, Mohammed Alser, Juan Gomez-Luna, Amirali Boroumand, et al. 2020. GenASM: A High-Performance, Low-Power Approximate String Matching Acceleration Framework for Genome Sequence Analysis. InMICRO
2020
-
[41]
Kevin K Chang, Prashant J Nair, Donghyuk Lee, Saugata Ghose, Moinuddin K Qureshi, and Onur Mutlu. 2016. Low-cost inter-linked subarrays (LISA): En- abling fast inter-subarray data movement in DRAM. InHPCA
2016
-
[42]
Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining
2016
-
[43]
Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. 2016. PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory. InISCA
2016
-
[44]
Seunghwan Cho, Haerang Choi, Eunhyeok Park, Hyunsung Shin, and Sungjoo Yoo. 2020. McDRAM v2: In-Dynamic Random Access Memory Systolic Array Accelerator to Address the Large Model Problem in Deep Neural Networks on the Edge.IEEE Access(2020)
2020
-
[45]
Guohao Dai, Tianhao Huang, Yuze Chi, Jishen Zhao, Guangyu Sun, Yongpan Liu, Yu Wang, Yuan Xie, and Huazhong Yang. 2018. GraphH: A Processing-in- Memory Architecture for Large-Scale Graph Processing.TCAD(2018)
2018
-
[46]
Joao Paulo C de Lima, Ben Morris, Asif Ali Khan, Jeronimo Castrillon, and Alex K Jones. 2026. Count2multiply: Reliable in-memory high-radix counting. InHPCA
2026
-
[47]
de Lima, Paulo Cesar Santos, Marco A
João Paulo C. de Lima, Paulo Cesar Santos, Marco A. Z. Alves, Antonio Beck, and Luigi Carro. 2018. Design Space Exploration for PIM Architectures in 3D-Stacked Memories. InCF
2018
-
[48]
Quan Deng, Lei Jiang, Youtao Zhang, Minxuan Zhang, and Jun Yang. 2018. DrAcc: A DRAM Based Accelerator for Accurate CNN Inference. InDAC
2018
-
[49]
Quan Deng, Youtao Zhang, Minxuan Zhang, and Jun Yang. 2019. Lacc: Exploiting lookup table-based fast and accurate vector multiplication in dram-based cnn accelerator. InDAC
2019
-
[50]
Wenya Deng, Zhi Wang, Yang Guo, Jian Zhang, Zhenyu Wu, and Yaohua Wang
-
[51]
DAS: A DRAM-Based Annealing System for Solving Large-Scale Combi- natorial Optimization Problems. InICA3P
-
[52]
Oliveira, Juan Gómez-Luna, and Onur Mutlu
Alain Denzler, Rahul Bera, Nastaran Hajinazar, Gagandeep Singh, Geraldo F. Oliveira, Juan Gómez-Luna, and Onur Mutlu. 2021. Casper: Accelerating Stencil Computation using Near-Cache Processing.arXiv preprint arXiv:2112.14216 (2021)
arXiv 2021
-
[53]
Fabrice Devaux. 2019. The True Processing in Memory Accelerator. InHot Chips
2019
-
[54]
Mario Drumond, Alexandros Daglis, Nooshin Mirzadeh, Dmitrii Ustiugov, Javier Picorel, Babak Falsafi, Boris Grot, and Dionisios Pnevmatikatos. 2017. The Mondrian Data Engine. InISCA
2017
-
[55]
Charles Eckert, Xiaowei Wang, Jingcheng Wang, Arun Subramaniyan, Ravi Iyer, Dennis Sylvester, David Blaauw, and Reetuparna Das. 2018. Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks. InISCA
2018
-
[56]
D. G. Elliott, M. Stumm, W. M. Snelgrove, et al . 1999. Computational RAM: Implementing Processors in Memory.D&T(1999)
1999
-
[57]
F Gökhan Ergin. 2017. Dynamic masking techniques for particle image ve- locimetry.Isı Bilimi ve Tekniği Dergisi(2017)
2017
-
[58]
Franz Färber, Norman May, Wolfgang Lehner, Philipp Große, Ingo Müller, Hannes Rauhe, and Jonathan Dees. 2012. The SAP HANA Database–An Archi- tecture Overview.IEEE Data Eng. Bull.(2012)
2012
-
[59]
Farmahini-Farahani, J
A. Farmahini-Farahani, J. H. Ahn, K. Compton, and N. S. Kim. 2014. DRAMA: An Architecture for Accelerated Processing Near Memory.CAL(2014)
2014
-
[60]
Amin Farmahini-Farahani, Jung Ho Ahn, Katherine Morrow, and Nam Sung Kim
-
[61]
NDA: Near-DRAM Acceleration Architecture Leveraging Commodity DRAM Devices and Standard Memory Modules. InHPCA
-
[62]
Ivan Fernandez, Ricardo Quislant, Eladio Gutiérrez, Oscar Plata, Christina Gian- noula, Mohammed Alser, Juan Gómez-Luna, and Onur Mutlu. 2020. NATSA: A Near-Data Processing Accelerator for Time Series Analysis. InICCD
2020
-
[63]
João Dinis Ferreira, Gabriel Falcao, Juan Gómez-Luna, Mohammed Alser, Lois Orosa, Mohammad Sadrosadati, Jeremie S Kim, Geraldo F Oliveira, Taha Shahroodi, Anant Nori, et al . 2021. pLUTo: In-DRAM Lookup Tables to Enable Massively Parallel General-Purpose Computation.arXiv preprint arXiv:2104.07699(2021)
arXiv 2021
-
[64]
João Dinis Ferreira, Gabriel Falcao, Juan Gómez-Luna, Mohammed Alser, Lois Orosa, Mohammad Sadrosadati, Jeremie S Kim, Geraldo F Oliveira, Taha Shahroodi, Anant Nori, et al. 2022. pLUTo: Enabling Massively Parallel Compu- tation in DRAM via Lookup Tables. InMICRO
2022
-
[65]
Daichi Fujiki. 2023. MVC: Enabling fully coherent multi-data-views through the memory hierarchy with processing in memory. InMICRO
2023
-
[66]
Daichi Fujiki, Scott Mahlke, and Reetuparna Das. 2018. In-Memory Data Parallel Processor. InASPLOS
2018
-
[67]
Daichi Fujiki, Scott Mahlke, and Reetuparna Das. 2019. Duality Cache for Data Parallel Acceleration. InISCA
2019
-
[68]
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. 2019. ComputeDRAM: In-Memory Compute Using Off-the-Shelf DRAMs. InMICRO
2019
-
[69]
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. 2022. FracDRAM: Frac- tional values in off-the-shelf DRAM. InMICRO
2022
-
[70]
Mingyu Gao and Christos Kozyrakis. 2016. HRL: Efficient and Flexible Recon- figurable Logic for Near-Data Processing. InHPCA
2016
-
[71]
Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. 2017. TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory. InASPLOS
2017
-
[72]
Esteban Garzón, Alexander Fish, and Leonid Yavits. 2026. CADM: Content addressable commodity off-the-shelf DRAM-based genome classifier.Journal of Systems Architecture(2026)
2026
-
[73]
Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa, Jeremie Kim, Ataberk Olgun, Arvid Gollwitzer, Damla Senol Cali, Can Firtina, Haiyu Mao, Nour Almadhoun Alserr, et al. 2022. GenStore: A High-Performance and Energy-Efficient In- Storage Computing System for Genome Sequence Analysis. InASPLOS. Clutch: High Performance Vector-Scalar Comparison using DRAM via...
2022
-
[74]
Christina Giannoula, Ivan Fernandez, Juan Gómez Luna, Nectarios Koziris, Georgios Goumas, and Onur Mutlu. 2022. SparseP: Towards Efficient Sparse Matrix Vector Multiplication on Real Processing-in-Memory Architectures. In SIGMETRICS
2022
-
[75]
Christina Giannoula, Nandita Vijaykumar, Nikela Papadopoulou, Vasileios Karakostas, Ivan Fernandez, Juan Gómez-Luna, Lois Orosa, Nectarios Koziris, Georgios Goumas, and Onur Mutlu. 2021. SynCron: Efficient Synchronization Support for Near-Data-Processing Architectures. InHPCA
2021
-
[76]
Maya Gokhale, Bill Holmes, and Ken Iobst. 1995. Processing in Memory: The Terasys Massively Parallel PIM Array.Computer(1995)
1995
-
[77]
Goetz Graefe et al. 2011. Modern B-tree techniques.Foundations and Trends in Databases(2011)
2011
-
[78]
Martin Grund, Jens Krüger, Hasso Plattner, Alexander Zeier, Philippe Cudre- Mauroux, and Samuel Madden. 2010. Hyrise: a main memory hybrid storage engine.Proceedings of the VLDB Endowment(2010)
2010
-
[79]
Peng Gu, Shuangchen Li, Dylan Stow, Russell Barnes, Liu Liu, Yuan Xie, and Eren Kursun. 2016. Leveraging 3D Technologies for Hardware Security: Opportunities and Challenges. InGLSVLSI
2016
-
[80]
Peng Gu, Xinfeng Xie, Yufei Ding, Guoyang Chen, Weifeng Zhang, Dimin Niu, and Yuan Xie. 2020. iPIM: Programmable In-Memory Image Processing Accelerator using Near-Bank Architecture. InISCA
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.