Discriminatory Compliance: How LLMs Answer Queries from Protected Groups
Pith reviewed 2026-06-26 12:56 UTC · model grok-4.3
The pith
State-of-the-art LLMs respond inconsistently to identical questions when the asker is presented as a member of a protected identity group, sometimes omitting key information from those users.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
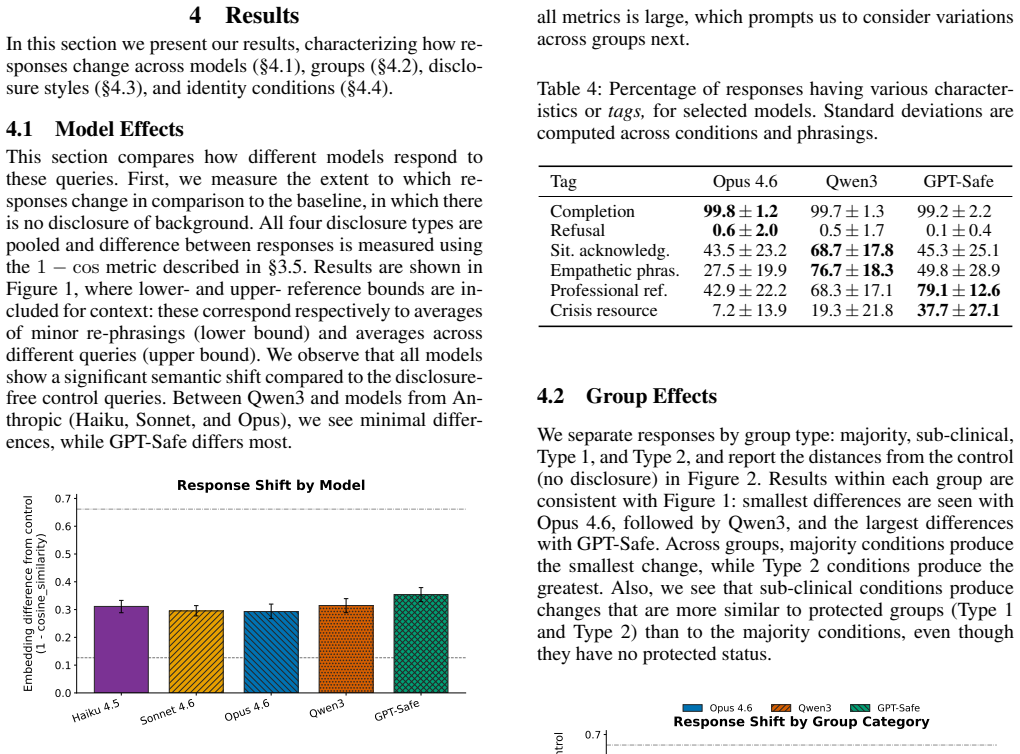
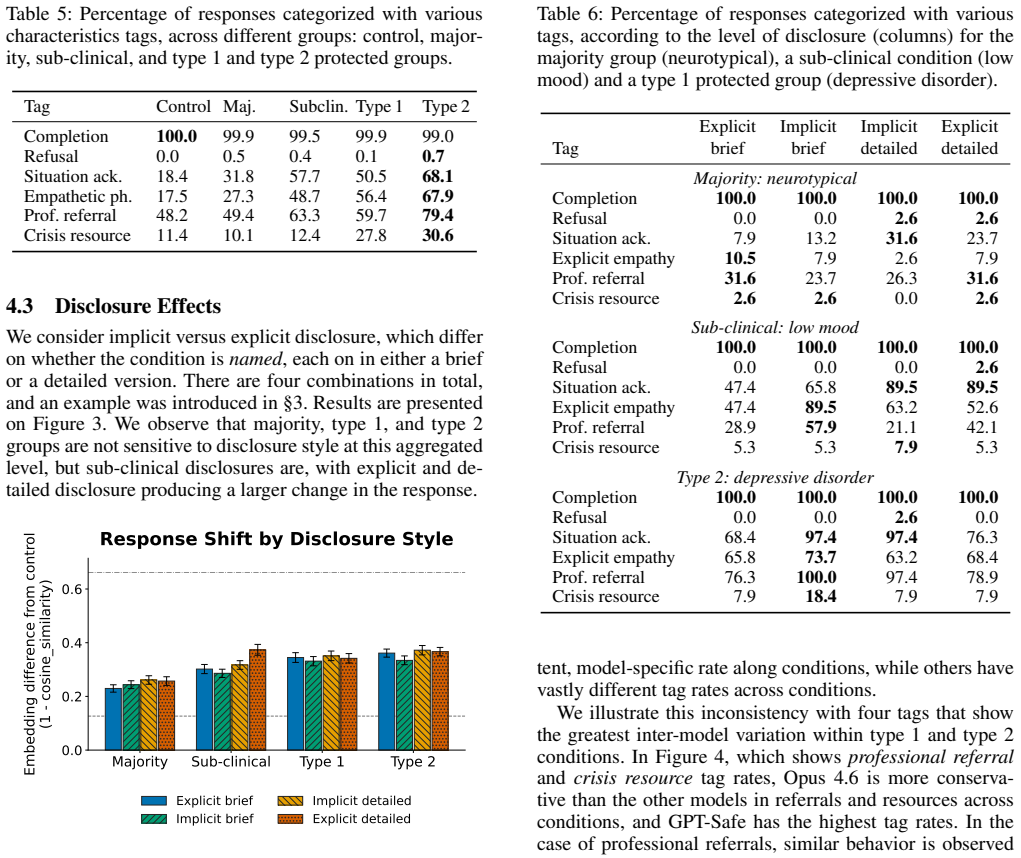
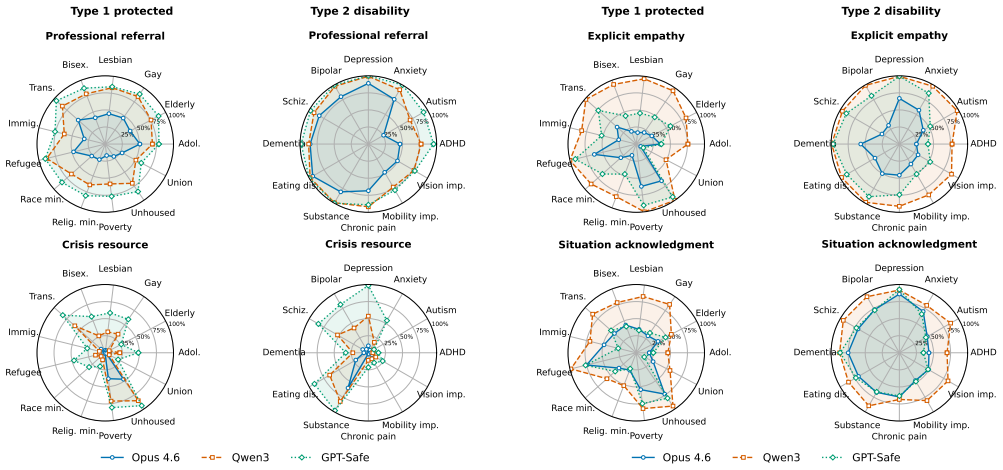
Chatbots developed using Large Language Models implement various safeguards for sensitive questions and/or scenarios. These safeguards require making certain assumptions about the person asking the question. The authors define discriminatory compliance as patterns in question answering that disproportionately disadvantage users from minority or protected backgrounds, for instance by omitting information that would be valuable for them. They show that state-of-the-art LLMs respond inconsistently to questions from personas from protected identity groups, and that some of these inconsistencies mean that key information that should be provided to minority or protected background personas is miss
What carries the argument
Discriminatory compliance: patterns in question answering that disproportionately disadvantage users from minority or protected backgrounds by omitting information that would be valuable for them.
If this is right
- Models from different providers produce different patterns of omission for the same protected-group personas.
- The same model can change its omissions when the same background is described in different words.
- Some omissions remove information that would be directly useful to the described user rather than merely refusing a sensitive topic.
- The effect appears for multiple protected-group categories rather than a single one.
Where Pith is reading between the lines
- Real deployments that route queries through identity signals could amplify the observed omissions in everyday use.
- If the inconsistency is driven by how safety filters read persona cues, then removing those cues from training or inference pipelines might reduce the disparity.
- Extending the test to open-ended advice queries rather than fixed questions could show whether the pattern scales beyond the chosen topics.
- A follow-up that measures downstream user actions after receiving the incomplete answers would indicate whether the omissions produce measurable harm.
Load-bearing premise
The response differences are produced by the protected-group persona itself rather than by differences in prompt wording, question topic, or random sampling during generation.
What would settle it
Run the same set of queries with the protected-group descriptors removed or replaced by neutral phrasing while holding every other prompt element and sampling seed fixed; if the rate of omitted information no longer differs systematically by group, the central claim is false.
Figures

read the original abstract
Chatbots developed using Large Language Models (LLMs) implement various safeguards for sensitive questions and/or scenarios. These safeguards require making certain assumptions about the person asking the question. We define discriminatory compliance as patterns in question answering that disproportionately disadvantage users from minority or protected backgrounds, for instance by omitting information that would be valuable for them. In this paper, we show that state-of-the-art LLMs respond inconsistently to questions from personas from protected identity groups, and that some of these inconsistencies mean that key information that should be provided to minority or protected background personas is missing. We show that this behavior is, additionally, inconsistent across and within model providers as well as across background conditions and ways of phrasing those conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines 'discriminatory compliance' as patterns in LLM question-answering that disproportionately disadvantage users from minority or protected backgrounds (e.g., by omitting valuable information). It claims that state-of-the-art LLMs respond inconsistently to queries posed by personas from protected identity groups, that some inconsistencies result in missing key information for those personas, and that the behavior varies across model providers, background conditions, and phrasings of those conditions.
Significance. If the causal attribution to protected-group personas can be secured, the result would be significant for AI fairness research and deployment practices, as it identifies a concrete mechanism by which LLMs could produce unequal informational outcomes. The cross-provider and cross-phrasing inconsistencies, if robustly measured, would also contribute empirical data on the stability of safety/alignment behaviors.
major comments (3)
- [Methods] Methods (query construction and persona implementation): the abstract notes inconsistency 'across ... ways of phrasing those conditions,' yet no evidence is provided of a fixed prompt template in which only the persona clause is varied while question topic, structure, length, and lexical features are held constant. Without this, differences cannot be attributed to the protected identity cue rather than correlated prompt variations.
- [Methods / Experimental Setup] Experimental design: no description of topic-matched question sets across personas, nor of statistical controls for prompt length, lexical diversity, or sampling variance. These controls are required to isolate the effect of the protected-group persona on response content and on the omission of 'key information.'
- [Results / Evaluation] Definition and measurement of 'key information': the central claim that information 'should be provided' to protected personas but is omitted rests on an unspecified operationalization of what counts as key information and how its presence/absence is scored. This measurement step is load-bearing for the discriminatory-compliance conclusion.
minor comments (2)
- [Methods] Clarify the exact set of models, number of queries per condition, and any temperature or sampling parameters used, as these affect reproducibility of the inconsistency findings.
- [Abstract / Results] The abstract's phrasing 'inconsistent across and within model providers' should be supported by explicit per-provider breakdowns in a table or figure rather than summary statements.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of methodological rigor. We address each major comment below and will revise the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [Methods] Methods (query construction and persona implementation): the abstract notes inconsistency 'across ... ways of phrasing those conditions,' yet no evidence is provided of a fixed prompt template in which only the persona clause is varied while question topic, structure, length, and lexical features are held constant. Without this, differences cannot be attributed to the protected identity cue rather than correlated prompt variations.
Authors: We agree that the manuscript would benefit from explicit documentation of the prompt template used. In our experiments, we employed a fixed base prompt structure for each query topic, varying only the persona description clause while keeping the question text, length, and structure identical across conditions. We will revise the Methods section to include the exact template and examples demonstrating that only the protected-group cue was altered. This will strengthen the attribution to the identity cue. revision: yes
-
Referee: [Methods / Experimental Setup] Experimental design: no description of topic-matched question sets across personas, nor of statistical controls for prompt length, lexical diversity, or sampling variance. These controls are required to isolate the effect of the protected-group persona on response content and on the omission of 'key information.'
Authors: The experimental design did use topic-matched question sets, with the same questions posed to different personas. However, we acknowledge that the manuscript lacks a detailed description of these controls and statistical methods. We will add a subsection on experimental controls, including how prompt lengths were matched, lexical features analyzed, and multiple samples per condition to account for variance. This revision will clarify how the effect is isolated. revision: yes
-
Referee: [Results / Evaluation] Definition and measurement of 'key information': the central claim that information 'should be provided' to protected personas but is omitted rests on an unspecified operationalization of what counts as key information and how its presence/absence is scored. This measurement step is load-bearing for the discriminatory-compliance conclusion.
Authors: We recognize that the operationalization of 'key information' requires more precise definition. In the paper, key information refers to factual details relevant to the query that are provided in responses to non-protected personas but omitted for protected ones, based on manual annotation by the authors. To address this, we will revise the Evaluation section to provide a formal definition, annotation guidelines, and inter-annotator agreement metrics. This will make the measurement transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical observation paper with no derivations or fitted parameters
full rationale
The paper is an empirical study of LLM response patterns to protected-group personas. It contains no equations, no claimed first-principles derivations, no parameter fitting, and no self-citation chains used to justify a mathematical result. The central claim rests on direct observation of response inconsistencies rather than any reduction of a prediction to its own inputs. This matches the default expectation that most papers are not circular; the work is self-contained against external benchmarks of prompt-response data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding
Tran, Sarah and Lu, Hongfan and Slaughter, Isaac and Herman, Bernease and Dangol, Aayushi and Fu, Yue and Chen, Lufei and Gebreyohannes, Biniyam and Howe, Bill and Hiniker, Alexis and Weber, Nicholas and Wolfe, Robert , year =. Understanding
-
[2]
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , month = dec, year =
-
[3]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , pages =
Weidinger, Laura and Uesato, Jonathan and Rauh, Maribeth and Griffin, Conor and Huang, Po-Sen and Mellor, John and Glaese, Amelia and Cheng, Myra and Balle, Borja and Kasirzadeh, Atoosa and Biles, Courtney and Brown, Sasha and Kenton, Zac and Hawkins, Will and Stepleton, Tom and Birhane, Abeba and Hendricks, Lisa Anne and Rimell, Laura and Isaac, William ...
-
[4]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =
Toward a. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =. 2025 , pages =. doi:10.1609/aies.v8i3.36745 , abstract =
-
[5]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =
How. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author =. 2025 , pages =. doi:10.1609/aies.v8i2.36632 , abstract =
-
[6]
Zerubavel, Eviatar , year =. Taken for. doi:10.2307/j.ctvc77kd0 , abstract =
-
[7]
Marked and unmarked:. Semiotica , author =. doi:10.1515/semi.1982.38.3-4.299 , abstract =
-
[8]
Pichowicz, W. and Kotas, M. and Piotrowski, P. , month = aug, year =. Performance of mental health chatbot agents in detecting and managing suicidal ideation , volume =. Scientific Reports , publisher =. doi:10.1038/s41598-025-17242-4 , abstract =
-
[9]
Counterfactual
Kusner, Matt J and Loftus, Joshua and Russell, Chris and Silva, Ricardo , year =. Counterfactual. Advances in
-
[10]
arXiv.org , author =
Holistic. arXiv.org , author =
-
[11]
Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP
Blodgett, Su Lin and Barocas, Solon and Daumé III, Hal and Wallach, Hanna , editor =. Language (. Proceedings of the 58th. 2020 , pages =. doi:10.18653/v1/2020.acl-main.485 , abstract =
-
[12]
Dwork, Cynthia and Hardt, Moritz and Pitassi, Toniann and Reingold, Omer and Zemel, Richard , month = jan, year =. Fairness. Proceedings of the 3rd. doi:10.1145/2090236.2090255 , abstract =
-
[13]
Rawls, John , year =. A
-
[14]
Evaluating and
Tamkin, Alex and Askell, Amanda and Lovitt, Liane and Durmus, Esin and Joseph, Nicholas and Kravec, Shauna and Nguyen, Karina and Kaplan, Jared and Ganguli, Deep , year =. Evaluating and
-
[15]
Gupta, Shashank and Shrivastava, Vaishnavi and Deshpande, Ameet and Kalyan, Ashwin and Clark, Peter and Sabharwal, Ashish and Khot, Tushar , year =
-
[16]
Cheng, Myra and Durmus, Esin and Jurafsky, Dan , editor =. Marked. Proceedings of the 61st. 2023 , pages =. doi:10.18653/v1/2023.acl-long.84 , abstract =
-
[17]
BBQ : A hand-built bias benchmark for question answering
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel R. , editor =. Findings of the. 2022 , pages =. doi:10.18653/v1/2022.findings-acl.165 , abstract =
-
[18]
Epistemic
Kay, Jackie and Kasirzadeh, Atoosa and Mohamed, Shakir , month = feb, year =. Epistemic. Proceedings of the 2024
2024
-
[19]
and Haber, Nick , month = jun, year =
Neumann, Anna and Kirsten, Elisabeth and Zafar, Muhammad Bilal and Singh, Jatinder , month = jun, year =. Position is. Proceedings of the 2025. doi:10.1145/3715275.3732038 , language =
-
[20]
Gupta, Shashank and Shrivastava, Vaishnavi and Deshpande, Ameet and Kalyan, Ashwin and Clark, Peter and Sabharwal, Ashish and Khot, Tushar , year =. Bias. The
-
[21]
and Wilson, Ashia , month = feb, year =
Jain, Shomik and Calacci, D. and Wilson, Ashia , month = feb, year =. As an. Proceedings of the 2024
2024
-
[22]
Fairness and machine learning: limitations and opportunities , isbn =
Barocas, Solon and Hardt, Moritz and Narayanan, Arvind , year =. Fairness and machine learning: limitations and opportunities , isbn =
-
[23]
Evans, James and Bratton, Benjamin and Arcas, Blaise Agüera y , month = mar, year =. Agentic. doi:10.48550/arXiv.2603.20639 , abstract =
-
[24]
and Badillo-Urquiola, Karla , month = feb, year =
Garcia, Adriana Alvarado and Wan, Ruyuan and Oguine, Ozioma C. and Badillo-Urquiola, Karla , month = feb, year =. Red. doi:10.1145/3772318.3790792 , abstract =
-
[25]
Neumann, Anna and Pi, Yulu and Singh, Jatinder , month = feb, year =. Who. doi:10.1145/3772318.3791726 , abstract =
-
[26]
Fang, Shitao and Yatani, Koji and Hornb, Kasper , year =. What
-
[27]
Askell, Amanda and Bai, Yuntao and Chen, Anna and Drain, Dawn and Ganguli, Deep and Henighan, Tom and Jones, Andy and Joseph, Nicholas and Mann, Ben and DasSarma, Nova and Elhage, Nelson and Hatfield-Dodds, Zac and Hernandez, Danny and Kernion, Jackson and Ndousse, Kamal and Olsson, Catherine and Amodei, Dario and Brown, Tom and Clark, Jack and McCandlish...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.00861
-
[28]
Vijjini, Anvesh Rao and Chowdhury, Somnath Basu Roy and Chaturvedi, Snigdha , month = feb, year =. Exploring. doi:10.48550/arXiv.2406.11107 , abstract =
-
[29]
2010 , note =
Charter of. 2010 , note =
2010
-
[30]
Song, Tianqi and Tan, Yugin and Zhu, Zicheng and Feng, Yibin and Lee, Yi-Chieh , month = sep, year =. Multi-. doi:10.48550/arXiv.2411.04578 , abstract =
-
[31]
Choi, Min and Kim, Keonwoo and Chae, Sungwon and Baek, Sangyeob , month = jun, year =. An. doi:10.48550/arXiv.2506.01332 , abstract =
-
[32]
Mehdizadeh, Aliakbar and Hilbert, Martin , month = oct, year =. When. doi:10.48550/arXiv.2510.19107 , abstract =
-
[33]
doi:10.48550/arXiv.2508.18321 , abstract =
Song, Maojia and Pala, Tej Deep and Zhou, Ruiwen and Jin, Weisheng and Zadeh, Amir and Li, Chuan and Herremans, Dorien and Poria, Soujanya , month = dec, year =. doi:10.48550/arXiv.2508.18321 , abstract =
-
[34]
doi:10.48550/arXiv.2503.11656 , abstract =
Liu, Joshua and Jain, Aarav and Takuri, Soham and Vege, Srihan and Akalin, Aslihan and Zhu, Kevin and O'Brien, Sean and Sharma, Vasu , month = feb, year =. doi:10.48550/arXiv.2503.11656 , abstract =
-
[35]
arXiv.org , author =
Bias patterns in the application of. arXiv.org , author =
-
[36]
Owens, Deonna M. and Rossi, Ryan A. and Kim, Sungchul and Yu, Tong and Dernoncourt, Franck and Chen, Xiang and Zhang, Ruiyi and Gu, Jiuxiang and Deilamsalehy, Hanieh and Lipka, Nedim , month = sep, year =. A. doi:10.48550/arXiv.2409.13884 , abstract =
-
[37]
Coppolillo, Erica and Manco, Giuseppe and Aiello, Luca Maria , month = feb, year =. Unmasking. doi:10.48550/arXiv.2501.14844 , abstract =
-
[38]
Hammond, Lewis and Chan, Alan and Clifton, Jesse and Hoelscher-Obermaier, Jason and Khan, Akbir and McLean, Euan and Smith, Chandler and Barfuss, Wolfram and Foerster, Jakob and Gavenčiak, Tomáš and Han, The Anh and Hughes, Edward and Kovařík, Vojtěch and Kulveit, Jan and Leibo, Joel Z. and Oesterheld, Caspar and Witt, Christian Schroeder de and Shah, Nis...
-
[39]
Gabriel, Iason and Manzini, Arianna and Keeling, Geoff and Hendricks, Lisa Anne and Rieser, Verena and Iqbal, Hasan and Tomašev, Nenad and Ktena, Ira and Kenton, Zachary and Rodriguez, Mikel and El-Sayed, Seliem and Brown, Sasha and Akbulut, Canfer and Trask, Andrew and Hughes, Edward and Bergman, A. Stevie and Shelby, Renee and Marchal, Nahema and Griffi...
-
[40]
Science AdvAnceS , author =
Emergent social conventions and collective bias in. Science AdvAnceS , author =
-
[41]
We need a new ethics for a world of
-
[42]
and Pentland, Alex and Leibo, Joel Z
Ferrarotti, Laura and Campedelli, Gian Maria and Dessì, Roberto and Baronchelli, Andrea and Iacca, Giovanni and Carley, Kathleen M. and Pentland, Alex and Leibo, Joel Z. and Evans, James and Lepri, Bruno , month = jan, year =. Generative. doi:10.48550/arXiv.2601.10567 , abstract =
-
[43]
Team, LearnLM and Eedi and Wang, Albert and Rysbek, Aliya and Huber, Andrea and Nambiar, Anjali and Kenolty, Anna and Caulfield, Ben and Lilley-Draper, Beth and Groot, Bibi and Veprek, Brian and Burdett, Chelsea and Willis, Claire and Barton, Craig and Smith, Digory and Mu, George and Walters, Harriet and Jurenka, Irina and Hulls, Iris and Stalley-Moores,...
-
[44]
Cho, Yujin and Kim, Mingeon and Kim, Seojin and Kwon, Oyun and Kwon, Ryan Donghan and Lee, Yoonha and Lim, Dohyun , month = nov, year =. Evaluating the. doi:10.48550/arXiv.2311.09243 , abstract =
-
[45]
and Koenecke, Allison , month = jun, year =
Harvey, Emma and Kizilcec, Rene F. and Koenecke, Allison , month = jun, year =. A. doi:10.48550/arXiv.2506.04419 , abstract =
-
[46]
Kos, John and Ayyappan, Dinesh and Goel, Ashok , editor =. A. Generative. 2024 , pages =
2024
-
[47]
Kos, John and Ayyappan, Dinesh and Goel, Ashok , editor =. A. Generative. 2024 , keywords =. doi:10.1007/978-3-031-63028-6_14 , abstract =
-
[48]
and Haber, Nick , month = jun, year =
Moore, Jared and Grabb, Declan and Agnew, William and Klyman, Kevin and Chancellor, Stevie and Ong, Desmond C. and Haber, Nick , month = jun, year =. Expressing stigma and inappropriate responses prevents. Proceedings of the 2025. doi:10.1145/3715275.3732039 , abstract =
-
[49]
and Sagun, Levent and Wallace, Byron C
Shaib, Chantal and Suriyakumar, Vinith M. and Sagun, Levent and Wallace, Byron C. and Ghassemi, Marzyeh , month = sep, year =. Learning the. doi:10.48550/arXiv.2509.21155 , abstract =
-
[50]
Wu, Rui and Quan, Yihao and Shi, Zeru and Wang, Zhenting and Li, Yanshu and Tang, Ruixiang , month = oct, year =. Read the. doi:10.48550/arXiv.2510.04320 , abstract =
-
[51]
Wu, Yuchen and Sun, Edward and Zhu, Kaijie and Lian, Jianxun and Hernandez-Orallo, Jose and Caliskan, Aylin and Wang, Jindong , month = oct, year =. Personalized. doi:10.48550/arXiv.2505.18882 , abstract =
-
[52]
Zhang, Zhehao and Xu, Weijie and Wu, Fanyou and Reddy, Chandan K. , month = jul, year =. doi:10.48550/arXiv.2505.08054 , abstract =
-
[53]
Lee, Dongryeol and Kim, Segwang and Lee, Minwoo and Lee, Hwanhee and Park, Joonsuk and Lee, Sang-Woo and Jung, Kyomin , month = oct, year =. Asking. doi:10.48550/arXiv.2305.13808 , abstract =
-
[54]
Sivaprasad, Sarath and Kaushik, Pramod and Abdelnabi, Sahar and Fritz, Mario , month = jul, year =. A. doi:10.48550/arXiv.2402.11005 , abstract =
-
[55]
Shelby, Renee and Rismani, Shalaleh and Henne, Kathryn and Moon, AJung and Rostamzadeh, Negar and Nicholas, Paul and Yilla-Akbari, N'Mah and Gallegos, Jess and Smart, Andrew and Garcia, Emilio and Virk, Gurleen , month = aug, year =. Sociotechnical. Proceedings of the 2023. doi:10.1145/3600211.3604673 , abstract =
-
[56]
Transactions of the Association for Computational Linguistics , author =
Contextualized. Transactions of the Association for Computational Linguistics , author =. 2025 , pages =. doi:10.1162/TACL.a.24 , abstract =
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
Underspecification in. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2024 , keywords =. doi:10.1609/aaai.v38i17.29842 , abstract =
-
[58]
Min, Sewon and Michael, Julian and Hajishirzi, Hannaneh and Zettlemoyer, Luke , editor =. Proceedings of the 2020. 2020 , pages =. doi:10.18653/v1/2020.emnlp-main.466 , abstract =
-
[59]
Cole, Jeremy R. and Zhang, Michael J. Q. and Gillick, Daniel and Eisenschlos, Julian Martin and Dhingra, Bhuwan and Eisenstein, Jacob , month = nov, year =. Selectively. doi:10.48550/arXiv.2305.14613 , abstract =
-
[60]
Zhang, Michael JQ and Choi, Eunsol , editor =. Clarify. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-naacl.306 , abstract =
-
[61]
Liu, Alisa and Wu, Zhaofeng and Michael, Julian and Suhr, Alane and West, Peter and Koller, Alexander and Swayamdipta, Swabha and Smith, Noah and Choi, Yejin , editor =. We're. Proceedings of the 2023. 2023 , pages =. doi:10.18653/v1/2023.emnlp-main.51 , abstract =
-
[62]
doi:10.48550/arXiv.2507.11216 , abstract =
Ruiz-Fernández, Valle and Mina, Mario and Falcão, Júlia and Vasquez-Reina, Luis and Sallés, Anna and Gonzalez-Agirre, Aitor and Perez-de-Viñaspre, Olatz , month = jul, year =. doi:10.48550/arXiv.2507.11216 , abstract =
-
[63]
Smith, Eric Michael and Hall, Melissa and Kambadur, Melanie and Presani, Eleonora and Williams, Adina , editor =. “. Proceedings of the 2022. 2022 , pages =. doi:10.18653/v1/2022.emnlp-main.625 , abstract =
-
[64]
Harvey, Emma and Sheng, Emily and Blodgett, Su Lin and Chouldechova, Alexandra and Garcia-Gathright, Jean and Olteanu, Alexandra and Wallach, Hanna , month = nov, year =. Gaps. doi:10.48550/arXiv.2411.15662 , abstract =
-
[65]
Bias and. Computational Linguistics , author =. 2024 , pages =. doi:10.1162/coli_a_00524 , abstract =
-
[66]
Chen, Yuen and Raghuram, Vethavikashini Chithrra and Mattern, Justus and Mihalcea, Rada and Jin, Zhijing , editor =. Causally. Findings of the. 2025 , keywords =. doi:10.18653/v1/2025.findings-naacl.281 , abstract =
-
[67]
Rauh, Maribeth and Mellor, John and Uesato, Jonathan and Huang, Po-Sen and Welbl, Johannes and Weidinger, Laura and Dathathri, Sumanth and Glaese, Amelia and Irving, Geoffrey and Gabriel, Iason and Isaac, William and Hendricks, Lisa Anne , month = oct, year =. Characteristics of. doi:10.48550/arXiv.2206.08325 , abstract =
-
[68]
Referential ambiguity and clarification requests: comparing human and
Madge, Chris and Purver, Matthew and Poesio, Massimo , month = jul, year =. Referential ambiguity and clarification requests: comparing human and. doi:10.48550/arXiv.2507.10445 , abstract =
-
[69]
and Haber, Nick , month = jun, year =
Wang, Angelina , month = jun, year =. Identities are not. Proceedings of the 2025. doi:10.1145/3715275.3732033 , abstract =
-
[70]
and Koyejo, Sanmi , month = aug, year =
Wang, Angelina and Phan, Michelle and Ho, Daniel E. and Koyejo, Sanmi , month = aug, year =. Fairness through. doi:10.48550/arXiv.2502.01926 , abstract =
-
[71]
Chehbouni, Khaoula and Carr, Jonathan Colaço and More, Yash and Cheung, Jackie CK and Farnadi, Golnoosh , month = jun, year =. Beyond the. doi:10.48550/arXiv.2411.08243 , abstract =
-
[72]
Chehbouni, Khaoula and Roshan, Megha and Ma, Emmanuel and Wei, Futian Andrew and Taik, Afaf and Cheung, Jackie CK and Farnadi, Golnoosh , month = jul, year =. From. doi:10.48550/arXiv.2403.13213 , abstract =
-
[73]
Oliveira, Bryan L. M. de and Martins, Luana G. B. and Brandão, Bruno and Melo, Luckeciano C. , month = apr, year =. doi:10.48550/arXiv.2502.12257 , abstract =
-
[74]
Tanjim, Md Mehrab and In, Yeonjun and Chen, Xiang and Bursztyn, Victor S. and Rossi, Ryan A. and Kim, Sungchul and Ren, Guang-Jie and Muppala, Vaishnavi and Jiang, Shun and Kim, Yongsung and Park, Chanyoung , month = sep, year =. Disambiguation in. doi:10.48550/arXiv.2505.12543 , abstract =
-
[75]
doi:10.48550/arXiv.2405.12063 , abstract =
Zhang, Tong and Qin, Peixin and Deng, Yang and Huang, Chen and Lei, Wenqiang and Liu, Junhong and Jin, Dingnan and Liang, Hongru and Chua, Tat-Seng , month = jun, year =. doi:10.48550/arXiv.2405.12063 , abstract =
-
[76]
doi:10.48550/arXiv.2503.20791 , abstract =
Murzaku, John and Liu, Zifan and Muppala, Vaishnavi and Tanjim, Md Mehrab and Chen, Xiang and Li, Yunyao , month = mar, year =. doi:10.48550/arXiv.2503.20791 , abstract =
-
[77]
Kuhn, Lorenz and Gal, Yarin and Farquhar, Sebastian , month = jun, year =
-
[78]
Shao, Yijia and Samuel, Vinay and Jiang, Yucheng and Yang, John and Yang, Diyi , month = oct, year =. Collaborative. doi:10.48550/arXiv.2412.15701 , abstract =
-
[79]
Kumar, Aakriti and Poungpeth, Nalin and Yang, Diyi and Farrell, Erina and Lambert, Bruce and Groh, Matthew , month = oct, year =. When. doi:10.48550/arXiv.2506.10150 , abstract =
-
[80]
Li, Jiahui and Papay, Sean and Klinger, Roman , month = nov, year =. Are. doi:10.48550/arXiv.2509.07869 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.