Want Better Synthetic Data? Steer It: Activation Steering for Low-Resource Language Generation
Pith reviewed 2026-06-27 00:43 UTC · model grok-4.3
The pith
Steering activations in early layers of LLMs produces more diverse synthetic data for low-resource languages and often improves downstream classifier performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
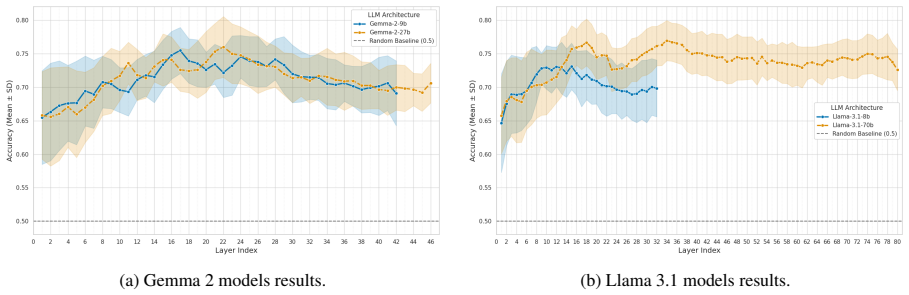
Deriving steering vectors from language-identity contrasts and from human-versus-backtranslated text contrasts, then adding those vectors to hidden states during generation, yields synthetic datasets whose diversity exceeds that of non-steered baselines and whose downstream classifiers often reach higher accuracy, especially when steering is applied at early layers.
What carries the argument
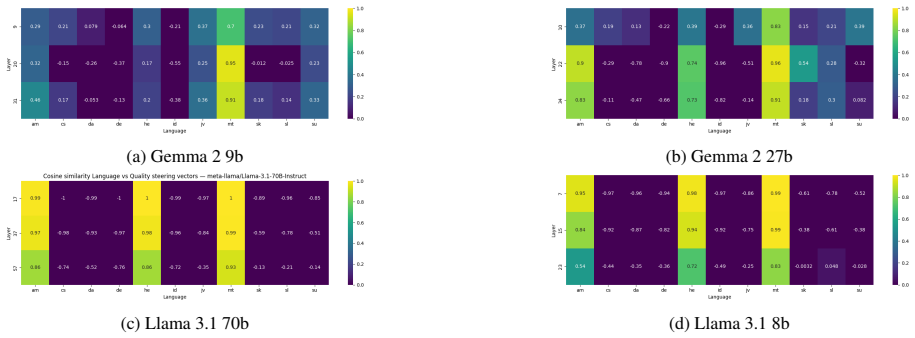
Steering vectors computed from activation differences in language-identity and quality contrasts, added to the model's hidden states at chosen layers during text generation.
If this is right
- Early-layer steering consistently raises the diversity of the generated sentences.
- Downstream classifiers trained on the steered data often reach higher accuracy than those trained on non-steered data.
- The gains appear most clearly for languages with the least available training data.
- The benefit holds in both zero-shot and few-shot generation settings across four open-source models and eleven typologically diverse languages.
Where Pith is reading between the lines
- The method could lower inference cost if it reduces the number of in-context examples needed.
- The same contrast-based steering approach might extend to generating data for other scarce domains such as technical or domain-specific text.
- Future experiments could test whether the steering vectors transfer across different generation tasks or model families.
Load-bearing premise
The steering vectors built from language contrasts and human-versus-backtranslated contrasts will shift generated text toward higher-quality examples of the target language without narrowing coverage of its natural distribution or introducing new biases.
What would settle it
A head-to-head comparison in which classifiers trained on steered synthetic data achieve equal or lower accuracy than classifiers trained on ordinary few-shot data, or in which diversity metrics show no gain, would falsify the central claim.
Figures

read the original abstract
Large language models (LLMs) have become an effective tool for synthetic data generation, including for low-resource languages, where generated data can improve downstream task performance. Current best-performing approaches typically rely on few-shot prompting with target-language examples, which increases inference costs and may reduce diversity through lexical anchoring. In this work, we investigate activation steering as an alternative for low-resource synthetic data generation. We study two steering strategies: Language Steering, which targets the linguistic identity of a language, and Quality Steering, which captures well-formedness by contrasting human-written and backtranslated text representations. We evaluate these methods across four open-source LLMs, multiple layers, and 11 typologically diverse languages by generating sentiment and topic classification data and finetuning smaller classifiers. Steering is applied in both zero-shot and few-shot prompting settings and compared against non-steered counterparts. Our results show that steering on early layers consistently improves the diversity of generated data while often yielding stronger downstream model performance, particularly for low-resource languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes activation steering as an alternative to few-shot prompting for synthetic data generation in low-resource languages. It defines Language Steering (via language-identity contrasts) and Quality Steering (via human-written vs. backtranslated text contrasts), applies them at various layers of four open-source LLMs across 11 typologically diverse languages, generates sentiment and topic classification data in zero- and few-shot settings, and evaluates the outputs by measuring diversity and downstream classifier performance after fine-tuning.
Significance. If the central empirical claim holds after addressing the noted gaps, the work offers a potentially lower-cost method for improving synthetic data diversity without lexical anchoring from few-shot examples, with particular relevance for low-resource settings. The multi-model and multi-language scope is a positive feature of the evaluation design.
major comments (2)
- [Methods] Methods section (steering vector construction): The central claim that early-layer steering improves diversity and downstream performance rests on the premise that the two contrast-derived vectors enhance data quality without introducing new biases or reducing target-language coverage. No explicit validation (e.g., distribution overlap metrics, artifact analysis, or coverage checks on generated outputs) is described for this premise, which is load-bearing for interpreting the results as higher-quality synthetic data.
- [Results] Results section: The abstract states that early-layer steering 'consistently improves' diversity and 'often' yields stronger downstream performance, yet the provided text supplies no quantitative effect sizes, error bars, exact layer ranges, or details on post-hoc layer selection. This absence prevents verification of whether the reported gains are robust or merely artifacts of selective reporting.
minor comments (1)
- [Abstract] Abstract: Including at least one concrete quantitative result (e.g., diversity delta or accuracy lift with layer index) would strengthen the summary of findings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods] Methods section (steering vector construction): The central claim that early-layer steering improves diversity and downstream performance rests on the premise that the two contrast-derived vectors enhance data quality without introducing new biases or reducing target-language coverage. No explicit validation (e.g., distribution overlap metrics, artifact analysis, or coverage checks on generated outputs) is described for this premise, which is load-bearing for interpreting the results as higher-quality synthetic data.
Authors: We agree that more direct validation of the steering vectors would strengthen the interpretation. The diversity and downstream performance metrics provide indirect evidence, as significant biases or coverage loss would likely manifest as poorer classifier results. To address this, we will add explicit checks including language identification accuracy on generated texts and token distribution comparisons in the revised manuscript. revision: yes
-
Referee: [Results] Results section: The abstract states that early-layer steering 'consistently improves' diversity and 'often' yields stronger downstream performance, yet the provided text supplies no quantitative effect sizes, error bars, exact layer ranges, or details on post-hoc layer selection. This absence prevents verification of whether the reported gains are robust or merely artifacts of selective reporting.
Authors: The results section contains per-layer, per-language tables with performance metrics. We will update the abstract to include specific quantitative details on the improvements observed and ensure error bars are clearly reported. Details on layer ranges (early layers 1-8 depending on model) and selection criteria are in the experimental setup; we will make these more prominent to avoid any perception of selective reporting. revision: yes
Circularity Check
No significant circularity; empirical comparison of steered vs. baseline generation
full rationale
The paper is an empirical study that generates synthetic data with and without activation steering, then measures diversity and downstream classifier performance across models and languages. No equations, fitted parameters, or derivations are present that could reduce reported improvements to inputs by construction. Steering vectors are derived from explicit contrasts (language identity, human vs. backtranslated) and applied as an intervention; results are evaluated against non-steered controls rather than being tautological. Self-citations, if any, are not load-bearing for the central empirical claims. The work is self-contained against external benchmarks (downstream accuracy, diversity metrics).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM hidden states contain directions that can be isolated to control language identity and output quality
Reference graph
Works this paper leans on
-
[1]
2022 , howpublished =
TransformerLens , author =. 2022 , howpublished =
2022
-
[2]
2023 , eprint=
Steering Language Models With Activation Engineering , author=. 2023 , eprint=
2023
-
[3]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[4]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Language-specific neurons: The key to multilingual capabilities in large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Language Arithmetics: Towards Systematic Language Neuron Identification and Manipulation
Gurgurov, Daniil and Trinley, Katharina and Al Ghussin, Yusser and Baeumel, Tanja and Genabith, Josef Van and Ostermann, Simon. Language Arithmetics: Towards Systematic Language Neuron Identification and Manipulation. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of...
-
[6]
2026 , eprint=
DFKI-MLT at SemEval-2026 TASK 7: Steering Multilingual Models Towards Cultural Knowledge , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
Multilingual Steering by Design: Multilingual Sparse Autoencoders and Principled Layer Selection , author=. 2026 , eprint=
2026
-
[8]
2025 , eprint=
Causal Language Control in Multilingual Transformers via Sparse Feature Steering , author=. 2025 , eprint=
2025
-
[9]
Advances in Neural Information Processing Systems , volume=
How do large language models handle multilingualism? , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2312.06681 , year=
Steering llama 2 via contrastive activation addition , author=. arXiv preprint arXiv:2312.06681 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
2024 , eprint=
Style Vectors for Steering Generative Large Language Model , author=. 2024 , eprint=
2024
-
[14]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
2024 , url=
Scaling and evaluating sparse autoencoders , author=. 2024 , url=
2024
-
[16]
Forty-second International Conference on Machine Learning , year=
AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders , author=. Forty-second International Conference on Machine Learning , year=
-
[17]
Manning and Christopher Potts , year=
Zhengxuan Wu and Aryaman Arora and Zheng Wang and Atticus Geiger and Dan Jurafsky and Christopher D. Manning and Christopher Potts , year=. arXiv:2404.03592 , archivePrefix=
-
[18]
2023 , eprint=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2023 , eprint=
2023
-
[19]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[20]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[21]
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
Deng, Boyi and Wan, Yu and Yang, Baosong and Zhang, Yidan and Feng, Fuli. Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.229
-
[22]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
The state and fate of linguistic diversity and inclusion in the NLP world , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[23]
arXiv preprint arXiv:2604.14090 , year=
From Weights to Activations: Is Steering the Next Frontier of Adaptation? , author=. arXiv preprint arXiv:2604.14090 , year=
-
[24]
arXiv preprint arXiv:2601.05062 , year=
Compositional Steering of Large Language Models with Steering Tokens , author=. arXiv preprint arXiv:2601.05062 , year=
-
[25]
arXiv preprint arXiv:2601.08331 , year=
CLaS-Bench: A Cross-Lingual Alignment and Steering Benchmark , author=. arXiv preprint arXiv:2601.08331 , year=
-
[26]
arXiv preprint arXiv:2604.03532 , year=
LangFIR: Discovering Sparse Language-Specific Features from Monolingual Data for Language Steering , author=. arXiv preprint arXiv:2604.03532 , year=
-
[27]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[28]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[29]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[30]
Gemma 3 , url=
Gemma Team , year=. Gemma 3 , url=
-
[31]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[32]
Unsupervised Cross-lingual Representation Learning at Scale , journal =
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Unsupervised Cross-lingual Representation Learning at Scale , journal =. 2019 , url =. 1911.02116 , timestamp =
Pith/arXiv arXiv 2019
-
[33]
Cross-lingual Transfer Learning with P ersian
Mollanorozy, Sepideh and Tanti, Marc and Nissim, Malvina. Cross-lingual Transfer Learning with P ersian. Proceedings of the 5th Workshop on Research in Computational Linguistic Typology and Multilingual NLP. 2023. doi:10.18653/v1/2023.sigtyp-1.9
-
[34]
G r E m LI n: A Repository of Green Baseline Embeddings for 87 Low-Resource Languages Injected with Multilingual Graph Knowledge
Gurgurov, Daniil and Kumar, Rishu and Ostermann, Simon. G r E m LI n: A Repository of Green Baseline Embeddings for 87 Low-Resource Languages Injected with Multilingual Graph Knowledge. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[35]
and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie
Adelani, David Ifeoluwa and Liu, Hannah and Shen, Xiaoyu and Vassilyev, Nikita and Alabi, Jesujoba O. and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie. SIB -200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. Proceedings of the 18th Conference of the European Chapter of the Association for Co...
2024
-
[36]
FitzGerald, Jack and Hench, Christopher and Peris, Charith and Mackie, Scott and Rottmann, Kay and Sanchez, Ana and Nash, Aaron and Urbach, Liam and Kakarala, Vishesh and Singh, Richa and Ranganath, Swetha and Crist, Laurie and Britan, Misha and Leeuwis, Wouter and Tur, Gokhan and Natarajan, Prem. MASSIVE : A 1 M -Example Multilingual Natural Language Und...
-
[37]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[38]
Publications Manual , year = "1983", publisher =
1983
-
[39]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[40]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[41]
Dan Gusfield , title =. 1997
1997
-
[42]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[43]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[44]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[45]
2024 , eprint=
Use Random Selection for Now: Investigation of Few-Shot Selection Strategies in LLM-based Text Augmentation for Classification , author=. 2024 , eprint=
2024
-
[46]
2023 , eprint=
ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT , author=. 2023 , eprint=
2023
-
[47]
Sen, Indira and Assenmacher, Dennis and Samory, Mattia and Augenstein, Isabelle and Aalst, Wil and Wagner, Claudia. People Make Better Edits: Measuring the Efficacy of LLM -Generated Counterfactually Augmented Data for Harmful Language Detection. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/...
-
[48]
Cegin, Jan and Pecher, Branislav and Simko, Jakub and Srba, Ivan and Bielikova, Maria and Brusilovsky, Peter. Effects of diversity incentives on sample diversity and downstream model performance in LLM -based text augmentation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.186...
-
[49]
2023 , eprint=
AugGPT: Leveraging ChatGPT for Text Data Augmentation , author=. 2023 , eprint=
2023
-
[50]
2025 , eprint=
Enhancing NER Performance in Low-Resource Pakistani Languages using Cross-Lingual Data Augmentation , author=. 2025 , eprint=
2025
-
[51]
Feng, Steven Y. and Gangal, Varun and Wei, Jason and Chandar, Sarath and Vosoughi, Soroush and Mitamura, Teruko and Hovy, Eduard. A Survey of Data Augmentation Approaches for NLP. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.84
-
[52]
arXiv preprint arXiv:2501.19314 , year=
An Efficient Approach for Machine Translation on Low-resource Languages: A Case Study in Vietnamese-Chinese , author=. arXiv preprint arXiv:2501.19314 , year=
-
[53]
2024 6th International Conference on Natural Language Processing (ICNLP) , pages=
Generative-Adversarial Networks for Low-Resource Language Data Augmentation in Machine Translation , author=. 2024 6th International Conference on Natural Language Processing (ICNLP) , pages=. 2024 , organization=
2024
-
[54]
Synthetic Data Generation for Multilingual Domain-Adaptable Question Answering Systems
Kramchaninova, Alina and Defauw, Arne. Synthetic Data Generation for Multilingual Domain-Adaptable Question Answering Systems. Proceedings of the 23rd Annual Conference of the European Association for Machine Translation. 2022
2022
-
[55]
GeMQuAD: Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning , author=. 2023
2023
-
[56]
arXiv preprint arXiv:2502.15419 , year=
Beyond Translation: LLM-Based Data Generation for Multilingual Fact-Checking , author=. arXiv preprint arXiv:2502.15419 , year=
-
[57]
M ul DA : A Multilingual Data Augmentation Framework for Low-Resource Cross-Lingual NER
Liu, Linlin and Ding, Bosheng and Bing, Lidong and Joty, Shafiq and Si, Luo and Miao, Chunyan. M ul DA : A Multilingual Data Augmentation Framework for Low-Resource Cross-Lingual NER. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1:...
-
[58]
Jetsons at the F in NLP -2023: Using Synthetic Data and Transfer Learning for Multilingual ESG Issue Classification
Glenn, Parker and Gon, Alolika and Kohli, Nikhil and Zha, Sihan and Dakle, Parag Pravin and Raghavan, Preethi. Jetsons at the F in NLP -2023: Using Synthetic Data and Transfer Learning for Multilingual ESG Issue Classification. Proceedings of the Fifth Workshop on Financial Technology and Natural Language Processing and the Second Multimodal AI For Financ...
2023
-
[59]
Aytuğ Onan , keywords =. SRL-ACO: A text augmentation framework based on semantic role labeling and ant colony optimization , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.jksuci.2023.101611 , url =
-
[60]
Is C hat GPT the ultimate Data Augmentation Algorithm?
Piedboeuf, Fr \'e d \'e ric and Langlais, Philippe. Is C hat GPT the ultimate Data Augmentation Algorithm?. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.1044
-
[61]
Liu, Qijiong and Chen, Nuo and Sakai, Tetsuya and Wu, Xiao-Ming , title =. 2024 , isbn =. doi:10.1145/3616855.3635845 , booktitle =
-
[62]
GPT 3 M ix: Leveraging Large-scale Language Models for Text Augmentation
Yoo, Kang Min and Park, Dongju and Kang, Jaewook and Lee, Sang-Woo and Park, Woomyoung. GPT 3 M ix: Leveraging Large-scale Language Models for Text Augmentation. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.192
-
[63]
Data Augmentation for Intent Classification with Off-the-shelf Large Language Models
Sahu, Gaurav and Rodriguez, Pau and Laradji, Issam and Atighehchian, Parmida and Vazquez, David and Bahdanau, Dzmitry. Data Augmentation for Intent Classification with Off-the-shelf Large Language Models. Proceedings of the 4th Workshop on NLP for Conversational AI. 2022. doi:10.18653/v1/2022.nlp4convai-1.5
-
[64]
2023 , eprint=
Using GPT-4 to Augment Unbalanced Data for Automatic Scoring , author=. 2023 , eprint=
2023
-
[65]
DALE: Generative Data Augmentation for Low-Resource Legal NLP
Sreyan Ghosh and Chandra Kiran Evuru and Sonal Kumar and S Ramaneswaran and S Sakshi and Utkarsh Tyagi and Dinesh Manocha. DALE: Generative Data Augmentation for Low-Resource Legal NLP. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[66]
Semi-automatic generation of multilingual datasets for stance detection in Twitter , journal =
Elena Zotova and Rodrigo Agerri and German Rigau , keywords =. Semi-automatic generation of multilingual datasets for stance detection in Twitter , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.eswa.2020.114547 , url =
-
[67]
2025 , eprint=
Synthetic Data Generation for Culturally Nuanced Commonsense Reasoning in Low-Resource Languages , author=. 2025 , eprint=
2025
-
[68]
LL atrieval: LLM -Verified Retrieval for Verifiable Generation
Li, Xiaonan and Zhu, Changtai and Li, Linyang and Yin, Zhangyue and Sun, Tianxiang and Qiu, Xipeng. LL atrieval: LLM -Verified Retrieval for Verifiable Generation. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/202...
-
[69]
2025 , eprint=
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models , author=. 2025 , eprint=
2025
-
[70]
Gu, Xu and Chen, Xiaoliang and Lu, Peng and Li, Zonggen and Du, Yajun and Li, Xianyong , title =. 2024 , issue_date =. doi:10.1016/j.engappai.2024.107907 , journal =
-
[71]
First International Workshop on Linked Science 2011-In conjunction with the International Semantic Web Conference (ISWC 2011) , year=
Glottolog/Langdoc: Defining dialects, languages, and language families as collections of resources , author=. First International Workshop on Linked Science 2011-In conjunction with the International Semantic Web Conference (ISWC 2011) , year=
2011
-
[72]
The annals of mathematical statistics , pages=
On a test of whether one of two random variables is stochastically larger than the other , author=. The annals of mathematical statistics , pages=. 1947 , publisher=
1947
-
[73]
2024 , eprint=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
2024
-
[74]
Cegin, Jan and Simko, Jakub and Brusilovsky, Peter. C hat GPT to Replace Crowdsourcing of Paraphrases for Intent Classification: Higher Diversity and Comparable Model Robustness. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.117
-
[75]
arXiv preprint arXiv:2402.13116 , year=
A survey on knowledge distillation of large language models , author=. arXiv preprint arXiv:2402.13116 , year=
-
[76]
Adapting Multilingual LLM s to Low-Resource Languages with Knowledge Graphs via Adapters
Gurgurov, Daniil and Hartmann, Mareike and Ostermann, Simon. Adapting Multilingual LLM s to Low-Resource Languages with Knowledge Graphs via Adapters. Proceedings of the 1st Workshop on Knowledge Graphs and Large Language Models (KaLLM 2024). 2024. doi:10.18653/v1/2024.kallm-1.7
-
[77]
arXiv preprint arXiv:2502.10140 , year=
Small Models, Big Impact: Efficient Corpus and Graph-Based Adaptation of Small Multilingual Language Models for Low-Resource Languages , author=. arXiv preprint arXiv:2502.10140 , year=
-
[78]
LLM s vs Established Text Augmentation Techniques for Classification: When do the Benefits Outweight the Costs?
Cegin, Jan and Simko, Jakub and Brusilovsky, Peter. LLM s vs Established Text Augmentation Techniques for Classification: When do the Benefits Outweight the Costs?. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025
2025
-
[79]
Language-agnostic BERT Sentence Embedding
Feng, Fangxiaoyu and Yang, Yinfei and Cer, Daniel and Arivazhagan, Naveen and Wang, Wei. Language-agnostic BERT Sentence Embedding. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.62
-
[80]
Data Mining , booktitle=
Rajaraman, Anand and Ullman, Jeffrey David , year=. Data Mining , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.