Beyond Triplet Plausibility: Relation Set Completion in Knowledge Graphs
Pith reviewed 2026-07-01 06:55 UTC · model grok-4.3
The pith
A new task and model infer missing relations compatible with entities by learning patterns from their observed relation sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that knowledge graph incompleteness includes missing entity-relation compatibility information, which a new relation set completion task can address by inferring additional relations that fit an entity's observed set. The RelSetE model does this by modeling latent patterns among observed relations, and evaluation on three derived benchmarks shows it performs favorably at this inference.
What carries the argument
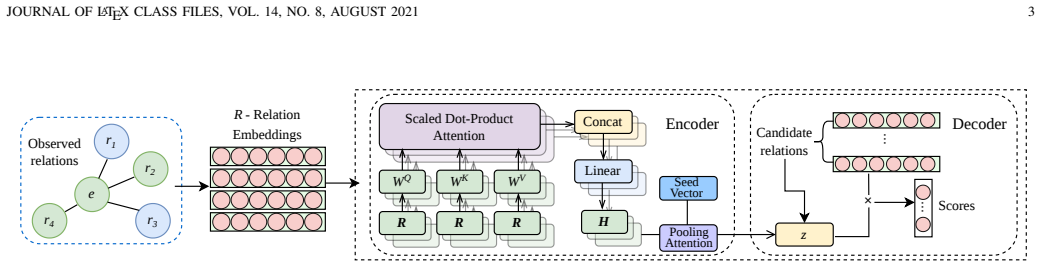
RelSetE, the Relation Set Embedding model that learns latent patterns among an entity's observed relations to infer missing semantically compatible relations.
If this is right
- Relation set completion complements link prediction by addressing a distinct form of incompleteness.
- Entities gain completed relation profiles through inference of compatible missing relations.
- Three new benchmark datasets enable standardized evaluation of relation set completion.
- Knowledge graphs achieve greater overall completeness for downstream use.
Where Pith is reading between the lines
- Combining relation set completion with link prediction could produce more internally consistent knowledge graphs.
- The method may expose natural clusters of semantically related relations around entities.
- Testing on knowledge graphs with different noise levels or domains could show where the pattern-based inference holds or breaks.
Load-bearing premise
That latent patterns among an entity's observed relations are sufficient to reliably infer which additional relations are semantically compatible.
What would settle it
A collection of entities where predicted compatible relations contradict known semantic incompatibilities or human judgments on fit.
Figures

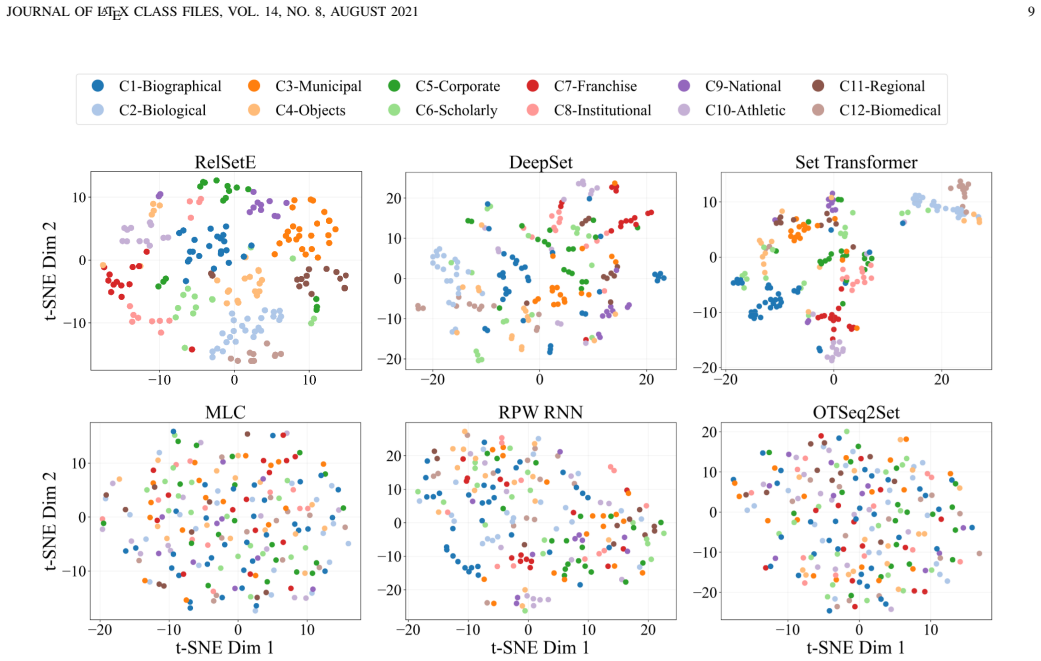
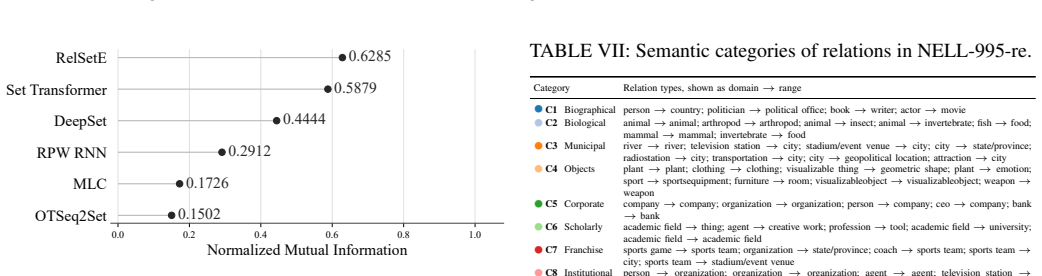
read the original abstract
Knowledge graphs (KGs) organize real-world knowledge as triplets and underpin many downstream applications. Due to their inherent incompleteness, knowledge graph completion (KGC) is widely studied and is typically formulated as triplet prediction, with link prediction as the dominant paradigm. However, this formulation focuses on the incompleteness of triplet-wise information and overlooks the incompleteness of entity-relation compatibility information. To address this limitation, we introduce a relation set completion task (RSC), which complements the link prediction task and aims to reason about missing relations that are semantically compatible with a given entity. We further propose a Relation Set Embedding model (RelSetE), which models latent patterns among the observed relations of entities to infer missing ones. To evaluate RelSetE, we derive three benchmark datasets from standard KG benchmarks. Extensive experiments demonstrate that RelSetE effectively captures entity-relation compatibility patterns and performs favorably in inferring missing relations of entities. Code and data are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Relation Set Completion (RSC) task to address incompleteness in entity-relation compatibility information in knowledge graphs, complementing standard triplet-based link prediction. It proposes the RelSetE model to capture latent patterns among an entity's observed relations for inferring missing compatible relations, derives three benchmark datasets from standard KGs, and claims that extensive experiments show RelSetE effectively captures these patterns and performs favorably.
Significance. If the claimed experimental results hold, the work could be significant by broadening KGC research to a new task focused on relation-set compatibility rather than individual triplets, with potential benefits for downstream KG applications. The public release of code and data is noted as a strength that would support reproducibility and follow-on work.
major comments (1)
- [Abstract] Abstract: The central claim that 'Extensive experiments demonstrate that RelSetE effectively captures entity-relation compatibility patterns and performs favorably in inferring missing relations of entities' is load-bearing for the paper's contribution, yet the provided text contains no description of the RelSetE model (embedding construction, training objective, or how latent patterns are modeled), the procedure for deriving the three benchmark datasets, the RSC evaluation protocol, quantitative results, baselines, or error analysis. This absence makes it impossible to assess whether the data support the claim or the key assumption that observed relation patterns suffice for reliable compatibility inference.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. The major comment concerns the level of detail in the abstract. We address it point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Extensive experiments demonstrate that RelSetE effectively captures entity-relation compatibility patterns and performs favorably in inferring missing relations of entities' is load-bearing for the paper's contribution, yet the provided text contains no description of the RelSetE model (embedding construction, training objective, or how latent patterns are modeled), the procedure for deriving the three benchmark datasets, the RSC evaluation protocol, quantitative results, baselines, or error analysis. This absence makes it impossible to assess whether the data support the claim or the key assumption that observed relation patterns suffice for reliable compatibility inference.
Authors: The abstract is written as a concise, high-level summary of the paper's contributions and findings, which is standard practice. The full manuscript contains dedicated sections that describe the RelSetE model (including embedding construction, training objective, and modeling of latent patterns among relations), the procedure for deriving the three benchmark datasets from standard KGs, the RSC evaluation protocol, quantitative results with baselines, and error analysis. These sections provide the evidence supporting the abstract's central claim. The abstract itself does not aim to include such details, as its role is to outline the problem, proposed task, model, and key outcomes. revision: no
Circularity Check
No derivation chain or self-referential steps present in abstract
full rationale
Only the abstract is available and it contains no equations, model definitions, training objectives, citations, or derivations. The central claim rests on an undescribed experimental result ('Extensive experiments demonstrate...') rather than any reduction of a prediction to a fitted input or self-citation. No load-bearing step matches any of the enumerated circularity patterns.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.