Beyond Classification Accuracy: An Exploration-Range Evaluation of Adaptive Crawling for Fake Shopping Sites
Pith reviewed 2026-06-26 14:00 UTC · model grok-4.3
The pith
A closed-loop crawler feeding classifier outputs into search queries discovers about 7.6 times more unique fake shopping hosts than a fixed-keyword baseline after three cycles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
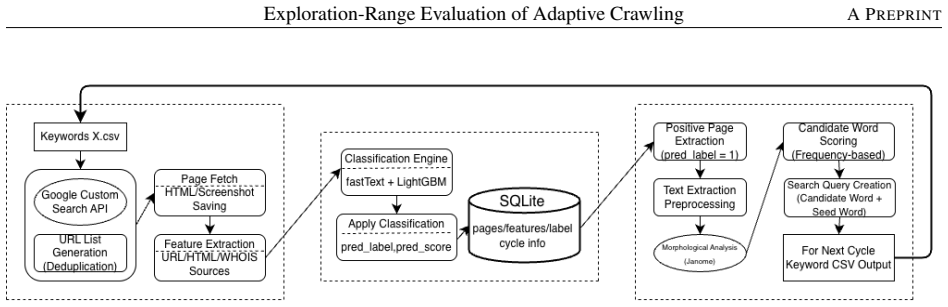
The central claim is that a closed-loop crawler incorporating page-level classifier outputs into a seed-compound query strategy sustains discovery of new fake shopping site hosts across multiple cycles, in contrast to fixed-keyword search which stagnates completely after the first cycle, producing an average cumulative unique-host count 7.6 times higher than the baseline by cycle three.
What carries the argument
The seed-compound strategy, which extracts characteristic words from pages the classifier labels positive and combines them with fixed seed words to form the queries used in the next crawling cycle.
If this is right
- Fixed-keyword search produces zero new hosts from cycle two onward.
- The adaptive method continues to acquire new hosts through at least cycle three.
- Cumulative unique-host count reaches approximately 7.6 times the baseline value on average at cycle three.
- Exploration-range metrics can be used alongside accuracy to judge whether a crawler keeps pace with changing site campaigns.
Where Pith is reading between the lines
- The same closed-loop pattern could be tested on other SEO-poisoned threats such as phishing or malware landing pages.
- The introduced per-cycle and cumulative host counts offer a general way to compare any crawler that must chase evolving web content.
- If a stronger classifier is substituted, the query-generation loop would be expected to produce even larger gaps over the baseline without other changes.
Load-bearing premise
That words taken from the classifier's positive pages can be combined with seed terms to produce queries that reliably locate previously unknown fake sites rather than repeating known ones or stalling.
What would settle it
Repeating the three-cycle experiment and finding that the proposed method's new-host acquisition rate falls to zero after cycle one or fails to exceed the baseline's cumulative total by a substantial margin.
Figures
read the original abstract
In recent years, fake shopping sites targeting Japanese users have appeared in the top results of search engines through SEO poisoning, causing increasing damage. Conventional collection methods rely on fixed keywords and cannot keep up with evolving attack campaigns, delaying the discovery of new sites. We propose a closed-loop crawler that incorporates the page-level outputs of a fake-site classifier (fastText+LightGBM) into the search queries of the next cycle. Search queries are generated by a seed-compound strategy that combines characteristic words extracted from positive pages with seed words from the fake-shopping context (e.g., ``deep discount,'' ``official''). To complement evaluations that tend to focus on classifier accuracy, we also introduce per-cycle new-host counts and cumulative unique-host counts as exploration-range metrics. In a comparative experiment ($n=3$ for the proposed method, $n=2$ for the baseline), the fixed-keyword baseline yielded zero new-host acquisition from cycle 2 onward, indicating complete stagnation, whereas the proposed method continued to discover new hosts and, at cycle 3, achieved a cumulative unique-host count approximately 7.6 times that of the baseline on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a closed-loop adaptive crawler for fake shopping sites that feeds page-level outputs from a fastText+LightGBM classifier into a seed-compound query generation strategy (combining extracted characteristic words with fixed seed words such as "deep discount"). It introduces exploration-range metrics (per-cycle new-host counts and cumulative unique-host counts) to evaluate discovery performance beyond classifier accuracy. In a small comparative experiment (n=3 runs of the adaptive method, n=2 of a fixed-keyword baseline), the baseline stagnates with zero new hosts after cycle 1 while the adaptive method continues discovering hosts, reaching ~7.6 imes the baseline's cumulative unique-host count by cycle 3 on average.
Significance. If the reported advantage is shown to be robust, the work would demonstrate a practical way to track evolving SEO-poisoned sites and would usefully shift evaluation of discovery systems toward exploration metrics rather than accuracy alone. The seed-compound idea and the explicit baseline comparison are clear strengths, but the current evidence base is too narrow to support strong claims about reliability.
major comments (1)
- [Abstract / Experimental Results] Abstract and Experimental Results: the central quantitative claim of an approximately 7.6 imes cumulative unique-host advantage rests on averages computed from only n=3 runs of the proposed crawler and n=2 runs of the baseline, with no per-run values, standard deviations, confidence intervals, or statistical tests supplied. Given the nondeterminism of search-engine results and stochastic word extraction from the classifier, this sample size is insufficient to distinguish a genuine property of the seed-compound strategy from sampling variability.
minor comments (3)
- The manuscript provides no description of the host-deduplication rules used to compute the cumulative unique-host metric, which is essential for interpreting the exploration-range results.
- No information is given on the training data, feature extraction, or cross-validation procedure for the fastText+LightGBM classifier, nor on how positive-page outputs are filtered before characteristic-word extraction.
- The paper does not discuss potential selection effects or timing biases across the three cycles of the experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of the seed-compound strategy and exploration-range metrics. We agree that the limited number of runs weakens the reliability of the reported advantage and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: the central quantitative claim of an approximately 7.6 imes cumulative unique-host advantage rests on averages computed from only n=3 runs of the proposed crawler and n=2 runs of the baseline, with no per-run values, standard deviations, confidence intervals, or statistical tests supplied. Given the nondeterminism of search-engine results and stochastic word extraction from the classifier, this sample size is insufficient to distinguish a genuine property of the seed-compound strategy from sampling variability.
Authors: We agree that the current sample sizes (n=3 and n=2) and absence of variability measures or statistical tests limit the strength of the claims. In the revised version we will run additional independent trials of both the adaptive crawler and the fixed-keyword baseline, report the per-run cumulative unique-host counts, compute standard deviations and confidence intervals, and include appropriate statistical tests (e.g., two-sample t-test or Wilcoxon rank-sum test) on the cycle-3 totals. These changes will allow readers to evaluate whether the observed advantage exceeds sampling variability. revision: yes
Circularity Check
No circularity: empirical comparison uses independent metrics
full rationale
The paper reports an empirical result from a comparative experiment (proposed method n=3 vs. fixed-keyword baseline n=2) using per-cycle new-host counts and cumulative unique-host counts. These metrics are defined directly from observed search-engine outputs and are not derived from any fitted parameters, self-referential definitions, or load-bearing self-citations. The 7.6× cumulative-host advantage is a measured experimental outcome, not a quantity that reduces to the seed-compound strategy inputs by construction. The derivation chain is self-contained against the explicit baseline.
Axiom & Free-Parameter Ledger
free parameters (1)
- seed words
axioms (1)
- domain assumption The fastText+LightGBM classifier produces page-level outputs sufficiently accurate to extract useful characteristic words for query adaptation.
Reference graph
Works this paper leans on
-
[1]
Statistical information on malicious shopping sites (first half of 2025)
Japan Cybercrime Control Center. Statistical information on malicious shopping sites (first half of 2025). Web. (in Japanese), Accessed: 2025-12-10.https://www.jc3.or.jp/threats/topics/article-641.html
2025
-
[2]
Fake shopping sites: Confirmed redirections from search results for osaka-kansai expo goods
Trend Micro. Fake shopping sites: Confirmed redirections from search results for osaka-kansai expo goods. Web. (in Japanese), Accessed: 2026-01-10. https://www.trendmicro.com/ja_jp/research/25/i/ fake-shopping-sites.html
2026
-
[3]
Warning on fraudulent sites disguised as selling rice at low prices
Consumer Affairs Agency, Government of Japan. Warning on fraudulent sites disguised as selling rice at low prices. Web. (in Japanese), Accessed: 2026-01-10.https://www.caa.go.jp/notice/entry/043659/
2026
-
[4]
Field survey on detecting stepping-stone sites that redirect users to fake shopping sites
Daigo Michishita, Satoru Kobayashi, and Toshihiro Yamauchi. Field survey on detecting stepping-stone sites that redirect users to fake shopping sites. InProceedings of Computer Security Symposium 2024 (CSS2024), pages 1095–1101. Information Processing Society of Japan, Oct 2024. (in Japanese)
2024
-
[5]
A nearly four-year longitudinal study of search-engine poisoning
Nektarios Leontiadis, Tyler Moore, and Nicolas Christin. A nearly four-year longitudinal study of search-engine poisoning. InProceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, CCS ’14, page 930–941, New York, NY , USA, 2014. Association for Computing Machinery. ISBN 9781450329576. doi:10.1145/2660267.2660332. URLhttps:/...
-
[6]
Elucidating attack methods of fake shopping sites.IPSJ Journal, 62:1523–1535, Sep 2021
Hirokazu Kodera, Shun Koide, Daiki Chiba, Kazufumi Aoki, and Mitsuaki Akiyama. Elucidating attack methods of fake shopping sites.IPSJ Journal, 62:1523–1535, Sep 2021. (in Japanese)
2021
-
[7]
Mitsuho Hasegawa, Kosuke Sekido, Kazuki Takada, Akira Fujita, Rui Tanabe, and Katsunari Yoshioka. Proposal of a collection method for fake shopping sites that reuse product information from legitimate sites.Proceedings of 11 Exploration-Range Evaluation of Adaptive CrawlingA PREPRINT Computer Security Symposium 2024 (CSS2024), pages 1080–1087, 10 2024. UR...
arXiv 2024
-
[8]
Saul, Stefan Savage, and Geoffrey M
Justin Ma, Lawrence K. Saul, Stefan Savage, and Geoffrey M. V oelker. Beyond blacklists: learning to detect malicious web sites from suspicious urls. KDD ’09, page 1245–1254, New York, NY , USA, 2009. Association for Computing Machinery. ISBN 9781605584959. doi:10.1145/1557019.1557153. URL https://doi.org/10. 1145/1557019.1557153
-
[9]
Hung Le, Quang Pham, Doyen Sahoo, and Steven C. H. Hoi. Urlnet: Learning a url representation with deep learning for malicious url detection, 2018. URLhttps://arxiv.org/abs/1802.03162
Pith/arXiv arXiv 2018
-
[10]
Keisuke Sakai, Kosuke Takeshige, Kazuki Kato, Naoki Kurihara, Katsumi Ono, and Masaki Hashimoto. An automatic detection system for fake japanese shopping sites using fasttext and lightgbm.IEEE Access, 11: 111389–111401, 2023. doi:10.1109/ACCESS.2023.3323218
-
[11]
Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages
Yun Lin, Ruofan Liu, Dinil Mon Divakaran, Jun Yang Ng, Qing Zhou Chan, Yiwen Lu, Yuxuan Si, Fan Zhang, and Jin Song Dong. Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages. In30th USENIX Security Symposium (USENIX Security 21), pages 3793–3810. USENIX Association, August 2021. ISBN 978-1-939133-24-3. URL https://www....
2021
-
[12]
Yuexin Li, Chengyu Huang, Shumin Deng, Mei Lin Lock, Tri Cao, Nay Oo, Hoon Wei Lim, and Bryan Hooi. Knowphish: Large language models meet multimodal knowledge graphs for enhancing reference-based phishing detection, 2024. URLhttps://arxiv.org/abs/2403.02253
arXiv 2024
-
[13]
A taxonomy of attacks on open-source software supply chains
Marzieh Bitaab, Haehyun Cho, Adam Oest, Zhuoer Lyu, Wei Wang, Jorij Abraham, Ruoyu Wang, Tiffany Bao, Yan Shoshitaishvili, and Adam Doupé. Beyond phish: Toward detecting fraudulent e-commerce websites at scale. In2023 IEEE Symposium on Security and Privacy (SP), pages 2566–2583, 2023. doi:10.1109/SP46215.2023.10179461
-
[14]
Learning to detect and measure fake ecommerce websites in search- engine results
Claudio Carpineto and Giovanni Romano. Learning to detect and measure fake ecommerce websites in search- engine results. WI ’17, page 403–410, New York, NY , USA, 2017. Association for Computing Machinery. ISBN 9781450349512. doi:10.1145/3106426.3106441. URLhttps://doi.org/10.1145/3106426.3106441
-
[15]
Measuring and analyzing search-redirection attacks in the illicit online prescription drug trade
Nektarios Leontiadis, Tyler Moore, and Nicolas Christin. Measuring and analyzing search-redirection attacks in the illicit online prescription drug trade. InProceedings of the 20th USENIX Conference on Security, SEC’11, page 19, USA, 2011. USENIX Association
2011
-
[16]
Wang, Stefan Savage, and Geoffrey M
David Y . Wang, Stefan Savage, and Geoffrey M. V oelker. Cloak and dagger: dynamics of web search cloak- ing. InProceedings of the 18th ACM Conference on Computer and Communications Security, CCS ’11, page 477–490, New York, NY , USA, 2011. Association for Computing Machinery. ISBN 9781450309486. doi:10.1145/2046707.2046763. URLhttps://doi.org/10.1145/204...
-
[17]
Cloak of visibility: Detecting when machines browse a different web
Luca Invernizzi, Kurt Thomas, Alexandros Kapravelos, Oxana Comanescu, Jean-Michel Picod, and Elie Bursztein. Cloak of visibility: Detecting when machines browse a different web. In2016 IEEE Symposium on Security and Privacy (SP), pages 743–758, 2016. doi:10.1109/SP.2016.50
-
[18]
Cui, S., Sun, Y., Zhang, Y., Meng, Q., Zhu, H.,
Adam Oest, Yeganeh Safaei, Adam Doupé, Gail-Joon Ahn, Brad Wardman, and Kevin Tyers. Phishfarm: A scalable framework for measuring the effectiveness of evasion techniques against browser phishing blacklists. In 2019 IEEE Symposium on Security and Privacy (SP), pages 1344–1361, 2019. doi:10.1109/SP.2019.00049
-
[19]
2021 IEEE symposium on security and privacy (SP) , pages=
Penghui Zhang, Adam Oest, Haehyun Cho, Zhibo Sun, RC Johnson, Brad Wardman, Shaown Sarker, Alexandros Kapravelos, Tiffany Bao, Ruoyu Wang, Yan Shoshitaishvili, Adam Doupé, and Gail-Joon Ahn. Crawlphish: Large-scale analysis of client-side cloaking techniques in phishing. In2021 IEEE Symposium on Security and Privacy (SP), pages 1109–1124, 2021. doi:10.110...
-
[20]
PhishDecloaker: Detecting CAPTCHA- cloaked phishing websites via hybrid vision-based interactive models
Xiwen Teoh, Yun Lin, Ruofan Liu, Zhiyong Huang, and Jin Song Dong. PhishDecloaker: Detecting CAPTCHA- cloaked phishing websites via hybrid vision-based interactive models. In33rd USENIX Security Symposium (USENIX Security 24), pages 505–522, Philadelphia, PA, August 2024. USENIX Association. ISBN 978-1- 939133-44-1. URLhttps://www.usenix.org/conference/us...
2024
-
[21]
Evilseed: A guided approach to finding malicious web pages
Luca Invernizzi, Stefano Benvenuti, Marco Cova, Paolo Milani Comparetti, Christopher Kruegel, and Giovanni Vigna. Evilseed: A guided approach to finding malicious web pages. InProceedings of the 2012 IEEE Symposium on Security and Privacy, SP ’12, page 428–442, USA, 2012. IEEE Computer Society. ISBN 9780769546810. doi:10.1109/SP.2012.33. URLhttps://doi.or...
-
[22]
Scalable detection of promotional website defacements in black hat SEO campaigns
Ronghai Yang, Xianbo Wang, Cheng Chi, Dawei Wang, Jiawei He, Siming Pang, and Wing Cheong Lau. Scalable detection of promotional website defacements in black hat SEO campaigns. In30th USENIX Security Symposium (USENIX Security 21), pages 3703–3720. USENIX Association, August 2021. ISBN 978-1-939133-24-3. URL https://www.usenix.org/conference/usenixsecurit...
2021
-
[23]
Custom search json api
Google. Custom search json api. Web. Accessed: 2026-01-21. https://developers.google.com/ custom-search/v1/overview?hl=ja
2026
-
[24]
Janome v0.5 documentation(ja). Web. Accessed: 2026-02-18.https://janome.mocobeta.dev/ja/. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.