A Comparative Study of Bayesian Contextual Bandits for Real-Time Warehouse Sorter Optimization
Pith reviewed 2026-06-26 08:39 UTC · model grok-4.3
The pith
Bayesian Contextual Bandits deliver a 2.03 percent reward uplift over heuristics for real-time warehouse sorter diversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
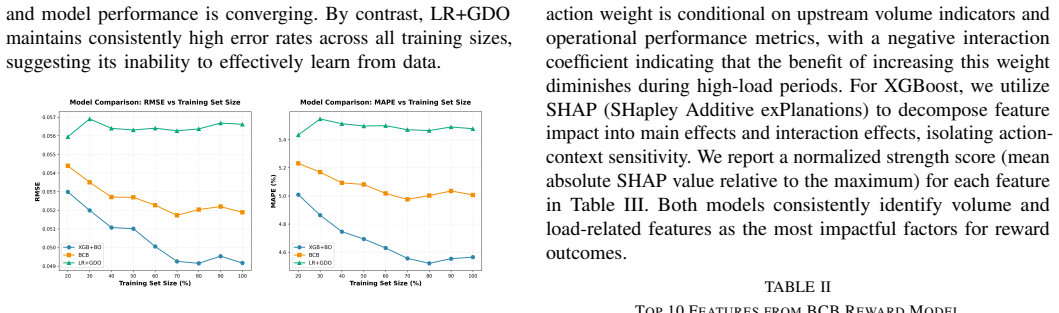
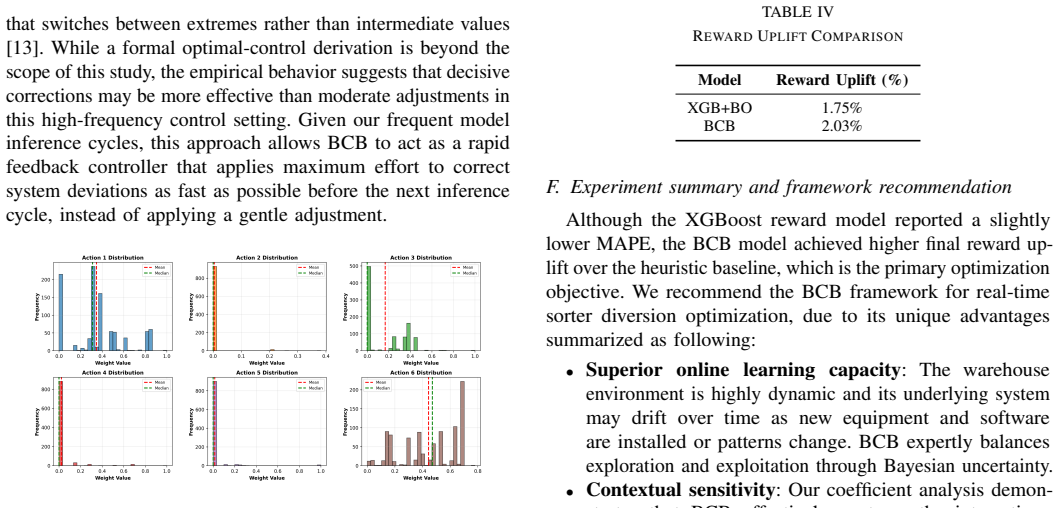
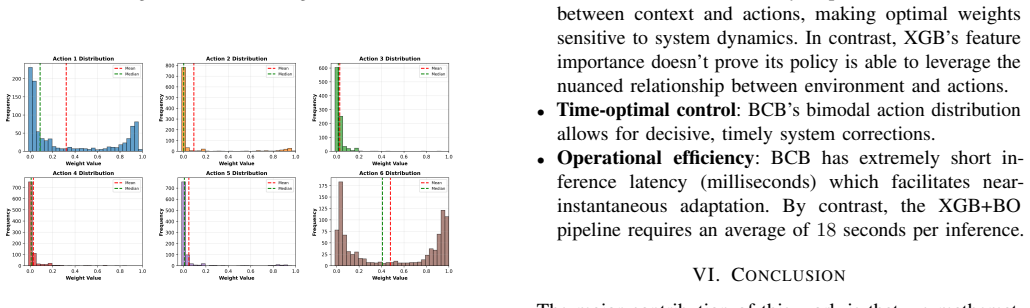
When evaluated on reward accuracy, action distributions, and projected performance, the Bayesian Contextual Bandits model outperforms both linear regression with gradient descent and XGBoost with Bayesian optimization. It achieves a 2.03 percent overall reward improvement relative to the heuristic baseline, exhibits a decisive time-optimal policy consistent with Bang-Bang control, supports continuous online updates, balances exploration and exploitation, and runs with substantially lower inference latency.
What carries the argument
Bayesian Contextual Bandits, which maintain posterior beliefs over action values conditioned on observed system context and select actions to balance immediate reward against information gain for future decisions.
If this is right
- The framework can be updated continuously from live data without periodic offline retraining.
- Inference latency remains low enough to support high-frequency diversion decisions at scale.
- The time-optimal policy property reduces unnecessary or delayed actions compared with probabilistic alternatives.
- The same emulator-based workflow supports safe testing of other real-time control policies before live use.
Where Pith is reading between the lines
- If the emulator matches reality closely, the same bandit approach could be applied to adjacent warehouse tasks such as dynamic routing or pick sequencing.
- The connection to Bang-Bang control suggests a route for injecting classical optimality guarantees into contextual bandit training.
- Continuous online adaptation may lower the cost of handling seasonal volume shifts without manual retuning of cost weights.
Load-bearing premise
The high-fidelity physics-aware emulator must capture the real sorter's dynamics, reward structure, and context dependencies well enough that policies learned offline transfer safely and perform as projected once deployed online.
What would settle it
Running the learned Bayesian Contextual Bandits policy on the live warehouse sorter for several weeks and measuring whether the realized reward uplift meets or exceeds the 2.03 percent projected from the emulator would confirm or refute the central result.
Figures


read the original abstract
Efficient sorter diversion control of automated material handling systems (MHS) is critical for optimizing operational efficiency in large-scale warehouse environments. In this study, we use an inbound receiving sorter at a high-volume e-commerce warehouse as our primary use case, where the sorter diversion system relies on cost functions with static weight configurations that fail to adapt to highly dynamic system contexts, such as volume mode, congestion level, equipment physical status, and upstream/downstream dependencies. To address this real-time sorter diversion optimization challenge, we conducted a comparative study of three candidate hybrid machine learning frameworks: Linear Regression with Gradient Descent Optimization (LR+GDO), XGBoost with Bayesian Optimization (XGB+BO), and Bayesian Contextual Bandits (BCB). Model training and evaluation were enabled by leveraging a high-fidelity physics-aware emulator to overcome the cold-start problem and allow a safe transition from offline to online learning. We performed comprehensive evaluations including reward model predictive accuracy, contextual sensitivity, action distribution, and projected reward uplift. Our results demonstrate that while tree-based reward models offer slightly better predictive power, the BCB framework achieved overall higher performance with 2.03% reward uplift over the heuristic baseline. Furthermore, BCB exhibits several superior characteristics, such as its decisive time-optimal policy backed by Bang-Bang control theory, continuous online learning capability, strategic balance between exploration and exploitation, and significantly shorter inference latency. These results demonstrate the potential of the BCB framework for real-time control optimization in large-scale warehouse environments, motivating further investigation toward operational deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comparative study of three hybrid ML frameworks—Linear Regression with Gradient Descent Optimization (LR+GDO), XGBoost with Bayesian Optimization (XGB+BO), and Bayesian Contextual Bandits (BCB)—for real-time sorter diversion control in a high-volume e-commerce warehouse. Training and evaluation rely on a high-fidelity physics-aware emulator to enable offline-to-online learning; the central empirical claim is that BCB delivers a 2.03% reward uplift over the static heuristic baseline while exhibiting a time-optimal policy aligned with Bang-Bang control, continuous online adaptation, balanced exploration-exploitation, and lower inference latency.
Significance. If the emulator-to-reality gap is closed and the uplift is shown to be statistically robust, the work would supply a concrete, latency-sensitive demonstration of contextual bandits for industrial material-handling control, with potential to influence operational practice in automated warehouses.
major comments (3)
- [Abstract] Abstract and results: the headline 2.03% reward uplift is stated without error bars, number of evaluation episodes, dataset sizes, or any statistical significance test, rendering the performance claim impossible to assess from the supplied text.
- [Abstract / Evaluation sections] No section reports quantitative emulator-to-reality calibration (e.g., Kolmogorov-Smirnov tests on throughput histograms, correlation of congestion time series, or hold-out real-system episodes). Because every reported metric and the offline-to-online transition argument rest exclusively on emulator fidelity, this omission is load-bearing for the central claims.
- [Results / Discussion] The assertion that BCB produces a “decisive time-optimal policy backed by Bang-Bang control theory” is presented without an explicit mapping from the bandit action space or reward model to the bang-bang optimality condition; the connection therefore remains an unverified interpretation rather than a derived result.
minor comments (2)
- [Abstract] The abstract lists “comprehensive evaluations including reward model predictive accuracy, contextual sensitivity, action distribution, and projected reward uplift” but the manuscript should supply the precise metrics, cross-validation scheme, and projection methodology used for each.
- [Introduction / Methods] Notation for context variables (volume mode, congestion level, equipment status) should be defined once in a dedicated table or section to avoid repeated informal descriptions.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below, with clear indications of where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the headline 2.03% reward uplift is stated without error bars, number of evaluation episodes, dataset sizes, or any statistical significance test, rendering the performance claim impossible to assess from the supplied text.
Authors: We agree that the abstract and results require additional statistical details to allow proper assessment of the performance claim. In the revised manuscript, we will update both the abstract and evaluation sections to include error bars on the reported uplift, the number of evaluation episodes, dataset sizes, and results from statistical significance tests. revision: yes
-
Referee: [Abstract / Evaluation sections] No section reports quantitative emulator-to-reality calibration (e.g., Kolmogorov-Smirnov tests on throughput histograms, correlation of congestion time series, or hold-out real-system episodes). Because every reported metric and the offline-to-online transition argument rest exclusively on emulator fidelity, this omission is load-bearing for the central claims.
Authors: We acknowledge the value of quantitative emulator-to-reality calibration. However, due to operational constraints and proprietary restrictions on live warehouse data, we lack access to hold-out real-system episodes or the raw time-series data needed for KS tests and correlation analyses. We will expand the evaluation section with all available emulator validation details and explicitly discuss the emulator-to-reality gap as a study limitation. revision: partial
-
Referee: [Results / Discussion] The assertion that BCB produces a “decisive time-optimal policy backed by Bang-Bang control theory” is presented without an explicit mapping from the bandit action space or reward model to the bang-bang optimality condition; the connection therefore remains an unverified interpretation rather than a derived result.
Authors: We will revise the results and discussion sections to include an explicit mapping and derivation from the BCB action space and reward model to the bang-bang optimality conditions, converting the claim from an interpretation into a derived result supported by the model formulation. revision: yes
Circularity Check
No derivation chain or circular reduction present
full rationale
The paper is a comparative empirical study of three ML frameworks evaluated on data from a high-fidelity physics-aware emulator. No mathematical derivation, first-principles result, or predictive claim is asserted that reduces by construction to its own fitted inputs or self-citations. Reported metrics such as the 2.03% uplift are direct outputs of model evaluation within the chosen simulator environment; the emulator is treated as the experimental testbed rather than an unstated input being renamed as an output. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The high-fidelity physics-aware emulator sufficiently models real system dynamics and context variables
Reference graph
Works this paper leans on
-
[1]
Order consolidation in warehouses with compact 3d sorter modules,
Z. Zhou, N. Boysen, K. Stephan, H. Yu, and Y . Yu, “Order consolidation in warehouses with compact 3d sorter modules,” European Journal of Operational Research, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0377221725009828
2025
-
[2]
Warehouse management optimization using a sorting-based slotting approach,
J. C. Duque-Jaramillo, J. M. Cogollo-Fl ´orez, C. G. G ´omez-Mar´ın, and A. A. Correa-Espinal, “Warehouse management optimization using a sorting-based slotting approach,”Journal of Industrial Engineering and Management, vol. 17, no. 1, pp. 133–150, 2024
2024
-
[3]
Optimizing automated sorting in warehouses: The minimum order spread sequencing problem,
N. Boysen, S. Fedtke, and F. Weidinger, “Optimizing automated sorting in warehouses: The minimum order spread sequencing problem,”European Journal of Operational Research, vol. 270, no. 1, pp. 386–400, 2018
2018
-
[4]
Order consolidation in warehouses: The loop sorter scheduling problem,
N. Boysen, K. Stephan, and S. Schwerdfeger, “Order consolidation in warehouses: The loop sorter scheduling problem,”European Journal of Operational Research, vol. 316, no. 2, pp. 459–472, 2024
2024
-
[5]
Lstm and linear programming- based optimization for logistics sorting center operations,
H. Wang, Z. Liu, Y . Chen, and X. Xie, “Lstm and linear programming- based optimization for logistics sorting center operations,” in2025 IEEE 7th International Conference on Communications, Information System and Computer Engineering (CISCE), 2025, pp. 862–866
2025
-
[6]
A contextual bandits framework for personalized learning action selection,
A. S. Lan and R. Baraniuk, “A contextual bandits framework for personalized learning action selection,” inProceedings of the 9th International Conference on Educational Data Mining, 2016
2016
-
[7]
B. Liang, L. Xu, A. Taneja, M. Tambe, and L. Janson, “Context in public health for underserved communities: A bayesian approach to online restless bandits,” 2024. [Online]. Available: https://arxiv.org/abs/ 2402.04933
arXiv 2024
-
[8]
From ads to interventions: Contextual bandits in mobile health,
A. Tewari and S. A. Murphy, “From ads to interventions: Contextual bandits in mobile health,” inMobile Health. Cham: Springer International Publishing, 2017, pp. 495–517
2017
-
[9]
Multi-objective contextual bandits in recommendation systems for smart tourism,
S. Qassimi and S. Rakrak, “Multi-objective contextual bandits in recommendation systems for smart tourism,”Scientific Reports, vol. 15, no. 1, Apr 2025
2025
-
[10]
A contextual-bandit approach to personalized news article recommendation,
L. Li, W. Chu, J. Langford, and R. E. Schapire, “A contextual-bandit approach to personalized news article recommendation,” inProceedings of the 19th International Conference on World Wide Web. New York, NY , USA: ACM, 2010, pp. 661–670
2010
-
[11]
Bayesian reinforcement learning: A survey,
M. Ghavamzadeh, S. Mannor, J. Pineau, and A. Tamar, “Bayesian reinforcement learning: A survey,”Foundations and Trends® in Machine Learning, vol. 8, no. 5-6, p. 359–483, Nov 2015. [Online]. Available: https://arxiv.org/abs/1609.04436
Pith/arXiv arXiv 2015
-
[12]
A concept for optimal warehouse allocation using contextual multi-arm bandits,
G. Siciliano, D. Braun, K. Z ¨ols, and J. Fottner, “A concept for optimal warehouse allocation using contextual multi-arm bandits,” inProceedings of the 25th International Conference on Enterprise Information Systems, Apr 2023, pp. 460–467. [Online]. Available: https://www.researchgate.net/publication/370315477
arXiv 2023
-
[13]
The bang-bang principle for linear control systems,
L. M. Sonneborn and F. S. Van Vleck, “The bang-bang principle for linear control systems,”Journal of the Society for Industrial and Applied Mathematics Series A Control, vol. 2, no. 2, pp. 151–159, Jan 1964
1964
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.