Enhancing Decision-Making with Large Language Models through Multi-Agent Fictitious Play
Pith reviewed 2026-06-26 20:56 UTC · model grok-4.3
The pith
MAFP lets LLM agents resolve stance entanglement by iteratively best-responding to the empirical mixture of each other's past decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
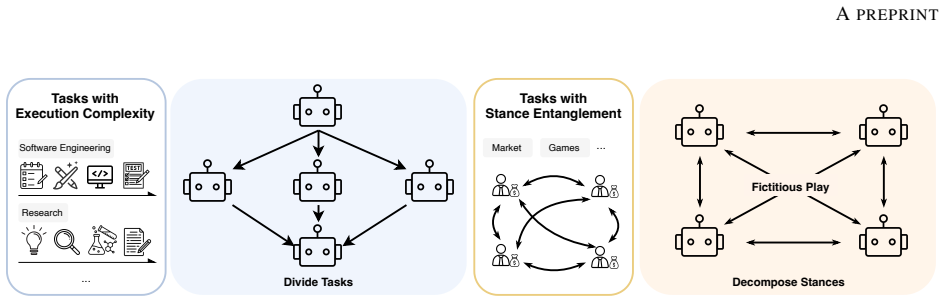
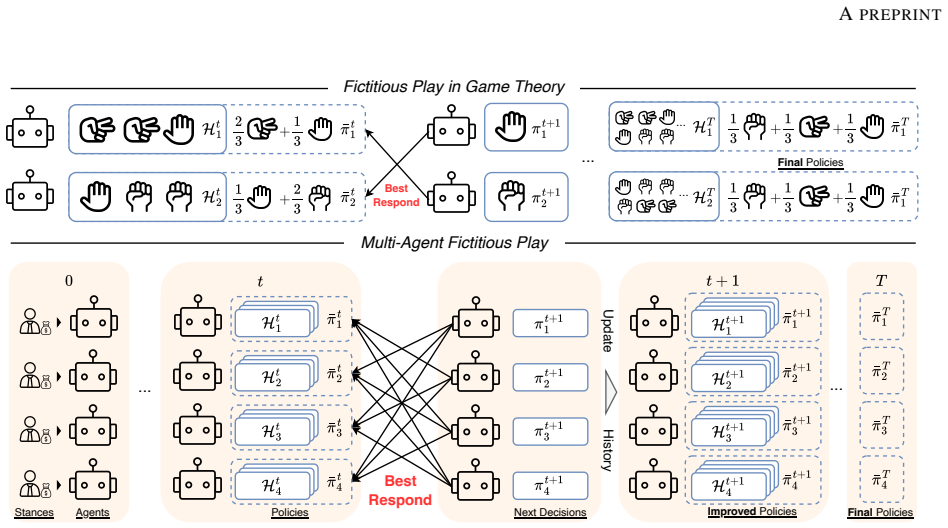
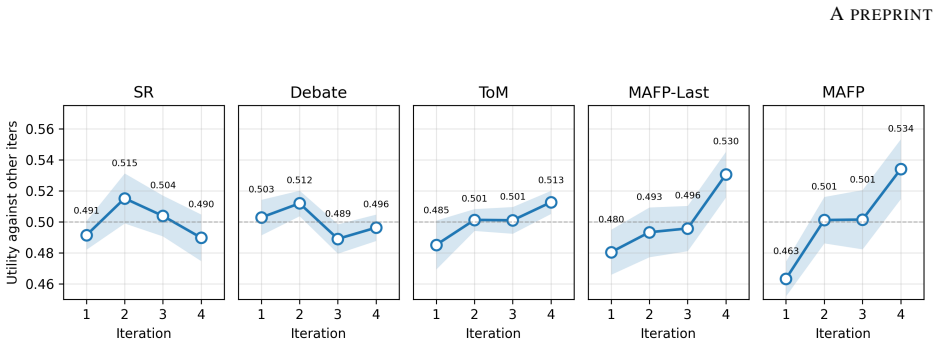
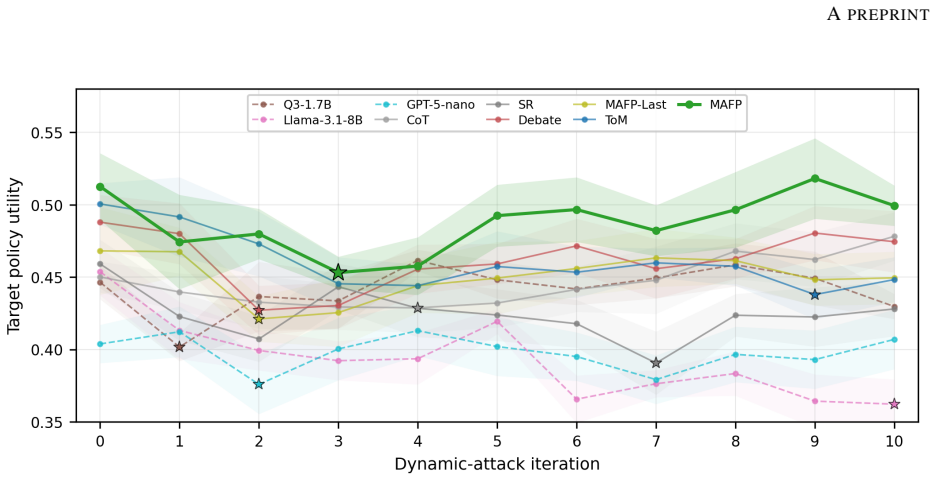
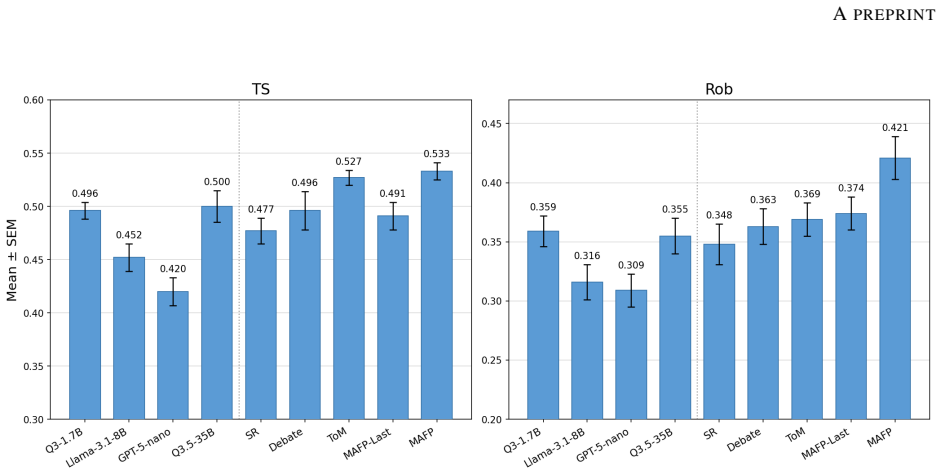
Multi-Agent Fictitious Play (MAFP) represents each stakeholder stance as an agent and formulates the decision problem as an equilibrium-seeking process in which every agent repeatedly replaces its decision with the best response to the empirical mixture of all other agents' previous decisions, thereby addressing stance entanglement and yielding decisions that outperform both single-round and multi-round baselines on tournament strength and robustness metrics.
What carries the argument
The fictitious-play update rule, in which each agent selects its next decision as the best response to the historical average of the other agents' decisions, carried out through LLM prompting.
If this is right
- Agents expose and correct one another's decision weaknesses through successive best-response updates.
- The resulting decisions score higher on both tournament strength and robustness than single-round or multi-round baselines.
- The method applies directly to tasks that require simultaneous reasoning across interdependent stances.
- Decision quality improves progressively rather than in a single forward pass.
Where Pith is reading between the lines
- The same prompting-based best-response loop could be applied to negotiation or resource-allocation settings that are not framed as tournaments.
- Scalability questions arise once the number of agents grows beyond the small numbers tested, because each iteration requires additional LLM calls.
- If the best-response step proves reliable, the approach could be layered on top of existing multi-agent debate or voting procedures.
- The framework supplies a concrete test for whether current LLMs can maintain coherent best-response behavior across multiple rounds without external stabilization.
Load-bearing premise
That LLM prompting will produce consistent best responses to the empirical mixture of past decisions and that the sequence of updates will converge to higher-quality joint decisions rather than cycle or amplify inconsistencies.
What would settle it
Running MAFP on a fixed collection of decision tasks and observing either no measurable gain in tournament strength after several iterations or repeated cycling between the same small set of decisions.
Figures



read the original abstract
Large language model (LLM)-based multi-agent systems (MAS) have demonstrated great potential in solving tasks with execution complexity, by distributing subtasks across cooperative agents. However, this divide-and-conquer paradigm falls short on decision-making tasks that are also prevalent in the real world. These tasks require simultaneous reasoning from the stances of all involved stakeholders whose decisions are mutually dependent and thus cannot be solved in isolation. We characterize this challenge as stance entanglement, a form of decision complexity distinct from execution complexity. To address it, we propose Multi-Agent Fictitious Play (MAFP), a novel MAS paradigm that represents stakeholder stances as agents and formulates decision-making as an equilibrium-seeking process. Built on the game-theoretic principle of fictitious play, MAFP iteratively updates each agent's decision by best responding to the empirical mixture of other agents' past decisions. This enables agents to expose and address one another's weaknesses, progressively improving decision quality and robustness. We evaluate MAFP on challenging decision-making tasks that test the capability of deciding strategies for competitive scenarios prior to acting. MAFP outperforms both single-round and multi-round baselines on two complementary metrics, tournament strength and robustness, demonstrating its effectiveness in addressing stance entanglement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multi-Agent Fictitious Play (MAFP), a multi-agent LLM paradigm that models stakeholder stances as agents and casts decision-making as an iterative equilibrium-seeking process based on the game-theoretic fictitious-play update rule. Each agent best-responds to the empirical mixture of other agents' historical decisions, with the goal of exposing and mitigating stance entanglement. The central empirical claim is that MAFP outperforms both single-round and multi-round baselines on tournament strength and robustness metrics across competitive decision-making tasks.
Significance. If the reported gains hold under rigorous controls, the work supplies a concrete, principle-driven mechanism for improving joint decision quality in LLM-based MAS where decisions are interdependent. It directly imports an established convergence concept from game theory rather than inventing new dynamics, which is a strength.
major comments (2)
- [Abstract, §4] Abstract and §4 (Evaluation): the central claim of outperformance on tournament strength and robustness is stated without definitions of either metric, without the number of runs, without statistical tests, and without controls for prompt variability or LLM stochasticity. These omissions make the quantitative results impossible to interpret or reproduce and are load-bearing for the main contribution.
- [§3] §3 (Method): the fictitious-play update is described at a high level via LLM prompting, but no concrete prompt templates, temperature settings, or stopping criteria are supplied. Without these, it is impossible to assess whether the iterative best-response step reliably produces consistent improvements or merely cycles, which directly affects the weakest assumption identified in the stress test.
minor comments (2)
- [Introduction] The term 'stance entanglement' is introduced without a formal definition or citation to prior literature on interdependent decision problems.
- [§3] No pseudocode or algorithmic listing of the MAFP loop is provided, which would clarify the exact sequence of best-response calls and mixture updates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address each major comment point by point below and will revise the manuscript to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): the central claim of outperformance on tournament strength and robustness is stated without definitions of either metric, without the number of runs, without statistical tests, and without controls for prompt variability or LLM stochasticity. These omissions make the quantitative results impossible to interpret or reproduce and are load-bearing for the main contribution.
Authors: We agree that these details are essential for interpreting and reproducing the results. In the revised manuscript, we will add explicit definitions of tournament strength and robustness in the abstract and §4, report the exact number of runs, include appropriate statistical tests (such as paired t-tests or Wilcoxon signed-rank tests with p-values), and describe controls for prompt variability and LLM stochasticity (e.g., fixed random seeds, multiple prompt paraphrases, and temperature settings). revision: yes
-
Referee: [§3] §3 (Method): the fictitious-play update is described at a high level via LLM prompting, but no concrete prompt templates, temperature settings, or stopping criteria are supplied. Without these, it is impossible to assess whether the iterative best-response step reliably produces consistent improvements or merely cycles, which directly affects the weakest assumption identified in the stress test.
Authors: We acknowledge that the current description in §3 is insufficient for full reproducibility and evaluation of the update process. In the revised version, we will supply the complete prompt templates for the best-response and mixture steps, specify the LLM temperature and other generation parameters, and detail the stopping criteria (such as maximum iterations or convergence thresholds based on decision stability). revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents MAFP as a direct application of the established game-theoretic fictitious play process to LLM agents, without any equations, parameter fitting, or derivations that reduce outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the iterative best-response mechanism is described as an external principle rather than an internally defined or renamed construct. The evaluation claims are empirical (outperformance on tournament strength and robustness) and do not rely on self-referential steps. This matches the default case of a self-contained application of prior theory.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025
2025
-
[2]
Axel Backlund and Lukas Petersson. Vending-bench: A benchmark for long-term coherence of autonomous agents.arXiv preprint arXiv:2502.15840, 2025
arXiv 2025
-
[3]
Suma Bailis, Jane Friedhoff, and Feiyang Chen. Werewolf arena: A case study in llm evaluation via social deduction.arXiv preprint arXiv:2407.13943, 2024
arXiv 2024
-
[4]
How well can llms negotiate? negotiationarena platform and analysis
Federico Bianchi, Patrick John Chia, Mert Yuksekgonul, Jacopo Tagliabue, Dan Jurafsky, and James Zou. How well can llms negotiate? negotiationarena platform and analysis. InInternational Conference on Machine Learning, pages 3935–3951. PMLR, 2024
2024
-
[5]
Iterative solution of games by fictitious play.Act
George W Brown. Iterative solution of games by fictitious play.Act. Anal. Prod Allocation, 13(1):374, 1951
1951
-
[6]
Jiangjie Chen, Siyu Yuan, Rong Ye, Bodhisattwa Prasad Majumder, and Kyle Richardson. Put your money where your mouth is: Evaluating strategic planning and execution of llm agents in an auction arena.arXiv preprint arXiv:2310.05746, 2023
arXiv 2023
-
[7]
Llmarena: Assessing capabilities of large language models in dynamic multi-agent environments
Junzhe Chen, Xuming Hu, Shuodi Liu, Shiyu Huang, Wei-Wei Tu, Zhaofeng He, and Lijie Wen. Llmarena: Assessing capabilities of large language models in dynamic multi-agent environments. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13055–13077, 2024
2024
-
[8]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InInternational Conference on Learning Representations, volume 2024, pages 20094–20136, 2024
2024
-
[9]
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, and Arjun Yadav. Gamebench: Evaluating strategic reasoning abilities of llm agents.arXiv preprint arXiv:2406.06613, 2024
arXiv 2024
-
[10]
Logan Cross, Violet Xiang, Agam Bhatia, Daniel LK Yamins, and Nick Haber. Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models.arXiv preprint arXiv:2407.07086, 2024
arXiv 2024
-
[11]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
Pith/arXiv arXiv 2025
-
[12]
Improving factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[13]
Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations.Advances in Neural Information Processing Systems, 37:28219–28253, 2024
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations.Advances in Neural Information Processing Systems, 37:28219–28253, 2024
2024
-
[14]
Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
Meta Fundamental AI Research Diplomacy Team (FAIR)†, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, et al. Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
2022
-
[15]
Theory of mind.Current biology, 15(17):R644–R645, 2005
Chris Frith and Uta Frith. Theory of mind.Current biology, 15(17):R644–R645, 2005
2005
-
[16]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[17]
Zhouhong Gu, Xiaoxuan Zhu, Yin Cai, Hao Shen, Xingzhou Chen, Qingyi Wang, Jialin Li, Xiaoran Shi, Haoran Guo, Wenxuan Huang, et al. Agentgroupchat-v2: Divide-and-conquer is what llm-based multi-agent system need.arXiv preprint arXiv:2506.15451, 2025
arXiv 2025
-
[18]
Jiaxian Guo, Bo Yang, Paul Yoo, Bill Yuchen Lin, Yusuke Iwasawa, and Yutaka Matsuo. Suspicion-agent: Playing imperfect information games with theory of mind aware gpt-4.arXiv preprint arXiv:2309.17277, 2023
arXiv 2023
-
[19]
A general theory of equilibrium selection in games.MIT Press Books, 1, 1988
John C Harsanyi and Reinhard Selten. A general theory of equilibrium selection in games.MIT Press Books, 1, 1988. 10 APREPRINT
1988
-
[20]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pages 23247–23275, 2024
2024
-
[21]
Fantom: A benchmark for stress-testing machine theory of mind in interactions
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. Fantom: A benchmark for stress-testing machine theory of mind in interactions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413, 2023
2023
-
[22]
Fast algorithms for finding randomized strategies in game trees
Daphne Koller, Nimrod Megiddo, and Bernhard von Stengel. Fast algorithms for finding randomized strategies in game trees. InSymposium on the Theory of Computing, 1994
1994
-
[23]
Extensive games and the problem of information.Contributions to the Theory of Games, 2(28):193–216, 1953
Harold W Kuhn. Extensive games and the problem of information.Contributions to the Theory of Games, 2(28):193–216, 1953
1953
-
[24]
Macm: Utilizing a multi-agent system for condition mining in solving complex mathematical problems.Advances in Neural Information Processing Systems, 37:53418–53437, 2024
Bin Lei, Yi Zhang, Shan Zuo, Ali Payani, and Caiwen Ding. Macm: Utilizing a multi-agent system for condition mining in solving complex mathematical problems.Advances in Neural Information Processing Systems, 37:53418–53437, 2024
2024
-
[25]
Lemke and Jr
Carlton E. Lemke and Jr. Joseph T. Howson. Equilibrium points of bimatrix games.Journal of The Society for Industrial and Applied Mathematics, 12:413–423, 1964
1964
-
[26]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
2023
-
[27]
Encouraging divergent thinking in large language models through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 17889–17904, 2024
2024
-
[28]
Avalonbench: Evaluating llms playing the game of avalon.arXiv preprint arXiv:2310.05036, 2023
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu. Avalonbench: Evaluating llms playing the game of avalon.arXiv preprint arXiv:2310.05036, 2023
arXiv 2023
-
[29]
L-mtp: Leap multi-token prediction beyond adjacent context for large language models.Advances in Neural Information Processing Systems, 38:102569–102600, 2026
Xiaohao Liu, Xiaobo Xia, Weixiang Zhao, Manyi Zhang, Xianzhi Yu, Xiu Su, Shuo Yang, See-Kiong Ng, and Tat-Seng Chua. L-mtp: Leap multi-token prediction beyond adjacent context for large language models.Advances in Neural Information Processing Systems, 38:102569–102600, 2026
2026
-
[30]
A dynamic llm-powered agent network for task-oriented agent collaboration
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic llm-powered agent network for task-oriented agent collaboration. InFirst Conference on Language Modeling, 2024
2024
-
[31]
Edward Lockhart, Marc Lanctot, Julien Pérolat, Jean-Baptiste Lespiau, Dustin Morrill, Finbarr Timbers, and Karl Tuyls. Computing approximate equilibria in sequential adversarial games by exploitability descent.arXiv preprint arXiv:1903.05614, 2019
arXiv 1903
-
[32]
Introducing wide research, 2025
Manus. Introducing wide research, 2025. URLhttps://manus.im/blog/introducing-wide-research
2025
-
[33]
R Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D Hardy, and Thomas L Griffiths. Embers of autoregression show how large language models are shaped by the problem they are trained to solve.Proceedings of the National Academy of Sciences, 121(41):e2322420121, 2024
2024
-
[34]
R Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D Hardy, and Thomas L Griffiths. When a language model is optimized for reasoning, does it still show embers of autoregression? an analysis of openai o1.arXiv preprint arXiv:2410.01792, 2024
arXiv 2024
-
[35]
Mike A. Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Hyeob Shin, Thomas Walshe, Estefany Kelly Buchanan, Junhong Shen, Guanghao Ye, Hao Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen,...
Pith/arXiv arXiv 2026
-
[36]
Fictitious play property for games with identical interests.Journal of economic theory, 68 (1):258–265, 1996
Dov Monderer and Lloyd S Shapley. Fictitious play property for games with identical interests.Journal of economic theory, 68 (1):258–265, 1996
1996
-
[37]
Non-cooperative games.ANNALS OF MATHEMATICS, 54(2), 1951
John Nash. Non-cooperative games.ANNALS OF MATHEMATICS, 54(2), 1951
1951
-
[38]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
2024
-
[39]
Escalation risks from language models in military and diplomatic decision-making
Juan-Pablo Rivera, Gabriel Mukobi, Anka Reuel, Max Lamparth, Chandler Smith, and Jacquelyn Schneider. Escalation risks from language models in military and diplomatic decision-making. InProceedings of the 2024 ACM conference on fairness, accountability, and transparency, pages 836–898, 2024. 11 APREPRINT
2024
-
[40]
Mixed-integer programming methods for finding nash equilibria
Tuomas Sandholm, Andrew Gilpin, and Vincent Conitzer. Mixed-integer programming methods for finding nash equilibria. In AAAI Conference on Artificial Intelligence, 2005
2005
-
[41]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[42]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[43]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Pith/arXiv arXiv 2026
-
[44]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[45]
Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
Pith/arXiv arXiv 2025
-
[46]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Y Zou. Mixture-of-agents enhances large language model capabilities. InInternational Conference on Learning Representations, volume 2025, pages 33944–33963, 2025
2025
-
[47]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[48]
Boosting llm agents with recursive contemplation for effective deception handling
Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Boosting llm agents with recursive contemplation for effective deception handling. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9909–9953, 2024
2024
-
[49]
From bits to boardrooms: A cutting-edge multi-agent llm framework for business excellence
Zihao Wang and Junming Zhang. From bits to boardrooms: A cutting-edge multi-agent llm framework for business excellence. arXiv preprint arXiv:2508.15447, 2025
arXiv 2025
-
[50]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[51]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeff Han, Isa Fulford, Hyung Won Chung, Alexandre Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv: 2504.12516, 2025
Pith/arXiv arXiv 2025
-
[52]
Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities
Alex Wilf, Sihyun Lee, Paul Pu Liang, and Louis-Philippe Morency. Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8292–8308, 2024
2024
-
[53]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[54]
Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, and Naihao Deng. Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10691–10706, 2023
2023
-
[55]
Chen Xu, Yicheng Hu, Ruizi Wang, Xinyu Lin, Wenjie Wang, Dongrui Liu, and Fuli Feng. Tacomas: Test-time co-evolution of topology and capability in llm-based multi-agent systems.arXiv preprint arXiv:2605.09539, 2026
Pith/arXiv arXiv 2026
-
[56]
Renjun Xu and Jingwen Peng. A comprehensive survey of deep research: Systems, methodologies, and applications.arXiv preprint arXiv:2506.12594, 2025
arXiv 2025
-
[57]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[58]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems.Advances in Neural Information Processing Systems, 38: 107309–107336, 2026
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems.Advances in Neural Information Processing Systems, 38: 107309–107336, 2026
2026
-
[59]
Junhyeog Yun, Hyoun Jun Lee, and Insu Jeon. Quantevolve: Automating quantitative strategy discovery through multi-agent evolutionary framework.arXiv preprint arXiv:2510.18569, 2025
arXiv 2025
-
[60]
Steering no-regret learners to a desired equilibrium
Brian Hu Zhang, Gabriele Farina, Ioannis Anagnostides, Federico Cacciamani, Stephen Marcus McAleer, Andreas Alexander Haupt, Andrea Celli, Nicola Gatti, Vincent Conitzer, and Tuomas Sandholm. Steering no-regret learners to a desired equilibrium. arXiv preprint arXiv:2306.05221, 2023
arXiv 2023
-
[61]
Linghua Zhang, Jun Wang, Jingtong Wu, and Zhisong Zhang. Retailbench: Evaluating long-horizon autonomous decision- making and strategy stability of llm agents in realistic retail environments.arXiv preprint arXiv:2603.16453, 2026
Pith/arXiv arXiv 2026
-
[62]
Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Adrian de Wynter, Yan Xia, Wenshan Wu, Ting Song, Man Lan, and Furu Wei. Llm as a mastermind: A survey of strategic reasoning with large language models.arXiv preprint arXiv:2404.01230, 2024. 12 APREPRINT
arXiv 2024
-
[63]
K-level reasoning: Establishing higher order beliefs in large language models for strategic reasoning
Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Yan Xia, Man Lan, and Furu Wei. K-level reasoning: Establishing higher order beliefs in large language models for strategic reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
2025
-
[64]
Chain of agents: Large language models collaborating on long-context tasks.Advances in Neural Information Processing Systems, 37:132208–132237, 2024
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Ö Arık. Chain of agents: Large language models collaborating on long-context tasks.Advances in Neural Information Processing Systems, 37:132208–132237, 2024
2024
-
[65]
An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
Weike Zhao, Chaoyi Wu, Yanjie Fan, Pengcheng Qiu, Xiaoman Zhang, Yuze Sun, Xiao Zhou, Shuju Zhang, Yu Peng, Yanfeng Wang, et al. An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
2026
-
[66]
no winner
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024. 13 APREPRINT Table 3: Scenarios Description. Scenario Description Strategic Games TicTacToe A two-player game on a 3×3 grid; players alter...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.