MG-RWKV: Multi-Grained Context-Aware RWKV for Temporal Forgery Localization
Pith reviewed 2026-07-02 14:01 UTC · model grok-4.3
The pith
MG-RWKV localizes temporal forgeries in untrimmed videos by processing full sequences at linear complexity through bidirectional RWKV, dynamic multi-granularity routing, and cross-granularity consistency alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
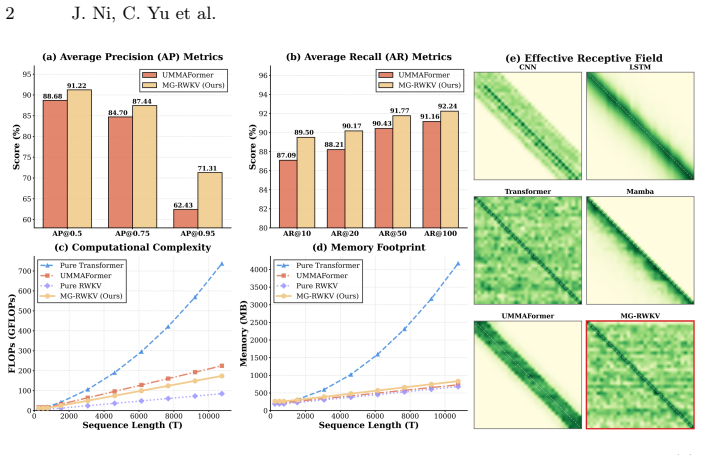
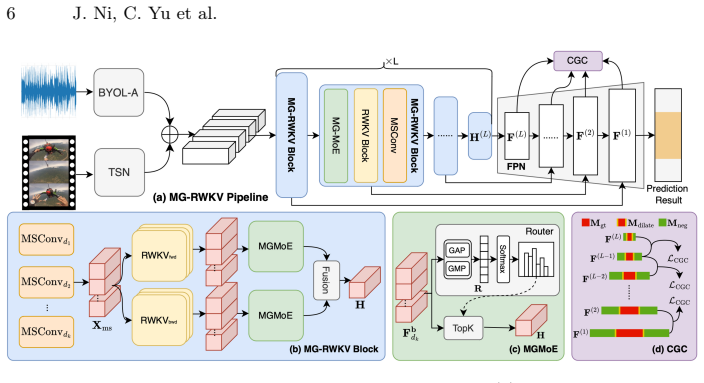
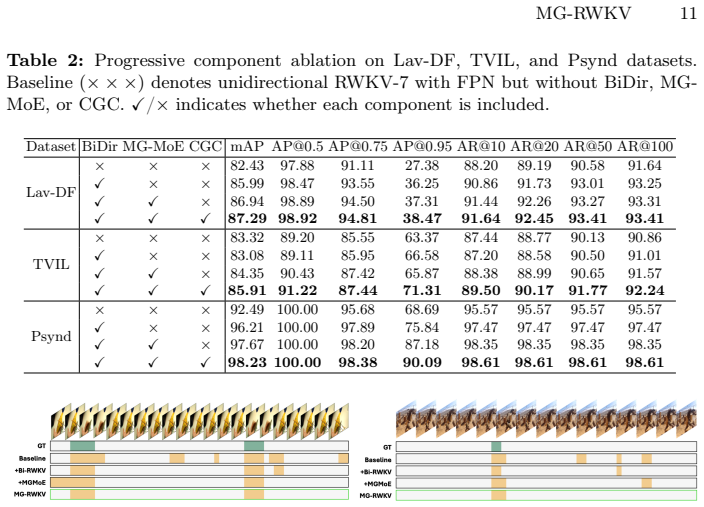
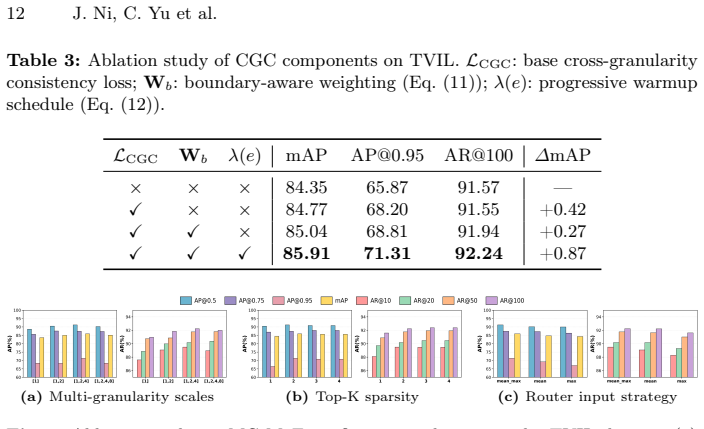
MG-RWKV is a multi-granularity framework that leverages the data-dependent state evolution of RWKV to achieve efficient full-sequence processing with O(T) complexity; its three core innovations are a Bidirectional RWKV architecture for bidirectional temporal contexts, a Multi-Granularity Mixture of Experts (MG-MoE) that routes over explicit temporal receptive fields according to forgery duration, and Cross-Granularity Consistency (CGC) that aligns adjacent feature pyramid levels via hierarchical scale-wise pairing and spatial boundary-aware weighting, together yielding state-of-the-art performance on Lav-DF, TVIL, and Psynd with low computational cost.
What carries the argument
Bidirectional RWKV combined with MG-MoE dynamic routing over explicit temporal receptive fields and CGC hierarchical alignment, which together compress global authentic context while preserving local forgery cues.
If this is right
- Full video sequences can be processed at linear O(T) cost instead of quadratic transformer scaling.
- Expert routing selects receptive-field granularity automatically according to observed forgery duration.
- Hierarchical alignment of pyramid levels reduces false positives inside authentic regions.
- Decision boundaries become more interpretable because each expert corresponds to an explicit temporal scale.
- State-of-the-art detection accuracy is maintained while computational cost stays low on the three tested benchmarks.
Where Pith is reading between the lines
- The same multi-granularity routing could be applied to audio-only or multimodal streams if the state-evolution mechanism transfers.
- Real-time content-moderation pipelines could adopt the linear-complexity backbone once the routing overhead is quantified on streaming inputs.
- If CGC weighting proves stable under distribution shift, the approach may reduce annotation effort needed for new forgery types.
- The explicit temporal receptive fields in MG-MoE offer a natural testbed for studying how forgery duration statistics affect detection thresholds.
Load-bearing premise
The proposed Bidirectional RWKV, MG-MoE routing, and CGC alignment will generalize beyond the three evaluated datasets without introducing new false-positive patterns in authentic regions.
What would settle it
Running MG-RWKV on a held-out dataset containing forgery durations and editing styles absent from Lav-DF, TVIL, and Psynd, then measuring whether the false-positive rate in authentic segments rises above the levels reported on the original three benchmarks.
Figures
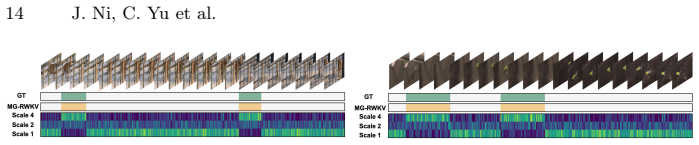
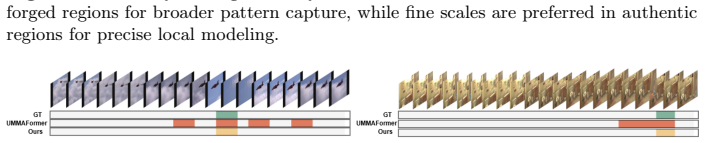
read the original abstract
Driven by Artificial Intelligence-Generated Content (AIGC), the authenticity of audio-visual content is facing severe challenges. Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments within untrimmed sequences. However, existing methods are limited by CNNs' local receptive fields or Transformers' quadratic complexity, while emerging linear models often struggle to balance global authentic context compression with local abrupt forgery perception. To address this, we propose MG-RWKV, a multi-granularity framework that leverages the data-dependent state evolution of RWKV to achieve efficient full-sequence processing with O(T) complexity. Our framework features three core innovations: (1) a Bidirectional RWKV architecture that captures bidirectional temporal contexts without quadratic overhead; (2) a Multi-Granularity Mixture of Experts (MG-MoE) that performs dynamic routing over explicit temporal receptive fields, adaptively selecting granularities based on forgery duration to significantly enhance decision interpretability; and (3) Cross-Granularity Consistency (CGC), which aligns adjacent feature pyramid levels through hierarchical scale-wise pairing and spatial boundary-aware weighting, effectively reducing false positives in authentic regions. Extensive experiments on Lav-DF, TVIL, and Psynd datasets demonstrate that MG-RWKV achieves state-of-the-art performance with low computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MG-RWKV, a multi-granularity framework for temporal forgery localization that uses a Bidirectional RWKV architecture for efficient O(T) full-sequence processing, a Multi-Granularity Mixture of Experts (MG-MoE) for dynamic routing over temporal receptive fields, and Cross-Granularity Consistency (CGC) for hierarchical scale-wise alignment to reduce false positives. It claims these components jointly achieve state-of-the-art localization performance with low computational cost on the Lav-DF, TVIL, and Psynd datasets.
Significance. If the empirical results and component contributions hold under scrutiny, the work could provide a useful linear-complexity alternative to quadratic Transformer or local CNN approaches for TFL, with added interpretability from explicit granularity routing. The emphasis on data-dependent state evolution and boundary-aware weighting addresses a recognized tension in the field between global context and local forgery cues.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim that the three components deliver SOTA localization while CGC 'effectively reduc[es] false positives in authentic regions' is unsupported because the abstract supplies no quantitative metrics, baseline tables, ablation results, or error analysis, and the experiments section reports results only on the three in-distribution datasets without cross-dataset transfer, OOD authentic-video tests, or ablations that isolate whether MG-MoE routing or CGC introduces new false-positive modes under different forgery durations or editing styles.
- [§3.3 (CGC) and §4] §3.3 (CGC) and §4: The claim that CGC alignment suppresses false positives rests on the assumption that scale-wise pairing and spatial boundary-aware weighting generalize; no evidence is given that this holds when forgery durations or editing styles differ from the training distribution, leaving the load-bearing generalization assumption untested.
minor comments (2)
- [§3] Notation for the MG-MoE routing weights and the CGC pairing function should be introduced with explicit equations rather than descriptive text only.
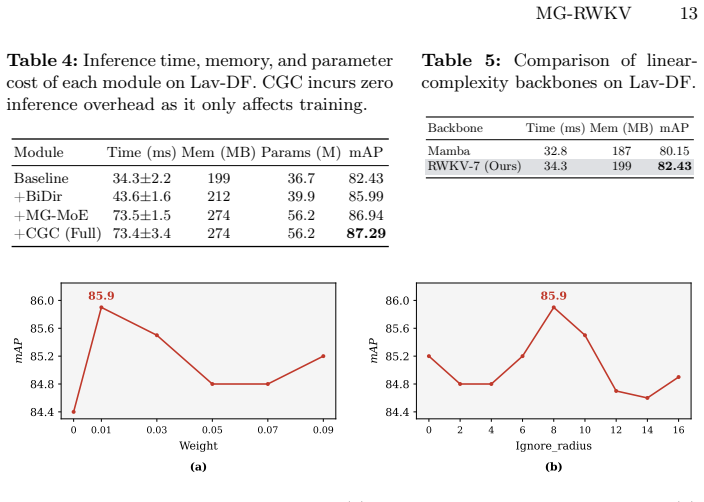
- [§4] Figure captions and axis labels in the experimental figures should explicitly state the evaluation metric (e.g., AUC, F1 at specific IoU thresholds) and whether results are reported on the full untrimmed sequences.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on our manuscript. We address each major comment below, providing clarifications based on the content of the paper while remaining honest about the scope of our experiments.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim that the three components deliver SOTA localization while CGC 'effectively reduc[es] false positives in authentic regions' is unsupported because the abstract supplies no quantitative metrics, baseline tables, ablation results, or error analysis, and the experiments section reports results only on the three in-distribution datasets without cross-dataset transfer, OOD authentic-video tests, or ablations that isolate whether MG-MoE routing or CGC introduces new false-positive modes under different forgery durations or editing styles.
Authors: The abstract follows standard conventions by summarizing contributions at a high level without embedding quantitative metrics or tables; all supporting evidence, including SOTA comparisons (Table 1), computational costs, and component ablations (§4.3), appears in the experiments section. The three evaluated datasets cover varied forgery durations and editing styles, and the ablation studies quantify the contribution of each module, including CGC's effect on localization precision. We did not include cross-dataset transfer or explicit OOD authentic-video tests, as the work centers on in-distribution performance across these benchmarks; the consistent improvements across datasets provide the primary empirical support for the claims. revision: no
-
Referee: [§3.3 (CGC) and §4] §3.3 (CGC) and §4: The claim that CGC alignment suppresses false positives rests on the assumption that scale-wise pairing and spatial boundary-aware weighting generalize; no evidence is given that this holds when forgery durations or editing styles differ from the training distribution, leaving the load-bearing generalization assumption untested.
Authors: Section 3.3 details the CGC design for hierarchical alignment via scale-wise pairing and boundary-aware weighting, and §4.3 ablations show that ablating CGC degrades performance metrics associated with false positives in authentic segments. The three datasets include differences in forgery characteristics, offering indirect support for the mechanism's effectiveness. We agree that dedicated out-of-distribution tests on unseen editing styles would provide stronger evidence of generalization and would be a valuable addition, though they fall outside the current experimental scope focused on the reported benchmarks. revision: partial
Circularity Check
No circularity: empirical proposal with independent experimental validation.
full rationale
The paper introduces MG-RWKV as a new architecture with Bidirectional RWKV, MG-MoE routing, and CGC alignment to address TFL challenges. Claims rest on empirical SOTA results across Lav-DF, TVIL, and Psynd datasets rather than any derivation chain, fitted-parameter predictions, or self-citation load-bearing theorems. No equations reduce performance metrics to inputs by construction, and the text frames the components as novel proposals without invoking prior self-work as uniqueness proofs. This is a standard self-contained ML architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Anshul,A.,Gopal,S.,Rajan,D.,Chng,E.S.:Intra-modalandcross-modalsynchro- nization for audio-visual deepfake detection and temporal localization. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 13826– 13836 (2025)
2025
-
[2]
arXiv preprint arXiv:2106.14118 (2021)
Bagchi, A., Mahmood, J., Fernandes, D., Sarvadevabhatla, R.K.: Hear me out: Fu- sional approaches for audio augmented temporal action localization. arXiv preprint arXiv:2106.14118 (2021)
-
[3]
In: Proceedings of the IEEE international conference on computer vision
Bodla, N., Singh, B., Chellappa, R., Davis, L.S.: Soft-NMS–improving object de- tection with one line of code. In: Proceedings of the IEEE international conference on computer vision. pp. 5561–5569 (2017)
2017
-
[4]
In: Proceedings of the British Machine Vision Conference (BMVC)
Buch, S., Escorcia, V., Ghanem, B., Fei-Fei, L., Niebles, J.C.: End-to-end, single- stream temporal action detection in untrimmed videos. In: Proceedings of the British Machine Vision Conference (BMVC). BMVA Press (2017)
2017
-
[5]
Cai,Z.,Ghosh,S.,Adatia,A.P.,Hayat,M.,Dhall,A.,Gedeon,T.,Stefanov,K.:Av- deepfake1m:Alarge-scalellm-drivenaudio-visualdeepfakedataset.In:Proceedings of the 32nd ACM International Conference on Multimedia. pp. 7414–7423 (2024)
2024
-
[6]
Computer Vision and Image Understanding236, 103818 (2023)
Cai, Z., Ghosh, S., Dhall, A., Gedeon, T., Stefanov, K., Hayat, M.: Glitch in the matrix: A large scale benchmark for content driven audio–visual forgery detection and localization. Computer Vision and Image Understanding236, 103818 (2023)
2023
-
[7]
In: 2022 International Conference on Digital Image Computing: Tech- niques and Applications (DICTA)
Cai, Z., Stefanov, K., Dhall, A., Hayat, M.: Do you really mean that? content driven audio-visual deepfake dataset and multimodal method for temporal forgery localization. In: 2022 International Conference on Digital Image Computing: Tech- niques and Applications (DICTA). pp. 1–10. IEEE (2022)
2022
-
[8]
In: Proceedings of the AAAI conference on artificial intelligence
Chen, G., Zheng, Y.D., Wang, L., Lu, T.: DCAN: improving temporal action de- tection via dual context aggregation. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 248–257 (2022)
2022
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Y., Huang, X., Zhang, Q., Li, W., Zhu, M., Yan, Q., Li, S., Chen, H., Hu, H., Yang, J., et al.: GIM: A million-scale benchmark for generative image manipulation detection and localization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2311–2319 (2025)
2025
-
[10]
In: International Conference on Learning Representations (2021)
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., et al.: Rethinking attention with performers. In: International Conference on Learning Representations (2021)
2021
-
[11]
In: Proceedings of the 28th ACM international conference on multimedia
Chugh, K., Gupta, P., Dhall, A., Subramanian, R.: Not made for each other-audio- visual dissonance-based deepfake detection and localization. In: Proceedings of the 28th ACM international conference on multimedia. pp. 439–447 (2020)
2020
-
[12]
In: Interspeech
Chung, J.S., Nagrani, A., Zisserman, A.: VoxCeleb2: Deep speaker recognition. In: Interspeech. pp. 1086–1090 (2018)
2018
-
[13]
IEEE Transactions on Pat- tern Analysis and Machine Intelligence45(3), 3539–3553 (2022) 16 J
Dong, C., Chen, X., Hu, R., Cao, J., Li, X.: MVSS-Net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Transactions on Pat- tern Analysis and Machine Intelligence45(3), 3539–3553 (2022) 16 J. Ni, C. Yu et al
2022
-
[14]
Multimedia Tools and Applications83(2), 4241–4307 (2024)
El-Shafai, W., Fouda, M.A., El-Rabaie, E.S.M., El-Salam, N.A.: A comprehensive taxonomy on multimedia video forgery detection techniques: challenges and novel trends. Multimedia Tools and Applications83(2), 4241–4307 (2024)
2024
-
[15]
Cascaded Boundary Regression for Temporal Action Detection
Gao, J., Yang, Z., Nevatia, R.: Cascaded boundary regression for temporal action detection. arXiv preprint arXiv:1705.01180 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
In: Conference on Language Modeling (COLM) (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: Conference on Language Modeling (COLM) (2024)
2024
-
[17]
In: International Conference on Learning Representations (2022)
Gu, A., Goel, K., Ré, C.: Efficiently modeling long sequences with structured state spaces. In: International Conference on Learning Representations (2022)
2022
-
[18]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guillaro, F., Cozzolino, D., Sud, A., Dufour, N., Verdoliva, L.: TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20606–20615 (2023)
2023
-
[19]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, Y., Gan, B., Chen, S., Zhou, Y., Yin, G., Song, L., Sheng, L., Shao, J., Liu, Z.: ForgeryNet: A versatile benchmark for comprehensive forgery analysis. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4360–4369 (2021)
2021
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Huang, B., Wang, Z., Yang, J., Ai, J., Zou, Q., Wang, Q., Ye, D.: Implicit iden- tity driven deepfake face swapping detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4490–4499 (2023)
2023
-
[21]
In: 2024 IEEE International Joint Conference on Biometrics (IJCB)
Katamneni, V.S., Rattani, A.: Contextual cross-modal attention for audio-visual deepfake detection and localization. In: 2024 IEEE International Joint Conference on Biometrics (IJCB). pp. 1–11. IEEE (2024)
2024
-
[22]
arXiv preprint arXiv:2411.10193 (2024)
Koutlis, C., Papadopoulos, S.: Dimodif: Discourse modality-information differ- entiation for audio-visual deepfake detection and localization. arXiv preprint arXiv:2411.10193 (2024)
-
[23]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Kwon, M.J., Yu, I.J., Nam, S.H., Lee, H.K.: CAT-Net: Compression artifact tracing network for detection and localization of image splicing. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 375–384 (2021)
2021
-
[24]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: BMN: Boundary-matching network for temporal action proposal generation. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 3889–3898 (2019)
2019
-
[25]
In: Proceedings of the 25th ACM international conference on Multimedia
Lin, T., Zhao, X., Shou, Z.: Single shot temporal action detection. In: Proceedings of the 25th ACM international conference on Multimedia. pp. 988–996 (2017)
2017
-
[26]
IEEE Transactions on Circuits and Systems for Video Technology32(11), 7505–7517 (2022)
Liu, X., Liu, Y., Chen, J., Liu, X.: PSCC-Net: Progressive spatio-channel correla- tion network for image manipulation detection and localization. IEEE Transactions on Circuits and Systems for Video Technology32(11), 7505–7517 (2022)
2022
-
[27]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[28]
Organizational Cybersecurity Journal: Practice, Process and People (ahead- of-print) (2024)
Lyu,S.:Deepfakethemenace:mitigatingthenegativeimpactsofAI-generatedcon- tent. Organizational Cybersecurity Journal: Practice, Process and People (ahead- of-print) (2024)
2024
-
[29]
In: International Conference on Learning Representations (ICLR) (2023)
Ma, X., Zhou, C., Kong, X., He, J., Gui, L., Neubig, G., May, J., Zettlemoyer, L.: Mega: Moving average equipped gated attention. In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[30]
In: European Conference on Computer Vision
Nag, S., Zhu, X., Song, Y.Z., Xiang, T.: Proposal-free temporal action detection via global segmentation mask learning. In: European Conference on Computer Vision. pp. 645–662. Springer (2022)
2022
-
[31]
arXiv preprint arXiv:2101.08540 (2021) MG-RWKV 17
Nawhal, M., Mori, G.: Activity graph transformer for temporal action localization. arXiv preprint arXiv:2101.08540 (2021) MG-RWKV 17
-
[32]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Ni, J., Lyu, K., Guo, Y., Yuan, C.: Semantic alignment and hard sample retraining for visible-infrared person re-identification. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ni, J., Zhang, Q., Jiang, D., Lv, K., Zhang, K., Yuan, C.: FCL-COD: Weakly super- vised camouflaged object detection with frequency-aware and contrastive learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7439–7449 (2026)
2026
-
[34]
In: 2021 Inter- national Joint Conference on Neural Networks (IJCNN)
Niizumi, D., Takeuchi, D., Ohishi, Y., Harada, N., Kashino, K.: BYOL for audio: Self-supervised learning for general-purpose audio representation. In: 2021 Inter- national Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2021)
2021
-
[35]
IEEE Access11, 143296–143323 (2023)
Patel, Y., Tanwar, S., Gupta, R., Bhattacharya, P., Davidson, I.E., Nyameko, R., Aluvala, S., Vimal, V.: Deepfake generation and detection: Case study and chal- lenges. IEEE Access11, 143296–143323 (2023)
2023
-
[36]
arXiv preprint arXiv:2503.14456 (2025)
Peng, B., Zhang, R., Goldstein, D., Alcaide, E., Du, X., Hou, H., Lin, J., Liu, J., Lu, J., Merrill, W., et al.: RWKV-7 “goose” with expressive dynamic state evolution. arXiv preprint arXiv:2503.14456 (2025)
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, D., Zhong, Y., Cao, Q., Ma, L., Li, J., Tao, D.: TriDet: Temporal action detection with relative boundary modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18857–18866 (2023)
2023
-
[38]
In: 2023 international conference on computer and applications (ICCA)
Shoaib, M.R., Wang, Z., Ahvanooey, M.T., Zhao, J.: Deepfakes, misinformation, and disinformation in the era of frontier AI, generative AI, and large AI models. In: 2023 international conference on computer and applications (ICCA). pp. 1–7. IEEE (2023)
2023
-
[39]
The Visual Computer39(3), 813–833 (2023)
Tyagi, S., Yadav, D.: A detailed analysis of image and video forgery detection techniques. The Visual Computer39(3), 813–833 (2023)
2023
-
[40]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., Qiao, Y.: Videomae v2: Scaling video masked autoencoders with dual masking. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14549–14560 (2023)
2023
-
[41]
In: European conference on computer vision
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Van Gool, L.: Tem- poral segment networks: Towards good practices for deep action recognition. In: European conference on computer vision. pp. 20–36. Springer (2016)
2016
-
[42]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B.Z., Khabsa, M., Fang, H., Ma, H.: Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[43]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, Y., Ni, J., Liu, Y., Yuan, C., Tang, Y.: IterPrime: Zero-shot referring image segmentation with iterative Grad-CAM refinement and primary word emphasis. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 8159–8168 (2025)
2025
-
[44]
In: 2025 IEEE International Conference on Image Processing (ICIP)
Xia, R., Jiang, D., Zhang, Q., Zhang, K., Yuan, C.: CLIP-AE: CLIP-assisted cross- view audio-visual enhancement for unsupervised temporal action localization. In: 2025 IEEE International Conference on Image Processing (ICIP). pp. 2014–2018. IEEE (2025)
2025
-
[45]
In: Proceedings of the IEEE international conference on computer vision
Xu, H., Das, A., Saenko, K.: R-C3D: Region convolutional 3D network for tem- poral activity detection. In: Proceedings of the IEEE international conference on computer vision. pp. 5783–5792 (2017)
2017
-
[46]
YouTube-VOS: A Large-Scale Video Object Segmentation Benchmark
Xu, N., Yang, L., Fan, Y., Yue, D., Liang, Y., Yang, J., Huang, T.: YouTube- VOS: A large-scale video object segmentation benchmark. arXiv preprint arXiv:1809.03327 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
Yan, S., Ni, J., Zheng, L., Zhang, J., Wu, P., Yin, D., Lyu, J., Yuan, C., Rao, F.: Adamem: Adaptive user-centric memory for long-horizon dialogue agents. arXiv preprint arXiv:2603.16496 (2026) 18 J. Ni, C. Yu et al
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yan, S., Zheng, L., Lv, K., Ni, J., Wei, H., Zhang, J., Wang, G., Lyu, J., Yuan, C., Rao, F.: Learning cross-view object correspondence via cycle-consistent mask prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6653–6663 (2026)
2026
-
[49]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Yan, Z., Zhang, Y., Fan, Y., Wu, B.: UCF: Uncovering common features for gener- alizable deepfake detection. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 22412–22423 (2023)
2023
-
[50]
arXiv preprint arXiv:2405.00711 (2024)
Yu, X., Wang, Y., Chen, Y., Tao, Z., Xi, D., Song, S., Niu, S., Li, Z.: Fake artificial intelligence generated contents (FAIGC): A survey of theories, detection methods, and opportunities. arXiv preprint arXiv:2405.00711 (2024)
-
[51]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
Zen, H., Dang, V., Clark, R., Zhang, Y., Weiss, R.J., Jia, Y., Chen, Z., Wu, Y.: LibriTTS: A corpus derived from LibriSpeech for text-to-speech. arXiv preprint arXiv:1904.02882 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[52]
In: 2022 26th International Conference on Pattern Recognition (ICPR)
Zhang, B., Sim, T.: Localizing fake segments in speech. In: 2022 26th International Conference on Pattern Recognition (ICPR). pp. 3224–3230. IEEE (2022)
2022
-
[53]
In: European Conference on Computer Vision
Zhang, C.L., Wu, J., Li, Y.: ActionFormer: Localizing moments of actions with transformers. In: European Conference on Computer Vision. pp. 492–510. Springer (2022)
2022
-
[54]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Zhang, Q., Fang, J., Qi, Y., Wan, M., Ma, G., Zhang, K., Yuan, C.: EAV-Mamba: Efficient audio-visual representation learning for weakly-supervised temporal ac- tion localization. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang,Q.,Fang,J.,Yuan,R.,Tang,X.,Qi,Y.,Zhang,K.,Yuan,C.:Weaklysuper- vised temporal action localization via dual-prior collaborative learning guided by multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24139–24148 (2025)
2025
-
[56]
In: The Thirteenth International Conference on Learning Representations (2025)
Zhang, Q., Qi, Y., Tang, X., Fang, J., Lin, X., Zhang, K., Yuan, C.: IMDPrompter: Adapting SAM to image manipulation detection by cross-view automated prompt learning. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[57]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, Q., Qi, Y., Tang, X., Yuan, R., Lin, X., Zhang, K., Yuan, C.: Rethinking pseudo-label guided learning for weakly supervised temporal action localization from the perspective of noise correction. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10085–10093 (2025)
2025
-
[58]
In: Proceedings of the 31st ACM International Conference on Multimedia
Zhang, R., Wang, H., Du, M., Liu, H., Zhou, Y., Zeng, Q.: UMMAFormer: A universal multimodal-adaptive transformer framework for temporal forgery local- ization. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 8749–8759 (2023)
2023
-
[59]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Zhang, Y., Miao, C., Luo, M., Li, J., Deng, W., Yao, W., Li, Z., Hu, B., Feng, W., Gong, T., et al.: MFMS: Learning modality-fused and modality-specific features for deepfake detection and localization tasks. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11365–11369 (2024) MG-RWKV 19 Supplementary Materials This supplementary...
-
[60]
83.65 88.66 85.67 68.38 87.59 88.86 90.75 90.97 [1,2] 85.02 90.5187.5968.31 89.07 89.98 90.86 91.85 [1,2,4] 85.91 91.2287.4471.31 89.5090.17 91.7792.24 [1,2,4,8] 85.10 90.27 87.35 68.38 88.9790.37 91.8192.00 Top-K K= 1 84.43 90.47 86.96 66.42 88.10 89.72 90.88 91.60 K= 2 85.91 91.2287.4471.31 89.5090.17 91.77 92.24 K= 3 85.66 90.8987.9770.75 89.4890.47 91...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.