Arbor: Explicit Geometric Conditioning for Controllable 3D Asset Generation
Pith reviewed 2026-06-26 08:46 UTC · model grok-4.3
The pith
Arbor adds explicit geometric control to text-to-3D models by routing constraint mesh tokens into a frozen denoiser.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
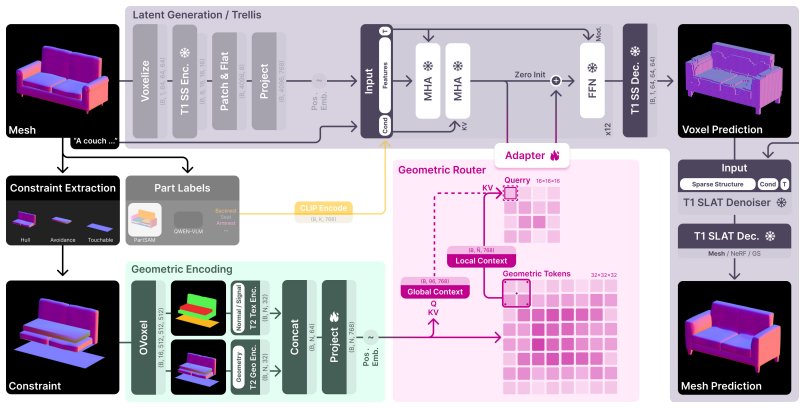
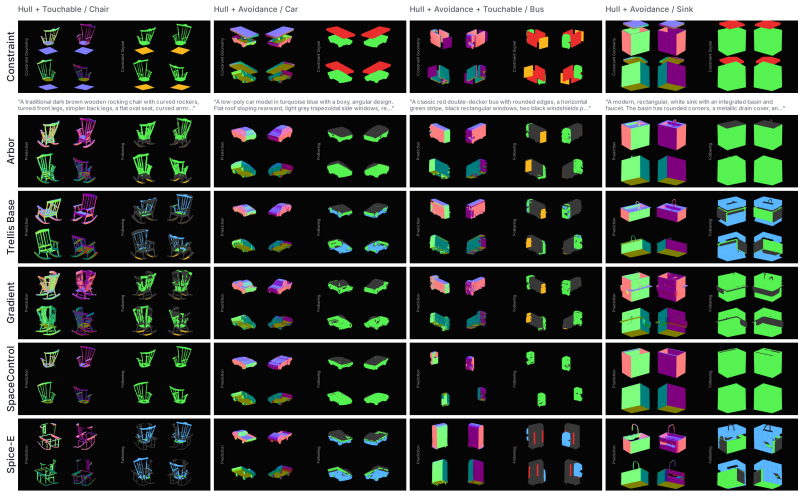
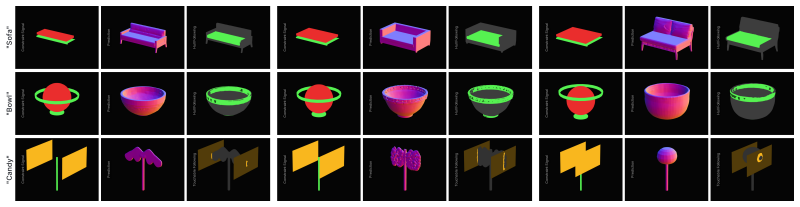
Arbor is a trainable attachment for text conditioned latent 3D generation that treats constraint meshes as a native 3D control interface. The interface supplies hull regions where geometry should exist, avoidance regions that should remain empty, and touch regions the object should contact. Constraint meshes are converted into tokens and integrated via a routed attachment inside a frozen denoiser so each latent region receives only the constraint portion that applies to its spatial location. Even without dedicated compliance losses, this improves constraint obedience while preserving object quality and variation under fixed constraints.
What carries the argument
The routed attachment that converts constraint meshes into tokens and injects them locally into the frozen denoiser.
If this is right
- Text-to-3D models can respect explicit spatial requirements such as fitting inside envelopes or leaving clearance for motion.
- Output variation remains high even when the same constraint meshes are applied.
- Constraint obedience rises on both automatic and artist-curated benchmarks for hull, avoidance, and touch constraints.
- Metric gains align with human preference ratings for the controlled outputs.
Where Pith is reading between the lines
- The same token-routing attachment could be tested on other latent generative backbones such as video or image models.
- Artists could iterate on 3D assets by successively adding or editing constraint meshes without restarting generation.
- The approach might reduce reliance on post-processing or manual cleanup in production asset pipelines.
Load-bearing premise
Constraint meshes can be converted into tokens and integrated via a routed attachment inside a frozen denoiser to locally influence generation without degrading base model performance or requiring additional compliance signals.
What would settle it
On the automatic and artist-curated control benchmarks, constraint obedience metrics show no improvement when the routed attachment is added compared with the unmodified base denoiser.
Figures





read the original abstract
Text and image conditioned 3D models now generate convincing assets, but they still offer little direct control over the space an object should occupy or avoid. In authoring, this spatial intent is often known before generation starts. A chair should fit a seating envelope, a prop should leave clearance for motion, or a part should expose a contact surface. Prompts and image views are poor carriers for such constraints, requiring the need for an explicit control interface. We present Arbor, a trainable attachment for text conditioned latent 3D generation. Arbor introduces constraint meshes as a native 3D control interface. The interface uses hull regions where geometry should exist, avoidance regions that should remain empty, and touch regions the object should contact. Unlike completion or whole object scaffold control, these meshes are not target evidence. They are local typed requirements and can include regions where no surface should appear. Arbor keeps this signal as geometry by converting constraint meshes into tokens and learning a routed attachment inside a frozen denoiser. Each latent region can therefore receive the part of the constraint that matters for its spatial location. We evaluate Arbor on automatic and artist curated control benchmarks with hull, avoidance, and touch constraints, and compare the metric trends to a user preference study. Even without dedicated compliance losses, Arbor improves constraint obedience while preserving object quality and variation under fixed constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Arbor, a trainable attachment for text-conditioned latent 3D generation. Arbor converts constraint meshes (hull regions where geometry should exist, avoidance regions that should remain empty, and touch regions the object should contact) into tokens and integrates them via a routed attachment inside a frozen denoiser, allowing each latent region to receive the relevant part of the constraint. The central claim is that, even without dedicated compliance losses, this yields improved constraint obedience on hull/avoidance/touch benchmarks while preserving object quality and variation, with supporting evidence from automatic/artist-curated benchmarks and a user preference study.
Significance. If the experimental claims hold, the work would supply a practical, geometry-native control interface that addresses a clear limitation in current 3D generative models, where prompts and images are poor carriers of spatial intent. The additive, frozen-denoiser design is a notable strength if it demonstrably avoids the need for compliance losses while maintaining base-model performance.
major comments (1)
- [Abstract] Abstract and provided manuscript text: the central claim of improved constraint obedience rests on metric trends from automatic and artist-curated benchmarks plus a user study, yet the text supplies no method equations, tokenization procedure, routing architecture, benchmark definitions, quantitative tables, error bars, or ablation results. Without these, the support for the claim that the routed attachment produces measurable gains cannot be verified.
Simulated Author's Rebuttal
We thank the referee for their review. The concern raised is that the abstract and provided text lack supporting technical details and results. The full manuscript contains dedicated sections addressing these elements; we address the point below and note that no changes to the core claims or experiments are required.
read point-by-point responses
-
Referee: [Abstract] Abstract and provided manuscript text: the central claim of improved constraint obedience rests on metric trends from automatic and artist-curated benchmarks plus a user study, yet the text supplies no method equations, tokenization procedure, routing architecture, benchmark definitions, quantitative tables, error bars, or ablation results. Without these, the support for the claim that the routed attachment produces measurable gains cannot be verified.
Authors: The full manuscript (beyond the abstract) includes: (1) Section 3 with the tokenization procedure for constraint meshes, the routed attachment architecture, and all relevant equations for the conditioning mechanism inside the frozen denoiser; (2) Section 4 with explicit definitions of the hull, avoidance, and touch benchmarks (both automatic and artist-curated); (3) Section 5 with quantitative tables reporting metric trends, error bars from multiple runs, and the user preference study results; and (4) Section 5.3 with ablation studies isolating the contribution of the routed attachment. These sections directly support the central claim. The abstract is intentionally concise and summarizes rather than reproduces the full technical content. We can add explicit section references to the abstract in a revision if the referee finds that helpful for navigation. revision: partial
Circularity Check
No circularity: method is an additive trainable attachment evaluated on external benchmarks
full rationale
The paper presents Arbor as a new trainable routed attachment that converts constraint meshes to tokens and integrates them locally inside a frozen denoiser. The central claim of improved constraint obedience is supported by evaluation on automatic and artist-curated benchmarks with hull/avoidance/touch constraints, plus a user preference study. No equations, predictions, or first-principles results are shown that reduce by construction to fitted parameters or self-citations; the approach is additive and externally benchmarked rather than self-referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A text-conditioned latent 3D denoiser can remain frozen while a trainable routed attachment processes constraint tokens.
invented entities (1)
-
constraint meshes (hull, avoidance, touch regions)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amir Barda, Matheus Gadelha, Vladimir G. Kim, Noam Aigerman, Amit H. Bermano, and Thibault Groueix. Instant3dit: Multiview inpainting for fast editing of 3D objects. InConference on Computer Vision and Pattern Recognition (CVPR), pages 16273–16282, 2025. URL https: //arxiv.org/abs/2412.00518
arXiv 2025
-
[2]
SF3D: Stable fast 3D mesh reconstruction with UV-unwrapping and illumination disentanglement
Mark Boss, Zixuan Huang, Aaryaman Vasishta, and Varun Jampani. SF3D: Stable fast 3D mesh reconstruction with UV-unwrapping and illumination disentanglement. InConference on Computer Vision and Pattern Recognition (CVPR), pages 16240–16250, 2025. URL https: //arxiv.org/abs/2408.00653
arXiv 2025
-
[3]
DiffComplete: Diffusion-based generative 3D shape completion
Ruihang Chu, Enze Xie, Shentong Mo, Zhenguo Li, Matthias Nießner, Chi-Wing Fu, and Jiaya Jia. DiffComplete: Diffusion-based generative 3D shape completion. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/ 2306.16329
arXiv 2023
-
[4]
Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik
Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F. Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik. ABO: Dataset and benchmarks for real-world 3D object understanding. InConference on Computer Vision and Pattern Recognition (CVPR), 2022. URL https: //arxiv.org/...
arXiv 2022
-
[5]
Objaverse-XL: A universe of 10M+ 3D objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-XL: A universe of 10M+ 3D objects. InAdvances in Neural Information Processi...
Pith/arXiv arXiv 2023
-
[6]
V*: Guided visual search as a core mechanism in multimodal llms
Jan-Niklas Dihlmann, Andreas Engelhardt, and Hendrik Lensch. SIGNeRF: Scene integrated generation for neural radiance fields. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. doi: 10.1109/CVPR52733.2024.00638. URL https://doi.org/10.1109/ CVPR52733.2024.00638
-
[7]
Jan-Niklas Dihlmann, Mark Boss, Simon Donne, Andreas Engelhardt, Hendrik P. A. Lensch, and Varun Jampani. ReLi3D: Relightable multi-view 3D reconstruction with disentangled illumination. InInternational Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=BlSKgQb3Vd
2026
-
[8]
2d gaussian splatting for geometrically accurate radiance fields,
Wenqi Dong, Bangbang Yang, Lin Ma, Xiao Liu, Liyuan Cui, Hujun Bao, Yuewen Ma, and Zhaopeng Cui. Coin3D: Controllable and interactive 3D assets generation with proxy- guided conditioning. InACM SIGGRAPH, 2024. doi: 10.1145/3641519.3657425. URL https://doi.org/10.1145/3641519.3657425
-
[9]
SpaceControl: Introducing test-time spatial control to 3D generative modeling
Elisabetta Fedele, Francis Engelmann, Ian Huang, Or Litany, Marc Pollefeys, and Leonidas Guibas. SpaceControl: Introducing test-time spatial control to 3D generative modeling. InInternational Conference on Learning Representations (ICLR), 2026. URL https: //openreview.net/forum?id=mEqsCVI5sN
2026
-
[10]
ObjFiller-3D: Consistent multi-view 3D inpainting via video diffusion models.arXiv preprint, 2025
Haitang Feng, Jie Liu, Jie Tang, Gangshan Wu, Beiqi Chen, Jianhuang Lai, and Guangcong Wang. ObjFiller-3D: Consistent multi-view 3D inpainting via video diffusion models.arXiv preprint, 2025. URLhttps://arxiv.org/abs/2508.18271
Pith/arXiv arXiv 2025
-
[11]
OpenLRM: Open-source large reconstruction models
Zexin He and Tengfei Wang. OpenLRM: Open-source large reconstruction models. https:// github.com/3DTopia/OpenLRM, 2023. URL https://github.com/3DTopia/OpenLRM. GitHub repository; open-source implementation of LRM, not a primary paper. 10
2023
-
[12]
Amir Hertz, Or Perel, Raja Giryes, Olga Sorkine-Hornung, and Daniel Cohen-Or. SPAGHETTI. ACM Transactions on Graphics (TOG), 2022. doi: 10.1145/3528223.3530084. URL https: //doi.org/10.1145/3528223.3530084
-
[13]
LRM: Large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. InInternational Conference on Learning Representations (ICLR), 2024. URL https: //openreview.net/forum?id=sllU8vvsFF
2024
-
[14]
Easy3E: Feed-forward 3D asset editing via rectified voxel flow.arXiv preprint, 2026
Shimin Hu, Yuanyi Wei, Fei Zha, Yudong Guo, and Juyong Zhang. Easy3E: Feed-forward 3D asset editing via rectified voxel flow.arXiv preprint, 2026. URL https://arxiv.org/abs/ 2602.21499. CVPR 2026
arXiv 2026
-
[15]
SPAR3D: Stable point-aware reconstruction of 3D objects from single images
Zixuan Huang, Mark Boss, Aaryaman Vasishta, James Matthew Rehg, and Varun Jampani. SPAR3D: Stable point-aware reconstruction of 3D objects from single images. InConference on Computer Vision and Pattern Recognition (CVPR), pages 16860–16870, 2025. URL https: //arxiv.org/abs/2501.04689
arXiv 2025
-
[16]
Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, and Ben Poole. Zero-shot text-guided object generation with dream fields. InConference on Computer Vision and Pattern Recognition (CVPR), pages 857–866, 2022. doi: 10.1109/CVPR52688.2022.00094. URL https://doi.org/10.1109/CVPR52688.2022.00094
-
[17]
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Schacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X. Chang, and Manolis Savva. Habitat synthetic scenes dataset (HSSD-200): An analysis of 3D scene scale and realism tradeoffs for ObjectGoal navigation. InIEEE International Conference on Robotics and Automation (ICRA), 2024. ...
arXiv 2024
-
[18]
SALAD: Part-level latent diffusion for 3D shape generation and manipulation
Juil Koo, Seungwoo Yoo, Minh Hieu Nguyen, and Minhyuk Sung. SALAD: Part-level latent diffusion for 3D shape generation and manipulation. InInternational Conference on Computer Vision (ICCV), 2023. URLhttps://arxiv.org/abs/2303.12236
arXiv 2023
-
[19]
BoxSplitGen: A generative model for 3D part bounding boxes in varying granularity
Juil Koo, Wei-Tung Lin, Chanho Park, Chanhyeok Park, and Minhyuk Sung. BoxSplitGen: A generative model for 3D part bounding boxes in varying granularity. InWinter Conference on Applications of Computer Vision (WACV), pages 1777–1787, 2026. URL https://arxiv. org/abs/2602.20666
arXiv 2026
-
[20]
Lightlab: Controlling light sources in images with diffusion models
Mingi Lee, Dongsu Zhang, Clément Jambon, and Young Min Kim. BrepDiff: Single-stage b-rep diffusion model. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, SIGGRAPH Conference Papers ’25, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400715402. doi: 10.1145/3...
-
[21]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3D: High-resolution text-to-3D content creation. InConference on Computer Vision and Pattern Recognition (CVPR), pages 300–309, 2023. doi: 10.1109/CVPR52729.2023.00037. URL https://doi.org/10.1109/ CVPR52729.2023.00037
-
[22]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2I-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InAAAI Conference on Artificial Intelligence (AAAI), pages 4296–4304, 2024. doi: 10.1609/AAAI.V38I5.28226. URLhttps://doi.org/10.1609/AAAI.V38I5.28226
-
[23]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patric...
2024
-
[24]
Barron, and Ben Mildenhall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3D using 2D diffusion. InInternational Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=FjNys5c7VyY. 11
2023
-
[25]
Spice·e: Structural priors in 3D diffusion using cross-entity attention
Etai Sella, Gal Fiebelman, Noam Atia, and Hadar Averbuch-Elor. Spice·e: Structural priors in 3D diffusion using cross-entity attention. InACM SIGGRAPH, pages 1–11, 2024. URL https://arxiv.org/abs/2311.17834
arXiv 2024
-
[26]
Stefan Stojanov, Anh Thai, and James M. Rehg. Using shape to categorize: Low-shot learning with an iterative categorization-discrimination loop. InConference on Computer Vision and Pattern Recognition (CVPR), 2021. URLhttps://arxiv.org/abs/2104.07371
arXiv 2021
-
[27]
DreamCraft3D: Hierarchical 3D generation with bootstrapped diffusion prior
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. DreamCraft3D: Hierarchical 3D generation with bootstrapped diffusion prior. InInternational Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/ forum?id=DDX1u29Gqr
2024
-
[28]
DreamGaussian: Generative gaussian splatting for efficient 3D content creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. DreamGaussian: Generative gaussian splatting for efficient 3D content creation. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/forum?id=UyNXMqnN3c
2024
-
[29]
Hunyuan3D-omni: A unified framework for controllable generation of 3D assets.arXiv preprint, 2025
Team Hunyuan3D. Hunyuan3D-omni: A unified framework for controllable generation of 3D assets.arXiv preprint, 2025. URLhttps://arxiv.org/abs/2509.21245
arXiv 2025
-
[30]
TripoSR: Fast 3D object reconstruction from a single image.arXiv preprint, 2024
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. TripoSR: Fast 3D object reconstruction from a single image.arXiv preprint, 2024. URL https://arxiv.org/abs/ 2403.02151
Pith/arXiv arXiv 2024
-
[31]
SK-adapter: Skeleton-based structural control for native 3D generation.arXiv preprint, 2026
Anbang Wang, Yuzhuo Ao, Shangzhe Wu, and Chi-Keung Tang. SK-adapter: Skeleton-based structural control for native 3D generation.arXiv preprint, 2026. URL https://arxiv.org/ abs/2603.14152
arXiv 2026
-
[32]
Zhenwei Wang, Tengfei Wang, Zexin He, Gerhard Hancke, Ziwei Liu, and Rynson W. H. Lau. Phidias: A generative model for creating 3D content from text, image, and 3D conditions with reference-augmented diffusion. InInternational Conference on Learning Representations (ICLR), 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ 50ca96a1a9ebe0b5...
2025
-
[33]
Direct3D: Scalable image-to-3D generation via 3D latent diffusion transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3D: Scalable image-to-3D generation via 3D latent diffusion transformer. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 121859–121881, 2024. doi: 10.52202/079017-3873. URL https://proceedings.neurips.cc/paper_files/paper/20...
-
[34]
Points-to-3D: Structure- aware 3D generation with point cloud priors
Jiatong Xia, Zicheng Duan, Anton van den Hengel, and Lingqiao Liu. Points-to-3D: Structure- aware 3D generation with point cloud priors. InConference on Computer Vision and Pattern Recognition (CVPR), 2026. URLhttps://jiatongxia.github.io/points2-3D/
2026
-
[35]
Native and compact structured latents for 3D generation.arXiv preprint, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Native and compact structured latents for 3D generation.arXiv preprint, 2025. URL https://arxiv.org/abs/ 2512.14692
Pith/arXiv arXiv 2025
-
[36]
Structured 3D latents for scalable and versatile 3D generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3D latents for scalable and versatile 3D generation. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 21469–21480, 2025. URLhttps://arxiv.org/abs/2412.01506
Pith/arXiv arXiv 2025
-
[37]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantMesh: Efficient 3D mesh generation from a single image with sparse-view large recon- struction models.arXiv preprint, 2024. URLhttps://arxiv.org/abs/2404.07191
Pith/arXiv arXiv 2024
-
[38]
Lambourne, Pradeep Kumar Jayaraman, Zhengqing Wang, Karl D.D
Xiang Xu, Joseph G. Lambourne, Pradeep Kumar Jayaraman, Zhengqing Wang, Karl D.D. Willis, and Yasutaka Furukawa. BrepGen: A b-rep generative diffusion model with structured latent geometry.ACM Transactions on Graphics (TOG), 43(4):1–14, 2024. doi: 10.1145/ 3658129. URLhttps://brepgen.github.io/
2024
-
[39]
Yunhan Yang, Yufan Zhou, Yuan-Chen Guo, Zi-Xin Zou, Yukun Huang, Ying-Tian Liu, Hao Xu, Ding Liang, Yan-Pei Cao, and Xihui Liu. OmniPart: Part-aware 3D generation with semantic decoupling and structural cohesion.arXiv preprint, 2025. URL https://arxiv.org/abs/ 2507.06165. SIGGRAPH Asia 2025. 12
arXiv 2025
-
[40]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint, 2023. URL https:// arxiv.org/abs/2308.06721
Pith/arXiv arXiv 2023
-
[41]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InInternational Conference on Computer Vision (ICCV), 2023. URL https://arxiv.org/abs/2302.05543
Pith/arXiv arXiv 2023
-
[42]
Assembler: Scalable 3D part assembly via anchor point diffusion.arXiv preprint, 2025
Wang Zhao, Yan-Pei Cao, Jiale Xu, Yuejiang Dong, and Ying Shan. Assembler: Scalable 3D part assembly via anchor point diffusion.arXiv preprint, 2025. URL https://arxiv.org/ abs/2506.17074. SIGGRAPH Asia 2025
arXiv 2025
-
[43]
Hunyuan3D 2.0: Scaling diffusion models for high resolution textured 3D assets generation.arXiv preprint, 2025
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, Huiwen Shi, Sicong Liu, Junta Wu, Yihang Lian, Fan Yang, Ruining Tang, Zebin He, Xinzhou Wang, Jian Liu, Xuhui Zuo, Zhuo Chen, Biwen Lei, Haohan Weng, Jing Xu, Yiling Zhu, Xinhai Liu, Lixin Xu, Changrong Hu, Shaoxiong Yang, So...
2025
-
[44]
Zhe Zhu, Le Wan, Rui Xu, Yiheng Zhang, Honghua Chen, Zhiyang Dou, Cheng Lin, Yuan Liu, and Mingqiang Wei. PartSAM: A scalable promptable part segmentation model trained on native 3D data.arXiv preprint, 2026. URL https://arxiv.org/abs/2509.21965. ICLR 2026. 13 A Supplementary Material This supplement adds the details that support the experimental claims b...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.