Where LLM Annotators Fail: Label-Free Learning on Graphs with LLMs
Pith reviewed 2026-06-29 14:23 UTC · model grok-4.3
The pith
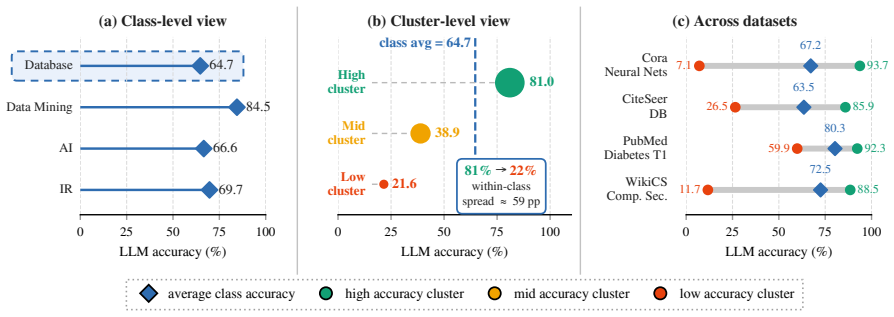
LLM labels on graphs show reliability that varies by feature-space cluster as well as class.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
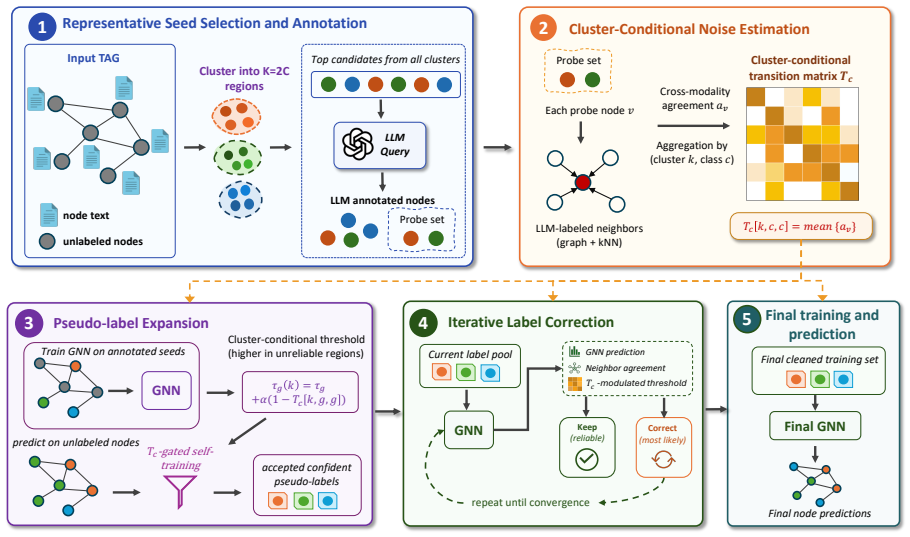
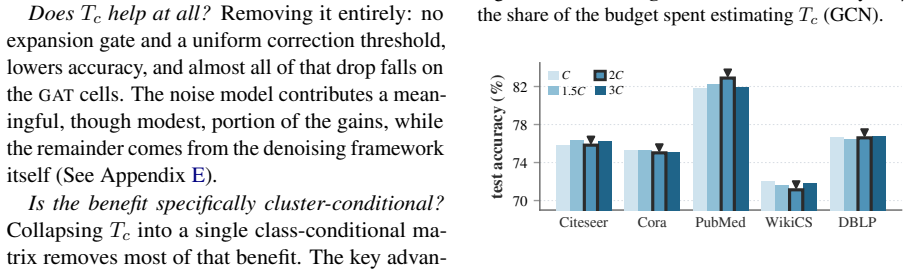
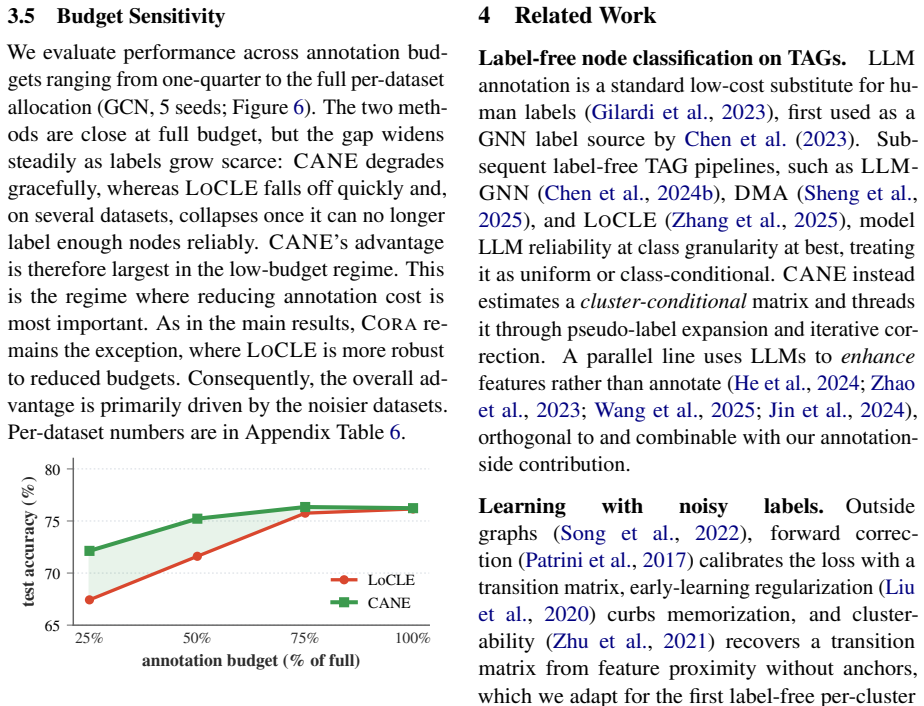
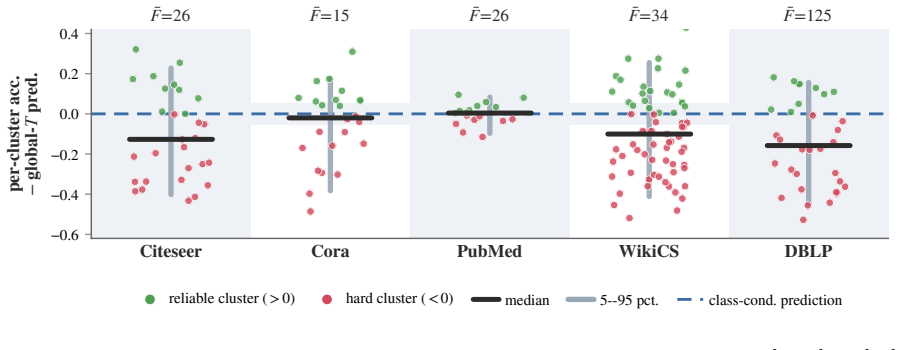
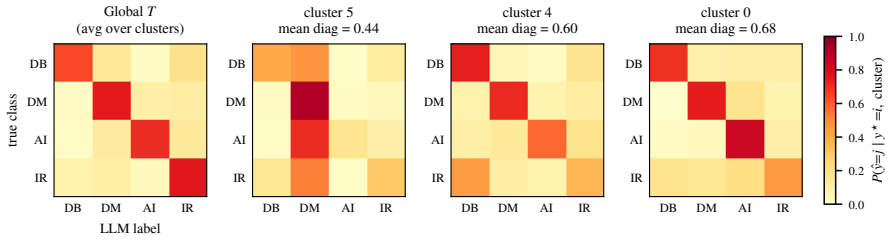
LLM annotation errors are both class-dependent and region-dependent. CANE estimates cluster-conditional LLM reliability without ground truth labels and uses this to decide which pseudo-labels to trust and which to correct.
What carries the argument
Cluster-Aware Noise Estimation (CANE) that partitions nodes into feature-space clusters and estimates per-cluster noise rates from the data distribution alone.
If this is right
- Improved accuracy in node classification using noisy LLM labels on graphs.
- Greater gains on datasets where LLM reliability varies across clusters within classes.
- Applicability across different GNN architectures as a label-free framework.
Where Pith is reading between the lines
- This suggests that cluster detection could be a general tool for handling heterogeneous annotation quality in semi-supervised learning.
- Future work could test whether the same cluster structure appears in other modalities like text or images with LLM labels.
Load-bearing premise
The clusters found in feature space correspond to distinct regions of LLM labeling reliability, making it possible to estimate noise rates without any true labels.
What would settle it
Observing no performance gain from CANE on a graph dataset where LLM errors are uniform across clusters within each class would falsify the utility of the cluster-conditional approach.
Figures

read the original abstract
Node classification on graphs often requires labeled nodes, yet obtaining labels at graph scale is expensive. When node attributes contain semantic content, such as paper abstracts, web pages, or product descriptions, large language models (LLMs) can provide low-cost supervision by annotating a small subset of nodes. However, these LLM-generated labels are noisy, and existing label-free graph learning methods usually treat this noise as either global or class-conditional. We find that LLM annotation errors are not only class-dependent but also region-dependent: within the same class, reliability can vary sharply across feature-space clusters. In light of this, we propose Cluster-Aware Noise Estimation (CANE), a label-free learning framework that estimates cluster-conditional LLM reliability without ground truth labels, and uses this estimate to decide which pseudo-labels to trust, and which labels to correct. Across various graph benchmarks and GNN backbones, CANE improves over the strongest label-free baselines, with the largest gains on datasets exhibiting stronger cluster-conditional noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that LLM-generated pseudo-labels for node classification on graphs exhibit noise that is both class-dependent and region-dependent within the same class, as revealed by feature-space clusters. It proposes Cluster-Aware Noise Estimation (CANE), a label-free framework that estimates per-cluster LLM reliability parameters without ground-truth labels and leverages these to selectively trust or correct pseudo-labels before training GNNs. Experiments across graph benchmarks and backbones show gains over prior label-free methods, largest where cluster-conditional noise is pronounced.
Significance. If the cluster-conditional estimation is valid, CANE offers a practical way to improve label-free graph learning when semantic node attributes allow LLM annotation. The empirical results on datasets with stronger region-dependent noise patterns provide concrete evidence of utility and highlight an under-explored structure in LLM supervision errors. The work supplies reproducible experimental comparisons that can serve as a baseline for future label-efficient graph methods.
major comments (1)
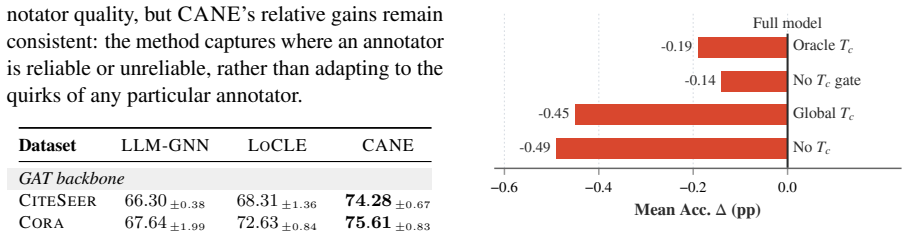
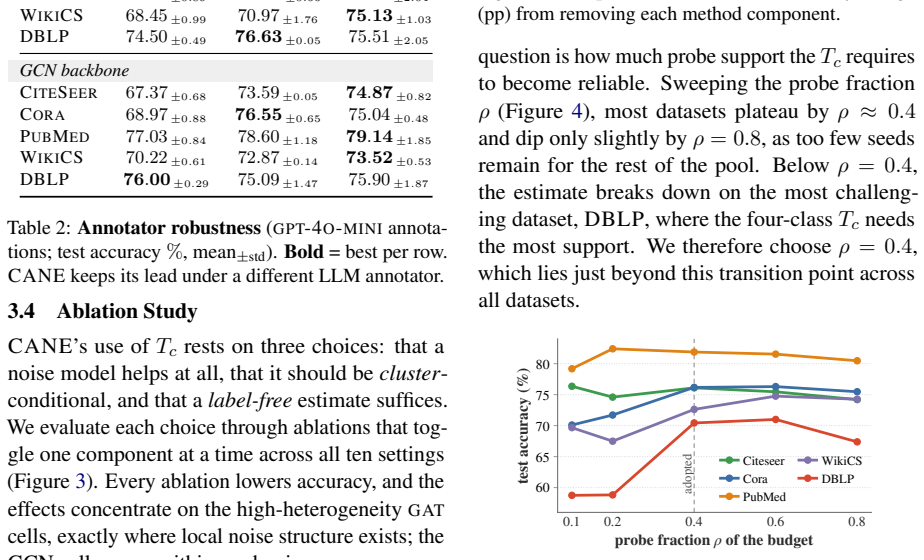
- [§3] §3 (CANE estimation procedure): the central claim that cluster-conditional noise rates are recoverable from the observed distribution of LLM pseudo-labels alone is not accompanied by an identifiability argument or set of sufficient conditions (e.g., on class priors per cluster, conditional independence, or within-cluster label consistency). Without such analysis the recovered reliability parameters used for trust/correction decisions rest on an unverified assumption, directly affecting the validity of the subsequent learning pipeline.
minor comments (2)
- [Abstract, §4] The abstract and §4 could more explicitly state the clustering algorithm, number of clusters chosen, and any hyper-parameters controlling the noise estimation step so that the method is fully reproducible from the text.
- [Figure 2] Figure 2 (or equivalent visualization of cluster-conditional error rates) would benefit from error bars or multiple random seeds to convey variability in the estimated reliabilities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the identifiability of the CANE procedure. We respond to the major comment below.
read point-by-point responses
-
Referee: [§3] §3 (CANE estimation procedure): the central claim that cluster-conditional noise rates are recoverable from the observed distribution of LLM pseudo-labels alone is not accompanied by an identifiability argument or set of sufficient conditions (e.g., on class priors per cluster, conditional independence, or within-cluster label consistency). Without such analysis the recovered reliability parameters used for trust/correction decisions rest on an unverified assumption, directly affecting the validity of the subsequent learning pipeline.
Authors: We agree that §3 presents the CANE estimation procedure without an explicit identifiability analysis. The method models the observed pseudo-label distribution within each cluster as arising from a mixture of true-class distributions corrupted by cluster-specific noise rates, and recovers the parameters by maximum-likelihood estimation (via an EM-style procedure) under the modeling assumptions that (i) clusters are homogeneous with respect to LLM annotation behavior and (ii) the feature-space clustering induces regions where class-conditional label distributions are sufficiently distinct. While the empirical results across benchmarks provide supporting evidence, the referee is correct that sufficient conditions (such as variation in class priors across clusters or conditional independence of pseudo-labels given cluster and true class) are not formally stated. We will revise the manuscript to add a dedicated paragraph in §3 that articulates these assumptions and the conditions under which the cluster-conditional noise rates are identifiable from the observed label distribution alone. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The provided abstract and description present CANE as a new label-free framework that estimates cluster-conditional noise rates from the observed distribution of LLM pseudo-labels and feature clusters, then applies those estimates to trust/correct decisions. No equations, self-citations, or definitional steps are visible that would reduce the estimation to a tautology or fitted input renamed as prediction. The identifiability concern raised by the skeptic is a question of modeling assumptions rather than a demonstrated reduction of the claimed result to its own inputs by construction. The derivation is therefore treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Hongyun Cai, Vincent W Zheng, and Kevin Chen-Chuan Chang. 2017. Active learning for graph embedding. arXiv preprint arXiv:1705.05085
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. 2024 a . Llaga: Large language and graph assistant. In International Conference on Machine Learning (ICML)
2024
- [5]
-
[6]
Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. 2024 b . https://arxiv.org/abs/2310.04668 Label-free node classification on graphs with large language models ( LLMs ) . In International Conference on Learning Representations (ICLR)
-
[7]
De Cheng, Tongliang Liu, Yixiong Ning, Nannan Wang, Bo Han, Gang Niu, Xinbo Gao, and Masashi Sugiyama. 2022. Instance-dependent label-noise learning with manifold-regularized transition matrix estimation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2022
-
[8]
Eli Chien, Wei-Cheng Chang, Cho-Jui Hsieh, Hsiang-Fu Yu, Jiong Zhang, Olgica Milenkovic, and Inderjit S. Dhillon. 2022. Node feature extraction by self-supervised multi-scale neighborhood prediction. In International Conference on Learning Representations (ICLR)
2022
-
[9]
Bosheng Ding, Chengwei Qin, Linlin Liu, Yew Ken Chia, Boyang Li, Shafiq Joty, and Lidong Bing. 2023. Is gpt-3 a good data annotator? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
2023
-
[10]
Fabrizio Gilardi, Meysam Alizadeh, and Ma \"e l Kubli. 2023. ChatGPT outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences (PNAS), 120(30):e2305016120
2023
-
[11]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. 2024. https://arxiv.org/abs/2305.19523 Harnessing explanations: LLM -to- LM interpreter for enhanced text-attributed graph representation learning . In International Conference on Learning Representations (ICLR)
- [12]
-
[13]
Shengding Hu, Zheng Xiong, Meng Qu, Xingdi Yuan, Marc-Alexandre C \^o t \'e , Zhiyuan Liu, and Jian Tang. 2020. Graph policy network for transferable active learning on graphs. In Advances in Neural Information Processing Systems (NeurIPS)
2020
-
[14]
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2024. Large language models on graphs: A comprehensive survey. IEEE Transactions on Knowledge and Data Engineering (TKDE)
2024
-
[15]
Suyeon Kim, SeongKu Kang, Dongwoo Kim, Jungseul Ok, and Hwanjo Yu. 2025. https://arxiv.org/abs/2506.12468 Delving into instance-dependent label noise in graph data: A comprehensive study and benchmark . In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
-
[16]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR)
2017
-
[17]
Ziming Li, Xiaoming Wu, Zehong Wang, Jiazheng Li, Yijun Tian, Jinhe Bi, Yunpu Ma, Yanfang Ye, and Chuxu Zhang. 2026. Graph is a substrate across data modalities. arXiv preprint arXiv:2601.22384
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. 2024. One for all: Towards training one graph model for all classification tasks. In International Conference on Learning Representations (ICLR)
2024
- [19]
- [20]
- [21]
-
[22]
Giorgio Patrini, Alessandro Rozza, Aditya Krishna Menon, Richard Nock, and Lizhen Qu. 2017. https://arxiv.org/abs/1609.03683 Making deep neural networks robust to label noise: A loss correction approach . In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. 2008. Collective classification in network data. AI Magazine, 29(3)
2008
-
[24]
Zeang Sheng, Weiyang Guo, Yingxia Shao, Wentao Zhang, and Bin Cui. 2025. LLMs are noisy oracles! LLM -based noise-aware graph active learning for node classification. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
2025
-
[25]
Hwanjun Song, Minseok Kim, Dongmin Park, Yooju Shin, and Jae-Gil Lee. 2022. Learning from noisy labels with deep neural networks: A survey. IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
2022
-
[26]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
2024
-
[27]
Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. ArnetMiner : Extraction and mining of academic social networks. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)
2008
- [28]
-
[29]
Petar Veli c kovi \'c , Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li \`o , and Yoshua Bengio. 2018. Graph attention networks. In International Conference on Learning Representations (ICLR)
2018
-
[30]
Zehong Wang, Sidney Liu, Zheyuan Zhang, Tianyi Ma, Chuxu Zhang, and Yanfang Ye. 2025. https://arxiv.org/abs/2412.10136 Can LLMs convert graphs to text-attributed graphs? In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
- [31]
-
[32]
Xiaobo Xia, Tongliang Liu, Bo Han, Nannan Wang, Mingming Gong, Haifeng Liu, Gang Niu, Dacheng Tao, and Masashi Sugiyama. 2020. https://arxiv.org/abs/2006.07836 Part-dependent label noise: Towards instance-dependent label noise . In Advances in Neural Information Processing Systems (NeurIPS)
-
[33]
Hao Yan, Chaozhuo Li, Ruosong Long, Chao Yan, Jianan Zhao, Wenwen Zhuang, Jun Yin, Peiyan Zhang, Weihao Han, Hao Sun, and 1 others. 2023. A comprehensive study on text-attributed graphs: Benchmarking and rethinking. Advances in Neural Information Processing Systems, 36:17238--17264
2023
- [34]
-
[35]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2024. Language is all a graph needs. In Findings of the Association for Computational Linguistics: EACL
2024
-
[36]
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V Chawla. 2019. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 793--803
2019
-
[37]
Taiyan Zhang, Renchi Yang, Yurui Lai, Mingyu Yan, Xiaochun Ye, and Dongrui Fan. 2025. Leveraging large language models for effective label-free node classification in text-attributed graphs. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
2025
-
[38]
Wentao Zhang, Yexin Wang, Zhenbang You, Meng Cao, Ping Huang, Jiulong Shan, Zhi Yang, and Bin Cui. 2021. RIM : Reliable influence-based active learning on graphs. In Advances in Neural Information Processing Systems (NeurIPS)
2021
- [39]
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.