Saliency Detection With Fully Convolutional Neural Network
Pith reviewed 2026-05-25 17:50 UTC · model grok-4.3
The pith
A fully convolutional network built from VGG-16 layers marks salient regions in images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a fully convolutional neural network using a portion of VGG-16 can perform saliency detection by reusing the pretrained weights of the classification network.
What carries the argument
The fully convolutional neural network that takes a subset of VGG-16 layers and repurposes them to output a saliency map instead of class scores.
If this is right
- Saliency maps can be generated by adapting existing classification networks rather than building new ones.
- Pretrained weights from image classification improve performance on the saliency task.
- The same reuse strategy could apply to other early-stage image processing steps that follow saliency detection.
- Training time and data requirements for saliency models decrease when starting from VGG-16 weights.
Where Pith is reading between the lines
- The same layer-reuse pattern might extend to related tasks such as edge detection or object proposal generation.
- Performance would likely vary with the choice of which VGG-16 layers are retained versus replaced.
- Real-time applications could benefit if the resulting network runs at interactive speeds on standard hardware.
Load-bearing premise
Reusing layers and weights from a classification network will produce accurate saliency maps without further architectural changes or task-specific validation.
What would settle it
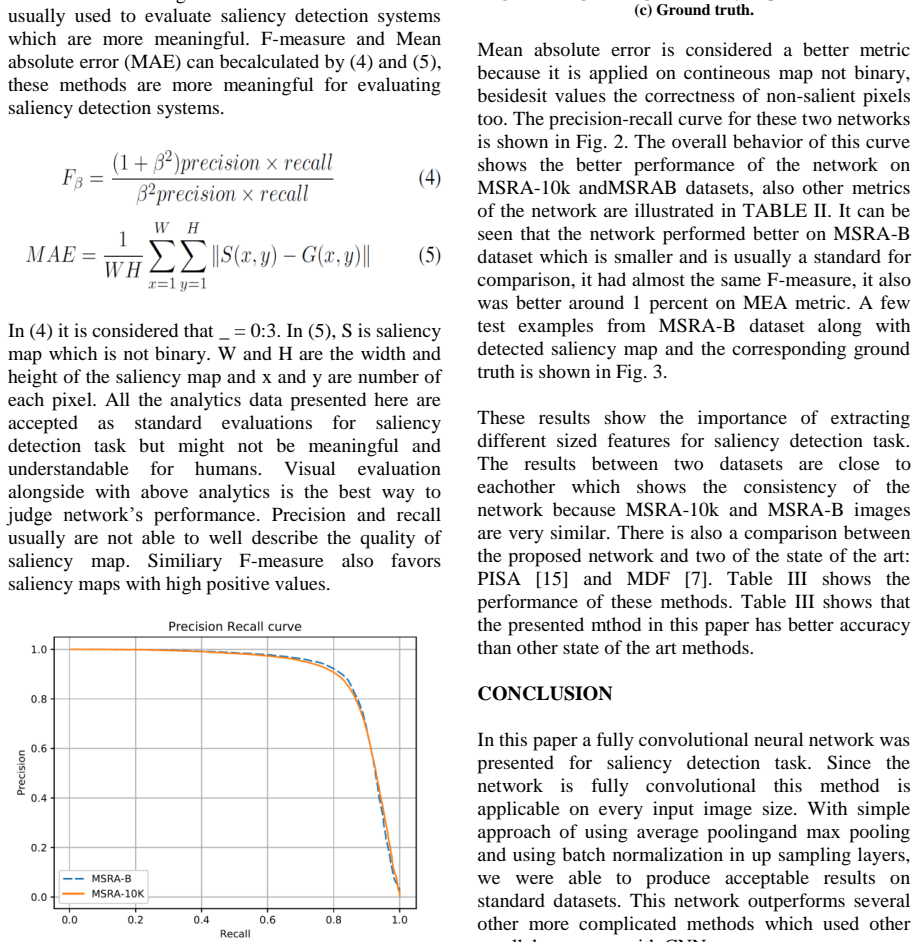
Evaluating the network outputs against human-annotated saliency ground truth on standard image datasets and measuring overlap metrics such as precision-recall or F-measure.
Figures

read the original abstract
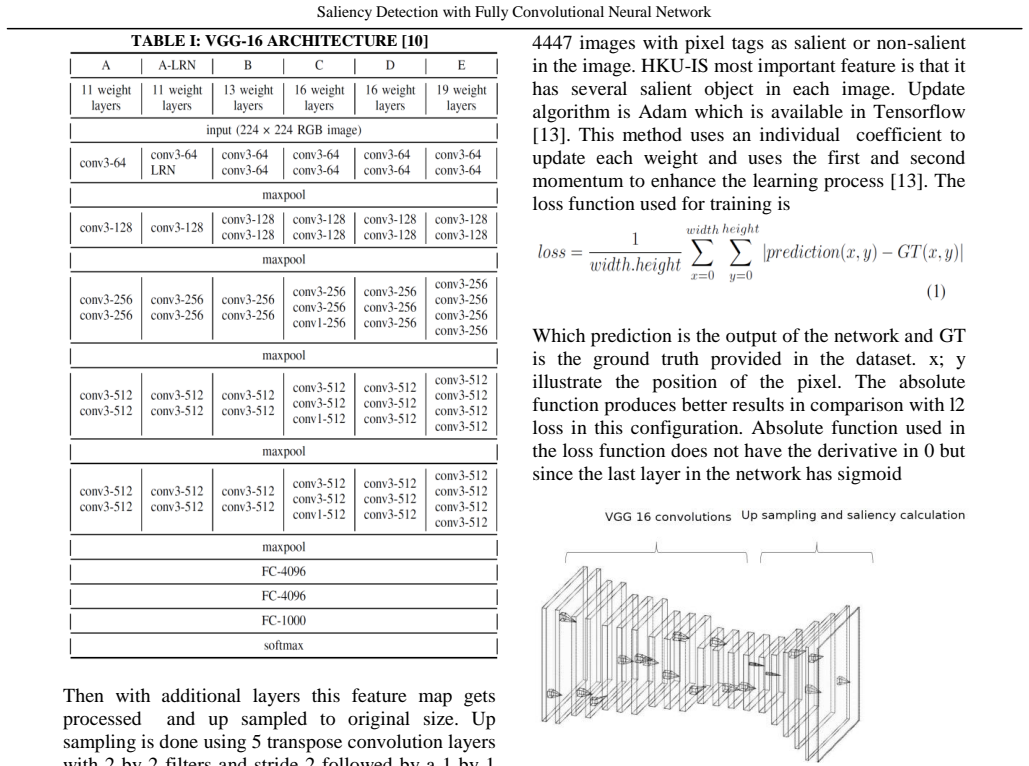
Saliency detection is an important task in image processing as it can solve many problems and it usually is the first step in for other processes. Convolutional neural networks have been proved to be very effective on several image processing tasks such as classification, segmentation, semantic colorization and object manipulation. Besides, using the weights of a pretrained networks is a common practice for enhancing the accuracy of a network. In this paper a fully convolutional neural network which uses a part of VGG-16 is proposed for saliency detection in images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fully convolutional neural network for saliency detection that reuses a portion of the pretrained VGG-16 classification network, motivated by the effectiveness of CNNs and transfer learning for image processing tasks.
Significance. Adapting pretrained classification backbones to saliency detection is a standard technique, but the manuscript supplies neither architectural specifics beyond the VGG-16 reference, nor any training protocol, datasets, baselines, or quantitative results. Consequently, even if the high-level idea holds, the work adds no verifiable contribution or falsifiable prediction.
major comments (1)
- [Abstract] Abstract: the central claim that the proposed network is effective for saliency detection cannot be evaluated because the text contains no architecture diagram, layer specifications, loss function, training details, evaluation metrics, or experimental results on any dataset.
minor comments (1)
- [Abstract] Abstract, line 3: 'first step in for other processes' contains a grammatical error.
Simulated Author's Rebuttal
We thank the referee for the review. We agree that the submitted manuscript is a brief proposal lacking the details needed for evaluation and will revise it substantially.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the proposed network is effective for saliency detection cannot be evaluated because the text contains no architecture diagram, layer specifications, loss function, training details, evaluation metrics, or experimental results on any dataset.
Authors: We agree the manuscript provides only a high-level proposal and contains none of the listed elements. The text proposes the network but does not claim or demonstrate effectiveness with evidence. In revision we will add an architecture diagram, layer-by-layer specifications reusing VGG-16, the loss function, training protocol, chosen datasets, evaluation metrics, and quantitative results against baselines. revision: yes
Circularity Check
No significant circularity; proposal is architectural description only
full rationale
The paper contains no equations, derivations, or load-bearing claims that reduce to self-definition, fitted inputs, or self-citation chains. The central statement is simply that an FCN reusing part of VGG-16 is proposed for saliency detection, with no internal logical steps or predictions that could be circular by construction. The provided abstract and description confirm this is a straightforward network proposal without any mathematical reduction or uniqueness theorem invoked.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Salient region detection and segmentation,
R. Achanta, F. Estrada, P. Wils, and S. S¨usstrunk , “Salient region detection and segmentation,” in International conference on computer vision systems , pp. 66–75, Springer, 2008
work page 2008
-
[2]
Efficient graph - based image segmentation,
P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph - based image segmentation,” International journal of computer vision, vol. 59, no. 2, pp. 167–181, 2004
work page 2004
-
[3]
Mean shift: A robust approach toward feature space analysis,
D. Comaniciu and P. Meer, “Mean shift: A robust approach toward feature space analysis,” IEEE Transactions on pattern analysis and machine intelligence , vol. 24, no. 5, pp. 603 – 619, 2002
work page 2002
-
[4]
A machine learning based intelligent vision system for autonomous object detection and recognition,
D. M. Ram´ık, C. Sabourin, R. Moreno, and K. Madani, “A machine learning based intelligent vision system for autonomous object detection and recognition,” Applied intelligence, vol. 40, no. 2, pp. 358–375, 2014
work page 2014
-
[5]
Deep learning for visual understanding: A review,
Y. Guo, Y. Liu, A. Oerlemans, S. Lao, S. Wu, and M. S. Lew, “Deep learning for visual understanding: A review,” eurocomputing, vol. 187, pp. 27–48, 2016
work page 2016
-
[7]
Visual saliency based on multiscale deep features,
G. Li and Y. Yu, “Visual saliency based on multiscale deep features,” in Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 5455 –5463, 2015
work page 2015
-
[8]
Convolutional neural network for saliency detection in images,
H. Misaghi, R. A. Moghadam, and K. Madani, “Convolutional neural network for saliency detection in images,” in Fuzzy and Intelligent Systems (CFIS), 2018 6th Iranian Joint Congress on, pp. 17–19, IEEE, 2018
work page 2018
-
[9]
Saliency detection by multi -context deep learning,
R. Zhao, W. Ouyang, H. Li, and X. Wang, “Saliency detection by multi -context deep learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1265–1274, 2015
work page 2015
-
[10]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large -scale image recognition,” arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
Global contrast based salient region detection,
M.-M. Cheng, N. J. Mitra, X. Huang, P. H. Torr, and S .-M. Hu, “Global contrast based salient region detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 37, no. 3, pp. 569–582, 2015
work page 2015
-
[12]
Deep contrast learning for salient object detection,
G. Li and Y. Yu, “Deep contrast learning for salient object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pp. 478 –487, 2016
work page 2016
-
[13]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Deeply supervi sed salient object detection with short connections,
Q. Hou, M. -M. Cheng, X. Hu, A. Borji, Z. Tu, and P. Torr, “Deeply supervi sed salient object detection with short connections,” IEEE TPAMI, 2018
work page 2018
-
[15]
K. Wang, L. Lin, J. Lu, C. Li, and K. Shi, “Pisa: Pixelwise image saliency by aggregating complementary appearance contrast measures with edge -preserving coherence,” IEEE Transactions on Image Processing, vol. 24, no. 10, pp. 3019 – 3033, 2015.
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.