Training LLMs with Reinforcement Learning over Digital Twin Representations for Reasoning-Intensive Surgical VideoQA
Pith reviewed 2026-06-27 03:37 UTC · model grok-4.3
The pith
Training LLMs with reinforcement learning over digital twin representations decouples perception from reasoning and improves performance on surgical video question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
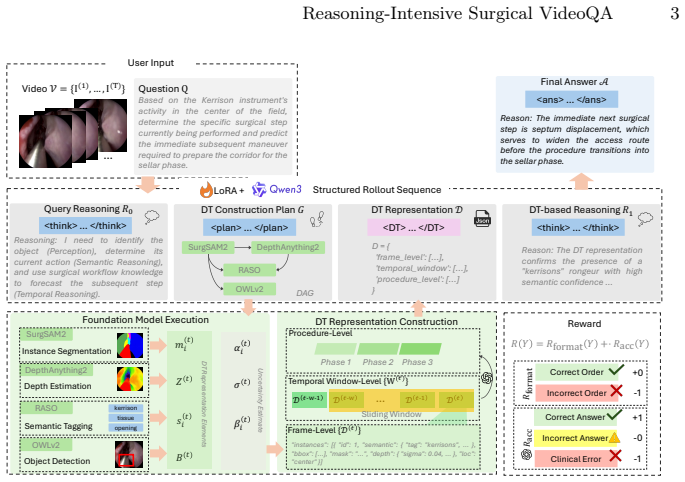
An RL framework trains LLMs to operate over digital twin representations from surgical foundation models, thereby decoupling perception from reasoning; the framework adds hierarchical probabilistic representations across frame, temporal-window, and procedure levels together with a reward that combines format validation, accuracy, clinical plausibility evaluation, and uncertainty-aware calibration, yielding state-of-the-art results on REAL-Colon-Reason and two prior surgical VideoQA benchmarks.
What carries the argument
Reinforcement learning over hierarchical digital twin representations (frame, temporal window, procedure levels) with uncertainty estimates and a reward that merges format validation, clinical plausibility, and uncertainty-aware calibration.
If this is right
- Multi-step reasoning across semantic, spatial, and temporal dimensions becomes feasible without token-level compression artifacts.
- Hierarchical representations with uncertainty estimates allow the model to handle varying levels of procedural complexity.
- The clinical-plausibility component of the reward improves alignment with medical validity beyond simple accuracy.
- State-of-the-art results transfer to existing surgical VideoQA benchmarks without task-specific architectural changes.
- The new REAL-Colon-Reason dataset provides graded evaluation of reasoning depth in colonoscopy videos.
Where Pith is reading between the lines
- The same decoupling strategy could be tested on non-surgical temporal reasoning tasks such as sports video analysis or robotic manipulation sequences.
- Uncertainty estimates produced at each hierarchy level might be used directly for human-in-the-loop clinical review.
- If digital twins already encode the needed geometry, future work could explore whether the perception module itself can be frozen rather than jointly trained.
- The reward design combining plausibility and calibration offers a template for other domains where correctness is not purely factual.
Load-bearing premise
Digital twin representations constructed from surgical foundation models preserve continuous spatial-temporal relationships well enough for LLMs to perform effective decoupled reasoning.
What would settle it
An experiment that measures whether the reported performance gain disappears when the same RL training is applied to video inputs whose spatial-temporal continuity has been deliberately broken while keeping semantic content intact.
Figures
read the original abstract
Surgical video question answering requires multi-step reasoning across semantic, spatial, and temporal dimensions. Existing methods architecturally compress videos into discrete token representations and couple visual perception with reasoning. This approach fragments continuous spatial-temporal relationships and has been shown to restrict multi-step reasoning capabilities. We introduce a reinforcement learning (RL) framework that trains large language models (LLMs) to decouple perception from reasoning by operating over digital twin representations constructed from surgical foundation models. Additionally, we introduce hierarchical representations across frame, temporal window, and procedure levels with probabilistic uncertainty estimates. Finally, we propose a novel reward that combines format validation with accuracy assessment through clinical plausibility evaluation and uncertainty-aware calibration for training. To demonstrate the capabilities of this approach, we introduce REAL-Colon-Reason, a colonoscopic benchmark with 2000 question-answer pairs across three complexity levels. We achieve state-of-the-art performance on REAL-Colon-Reason and two existing surgical VideoQA benchmarks REAL-Colon-VQA and EndoVis18-VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an RL framework to train LLMs for surgical VideoQA by operating over digital twin representations (constructed from surgical foundation models with hierarchical frame/temporal-window/procedure levels and probabilistic uncertainty estimates) to decouple perception from reasoning. It introduces a novel reward combining format validation, accuracy via clinical plausibility, and uncertainty-aware calibration, plus the new REAL-Colon-Reason benchmark with 2000 QA pairs, claiming SOTA results on REAL-Colon-Reason, REAL-Colon-VQA, and EndoVis18-VQA.
Significance. If the central claim holds, the work could advance multi-step reasoning in medical video understanding by mitigating fragmentation of spatial-temporal structure. The new benchmark and uncertainty-aware reward are useful contributions; however, the significance hinges on whether gains are attributable to the digital-twin decoupling rather than reward engineering or benchmark tuning.
major comments (3)
- [Experiments] The manuscript provides no ablation or analysis (e.g., in the Experiments or Results sections) isolating the contribution of digital twin representations from the novel reward function; without this, SOTA claims on the three benchmarks cannot be attributed to decoupling rather than reward design or post-hoc tuning.
- [Method] The core assumption that digital twin representations preserve continuous spatial-temporal relationships (unlike token-based compression) is load-bearing for the decoupling claim but receives no direct validation, such as continuity metrics or comparison against foundation-model token outputs at the scales needed for multi-step reasoning.
- [Results] Dataset construction details, error bars, and statistical tests for the reported SOTA on REAL-Colon-Reason (and the two existing benchmarks) are absent, undermining verification of the performance claims.
minor comments (1)
- [Method] Notation for the hierarchical levels and uncertainty estimates should be formalized with equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment below, providing clarifications and committing to revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Experiments] The manuscript provides no ablation or analysis (e.g., in the Experiments or Results sections) isolating the contribution of digital twin representations from the novel reward function; without this, SOTA claims on the three benchmarks cannot be attributed to decoupling rather than reward design or post-hoc tuning.
Authors: We agree that an ablation study is essential to isolate the effects. The current manuscript focuses on the overall framework performance, but we will add a dedicated ablation section in the revised manuscript comparing the full model against ablated versions (e.g., without hierarchical digital twins, without uncertainty estimates, and using standard rewards) to attribute the contributions appropriately. revision: yes
-
Referee: [Method] The core assumption that digital twin representations preserve continuous spatial-temporal relationships (unlike token-based compression) is load-bearing for the decoupling claim but receives no direct validation, such as continuity metrics or comparison against foundation-model token outputs at the scales needed for multi-step reasoning.
Authors: The assumption is indeed central, and while the design of hierarchical probabilistic representations is intended to address this, we recognize the value of direct validation. In the revision, we will include quantitative comparisons, such as measuring spatial-temporal continuity metrics between digital twin representations and direct token outputs from the foundation models. revision: yes
-
Referee: [Results] Dataset construction details, error bars, and statistical tests for the reported SOTA on REAL-Colon-Reason (and the two existing benchmarks) are absent, undermining verification of the performance claims.
Authors: We acknowledge these omissions in the presentation. The revised manuscript will expand the dataset section with full construction details for REAL-Colon-Reason, include error bars from repeated experiments, and report p-values from appropriate statistical tests to substantiate the SOTA claims. revision: yes
Circularity Check
No derivation chain or self-referential reductions present
full rationale
The abstract and available text describe an empirical RL framework using digital twin representations from foundation models, hierarchical levels, uncertainty estimates, and a composite reward, plus SOTA results on new and existing benchmarks. No equations, derivations, fitted parameters presented as predictions, or self-citations appear. No load-bearing step reduces by construction to its inputs, satisfying the requirement to quote specific reductions before flagging circularity. This matches the most common honest finding for papers without mathematical claims.
Axiom & Free-Parameter Ledger
invented entities (3)
-
digital twin representations
no independent evidence
-
hierarchical representations with probabilistic uncertainty estimates
no independent evidence
-
novel reward combining format validation, accuracy, clinical plausibility, and uncertainty-aware calibration
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Long Bai, Mobarakol Islam, Lalithkumar Seenivasan, and Hongliang Ren. Surgical- vqla: Transformer with gated vision-language embedding for visual question localized-answering in robotic surgery.arXiv preprint arXiv:2305.11692, 2023
arXiv 2023
-
[2]
Shuai Bai et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[3]
Qwen3-vl technical report, 2025
Shuai Bai et al. Qwen3-vl technical report, 2025
2025
-
[4]
Real-colon: A dataset for developing real-world ai applications in colonoscopy.Scientific Data, 11(1):539, 2024
Carlo Biffi et al. Real-colon: A dataset for developing real-world ai applications in colonoscopy.Scientific Data, 11(1):539, 2024
2024
-
[5]
Llm-assisted multi-teacher continual learning for visual question answering in robotic surgery
Kexin Chen et al. Llm-assisted multi-teacher continual learning for visual question answering in robotic surgery. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 10772–10778. IEEE, 2024
2024
-
[6]
Visual question answering in robotic surgery: A comprehensive review.IEEE Access, 2025
Di Ding, Tianliang Yao, Rong Luo, and Xusen Sun. Visual question answering in robotic surgery: A comprehensive review.IEEE Access, 2025
2025
-
[7]
Mauro Orazio Drago et al. Surgvivqa: Temporally-grounded video question an- swering for surgical scene understanding.arXiv preprint arXiv:2511.03325, 2025
Pith/arXiv arXiv 2025
-
[8]
Automated capture of intraoperative adverse events using artificial intelligence: a systematic review and meta-analysis.Journal of Clinical Medicine, 12(4):1687, 2023
Michael B Eppler et al. Automated capture of intraoperative adverse events using artificial intelligence: a systematic review and meta-analysis.Journal of Clinical Medicine, 12(4):1687, 2023
2023
-
[9]
Pitvqa: Image-grounded text embedding llm for visual question answering in pituitary surgery
Runlong He et al. Pitvqa: Image-grounded text embedding llm for visual question answering in pituitary surgery. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 488–498. Springer, 2024
2024
-
[10]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[11]
Shrikant Kendre et al. Smile: A composite lexical-semantic metric for question- answering evaluation.arXiv preprint arXiv:2511.17432, 2025
arXiv 2025
-
[12]
Jiajie Li et al. Recognize any surgical object: Unleashing the power of weakly- supervised data.arXiv preprint arXiv:2501.15326, 2025
arXiv 2025
-
[13]
Lili Liang, Guanglu Sun, Jin Qiu, and Lizhong Zhang. Neural-symbolic videoqa: Learning compositional spatio-temporal reasoning for real-world video question answering.arXiv preprint arXiv:2404.04007, 2024
arXiv 2024
-
[14]
Haofeng Liu et al. Surgical sam 2: Real-time segment anything in surgical video by efficient frame pruning.arXiv preprint arXiv:2408.07931, 2024. 10 Y. Shen et al
arXiv 2024
-
[15]
Haofeng Liu et al. Sam2s: Segment anything in surgical videos via semantic long- term tracking.arXiv preprint arXiv:2511.16618, 2025
arXiv 2025
-
[16]
Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems, 36, 2024
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[17]
Dennis Pierantozzi, Luca Carlini, Mauro Orazio Drago, Chiara Lena, Cesare Has- san, Elena De Momi, Danail Stoyanov, Sophia Bano, and Mobarak I Hoque. When to trust the answer: Question-aligned semantic nearest neighbor entropy for safer surgical vqa.arXiv preprint arXiv:2511.01458, 2025
Pith/arXiv arXiv 2025
-
[18]
Surgicalgpt: end-to-end language-vision gpt for vi- sual question answering in surgery
Lalithkumar Seenivasan et al. Surgicalgpt: end-to-end language-vision gpt for vi- sual question answering in surgery. InInternational conference on medical image computing and computer-assisted intervention, pages 281–290. Springer, 2023
2023
-
[19]
Surgical-vqa: Visual question answering in surgical scenes using transformer
Lalithkumar Seenivasan, Mobarakol Islam, Adithya K Krishna, and Hongliang Ren. Surgical-vqa: Visual question answering in surgical scenes using transformer. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 33–43. Springer, 2022
2022
-
[20]
Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Andrew Sellergren et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[21]
Zhihong Shao et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[22]
Position: Foundation models need digital twin representations.arXiv preprint arXiv:2505.03798, 2025
Yiqing Shen, Hao Ding, Lalithkumar Seenivasan, Tianmin Shu, and Mathias Un- berath. Position: Foundation models need digital twin representations.arXiv preprint arXiv:2505.03798, 2025
arXiv 2025
-
[23]
Reasoning text- to-video retrieval via digital twin video representations and large language models
Yiqing Shen, Chenxiao Fan, Chenjia Li, and Mathias Unberath. Reasoning text- to-video retrieval via digital twin video representations and large language models. arXiv preprint arXiv:2511.12371, 2025
arXiv 2025
-
[24]
Yiqing Shen, Chenjia Li, and Mathias Unberath. Text-driven reasoning video editing via reinforcement learning on digital twin representations.arXiv preprint arXiv:2511.14100, 2025
arXiv 2025
-
[25]
Yiqing Shen, Bohan Liu, Chenjia Li, Lalithkumar Seenivasan, and Mathias Un- berath. Online reasoning video segmentation with just-in-time digital twins.arXiv preprint arXiv:2503.21056, 2025
arXiv 2025
-
[26]
Yiqing Shen and Mathias Unberath. Constructing and interpreting digital twin representations for visual reasoning via reinforcement learning.arXiv preprint arXiv:2511.12365, 2025
arXiv 2025
-
[27]
Explore multi-step rea- soning in video question answering
Xiaomeng Song, Yucheng Shi, Xin Chen, and Yahong Han. Explore multi-step rea- soning in video question answering. InProceedings of the 26th ACM international conference on Multimedia, pages 239–247, 2018
2018
-
[28]
Guankun Wang et al. Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery.arXiv preprint arXiv:2405.10948, 2024
arXiv 2024
-
[29]
Haibo Wang et al. Grounded-videollm: Sharpening fine-grained temporal ground- ing in video large language models.arXiv preprint arXiv:2410.03290, 2024
arXiv 2024
-
[30]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[32]
Depth anything v2.arXiv preprint arXiv:2406.09414, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, et al. Depth anything v2.arXiv preprint arXiv:2406.09414, 2024
Pith/arXiv arXiv 2024
-
[33]
Advancing surgical vqa with scene graph knowledge.International journal of computer assisted radiology and surgery, 19(7):1409–1417, 2024
Kun Yuan et al. Advancing surgical vqa with scene graph knowledge.International journal of computer assisted radiology and surgery, 19(7):1409–1417, 2024. Reasoning-Intensive Surgical VideoQA 11
2024
-
[34]
Cascade multi-level transformer network for surgical workflow analysis.IEEE transactions on medical imaging, 42(10):2817–2831, 2023
Wenxi Yue et al. Cascade multi-level transformer network for surgical workflow analysis.IEEE transactions on medical imaging, 42(10):2817–2831, 2023
2023
-
[35]
Boqiang Zhang et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
Pith/arXiv arXiv 2025
-
[36]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595–46623, 2023
2023
-
[37]
Proreason: Multi-modal proactive reasoning with decoupled eyesight and wisdom
Jingqi Zhou, Sheng Wang, Jingwei Dong, Kai Liu, Lei Li, Jiahui Gao, Jiyue Jiang, Lingpeng Kong, and Chuan Wu. Proreason: Multi-modal proactive reasoning with decoupled eyesight and wisdom. InProceedings of the 2025 Conference on Empir- ical Methods in Natural Language Processing, pages 31650–31679, 2025
2025
-
[38]
Jinguo Zhu et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.