A Neurosymbolic Framework for Interpretable Skeleton-Based Seizure Detection via Concept-Driven Logical Reasoning
Pith reviewed 2026-07-01 07:22 UTC · model grok-4.3
The pith
A neurosymbolic framework detects seizures from video skeletons by composing clinical motor concepts into Boolean rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework extracts patient-centric skeleton sequences from epilepsy monitoring videos via a prompt-guided foundation model, predicts binary spatio-temporal concept activations grounded in clinical motor semiology guidelines, and composes them via differentiable logic into interpretable Boolean rules with auditable contributions, while sub-classifying non-seizure segments into clinically relevant normal activities to reduce false positives.
What carries the argument
Differentiable logic that composes binary concept activations into Boolean rules.
If this is right
- Every prediction breaks down into detected motor primitives, their logical composition, and each rule's contribution to the output.
- Sub-classifying non-seizure segments supplies fine-grained supervision that lowers false detections per hour.
- The three-level interpretability holds for every frame-level decision on the tested benchmarks.
- Public release of annotations, pose sequences, pipeline, and code allows direct reuse or extension of the extracted data.
Where Pith is reading between the lines
- The same concept-to-rule pipeline could be tested on other video tasks that already have published clinical movement guidelines.
- If the extracted skeletons prove stable across camera angles and clothing, the method might transfer to home monitoring without retraining the concept layer.
- Adding temporal duration constraints to the Boolean rules could be checked against seizure-length statistics to see whether specificity rises further.
Load-bearing premise
The prompt-guided foundation model accurately extracts patient-centric skeleton sequences from the videos and the predicted concept activations correctly match clinical motor semiology guidelines.
What would settle it
Independent neurologist review of the same videos showing that the model's concept activations do not align with observed motor primitives would disprove the grounding step.
Figures
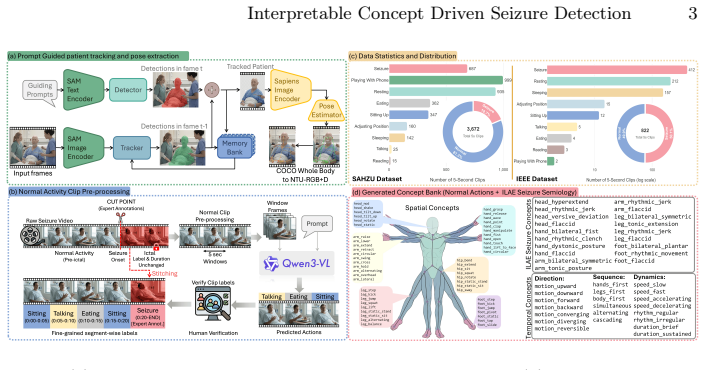
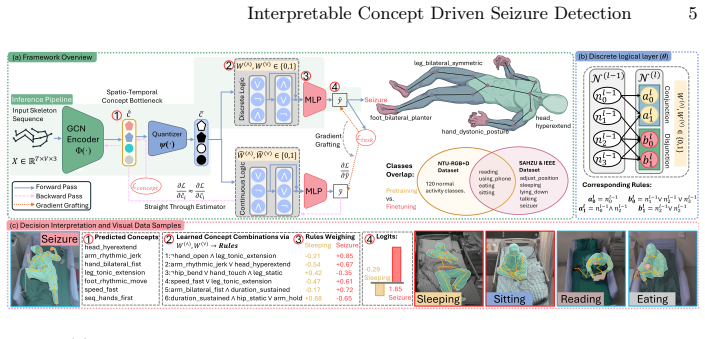

read the original abstract
Video-based seizure detection is essential for the management of epilepsy patients, offering a non-invasive complement to electroencephalography. While several deep learning approaches have been developed for video-based seizure detection, none are inherently interpretable, limiting their adoption and translation into clinical practice. We present, to our knowledge, the first exploration of a neurosymbolic framework for video-based seizure detection that directly addresses this gap. Our approach (1) extracts patient-centric skeleton sequences from epilepsy monitoring units via a prompt-guided foundation model, (2) predicts binary spatio-temporal concept activations grounded in clinical motor semiology guidelines, and (3) composes them via differentiable logic into interpretable Boolean rules with auditable contributions. Furthermore, to mitigate false positives arising from the traditional binary formulation (seizure vs.\ non-seizure), we sub-classify non-seizure segments into clinically relevant normal activities, providing the model with fine-grained discriminative supervision. Evaluated on two public seizure video benchmarks, our framework achieves 89.78% sensitivity with 0.06 false detections per hour on SAHZU and 85.27%,0.09 on IEEE, while producing complete three-level interpretability: every prediction decomposes into which motor primitives were detected, how they were logically composed, and how much each rule contributed to the clinical decision. We publicly release all annotations, extracted pose sequences, our data pipeline and code, https://github.com/Mr-TalhaIlyas/CDSD/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the first neurosymbolic framework for video-based seizure detection. It extracts patient-centric skeleton sequences from epilepsy monitoring videos using a prompt-guided foundation model, predicts binary spatio-temporal concept activations grounded in clinical motor semiology guidelines, composes them via differentiable logic into interpretable Boolean rules with auditable contributions, and sub-classifies non-seizure segments into normal activities for finer supervision. On the SAHZU and IEEE public benchmarks it reports 89.78% sensitivity / 0.06 false detections per hour and 85.27% / 0.09 respectively, together with three-level interpretability (motor primitives, logical composition, rule contributions). All annotations, pose sequences, pipeline and code are released publicly.
Significance. If the central claims hold, the work would be significant as the first neurosymbolic treatment of this clinical task, directly addressing the interpretability barrier that has limited adoption of prior deep-learning video detectors. The public release of annotations, extracted pose sequences, data pipeline and code is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: the reported sensitivity and false-detection rates rest on two unvalidated steps—prompt-guided foundation-model skeleton extraction from EMU videos (subject to motion blur, occlusions, non-standard poses) and binary concept activations asserted to be grounded in motor semiology guidelines—yet no quantitative metrics (pose error vs. manual landmarks, inter-rater agreement on concept labels, or ablation removing the grounding step) are supplied, preventing assessment of whether the data support the performance and interpretability claims.
- [Abstract] Abstract (points 1–2 of the approach): the framework’s three-level interpretability guarantee is only clinically meaningful if the extracted skeletons and concept activations are accurate; without reported validation of these steps the downstream differentiable logic produces auditable but potentially meaningless rules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for validation of the skeleton extraction and concept activation stages. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported sensitivity and false-detection rates rest on two unvalidated steps—prompt-guided foundation-model skeleton extraction from EMU videos (subject to motion blur, occlusions, non-standard poses) and binary concept activations asserted to be grounded in clinical motor semiology guidelines—yet no quantitative metrics (pose error vs. manual landmarks, inter-rater agreement on concept labels, or ablation removing the grounding step) are supplied, preventing assessment of whether the data support the performance and interpretability claims.
Authors: We acknowledge that the manuscript does not report quantitative metrics such as pose estimation error against manual landmarks or inter-rater agreement on the binary concept labels. The skeleton extraction relies on a prompt-guided foundation model, and concept activations follow published clinical motor semiology guidelines, with all annotations and pose sequences released publicly to enable external verification. The reported performance figures are end-to-end results on the detection task. To address the concern, we will add an ablation that replaces the grounded concepts with ungrounded learned activations and quantify the performance difference; we will also add a dedicated limitations paragraph discussing the absence of these intermediate validation metrics. revision: yes
-
Referee: [Abstract] Abstract (points 1–2 of the approach): the framework’s three-level interpretability guarantee is only clinically meaningful if the extracted skeletons and concept activations are accurate; without reported validation of these steps the downstream differentiable logic produces auditable but potentially meaningless rules.
Authors: We agree that the clinical utility of the three-level interpretability (motor primitives, logical composition, rule contributions) presupposes reasonable accuracy in the skeleton and concept stages. The current manuscript demonstrates interpretability via qualitative examples and releases the full annotation and pose data for independent assessment. We will revise the abstract, approach description, and discussion sections to explicitly state this dependency and list it among the limitations. No additional experiments are required for this textual clarification. revision: yes
Circularity Check
No circularity: empirical framework on external benchmarks
full rationale
The paper describes a three-stage pipeline (prompt-guided skeleton extraction, binary concept activation, differentiable logic composition) and reports sensitivity/FDR numbers on two public external datasets (SAHZU, IEEE). No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems are present in the provided text. The central claims rest on empirical results rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Clinical motor semiology guidelines provide reliable binary spatio-temporal concepts for seizure detection
- domain assumption Prompt-guided foundation model accurately extracts patient-centric skeleton sequences from epilepsy monitoring videos
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Epileptic Disorders24(3), 447–495 (2022)
Beniczky, S., Tatum, W.O., Blumenfeld, H., Stefan, H., Mani, J., Maillard, L., Fahoum, F., Vinayan, K.P., Mayor, L.C., Vlachou, M., et al.: Seizure semiology: Ilae glossary of terms and their significance. Epileptic Disorders24(3), 447–495 (2022)
2022
-
[3]
Epilepsia66(6), 1804–1823 (2025)
Beniczky, S., Trinka, E., Wirrell, E., Abdulla, F., Al Baradie, R., Alonso Vanegas, M., Auvin, S., Singh, M.B., Blumenfeld, H., Bogacz Fressola, A., et al.: Updated classification of epileptic seizures: Position paper of the international league against epilepsy. Epilepsia66(6), 1804–1823 (2025)
2025
-
[4]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., Hu, W.: Channel-wise topology refinement graph convolution for skeleton-based action recognition. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13359–13368 (2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chi, H.g., Ha, M.H., Chi, S., Lee, S.W., Huang, Q., Ramani, K.: Infogcn: Repre- sentation learning for human skeleton-based action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20186– 20196 (2022)
2022
-
[7]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Gao, Y., Zhou, H., Gao, Z., Wang, B., Gao, S., Wang, S., Zhuang, X.: Learn- ing concept-driven logical rules for interpretable and generalizable medical im- age classification. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 291–300. Springer (2025)
2025
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Hou, J.C., Thonnat, M., Bartolomei, F., McGonigal, A.: Automated video analysis ofemotionanddystoniainepilepticseizures.EpilepsyResearch184,106953(2022)
2022
-
[10]
Ilyas, T., Mehta, D., Ge, Z.: Neurosymbolic framework for concept-driven logical reasoning in skeleton-based human action recognition. arXiv preprint arXiv:2605.07140 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
In: International Workshop on Ap- plications of Medical AI
Ilyas, T., Mehta, D., Sivathamboo, S., Wijaya, I., Steele, R., Simpson, H., Millist, L., O’Brien, T., Kwan, P., Ge, Z.: Privacy-centric seizure diagnosis via relation- aware fusion of minimally-invasive modalities. In: International Workshop on Ap- plications of Medical AI. pp. 173–183. Springer (2025) 10 T. Ilyas et al
2025
-
[12]
Epilepsy & Behavior41, 197–202 (2014)
Jin, B., Wu, H., Xu, J., Yan, J., Ding, Y., Wang, Z.I., Guo, Y., Wang, Z., Shen, C., Chen, Z., et al.: Analyzing reliability of seizure diagnosis based on semiology. Epilepsy & Behavior41, 197–202 (2014)
2014
-
[13]
In: European Conference on Computer Vision
Jin, S., Xu, L., Xu, J., Wang, C., Liu, W., Qian, C., Ouyang, W., Luo, P.: Whole- body human pose estimation in the wild. In: European Conference on Computer Vision. pp. 196–214. Springer (2020)
2020
-
[14]
Scientific Reports12(1), 19571 (2022)
Karácsony, T., Loesch-Biffar, A.M., Vollmar, C., Rémi, J., Noachtar, S., Cunha, J.P.S.: Novel 3d video action recognition deep learning approach for near real time epileptic seizure classification. Scientific Reports12(1), 19571 (2022)
2022
-
[15]
In: European Conference on Computer Vision
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: European Conference on Computer Vision. pp. 206–228. Springer (2024)
2024
-
[16]
In: International conference on machine learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International conference on machine learning. pp. 5338–5348. PMLR (2020)
2020
-
[17]
Li,Y.L.,Liu,X.,Wu,X.,Li,Y.,Qiu,Z.,Xu,L.,Xu,Y.,Fang,H.S.,Lu,C.:Hake:A knowledgeenginefoundationforhumanactivityunderstanding.IEEETransactions on Pattern Analysis and Machine Intelligence45(7), 8494–8506 (2022)
2022
-
[18]
Liang, J.: Seizure videos of epilepsy patients (2024).https://doi.org/10.21227/ nt6e-3x56,https://dx.doi.org/10.21227/nt6e-3x56
-
[19]
IEEE trans- actions on pattern analysis and machine intelligence42(10), 2684–2701 (2019)
Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L.Y., Kot, A.C.: Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE trans- actions on pattern analysis and machine intelligence42(10), 2684–2701 (2019)
2019
-
[20]
arXiv preprint arXiv:2506.00915 (2025)
Liu, M., Liu, H., Hu, Q., Ren, B., Yuan, J., Lin, J., Wen, J.: 3d skeleton-based action recognition: A review. arXiv preprint arXiv:2506.00915 (2025)
-
[21]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Mehta, D., Sivathamboo, S., Simpson, H., Kwan, P., O’Brien, T., Ge, Z.: Privacy- preserving early detection of epileptic seizures in videos. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 210–219. Springer (2023)
2023
-
[22]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Pérez-García, F., Scott, C., Sparks, R., Diehl, B., Ourselin, S.: Transfer learning of deep spatiotemporal networks to model arbitrarily long videos of seizures. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 334–344. Springer (2021)
2021
-
[23]
In: Australasian Joint Conference on Artificial Intelligence
Ponnambalam, K.G., Ilyas, T., Sivathamboo, S., Ge, Z., Kwan, P., Kuhlmann, L., Mehta, D.: Privacy-centric seizure detection using surface normals, pose and segmentation masks. In: Australasian Joint Conference on Artificial Intelligence. pp. 322–334. Springer (2025)
2025
-
[24]
In: 2024 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC)
Rehman,M.U.,Ilyas,T.,Seneviratne,L.,Hussain,I.:Enhancedgesturerecognition through graph-based multimodal fusion. In: 2024 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC). pp. 1–5. IEEE (2024)
2024
-
[25]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (11 2019),https: //arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
npj Digital Medicine7(1), 42 (2024)
Saab, K., Tang, S., Taha, M., Lee-Messer, C., Re, C., Rubin, D.L.: Towards trust- worthy seizure onset detection using workflow notes. npj Digital Medicine7(1), 42 (2024)
2024
-
[27]
Epilepsy & Behavior126, 108455 (2022) Interpretable Concept Driven Seizure Detection 11
Turek, G., Skjei, K.: Seizure semiology, localization, and the 2017 ilae seizure clas- sification. Epilepsy & Behavior126, 108455 (2022) Interpretable Concept Driven Seizure Detection 11
2017
-
[28]
arXiv preprint arXiv:2512.07383 (2025)
Vemuri, D.S., Bellamkonda, G., Pola, A., Balasubramanian, V.N.: Logiccbms: Logic-enhanced concept-based learning. arXiv preprint arXiv:2512.07383 (2025)
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(2), 1121–1133 (2023)
Wang, Z., Zhang, W., Liu, N., Wang, J.: Learning interpretable rules for scalable data representation and classification. IEEE Transactions on Pattern Analysis and Machine Intelligence46(2), 1121–1133 (2023)
2023
-
[30]
World: Epilepsy (Feb 2024),https://www.who.int/news-room/fact-sheets/ detail/epilepsy
2024
-
[31]
In: European Conference on Computer Vision
Xu, Y., Wang, J., Chen, Y.H., Yang, J., Ming, W., Wang, S., Sawan, M.: Vsvig: Real-time video-based seizure detection via skeleton-based spatiotemporal vig. In: European Conference on Computer Vision. pp. 228–245. Springer (2024)
2024
-
[32]
IEEE Journal of Biomedical and Health Informatics25(8), 2997–3008 (2021)
Yang, Y., Sarkis, R.A., El Atrache, R., Loddenkemper, T., Meisel, C.: Video-based detection of generalized tonic-clonic seizures using deep learning. IEEE Journal of Biomedical and Health Informatics25(8), 2997–3008 (2021)
2021
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Y., Panagopoulou, A., Zhou, S., Jin, D., Callison-Burch, C., Yatskar, M.: Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19187–19197 (2023)
2023
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhou, Y., Xu, T., Wu, C., Wu, X., Kittler, J.: Adaptive hyper-graph convolution network for skeleton-based human action recognition with virtual connections. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12648–12658 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.