Structuring Sparsity: Block-Sparse Featurizers Capture Visual Concept Manifolds
Pith reviewed 2026-06-25 23:52 UTC · model grok-4.3
The pith
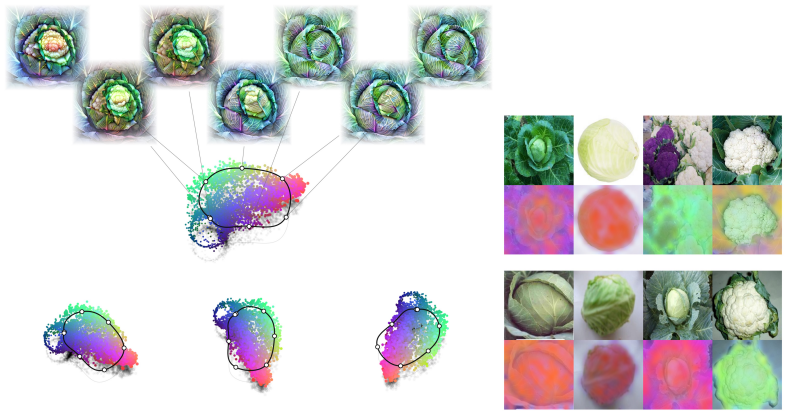
Block-sparse featurizers recover visual concepts as low-dimensional manifolds instead of isolated directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
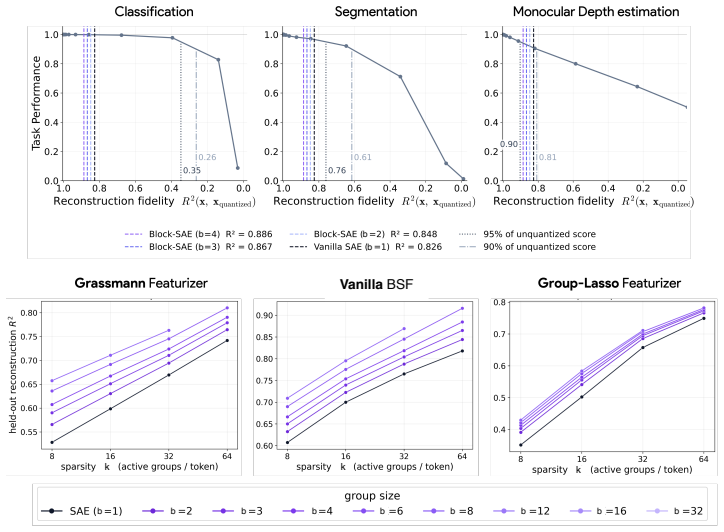
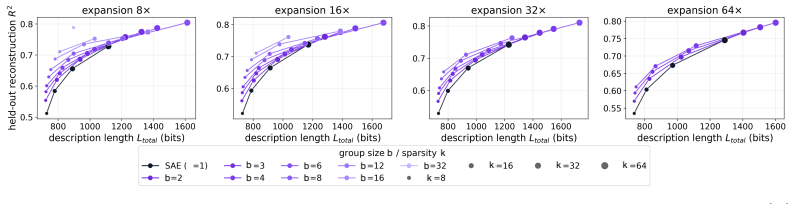
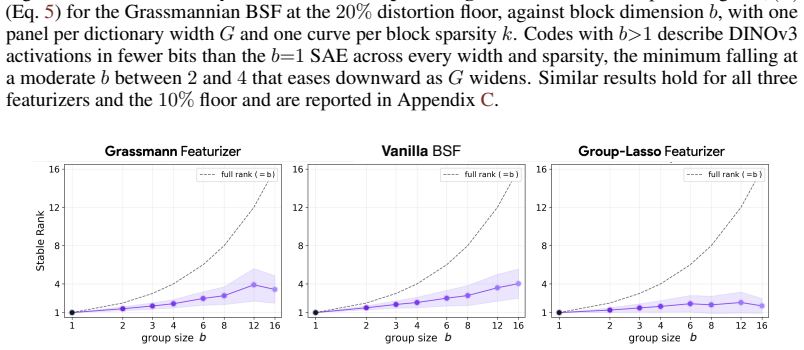
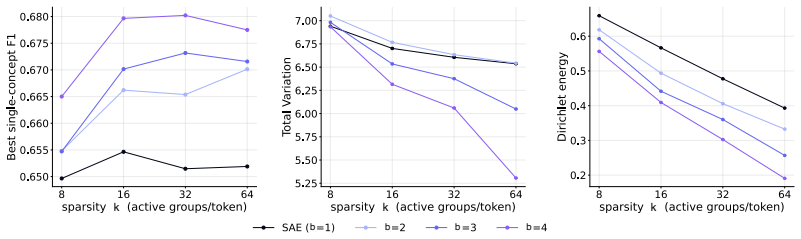
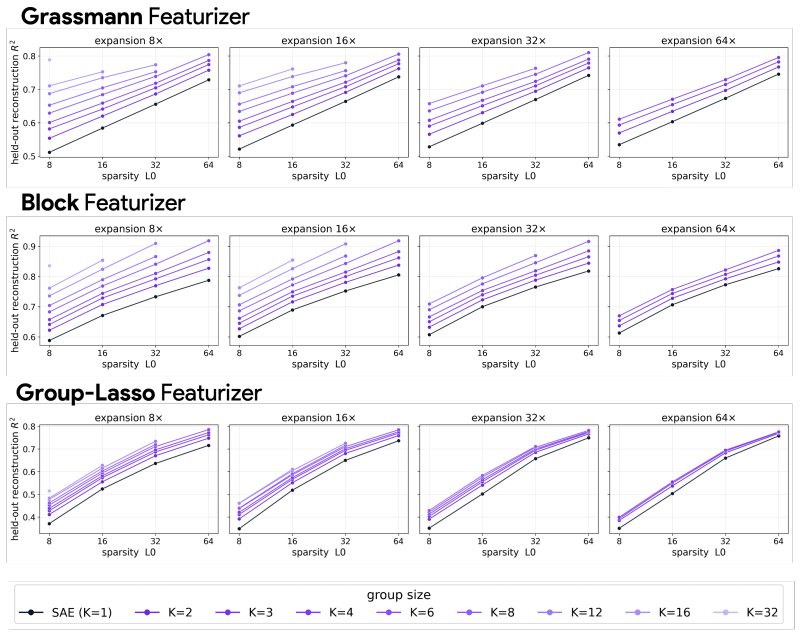
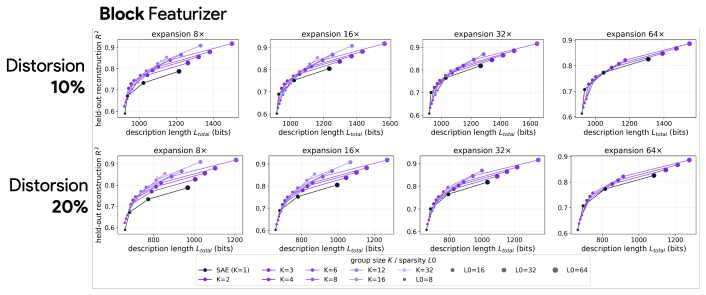
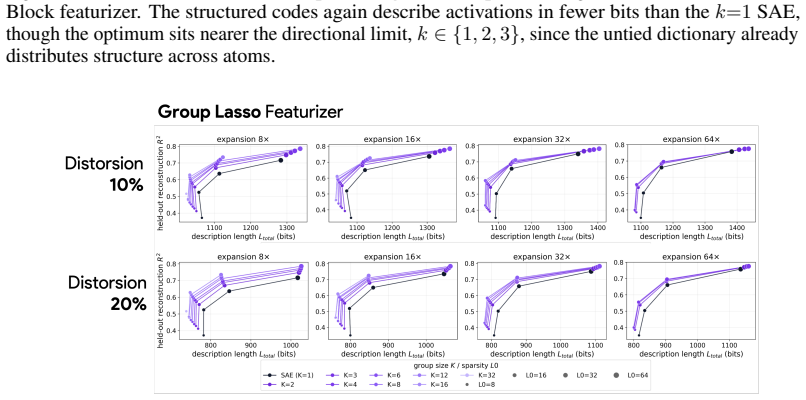
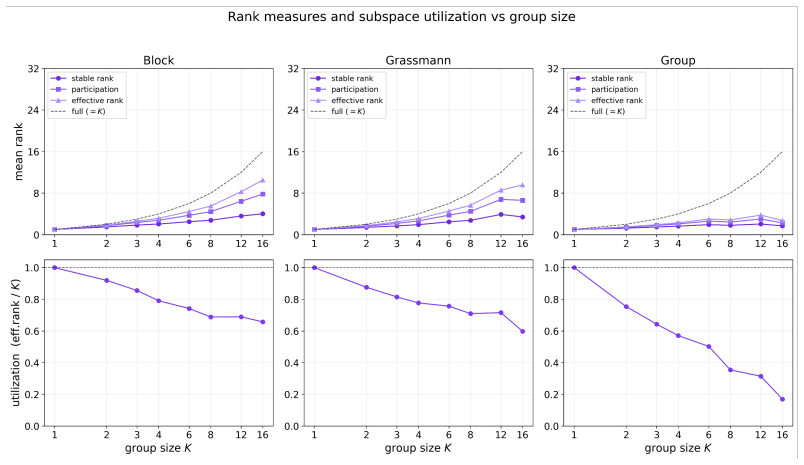
Block sparsity, which groups directions into blocks, is the prior matched to a generative model in which a representation is a sparse sum of low-dimensional manifolds. This is the modern, learned form of a classical idea in visual neuroscience, where a visual feature is carried by a coordinated group of neurons rather than a single tuned one. All three variants of block-sparse featurizers describe activations more compactly than direction-based featurizers, with the recovered concepts typically two- to four-dimensional.
What carries the argument
Block-sparse featurizers that enforce sparsity over blocks of directions to model low-dimensional manifolds in activation space.
If this is right
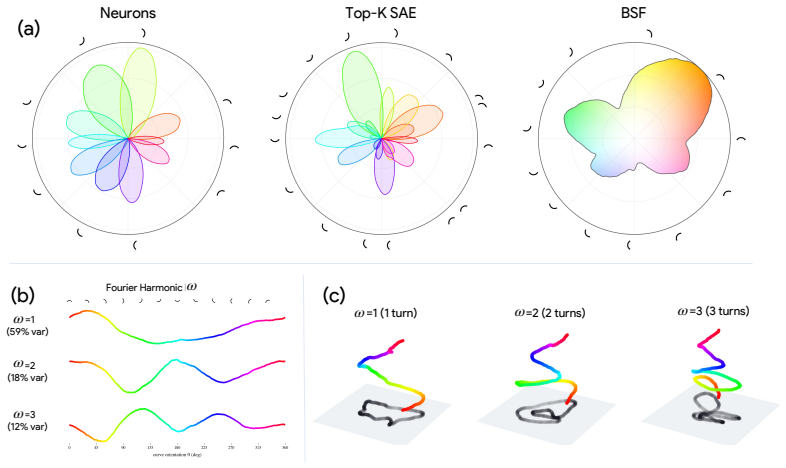
- Prior curve detectors in InceptionV1 are shown to read from a single continuous curve manifold.
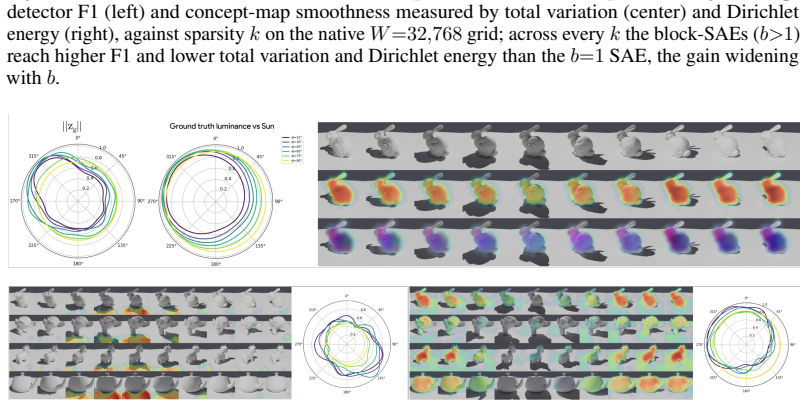
- New manifolds for shadows and lighting are discovered in DINOv3.
- Manifold steering provides interpretable control over image generation in SDXL diffusion models.
Where Pith is reading between the lines
- This suggests that interpretability methods should shift from individual directions to structured groups.
- Similar structured sparsity approaches might improve analysis in non-visual domains.
- Testing other block sizes or sparsity patterns could yield even more efficient descriptions of activations.
Load-bearing premise
The minimum-description-length comparison between block-sparse and direction-based featurizers directly measures which generative model better matches the true structure of the activations.
What would settle it
If direction-based featurizers were found to yield lower minimum description lengths than block-sparse featurizers across the tested models and layers, the superiority of the block-sparse approach would be challenged.
Figures











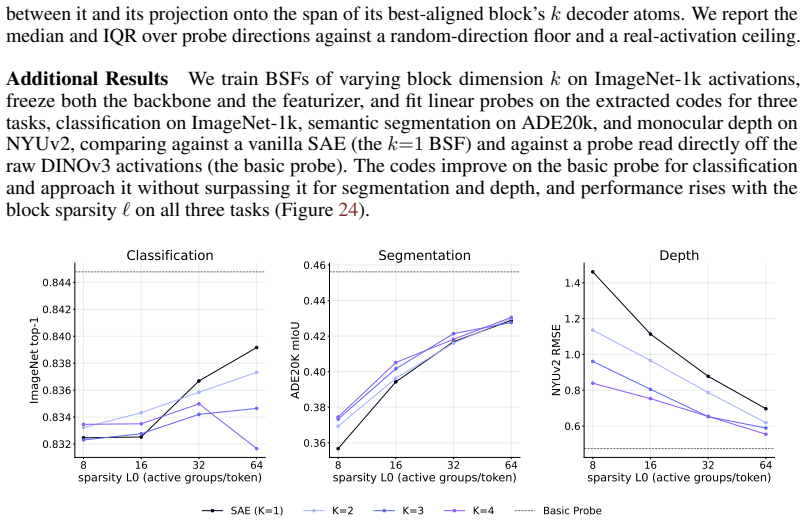
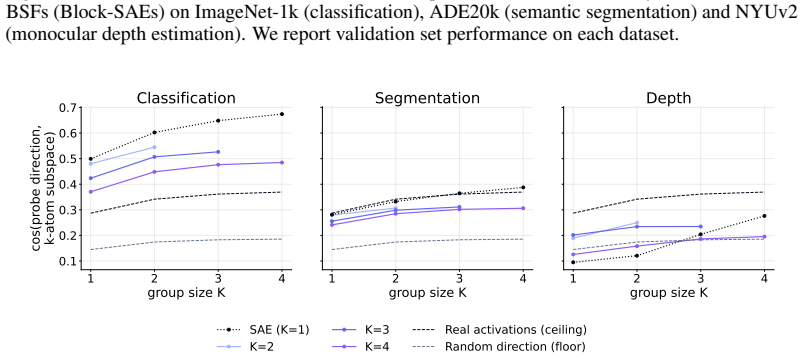
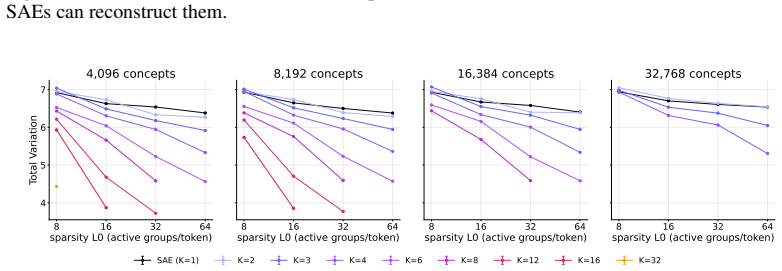
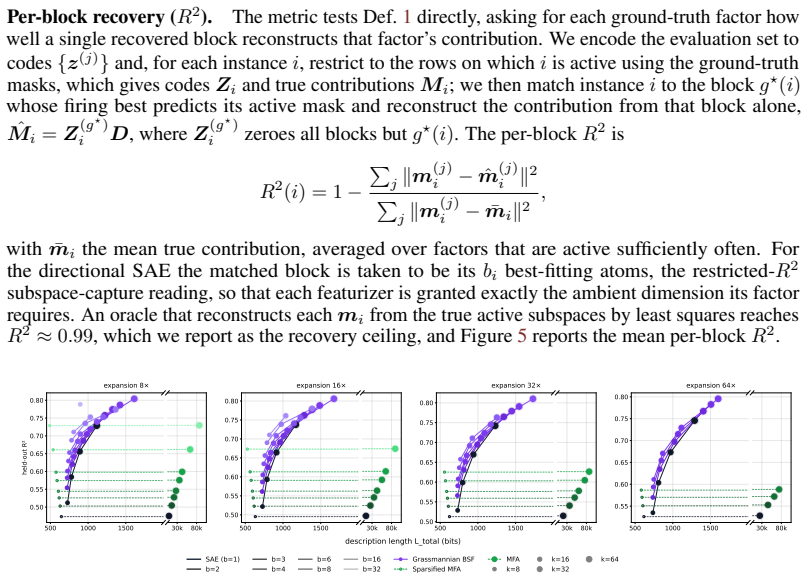
read the original abstract
What is the geometry of a visual percept? The most widely used protocols for decomposing neural network representations into interpretable parts treat concepts as isolated directions, yet recent work shows that concepts are often realized as geometric structures in low dimensional regions of activation space. We turn to the literature of Structured sparsity to close this gap, and show that block sparsity, which groups directions into blocks, is the prior matched to a generative model in which a representation is a sparse sum of low-dimensional manifolds: the modern, learned form of a classical idea in visual neuroscience, where a visual feature is carried by a coordinated group of neurons rather than a single tuned one. We implement three variants of block-sparse featurizers (BSFs) and, through a minimum-description-length analysis, show that all three describe activations more compactly than direction-based featurizers, with the recovered concepts typically two- to four-dimensional. We then use BSFs to (i) recontextualize prior work, showing that curve detectors in InceptionV1 actually read from a single continuous curve manifold, (ii) discover novel manifolds including shadows and lighting in DINOv3, and (iii) support interpretable control of image generation in diffusion models (SDXL) via manifold steering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that block sparsity is the prior matched to a generative model of neural activations as sparse sums of low-dimensional manifolds. It implements three block-sparse featurizer (BSF) variants and shows via minimum-description-length (MDL) analysis that they yield lower description lengths than direction-based featurizers, with recovered blocks typically 2-4 dimensional. Applications include recontextualizing curve detectors in InceptionV1 as reading from a single continuous manifold, discovering novel manifolds (e.g., shadows/lighting) in DINOv3, and enabling manifold-based steering in SDXL diffusion models.
Significance. If the central MDL result holds and the generative-model interpretation is supported, the work would advance interpretability by supplying a structured-sparsity prior aligned with manifold geometry rather than isolated directions, extending classical neuroscience ideas to modern networks. The cross-model applications and control demonstration would be concrete strengths.
major comments (1)
- [MDL analysis] MDL analysis section: the claim that lower description length establishes that block sparsity is 'the prior matched to' the sparse-sum-of-manifolds generative model is not isolated by the reported experiments. The comparison is consistent with BSFs simply capturing local correlations or clustered directions more efficiently; a controlled test on synthetic data generated from each process is needed to distinguish the two stories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: MDL analysis section: the claim that lower description length establishes that block sparsity is 'the prior matched to' the sparse-sum-of-manifolds generative model is not isolated by the reported experiments. The comparison is consistent with BSFs simply capturing local correlations or clustered directions more efficiently; a controlled test on synthetic data generated from each process is needed to distinguish the two stories.
Authors: We agree that the MDL comparison performed on real network activations does not isolate the sparse-sum-of-manifolds generative model from alternative explanations such as efficient capture of local correlations or clustered directions. The manuscript's theoretical section motivates block sparsity from the manifold model, and the recovered blocks are observed to be low-dimensional (typically 2-4D) with applications that align with manifold geometry, but these observations remain correlational. A controlled synthetic experiment comparing description lengths under data generated from each process would strengthen the causal claim. We will add such an experiment to the revised manuscript. revision: yes
Circularity Check
No circularity; central claim rests on independent empirical MDL comparison
full rationale
The paper advances its claim that block sparsity matches a sparse-sum-of-manifolds generative model solely via an empirical minimum-description-length analysis comparing BSF variants to direction-based featurizers on real activations. No equations, fitting procedures, or self-citations are shown that would reduce any prediction or uniqueness result to the inputs by construction. The MDL metric functions as an external benchmark rather than a self-referential definition, and the recovered block dimensionalities (2-4) are reported outcomes rather than fitted inputs renamed as predictions. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concepts are realized as geometric structures in low dimensional regions of activation space rather than isolated directions
Reference graph
Works this paper leans on
-
[1]
and Gillis, N
Abdolali, M. and Gillis, N. Beyond linear subspace clustering: A comparative study of nonlinear manifold clustering algorithms. Computer Science Review, 2021
2021
-
[2]
Sanity checks for saliency maps
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., and Kim, B. Sanity checks for saliency maps. Advances in Neural Information Processing Systems (NIPS), 2018
2018
-
[3]
Adelson, E. H. and Bergen, J. R. Spatiotemporal energy models for the perception of motion. Journal of the Optical Society of America A, 2 0 (2): 0 284--299, 1985. doi:10.1364/JOSAA.2.000284
-
[4]
Ayonrinde, K., Pearce, M. T., and Sharkey, L. Interpretability as compression: Reconsidering sae explanations of neural activations with mdl-saes. arXiv preprint arXiv:2410.11179, 2024
arXiv 2024
-
[5]
Structured sparsity through convex optimization
Bach, F., Jenatton, R., Mairal, J., and Obozinski, G. Structured sparsity through convex optimization. Statistical Science, 2012
2012
-
[6]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., and Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. Public Library of Science (PloS One), 2015
2015
-
[7]
Bao, P., She, L., McGill, M., and Tsao, D. Y. A map of object space in primate inferotemporal cortex. Nature, 583 0 (7814): 0 103--108, 2020. doi:10.1038/s41586-020-2350-5
-
[8]
G., Cevher, V., Duarte, M
Baraniuk, R. G., Cevher, V., Duarte, M. F., and Hegde, C. Model-based compressive sensing. IEEE Transactions on information theory, 2010
2010
-
[9]
Barlow, H. B. et al. Possible principles underlying the transformation of sensory messages. Sensory communication, 1961
1961
-
[10]
and Niyogi, P
Belkin, M. and Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Advances in Neural Information Processing Systems (NeurIPS), 2001
2001
-
[11]
Do sparse autoencoders capture concept manifolds? A r X iv e-print , 2026 a
Bhalla, U., Fel, T., Rager, C., Feucht, S., Haklay, T., Wurgaft, D., Boppana, S., Kowal, M., Shyam, V., Merullo, J., et al. Do sparse autoencoders capture concept manifolds? A r X iv e-print , 2026 a
2026
-
[12]
M., Lakkaraju, H., and Calmon, F
Bhalla, U., Oesterling, A., Verdun, C. M., Lakkaraju, H., and Calmon, F. P. Temporal sparse autoencoders: Leveraging the sequential nature of language for interpretability. 2026 b . URL https://arxiv.org/abs/2511.05541
arXiv 2026
-
[13]
E., Hume, T., Carter, S., Henighan, T., and Olah, C
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., and Olah, C. Towards monosemanticity: Decomposing languag...
2023
-
[14]
Batchtopk sparse autoencoders
Bussmann, B., Leask, P., and Nanda, N. Batchtopk sparse autoencoders. A r X iv e-print , 2024
2024
-
[15]
Cadieu, C. F. and Olshausen, B. A. Learning intermediate-level representations of form and motion from natural movies. Neural Computation, 24 0 (4): 0 827--866, 2012. doi:10.1162/NECO_a_00247
-
[16]
Curve detectors
Cammarata, N., Goh, G., Carter, S., Schubert, L., Petrov, M., and Olah, C. Curve detectors. Distill.pub, 2020
2020
-
[17]
Penalized regression, standard errors, and bayesian lassos
Casella, G., Ghosh, M., Gill, J., and Kyung, M. Penalized regression, standard errors, and bayesian lassos. 2010
2010
-
[18]
Chang, L. and Tsao, D. Y. The code for facial identity in the primate brain. Cell, 169 0 (6): 0 1013--1028, 2017. doi:10.1016/j.cell.2017.05.011
-
[19]
and Abbott, L
Chung, S. and Abbott, L. F. Neural population geometry: An approach for understanding biological and artificial neural networks. Current opinion in neurobiology, 70: 0 137--144, 2021
2021
-
[20]
D., and Sompolinsky, H
Chung, S., Lee, D. D., and Sompolinsky, H. Classification and geometry of general perceptual manifolds. Physical Review X, 8 0 (3): 0 031003, 2018
2018
-
[21]
M., Cunningham, J
Churchland, M. M., Cunningham, J. P., Kaufman, M. T., Foster, J. D., Nuyujukian, P., Ryu, S. I., and Shenoy, K. V. Neural population dynamics during reaching. Nature, 2012
2012
-
[22]
Coifman, R. R. and Lafon, S. Diffusion maps. Applied and computational harmonic analysis, 2006
2006
-
[23]
What i cannot predict, i do not understand: A human-centered evaluation framework for explainability methods
Colin, J., Fel, T., Cad \`e ne, R., and Serre, T. What i cannot predict, i do not understand: A human-centered evaluation framework for explainability methods. Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[24]
Costa, V., Fel, T., Lubana, E. S., Tolooshams, B., and Ba, D. From flat to hierarchical: Extracting sparse representations with matching pursuit. arXiv preprint arXiv:2506.03093, 2025
arXiv 2025
-
[25]
Sparse autoencoders find highly interpretable features in language models
Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600, 2023
Pith/arXiv arXiv 2023
-
[26]
Dalili, S. A. and Mahdavi, M. Subspace-aware sparse autoencoders for effective mechanistic interpretability. A r X iv e-print , 2026
2026
-
[27]
Donoho, D. L. and Grimes, C. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proceedings of the National Academy of Sciences, 2003
2003
-
[28]
Doshi, F. R. and Konkle, T. Cortical topographic motifs emerge in a self-organized map of object space. Science Advances, 2023
2023
-
[29]
and Irofti, P
Dumitrescu, B. and Irofti, P. Dictionary learning algorithms and applications. 2018
2018
-
[30]
Ebitz, R. B. and Hayden, B. Y. The population doctrine in cognitive neuroscience. Neuron, 2021
2021
-
[31]
Sparse and redundant representations: from theory to applications in signal and image processing
Elad, M. Sparse and redundant representations: from theory to applications in signal and image processing. Springer Science & Business Media, 2010
2010
-
[32]
Eldar, Y. C. and Bolcskei, H. Block-sparsity: Coherence and efficient recovery. 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, 2009
2009
-
[33]
and Vidal, R
Elhamifar, E. and Vidal, R. Sparse manifold clustering and embedding. Advances in Neural Information Processing Systems (NeurIPS), 2011
2011
-
[34]
and Vidal, R
Elhamifar, E. and Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE transactions on pattern analysis and machine intelligence, 2013
2013
-
[35]
J., Liao, I., Gurnee, W., and Tegmark, M
Engels, J., Michaud, E. J., Liao, I., Gurnee, W., and Tegmark, M. Not all language model features are one-dimensionally linear. arXiv preprint arXiv:2405.14860, 2024
arXiv 2024
-
[36]
Look at the variance! efficient black-box explanations with sobol-based sensitivity analysis
Fel, T., Cadene, R., Chalvidal, M., Cord, M., Vigouroux, D., and Serre, T. Look at the variance! efficient black-box explanations with sobol-based sensitivity analysis. Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[37]
Unlocking feature visualization for deeper networks with magnitude constrained optimization
Fel, T., Boissin, T., Boutin, V., Picard, A., Novello, P., Colin, J., Linsley, D., Rousseau, T., Cadène, R., Gardes, L., and Serre, T. Unlocking feature visualization for deeper networks with magnitude constrained optimization. Advances in Neural Information Processing Systems (NeurIPS), 2023 a
2023
-
[38]
A holistic approach to unifying automatic concept extraction and concept importance estimation
Fel, T., Boutin, V., Moayeri, M., Cadene, R., Bethune, L., Chalvidal, M., and Serre, T. A holistic approach to unifying automatic concept extraction and concept importance estimation. Advances in Neural Information Processing Systems (NeurIPS), 2023 b
2023
-
[39]
Craft: Concept recursive activation factorization for explainability
Fel, T., Picard, A., Bethune, L., Boissin, T., Vigouroux, D., Colin, J., Cadène, R., and Serre, T. Craft: Concept recursive activation factorization for explainability. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 c
2023
-
[40]
A., Kowal, M., Lee, A., Balestriero, R., Joseph, S., Lubana, E
Fel, T., Wang, B., Lepori, M. A., Kowal, M., Lee, A., Balestriero, R., Joseph, S., Lubana, E. S., Konkle, T., Ba, D., et al. Into the rabbit hull: From task-relevant concepts in dino to minkowski geometry. arXiv preprint arXiv:2510.08638, 2025
Pith/arXiv arXiv 2025
-
[41]
S., et al
Feucht, S., Haklay, T., Bhalla, U., Wurgaft, D., Rager, C., Sarfati, R., Merullo, J., McGrath, T., Lewis, O., Lubana, E. S., et al. Arithmetic in the wild: Llama uses base-10 addition to reason about cyclic concepts. A r X iv e-print , 2026
2026
-
[42]
and Endres, D
Foldiak, P. and Endres, D. M. Sparse coding. A r X iv e-print , 2008
2008
-
[43]
Fong, R. C. and Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[44]
Smixae: Towards unsupervised manifold discovery in language models
Francel, C. Smixae: Towards unsupervised manifold discovery in language models. A r X iv e-print , 2026
2026
-
[45]
Convergent evolution: How different language models learn similar number representations
Fu, D., Zhou, T., Belkin, M., Sharan, V., and Jia, R. Convergent evolution: How different language models learn similar number representations. A r X iv e-print , 2026
2026
-
[46]
Fusi, S., Miller, E. K., and Rigotti, M. Why neurons mix: high dimensionality for higher cognition. Current Opinion in Neurobiology, 37: 0 66--74, 2016. doi:10.1016/j.conb.2016.01.010
-
[47]
A., Perich, M
Gallego, J. A., Perich, M. G., Miller, L. E., and Solla, S. A. Neural manifolds for the control of movement. Neuron, 2017
2017
-
[48]
D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., and Wu, J
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., and Wu, J. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093, 2024
Pith/arXiv arXiv 2024
-
[49]
S., Fel, T., Merullo, J., Lewis, O., and McGrath, T
Geiger, A., Lubana, E. S., Fel, T., Merullo, J., Lewis, O., and McGrath, T. The world inside neural networks: How neural geometry will unlock understanding and control of ai. Goodfire, May 2026
2026
-
[50]
P., Schwartz, A
Georgopoulos, A. P., Schwartz, A. B., and Kettner, R. E. Neuronal population coding of movement direction. Science, 233 0 (4771): 0 1416--1419, 1986
1986
-
[51]
Interpretation of neural networks is fragile
Ghorbani, A., Abid, A., and Zou, J. Interpretation of neural networks is fragile. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2017
2017
-
[52]
Y., and Kim, B
Ghorbani, A., Wexler, J., Zou, J. Y., and Kim, B. Towards automatic concept-based explanations. Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[53]
The missing curve detectors of inceptionv1: Applying sparse autoencoders to inceptionv1 early vision
Gorton, L. The missing curve detectors of inceptionv1: Applying sparse autoencoders to inceptionv1 early vision. A r X iv e-print , 2024
2024
-
[54]
and LeCun, Y
Gregor, K. and LeCun, Y. Learning fast approximations of sparse coding. Proceedings of the International Conference on Machine Learning (ICML), 2010
2010
-
[55]
When models manipulate manifolds: The geometry of a counting task
Gurnee, W., Ameisen, E., Kauvar, I., Tarng, J., Pearce, A., Olah, C., and Batson, J. When models manipulate manifolds: The geometry of a counting task. Transformer Circuits Thread, 2025. URL https://transformer-circuits.pub/2025/linebreaks/index.html
2025
-
[56]
Guthikonda, S. M. Kohonen self-organizing maps. Wittenberg University, 2005
2005
-
[57]
The out-of-distribution problem in explainability and search methods for feature importance explanations
Hase, P., Xie, H., and Bansal, M. The out-of-distribution problem in explainability and search methods for feature importance explanations. Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[58]
Hindupur, S. S. R., Lubana, E. S., Fel, T., and Ba, D. Projecting assumptions: The duality between sparse autoencoders and concept geometry. arXiv preprint arXiv:2503.01822, 2025
arXiv 2025
-
[59]
Evaluations and methods for explanation through robustness analysis
Hsieh, C.-Y., Yeh, C.-K., Liu, X., Ravikumar, P., Kim, S., Kumar, S., and Hsieh, C.-J. Evaluations and methods for explanation through robustness analysis. Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[60]
Learning with structured sparsity
Huang, J., Zhang, T., and Metaxas, D. Learning with structured sparsity. In Proceedings of the 26th Annual International Conference on Machine Learning, pp.\ 417--424, 2009
2009
-
[61]
Hyv \"a rinen, A. and Hoyer, P. Emergence of phase- and shift-invariant features by decomposition of natural images into independent feature subspaces. Neural Computation, 12 0 (7): 0 1705--1720, 2000. doi:10.1162/089976600300015312
-
[62]
Hyv \"a rinen, A., Hoyer, P. O., and Inki, M. Topographic independent component analysis. Neural Computation, 13 0 (7): 0 1527--1558, 2001. doi:10.1162/089976601750264992
-
[63]
Structured sparse principal component analysis
Jenatton, R., Obozinski, G., and Bach, F. Structured sparse principal component analysis. International Conference on Artificial Intelligence and Statistics, 2010
2010
-
[64]
Deep subspace clustering networks
Ji, P., Zhang, T., Li, H., Salzmann, M., and Reid, I. Deep subspace clustering networks. Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[65]
Kantamneni, S. and Tegmark, M. Language models use trigonometry to do addition. arXiv preprint arXiv:2502.00873, 2025 a
arXiv 2025
-
[66]
and Tegmark, M
Kantamneni, S. and Tegmark, M. Language models use trigonometry to do addition. A r X iv e-print , 2025 b
2025
-
[67]
J., Nava, A., Wyart, M., and Bahri, Y
Karkada, D., Korchinski, D. J., Nava, A., Wyart, M., and Bahri, Y. Symmetry in language statistics shapes the geometry of model representations. arXiv preprint arXiv:2602.15029, 2026
arXiv 2026
-
[68]
Karklin, Y. and Lewicki, M. S. Emergence of complex cell properties by learning to generalize in natural scenes. Nature, 457 0 (7225): 0 83--86, 2009. doi:10.1038/nature07481
-
[69]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav)
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In International conference on machine learning, pp.\ 2668--2677. PMLR, 2018
2018
-
[70]
Identifying interpretable visual features in artificial and biological neural systems
Klindt, D., Sanborn, S., Acosta, F., Poitevin, F., and Miolane, N. Identifying interpretable visual features in artificial and biological neural systems. A r X iv e-print , 2023
2023
-
[71]
From superposition to sparse codes: interpretable representations in neural networks
Klindt, D., O'Neill, C., Reizinger, P., Maurer, H., and Miolane, N. From superposition to sparse codes: interpretable representations in neural networks. arXiv preprint arXiv:2503.01824, 2025
arXiv 2025
-
[72]
Emergent organization of multiple visuotopic maps without a feature hierarchy
Konkle, T. Emergent organization of multiple visuotopic maps without a feature hierarchy. bioRxiv, 2021
2021
-
[73]
G., and Tokmakov, P
Kowal, M., Dave, A., Ambrus, R., Gaidon, A., Derpanis, K. G., and Tokmakov, P. Understanding video transformers via universal concept discovery. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 a
2024
-
[74]
P., and Derpanis, K
Kowal, M., Wildes, R. P., and Derpanis, K. G. Visual concept connectome (vcc): Open world concept discovery and their interlayer connections in deep models. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 b
2024
-
[75]
Structured sparse subspace clustering: A joint affinity learning and subspace clustering framework
Li, C.-G., You, C., and Vidal, R. Structured sparse subspace clustering: A joint affinity learning and subspace clustering framework. IEEE Transactions on Image Processing, 2017
2017
-
[76]
Li, Z., Chen, Y., LeCun, Y., and Sommer, F. T. Neural manifold clustering and embedding. A r X iv e-print , 2022
2022
-
[77]
Robust subspace segmentation by low-rank representation
Liu, G., Lin, Z., and Yu, Y. Robust subspace segmentation by low-rank representation. Proceedings of the International Conference on Machine Learning (ICML), 2010
2010
-
[78]
Robust recovery of subspace structures by low-rank representation
Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., and Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE transactions on pattern analysis and machine intelligence, 2012
2012
-
[79]
Lubana, E. S., Rager, C., Hindupur, S. S. R., Costa, V., Tuckute, G., Patel, O., Murthy, S. K., Fel, T., Wurgaft, D., Bigelow, E. J., et al. Priors in time: Missing inductive biases for language model interpretability. arXiv preprint arXiv:2511.01836, 2025
arXiv 2025
-
[80]
Sparse modeling for image and vision processing
Mairal, J., Bach, F., and Ponce, J. Sparse modeling for image and vision processing. Foundations and Trends in Computer Graphics and Vision, 2014
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.