The Ringelmann Effect in Multi-Agent LLM Systems: A Scaling Law for Effective Team Size
Pith reviewed 2026-06-28 16:02 UTC · model grok-4.3
The pith
Multi-agent LLM systems obey a two-parameter scaling law for effective team size that saturates in most configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
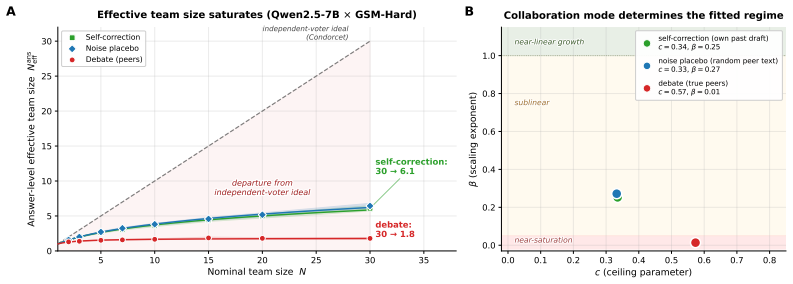
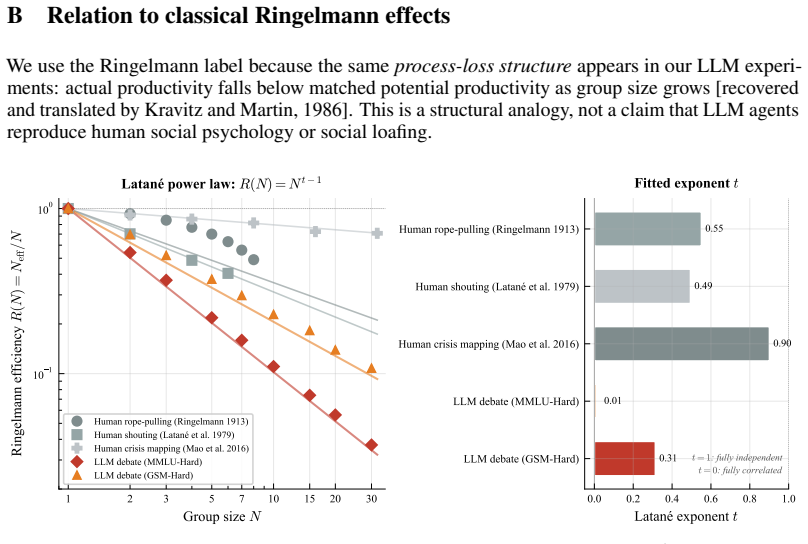
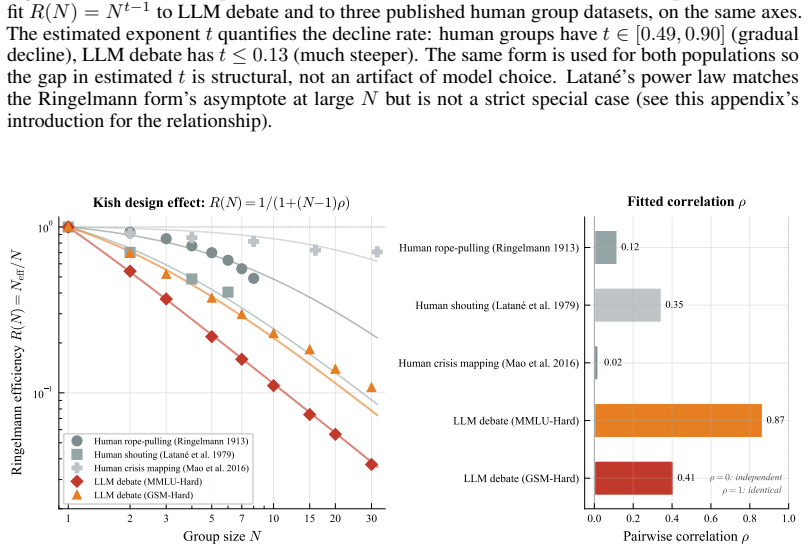
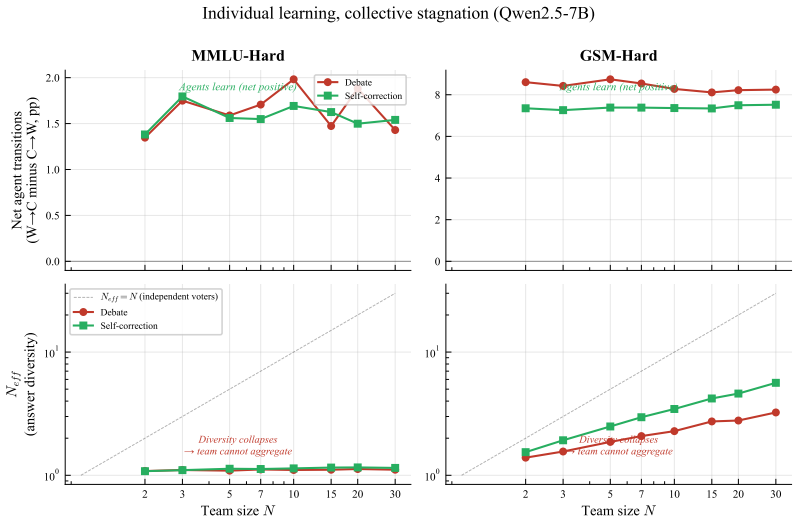
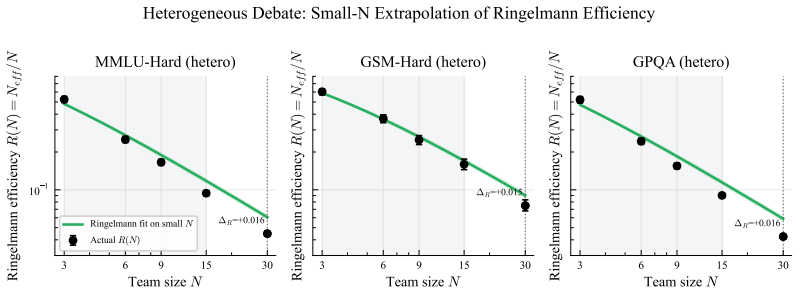
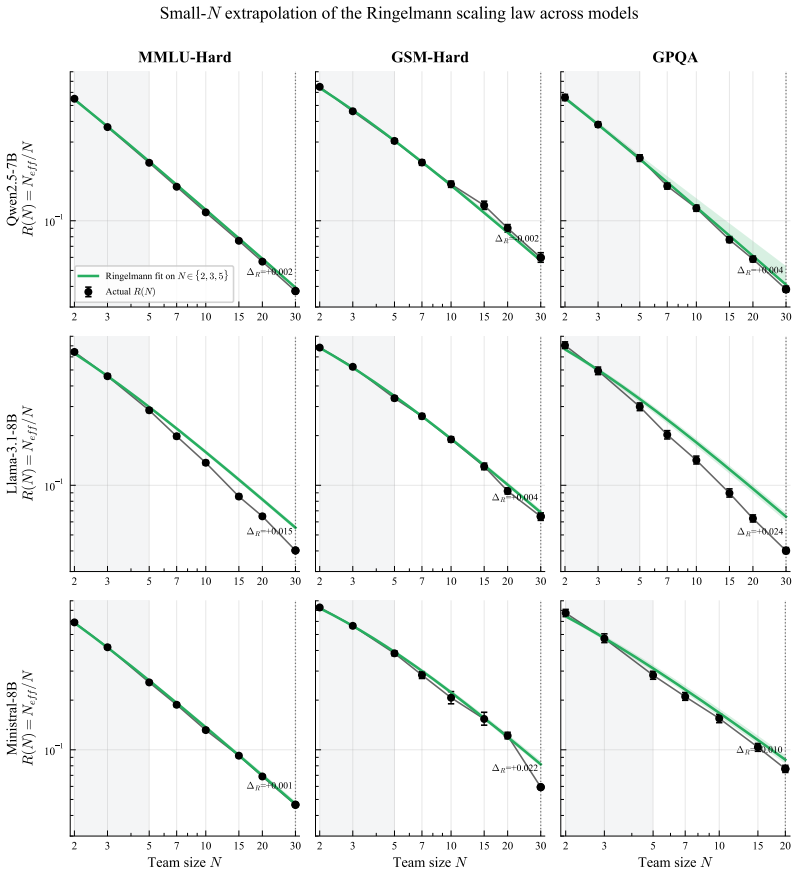
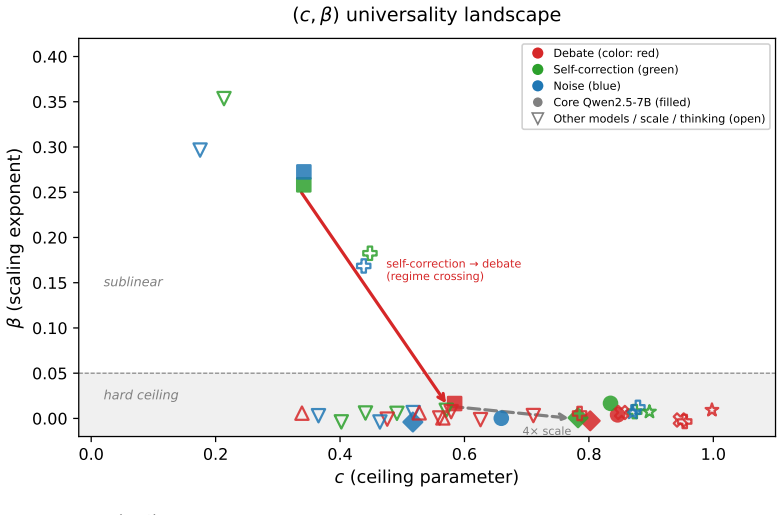
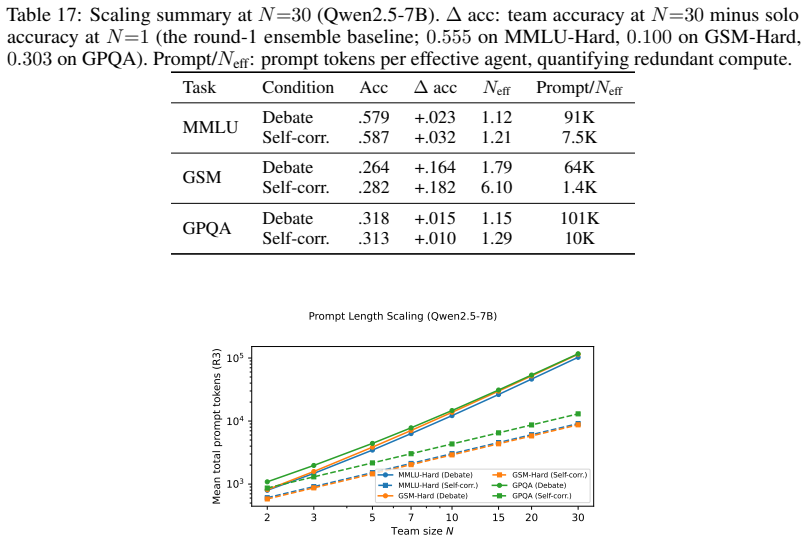
The central discovery is that the functional form R(N) = N_eff/N = 1/(1+c(N-1)N^{-β}) fits every tested condition at R² > 0.99, with only the parameters (c, β) varying. The exponent β determines the regime: hard-ceiling at 1/c when β=0, sublinear growth when 0<β<1, or linear when β≥1. A mean-field theorem predicts that peer count k and rounds τ enter only through the product kτ. The law holds at answer diversity and correctness redundancy levels, and across peer debate, self-correction, placebo, self-consistency, various models, and communication modes.
What carries the argument
The two-parameter scaling law R(N) = 1/(1 + c(N-1)N^{-β}) that measures the fraction of effective agents N_eff/N and classifies configurations by the regime exponent β.
Load-bearing premise
Peer count k and debate rounds τ influence the system only through their product kτ, and the 44 experimental cells represent the full space of configurations without bias in selection.
What would settle it
Running new experiments with different k and τ where the effect depends on them separately rather than only their product, or finding conditions where the scaling form fits with R² much lower than 0.99.
Figures
read the original abstract
Inference-time multi-agent LLM scaling lacks a shared unit: counting nominal agents conflates cost with independent evidence. We derive a two-parameter scaling law $R(N) = N_\text{eff}/N = 1/(1+c(N-1)N^{-\beta})$ where the regime exponent $\beta$ classifies any configuration into one of three asymptotic regimes -- hard-ceiling at $1/c$ ($\beta = 0$), sublinear at $N^\beta/c$ ($0 < \beta < 1$), or linear ($\beta \ge 1$), and a mean-field theorem predicts that peer count $k$ and rounds $\tau$ during agent debate enter the dynamics only through their product $k\tau$. The law applies at two levels: answer diversity and correctness redundancy. Across 44 (model $\times$ task $\times$ condition) cells spanning peer debate, self-correction, random-noise placebo, self-consistency, three open-weight families (Qwen, Llama, Ministral) at scales from 7B to 32B with a frontier API check (Gemini), thinking models, heterogeneous teams, and sparse communication, the functional form fits every condition at $R^2 > 0.99$; only $(c, \beta)$ shifts. On free-form math, dense peer influence collapses the answer-level regime from sublinear into hard-ceiling; correctness-level fits remain hard-ceiling throughout. Three findings have practical implications. \emph{(i)}~Thirty dense debating agents produce no more answer diversity than one on MMLU-Hard. \emph{(ii)}~A noise placebo tracks self-correction on free-form math and at $4\times$ scale, so within homogeneous teams the gain commonly attributed to ``debate'' comes from re-evaluation, not peer content. \emph{(iii)}~A single $N \le 5$ pilot predicts the $N=30$ structural ceiling, and within the configurations tested only architectural diversity (heterogeneous teams) lowers $c$ and escapes the hard-ceiling regime, communication-mode interventions do not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a two-parameter scaling law R(N) = N_eff/N = 1/(1 + c(N-1)N^{-β}) for effective team size in multi-agent LLM systems. It classifies configurations into hard-ceiling, sublinear, or linear regimes via the exponent β, and presents a mean-field theorem asserting that peer count k and debate rounds τ enter the dynamics only through the product kτ. The law is reported to fit answer diversity and correctness redundancy across 44 cells (spanning models, tasks, debate, self-correction, heterogeneous teams, and communication modes) at R² > 0.99, with only (c, β) varying; practical claims include that 30 dense agents add no diversity beyond one on MMLU-Hard and that heterogeneity lowers c while communication interventions do not.
Significance. If the central functional form and mean-field reduction hold after verification, the work supplies a compact, falsifiable description of diminishing returns in LLM teams, directly linking observable parameters (k, τ) to measurable effective size. The consistent high-R² fits across open-weight families, frontier models, and free-form vs. multiple-choice tasks, together with the explicit regime classification, would constitute a useful quantitative tool for system design; the observation that a small-N pilot predicts large-N ceilings is particularly actionable.
major comments (1)
- [Mean-field theorem and experimental design] The mean-field theorem (stated in the abstract and used to justify universality across the 44 cells) asserts that k and τ contribute only via their product kτ. No experiment is described that holds kτ fixed while varying k and τ independently; without such a test, finite-size effects or round-wise correlations could produce different N_eff for the same product, rendering the claimed two-parameter universality dependent on the particular (k, τ) sampling chosen for the cells rather than a general derivation.
minor comments (1)
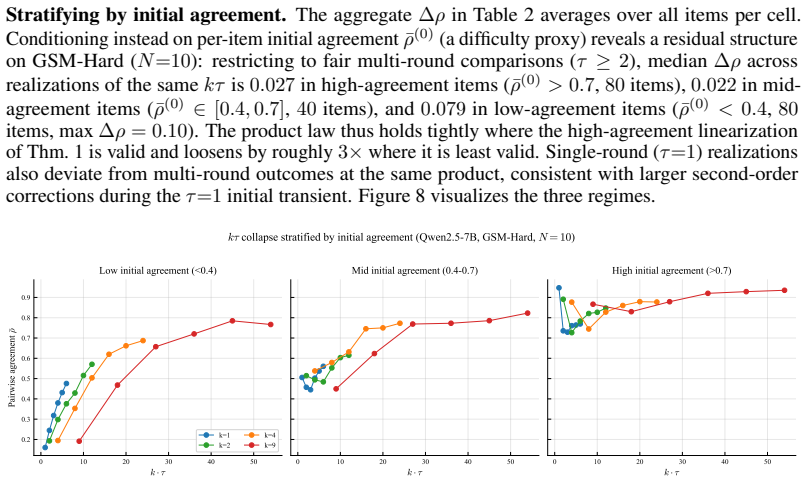
- [Abstract and methods] The abstract states that the functional form applies at both answer-diversity and correctness-redundancy levels, yet the precise operational definitions of N_eff for each level (e.g., how diversity is quantified, how redundancy is measured) are not restated in the provided excerpt; a short methods paragraph clarifying these quantities would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting this important point on the empirical support for the mean-field theorem. We respond to the major comment below and agree that additional clarification is warranted.
read point-by-point responses
-
Referee: The mean-field theorem (stated in the abstract and used to justify universality across the 44 cells) asserts that k and τ contribute only via their product kτ. No experiment is described that holds kτ fixed while varying k and τ independently; without such a test, finite-size effects or round-wise correlations could produce different N_eff for the same product, rendering the claimed two-parameter universality dependent on the particular (k, τ) sampling chosen for the cells rather than a general derivation.
Authors: We agree that a direct experimental test holding the product kτ fixed while independently varying k and τ would strengthen the claim. The mean-field theorem is a theoretical derivation from a mean-field approximation of the interaction process, in which the effective peer influence depends on the total number of interactions kτ. Although the 44 cells include a range of (k, τ) pairs and yield consistent high-R² fits, they were not explicitly sampled to hold kτ constant. We will revise the manuscript to (i) clarify that the reduction is a theoretical prediction whose empirical support is indirect, (ii) explicitly note the absence of a matched-product control as a limitation, and (iii) outline a targeted follow-up experiment. This revision does not alter the reported scaling-law fits or regime classifications but improves the interpretation of universality. revision: yes
Circularity Check
No significant circularity; derivation presented as independent of fitted values
full rationale
The paper states it derives the scaling law R(N) from a mean-field theorem reducing k and τ to the product kτ, then reports that the resulting two-parameter form fits all 44 cells at R² > 0.99 with only (c, β) varying. No equation or step is exhibited that reduces the claimed derivation or the mean-field prediction to the experimental fits by construction, nor is any self-citation used as load-bearing justification. The regime classification follows directly from the value of the fitted exponent β rather than presupposing the outcome, and the experimental validation remains external to the derivation step itself. The central claim therefore retains independent content from the data.
Axiom & Free-Parameter Ledger
free parameters (2)
- c
- β
axioms (1)
- domain assumption Mean-field theorem: peer count k and rounds τ enter the dynamics only through their product kτ
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Recherches sur les moteurs anim
Ringelmann, Maximilien , journal=. Recherches sur les moteurs anim
-
[3]
1972 , publisher=
Group Process and Productivity , author=. 1972 , publisher=
1972
-
[4]
American Psychologist , volume=
The psychology of social impact , author=. American Psychologist , volume=
-
[5]
Journal of Personality and Social Psychology , volume=
Many hands make light the work: The causes and consequences of social loafing , author=. Journal of Personality and Social Psychology , volume=
-
[6]
Essai sur l'application de l'analyse
de Condorcet, Marquis , year=. Essai sur l'application de l'analyse
-
[7]
1965 , publisher=
Survey Sampling , author=. 1965 , publisher=
1965
-
[8]
ICML , year=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. ICML , year=
-
[9]
EMNLP , year=
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. EMNLP , year=
-
[10]
ICLR , year=
Towards Understanding Sycophancy in Language Models , author=. ICLR , year=
-
[11]
Findings of ACL , year=
Discovering Language Model Behaviors with Model-Written Evaluations , author=. Findings of ACL , year=
-
[12]
Rethinking the Bounds of
Wang, Qineng and Wang, Zihao and Su, Ying and Tong, Hanghang and Song, Yangqiu , booktitle=. Rethinking the Bounds of
-
[13]
Talk Isn't Always Cheap: Understanding Failure Modes in Multi-Agent Debate , author=. arXiv preprint arXiv:2509.05396 , year=
-
[14]
Proceedings of ACM Conference on AI and Agentic Systems , year=
Decomposing Sycophancy, Fragility, Consensus Collapse and Cost in Homogeneous Multi-Agent LLM Debate , author=. Proceedings of ACM Conference on AI and Agentic Systems , year=
-
[15]
ICLR 2026 Workshop on AI for Mechanism Design and Strategic Decision Making , year=
Understanding Agent Scaling in LLM-based Multi-Agent Systems via Diversity , author=. ICLR 2026 Workshop on AI for Mechanism Design and Strategic Decision Making , year=
2026
-
[16]
Wu, Haolun and Li, Zhenkun and Li, Lingyao , journal=. Can
-
[17]
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning , author=. arXiv preprint arXiv:2510.07517 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
NeurIPS , year=
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models? , author=. NeurIPS , year=
-
[19]
Revisiting Multi-Agent Debate as Test-Time Scaling: When Does Multi-Agent Help? , author=. arXiv preprint arXiv:2505.22960 , year=
-
[20]
ACL , year=
Conformity in Large Language Models , author=. ACL , year=
-
[21]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[22]
NeurIPS , year=
Training Compute-Optimal Large Language Models , author=. NeurIPS , year=
-
[23]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
-
[24]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , booktitle=. Scaling
-
[25]
Are More
Chen, Lingjiao and Davis, Jared Quincy and Hanin, Boris and Bailis, Peter and Stoica, Ion and Zaharia, Matei and Zou, James , booktitle=. Are More
-
[26]
Reasoning in Token Economies: Budget-Aware Evaluation of
Wang, Junlin and Jain, Siddhartha and Zhang, Dejiao and Ray, Baishakhi and Kumar, Varun and Athiwaratkun, Ben , booktitle=. Reasoning in Token Economies: Budget-Aware Evaluation of
-
[27]
Consensus is Not Verification: Why Crowd Wisdom Strategies Fail for
Denisov-Blanch, Yegor and Kazdan, Joshua and Chudnovsky, Jessica and Schaeffer, Rylan and others , journal=. Consensus is Not Verification: Why Crowd Wisdom Strategies Fail for
-
[28]
Conformity and Social Impact on
Bellina, Alessandro and De Marzo, Giordano and Garcia, David , journal=. Conformity and Social Impact on
-
[29]
Peacemaker or Troublemaker: How Sycophancy Shapes Multi-Agent Debate , author=. arXiv preprint arXiv:2509.23055 , year=
-
[30]
Understanding Bias Reinforcement in
Oh, Jihwan and Jeong, Minchan and Ko, Jongwoo and Yun, Se-Young , journal=. Understanding Bias Reinforcement in
-
[31]
Chan, Chi-Min and Chen, Weize and Su, Yusheng and Yu, Jianxuan and Xue, Wei and Zhang, Shanghang and Fu, Jie and Liu, Zhiyuan , booktitle=. Chat
-
[32]
Zhang, Hangfan and Cui, Zhiyao and Zhang, Qiaosheng and Hu, Shuyue , journal=. Multi-. 2025 , note=
2025
-
[33]
Journal of Personality and Social Psychology , volume=
Ringelmann rediscovered: The original article , author=. Journal of Personality and Social Psychology , volume=
-
[34]
Is out of sight, out of mind?
Chidambaram, Laku and Tung, Lai Lai , journal=. Is out of sight, out of mind?
-
[35]
PLOS ONE , volume=
An experimental study of team size and performance on a complex task , author=. PLOS ONE , volume=
-
[36]
Towards a Science of Scaling Agent Systems
Towards a Science of Scaling Agent Systems , author=. arXiv preprint arXiv:2512.08296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
ICLR , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. ICLR , year=
-
[38]
and Pretorius, Arnu , booktitle=
Smit, Andries Petrus and Grinsztajn, Nathan and Duckworth, Paul and Barrett, Thomas D. and Pretorius, Arnu , booktitle=. Should We Be Going
-
[39]
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu
Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial? , author=. arXiv preprint arXiv:2502.00674 , year=
-
[40]
COLM , year=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. COLM , year=
-
[41]
, journal=
Ladha, Krishna K. , journal=. The
-
[42]
, journal=
Boland, Philip J. , journal=. Majority Systems and the
-
[43]
Oikos , volume=
Entropy and Diversity , author=. Oikos , volume=
-
[44]
Journal of the American Statistical Association , volume=
Reaching a Consensus , author=. Journal of the American Statistical Association , volume=
-
[45]
Irving, Geoffrey and Christiano, Paul and Amodei, Dario , journal=
-
[46]
Debating with More Persuasive
Khan, Akbir and Hughes, John and Valentine, Dan and Ruis, Laura and Sachan, Kush and Raber, Ansh and Guo, Edward and He, Haotian and Perez, Ethan and Irving, Geoffrey , booktitle=. Debating with More Persuasive
-
[47]
1972 , publisher=
Victims of Groupthink: A Psychological Study of Foreign-Policy Decisions and Fiascoes , author=. 1972 , publisher=
1972
-
[48]
Transactions on Machine Learning Research , year=
More Agents Is All You Need , author=. Transactions on Machine Learning Research , year=
-
[49]
NeurIPS , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. NeurIPS , year=
-
[50]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Findings of ACL , year=
Voting or Consensus? Decision-Making in Multi-Agent Debate , author=. Findings of ACL , year=
-
[52]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
ICLR , year=
Let's Verify Step by Step , author=. ICLR , year=
-
[54]
AAAI , year=
Diverse Beam Search for Improved Description of Complex Scenes , author=. AAAI , year=
-
[55]
DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning , author=. arXiv preprint arXiv:2602.19895 , year=
-
[56]
NeurIPS , year=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. NeurIPS , year=
-
[57]
PAL: Program-aided Language Models
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , year=. 2211.10435 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations (ICLR) , year=
-
[59]
, journal=
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.