WingSpan: Concurrency and Dependence for Sparse and Structured Tensor Compilers
Pith reviewed 2026-06-26 14:26 UTC · model grok-4.3
The pith
WingSpan enables arbitrary parallel compositions of loops and data structures for sparse tensors while using a dependence theory to guarantee safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WingSpan shows that a dependence theory tailored to sparse tensors and related structures can certify the safety of unrestricted parallel compositions, and that a compiler realizing this theory can match or exceed the speed of hand-optimized parallel routines on representative kernels.
What carries the argument
The dependence theory that classifies parallel compositions involving sparse tensors as safe or unsafe.
If this is right
- Any safe combination of parallel loops over sparse inputs and outputs can be written directly in the language.
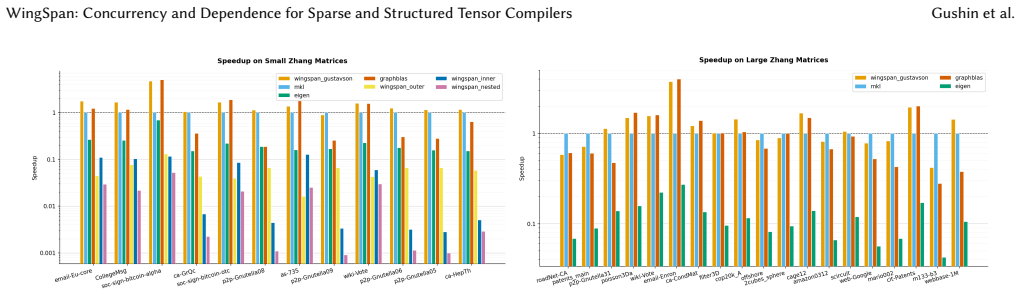
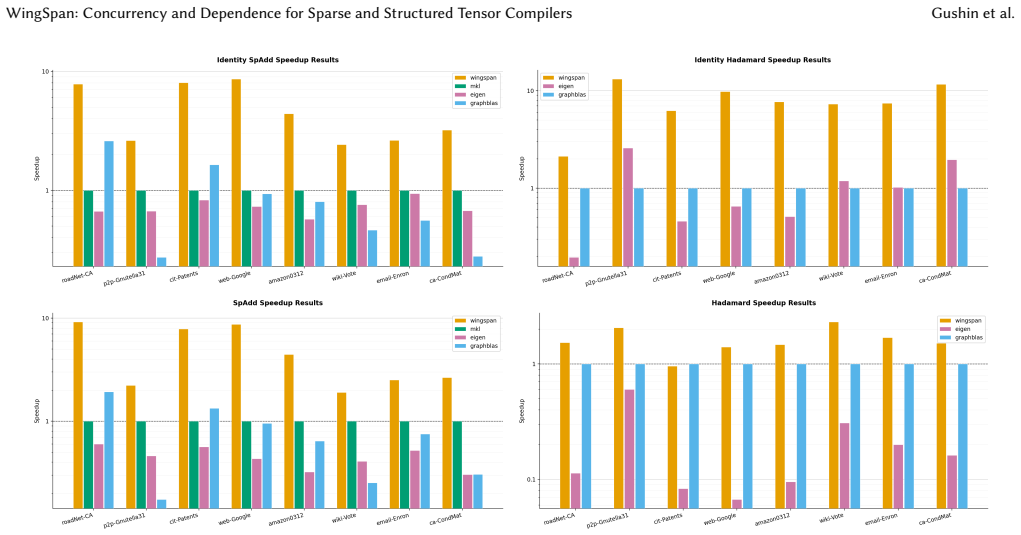
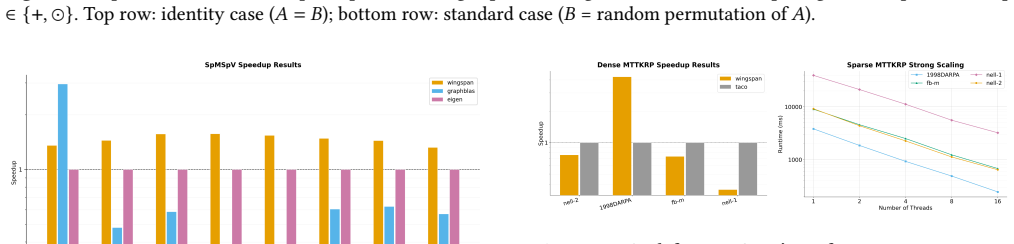
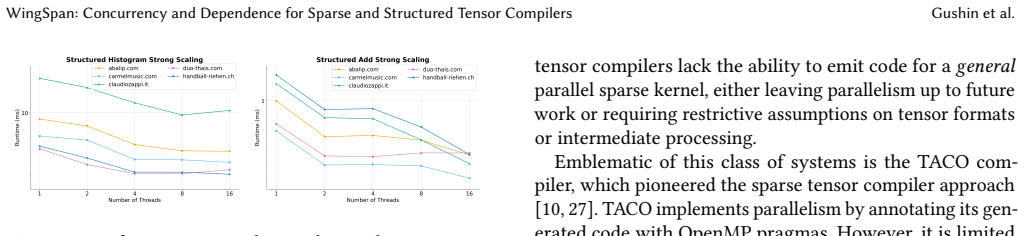
- Performance on SpGEMM and similar kernels reaches the level of manually tuned parallel code.
- The same safety analysis applies to data structures that go beyond simple sparsity.
- Parallel programs no longer require separate hand-written synchronization for sparse cases.
Where Pith is reading between the lines
- The same dependence rules could be ported to other tensor compilers to add parallelism without new language features.
- Hardware designers might use the theory to decide which sparse patterns warrant special parallel support.
- Large-scale sparse applications such as graph analytics could gain automatic parallelization once the theory is implemented.
Load-bearing premise
The dependence theory correctly flags every unsafe parallel composition that involves sparse outputs or multiple sparse inputs.
What would settle it
A concrete parallel program the theory labels safe yet produces wrong answers from concurrent writes on sparse tensor entries would disprove the claim.
Figures






read the original abstract
Sparse tensors represent data that is mostly zero or some other compressible fill pattern. Such datasets can be massive, so optimized tensor algebra libraries and compilers have been developed to exploit these patterns to improve performance. Existing systems, however, frequently lack support for parallelism, especially when outputs are sparse or multiple inputs are sparse. We propose WingSpan, a sparse tensor language enabling unrestricted parallel programming. WingSpan supports arbitrary composition of parallel loops and data structures, matching or exceeding the performance of hand-optimized parallel routines on critical kernels such as SpGEMM. We also introduce a dependence theory for the safety of parallel programs involving sparse tensors and structures beyond sparsity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WingSpan, a sparse tensor language that supports arbitrary composition of parallel loops and data structures to enable unrestricted parallel programming. It presents a dependence theory for ensuring the safety of such parallel programs involving sparse tensors and structures beyond sparsity, and claims that the system matches or exceeds the performance of hand-optimized parallel routines on kernels such as SpGEMM.
Significance. If the dependence theory correctly identifies unsafe compositions and the implementation delivers the claimed performance without hidden restrictions on parallelism, the work would address a notable gap in existing sparse tensor compilers by enabling more flexible parallel compositions than current systems.
major comments (2)
- [Abstract] Abstract: the central performance claim ('matching or exceeding the performance of hand-optimized parallel routines on critical kernels such as SpGEMM') is stated without reference to any experimental section, table, figure, or benchmark data, so the empirical result cannot be evaluated.
- [Abstract] Abstract: the dependence theory is asserted to ensure safety for parallel programs with sparse outputs or multiple sparse inputs, but no axioms, definitions, or proof outline is supplied, preventing assessment of whether it correctly identifies all unsafe compositions.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below and propose revisions where appropriate to improve clarity and evaluability of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim ('matching or exceeding the performance of hand-optimized parallel routines on critical kernels such as SpGEMM') is stated without reference to any experimental section, table, figure, or benchmark data, so the empirical result cannot be evaluated.
Authors: We agree that the abstract would benefit from explicit references to the supporting experimental results. The full manuscript includes performance evaluations in the experimental section with direct comparisons to hand-optimized baselines on SpGEMM and related kernels. We will revise the abstract to cite the relevant figures and tables. revision: yes
-
Referee: [Abstract] Abstract: the dependence theory is asserted to ensure safety for parallel programs with sparse outputs or multiple sparse inputs, but no axioms, definitions, or proof outline is supplied, preventing assessment of whether it correctly identifies all unsafe compositions.
Authors: The abstract is intended as a concise summary. The manuscript develops the dependence theory in detail, including the relevant axioms, definitions, and proof outlines in the sections presenting the theory. We will update the abstract to reference those sections so readers can locate the formal development immediately. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce WingSpan as a new language with a dependence theory for sparse tensor parallelism, claiming empirical performance matching on kernels like SpGEMM. No equations, fitted parameters, self-citations, or derivation steps are present that reduce claims to inputs by construction. The central claims rest on the proposed system and external empirical validation rather than any self-definitional, fitted-input, or self-citation load-bearing patterns. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
cuSPARSE.https://docs.nvidia.com/cuda/cusparse/index.html
2024. cuSPARSE.https://docs.nvidia.com/cuda/cusparse/index.html
2024
-
[2]
Willow Ahrens, Teodoro Fields Collin, Radha Patel, Kyle Deeds, Chang- wan Hong, and Saman Amarasinghe. 2025. Finch: Sparse and Struc- tured Tensor Programming with Control Flow.Proc. ACM Program. Lang.9, OOPSLA1 (April 2025). doi:10.1145/3720473Place: New York, NY, USA Publisher: Association for Computing Machinery
-
[3]
Willow Ahrens, Daniel Donenfeld, Fredrik Kjolstad, and Saman Ama- rasinghe. 2023. Looplets: A Language for Structured Coiteration. In Proceedings of the 21st ACM/IEEE International Symposium on Code Generation and Optimization (CGO). Association for Computing Ma- chinery, New York, NY, USA, 41–54. doi:10.1145/3579990.3580020
-
[4]
Fahri Aydos. 2020. WebScreenshots. doi:10.34740/KAGGLE/DS/202248
-
[5]
Mohsen Aznaveh, Jinhao Chen, Timothy A Davis, Bálint Hegyi, Scott P Kolodziej, Timothy G Mattson, and Gábor Szárnyas. 2020. Parallel GraphBLAS with OpenMP*. In2020 Proceedings of the SIAM Workshop on Combinatorial Scientific Computing. SIAM, 138–148
2020
-
[6]
2020.PETSc Users Manual (Rev
S Balay, S Abhyankar, Mark F Adams, J Brown, P Brune, K Buschelman, L Dalcin, A Dener, V Eijkhout, W Gropp, and others. 2020.PETSc Users Manual (Rev. 3.13). Technical Report. Argonne National Lab.(ANL), Argonne, IL (United States)
2020
-
[7]
1997.Dependence Analysis
Utpal Banerjee. 1997.Dependence Analysis. Springer
1997
-
[8]
Aart Bik, Penporn Koanantakool, Tatiana Shpeisman, Nicolas Vasi- lache, Bixia Zheng, and Fredrik Kjolstad. 2022. Compiler Support for Sparse Tensor Computations in MLIR.ACM Transactions on Architecture and Code Optimization19, 4 (Sept. 2022), 50:1–50:25. doi:10.1145/3544559
-
[9]
Stephen Chou and Saman Amarasinghe. 2022. Compilation of dy- namic sparse tensor algebra.Proceedings of the ACM on Programming Languages6, OOPSLA2 (Oct. 2022), 175:1408–175:1437. doi:10.1145/ 3563338
2022
-
[10]
Stephen Chou, Fredrik Kjolstad, and Saman Amarasinghe. 2018. For- mat abstraction for sparse tensor algebra compilers.Proceedings of the ACM on Programming Languages2, OOPSLA (Oct. 2018), 123:1–123:30. doi:10.1145/3276493
-
[11]
Atharva Chougule, Alexander J Root, Rubens Lacouture, Bobby Yan, Rohan Yadav, and Fredrik Kjolstad. 2026. Partitioning Unstruc- tured Sparse Tensor Algebra for Load-Balanced Parallel Execution. arXiv:2604.17198 [cs.PL]https://arxiv.org/abs/2604.17198
Pith/arXiv arXiv 2026
-
[12]
Anirban Dasgupta, Ravi Kumar, and D. Sivakumar. 2012. Sparse and Lopsided Set Disjointness via Information Theory. InApproximation, Randomization, and Combinatorial Optimization. Algorithms and Tech- niques (Lecture Notes in Computer Science), Anupam Gupta, Klaus Jansen, José Rolim, and Rocco Servedio (Eds.). Springer, Berlin, Hei- delberg, 517–528. doi:1...
-
[13]
Timothy A. Davis. 2019. Algorithm 1000: SuiteSparse:GraphBLAS: Graph Algorithms in the Language of Sparse Linear Algebra.ACM Trans. Math. Softw.45, 4, Article 44 (dec 2019), 25 pages. doi:10.1145/ 3322125
2019
-
[14]
Sofie De Cnudde, Yanou Ramon, David Martens, and Foster Provost
-
[15]
Deep learning on big, sparse, behavioral data.Big data7, 4 (2019), 286–307
2019
-
[16]
Daniel Donenfeld, Stephen Chou, and Saman Amarasinghe. 2022. Uni- fied Compilation for Lossless Compression and Sparse Computing. In2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 205–216. doi:10.1109/CGO53902.2022.9741282
-
[17]
Laurent El Ghaoui, Vu Pham, Guan-Cheng Li, Viet-An Duong, Ashok Srivastava, and Kanishka Bhaduri. 2013. Understanding large text corpora via sparse machine learning.Statistical Analysis and Data Mining: The ASA Data Science Journal6, 3 (2013), 221–242
2013
-
[18]
Jonathan Frankle and Michael Carbin. 2019. The Lottery Ticket Hy- pothesis: Finding Sparse, Trainable Neural Networks.arXiv:1803.03635 [cs](March 2019).http://arxiv.org/abs/1803.03635arXiv: 1803.03635
Pith/arXiv arXiv 2019
-
[19]
Graph500. 2025. November 2025 BFS.http://graph500.org/?page_id= 1410
2025
-
[20]
Gaël Guennebaud, Benoît Jacob, and others. 2010. Eigen v3.http: //eigen.tuxfamily.org
2010
-
[21]
Dorit S Hochbaum and Philipp Baumann. 2016. Sparse computation for large-scale data mining.IEEE Transactions on Big Data2, 2 (2016), 151–174
2016
-
[22]
Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. 2019. Taichi: a language for high-performance computation on spatially sparse data structures.ACM Transactions on Graphics38, 6 (Nov. 2019), 201:1–201:16. doi:10.1145/3355089.3356506
-
[23]
Intel Corporation. 2024. Developer Reference for Intel®oneAPI Math Kernel Library for Fortran.https://www.intel.com/content/www/us/ en/docs/onemkl/developer-reference-fortran/2024-0/overview.html
2024
-
[24]
John Jenkinson, Artyom Grigoryan, Mehdi Hajinoroozi, Raquel Díaz Hernández, Hayde Peregrina Barreto, Ariel Ortiz Esquivel, Leopoldo Altamirano, and Vahram Chavushyan. 2014. Machine learning and image processing in astronomy with sparse data sets. In2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 200–203
2014
-
[25]
2001.Optimizing Compilers For Mod- ern Architectures: A Dependence-Based Approach
Ken Kennedy and John R Allen. 2001.Optimizing Compilers For Mod- ern Architectures: A Dependence-Based Approach. Morgan Kaufmann Publishers Inc
2001
-
[26]
Owens, Marcin Zalewski, Timothy Mattson, and Jose Moreira
Jeremy Kepner, Peter Aaltonen, David Bader, Aydin Buluç, Franz Franchetti, John Gilbert, Dylan Hutchison, Manoj Kumar, Andrew Lumsdaine, Henning Meyerhenke, Scott McMillan, Carl Yang, John D. Owens, Marcin Zalewski, Timothy Mattson, and Jose Moreira. 2016. Mathematical foundations of the GraphBLAS. In2016 IEEE High Per- formance Extreme Computing Conferen...
arXiv 2016
-
[27]
2011.Graph Algorithms in the Lan- guage of Linear Algebra
Jeremy Kepner and John Gilbert. 2011.Graph Algorithms in the Lan- guage of Linear Algebra. Society for Industrial and Applied Mathemat- ics, USA
2011
-
[28]
Fredrik Kjolstad, Stephen Chou, David Lugato, Shoaib Kamil, and Saman Amarasinghe. 2017. taco: a tool to generate tensor algebra kernels. InProceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE 2017). IEEE Press, Urbana- Champaign, IL, USA, 943–948
2017
-
[29]
Kolodziej, Mohsen Aznaveh, Matthew Bullock, Jarrett David, Timothy A
Scott P. Kolodziej, Mohsen Aznaveh, Matthew Bullock, Jarrett David, Timothy A. Davis, Matthew Henderson, Yifan Hu, and Read Sandstrom
-
[30]
The SuiteSparse Matrix Collection Website Interface.Journal of Open Source Software4, 35 (2019), 1244. doi:10.21105/joss.01244
-
[31]
Minseok Kong, Jiho Park, Daye Lee, Nikolaos Kourtzanidis, and Jung- min So. 2025. Simulating Mobile Robot Vision: An Analysis of RGB-D Versus RGB-Based Distance Accuracy and CPU Optimization. In2025 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). IEEE, 0871–0876
2025
-
[32]
Jie Liu, Zhongyuan Zhao, Zijian Ding, Benjamin Brock, Hongbo Rong, and Zhiru Zhang. 2024. UniSparse: An Intermediate Language for General Sparse Format Customization.Reproduction Package for Arti- cle ‘UniSparse: An Intermediate LanguageforGeneralSparseFormatCus- tomization’8, OOPSLA1 (April 2024), 99:137–99:165. doi:10.1145/ 3649816
2024
-
[33]
Tim Mattson, Timothy A Davis, Manoj Kumar, Aydin Buluc, Scott McMillan, José Moreira, and Carl Yang. 2019. LAGraph: A community effort to collect graph algorithms built on top of the GraphBLAS. In 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 276–284
2019
-
[34]
Erdal Mutlu, Ruiqin Tian, Bin Ren, Sriram Krishnamoorthy, Roberto Gioiosa, Jacques Pienaar, and Gokcen Kestor. 2020. COMET: A Domain- Specific Compilation of High-Performance Computational Chemistry. InInternational Workshop on Languages and Compilers for Parallel Computing. Springer, 87–103. WingSpan: Concurrency and Dependence for Sparse and Structured ...
2020
-
[35]
George, Kalyan Bhetwal, Michelle Mills Strout, Mary Hall, and Catherine Olschanowsky
Tobi Popoola, Tuowen Zhao, Aaron St. George, Kalyan Bhetwal, Michelle Mills Strout, Mary Hall, and Catherine Olschanowsky. 2023. Code Synthesis for Sparse Tensor Format Conversion and Optimiza- tion. InProceedings of the 21st ACM/IEEE International Symposium on Code Generation and Optimization (CGO 2023). Association for Com- puting Machinery, New York, N...
-
[36]
Jason Rumengan, Terry Yue Zhuo, and Conrad Sanderson. 2021. PyArmadillo: a streamlined linear algebra library for Python.Journal of Open Source Software6, 66 (2021), 3051. doi:10.21105/joss.03051
-
[37]
Ryan Senanayake, Changwan Hong, Ziheng Wang, Amalee Wilson, Stephen Chou, Shoaib Kamil, Saman Amarasinghe, and Fredrik Kjol- stad. 2020. A sparse iteration space transformation framework for sparse tensor algebra.Proceedings of the ACM on Programming Lan- guages4, OOPSLA (Nov. 2020), 158:1–158:30. doi:10.1145/3428226
-
[38]
Amir Shaikhha, Mathieu Huot, Jaclyn Smith, and Dan Olteanu. 2022. Functional collection programming with semi-ring dictionaries.Pro- ceedings of the ACM on Programming Languages6, OOPSLA1 (April 2022), 89:1–89:33. doi:10.1145/3527333
-
[39]
Choi, Jiajia Li, Richard Vuduc, Jongsoo Park, Xing Liu, and George Karypis
Shaden Smith, Jee W. Choi, Jiajia Li, Richard Vuduc, Jongsoo Park, Xing Liu, and George Karypis. 2017.FROSTT: The Formidable Repository of Open Sparse Tensors and Tools.http://frostt.io/
2017
-
[40]
Michelle Mills Strout, Geri Georg, and Catherine Olschanowsky. 2012. Set and Relation Manipulation for the Sparse Polyhedral Framework. InLanguages and Compilers for Parallel Computing (Lecture Notes in Computer Science). Springer, Berlin, Heidelberg, 61–75. doi:10.1007/ 978-3-642-37658-0_5
2012
-
[41]
Michelle Mills Strout, Mary Hall, and Catherine Olschanowsky. 2018. The Sparse Polyhedral Framework: Composing Compiler-Generated Inspector-Executor Code.Proc. IEEE106, 11 (Nov. 2018), 1921–1934. doi:10.1109/JPROC.2018.2857721Conference Name: Proceedings of the IEEE
-
[42]
Michelle Mills Strout, Alan LaMielle, Larry Carter, Jeanne Ferrante, Barbara Kreaseck, and Catherine Olschanowsky. 2016. An approach for code generation in the Sparse Polyhedral Framework.Parallel Comput.53 (April 2016), 32–57. doi:10.1016/j.parco.2016.02.004
-
[43]
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S. Emer. 2020. Efficient Processing of Deep Neural Networks.Synthesis Lectures on Computer Architecture15, 2 (June 2020), 1–341. doi:10.2200/ S01004ED1V01Y202004CAC050Publisher: Morgan & Claypool Pub- lishers
2020
-
[44]
Ruiqin Tian, Luanzheng Guo, Jiajia Li, Bin Ren, and Gokcen Kestor
-
[45]
2021).http://arxiv.org/abs/2102
A High-Performance Sparse Tensor Algebra Compiler in Multi- Level IR.arXiv:2102.05187 [cs](Feb. 2021).http://arxiv.org/abs/2102. 05187arXiv: 2102.05187
arXiv 2021
-
[46]
qblaze: An Efficient and Scalable Sparse Quantum Simulator
Hristo Venev, Thien Udomsrirungruang, Dimitar Dimitrov, Timon Gehr, and Martin Vechev. 2025. qblaze: An Efficient and Scalable Sparse Quantum Simulator.Artifact for "qblaze: An Efficient and Scalable Sparse Quantum Simulator"9, OOPSLA2 (Oct. 2025), 288:444–288:470. doi:10.1145/3763066
-
[47]
Liang, Image classification based on RESNET
Richard Vuduc, James W. Demmel, and Katherine A. Yelick. 2005. OSKI: A library of automatically tuned sparse matrix kernels.Journal of Physics: Conference Series16 (Jan. 2005), 521–530. doi:10.1088/1742- 6596/16/1/071Publisher: IOP Publishing
-
[48]
Jaeyeon Won, Willow Ahrens, Saman Amarasinghe, and Joel S Emer
-
[49]
InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2
Insum: Sparse GPU Kernels Simplified and Optimized with Indi- rect Einsums. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 993–1006
-
[50]
Zihao Ye, Ruihang Lai, Junru Shao, Tianqi Chen, and Luis Ceze. 2023. SparseTIR: Composable Abstractions for Sparse Compilation in Deep Learning. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Sys- tems, Volume 3 (ASPLOS 2023). Association for Computing Machinery, New York, NY, USA, 6...
-
[51]
Guowei Zhang, Nithya Attaluri, Joel S. Emer, and Daniel Sanchez. 2021. Gamma: leveraging Gustavson’s algorithm to accelerate sparse matrix multiplication. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. ACM, Virtual USA, 687–701. doi:10.1145/3445814.3446702
-
[52]
Tuowen Zhao, Tobi Popoola, Mary Hall, Catherine Olschanowsky, and Michelle Strout. 2022. Polyhedral specification and code generation of sparse tensor contraction with co-iteration.ACM Transactions on Architecture and Code Optimization20, 1 (2022), 1–26
2022
-
[53]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. 2024. A Survey on Model Compression for Large Language Models.Transac- tions of the Association for Computational Linguistics12 (Nov. 2024), 1556–1577. doi:10.1162/tacl_a_00704
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.