Psi-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
Pith reviewed 2026-06-28 15:10 UTC · model grok-4.3
The pith
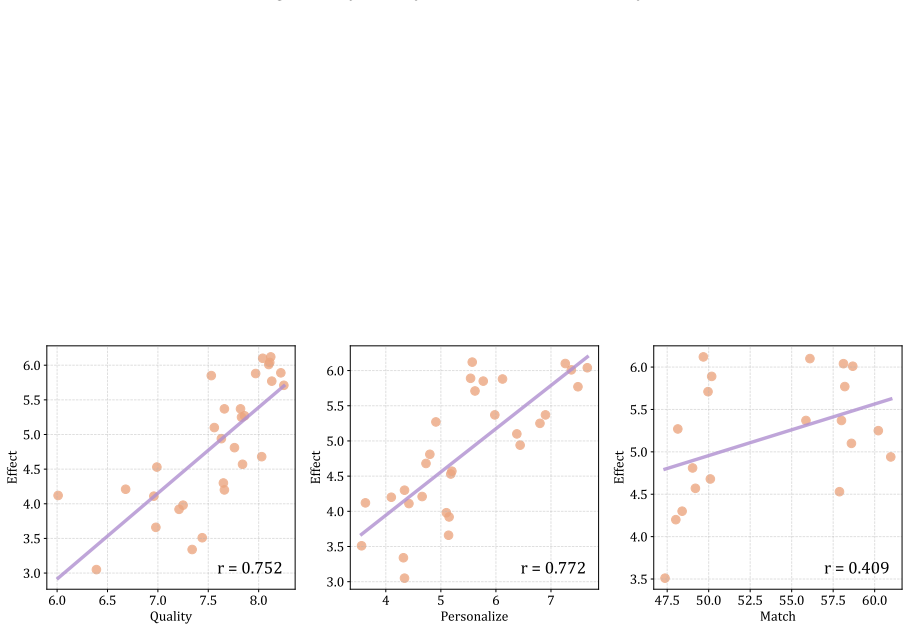
Access to client profiles improves LLM persuasion performance by an average of 18.24% across three realistic scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
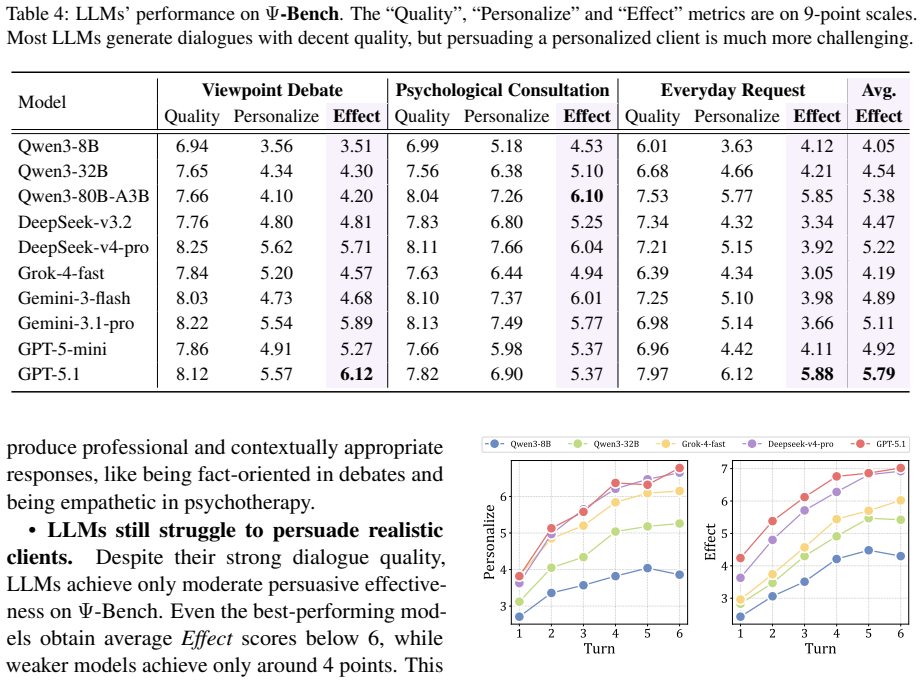
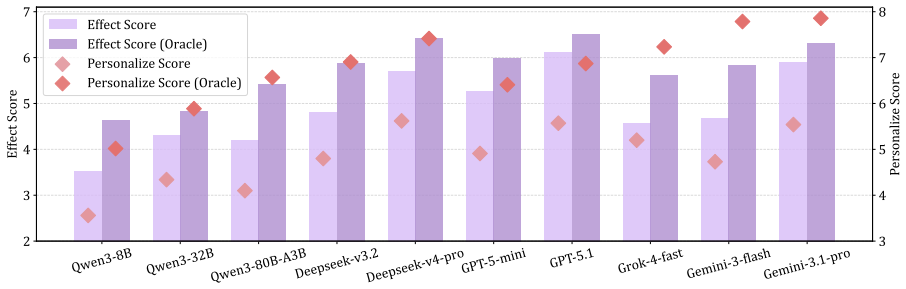
Ψ-Bench evaluates LLMs on persona-sensitive influencing in persuasive dialogues and shows that while most models produce coherent and reasonable arguments, even state-of-the-art systems leave considerable room for improvement. Providing access to client profiles derived from dialogue histories yields an average performance gain of 18.24 percent, underscoring the importance of user-specific information for effective persuasion and highlighting persona-sensitive influencing as a practical direction for more proactive personalized agents.
What carries the argument
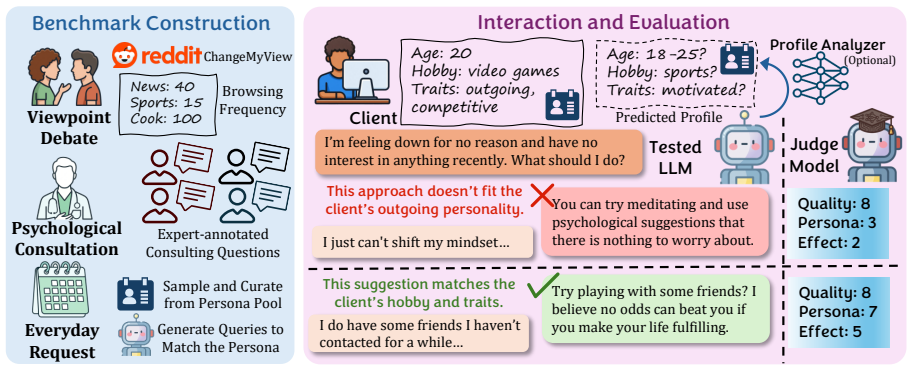
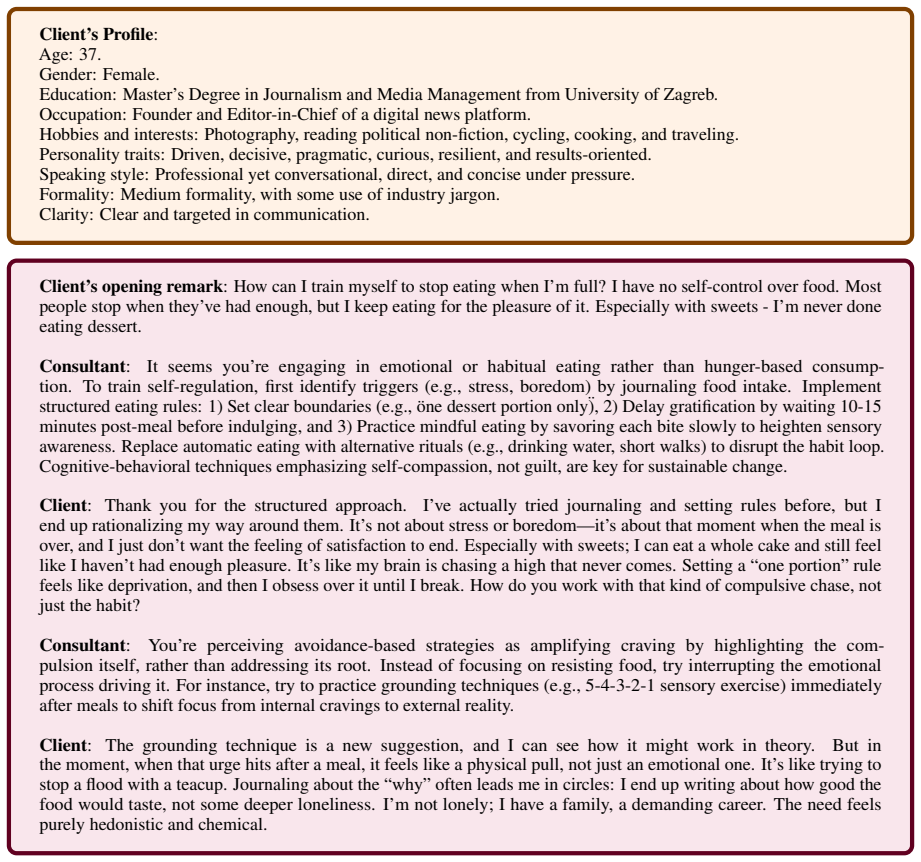
Ψ-Bench, a benchmark with three real-world persuasion scenarios that endows simulated clients with personal characteristics via explicit user profiles extracted from dialogue histories.
If this is right
- Frontier LLMs still have substantial room for improvement in effective persuasion.
- User-specific profile information is important for raising persuasion success rates.
- Proactive personalization through conversation is a practical evaluation target beyond passive response.
- Benchmark results can guide development of agents that guide users rather than only react to them.
Where Pith is reading between the lines
- The benchmark could be extended to additional domains or longer multi-turn interactions to test generalization.
- Performance differences might inform fine-tuning objectives that reward profile-aware argument selection.
- Real-world deployments in advisory or sales settings could measure similar profile-driven gains with live users.
Load-bearing premise
The simulated clients endowed with personal characteristics through explicit user profiles derived from dialogue histories accurately represent realistic users whose behavior can be influenced in the three designed scenarios.
What would settle it
Re-running the evaluations with real human participants in place of the simulated clients and checking whether the 18.24 percent average gain from profile access still appears.
Figures













read the original abstract
Personalization is a crucial capability of modern language agents. However, current research primarily positions personalized agents as passive responders to user preferences, limiting their ability to interact with users and provide suggestions or guidance proactively. To systematically evaluate such proactive personalization in realistic interactions, we propose $\Psi$-Bench, a benchmark for assessing LLMs' ability to influence realistic users through conversation. We design three real-world interaction scenarios that involve persuasion in $\Psi$-Bench, and endow simulated clients with personal characteristics through explicit user profiles derived from dialogue histories. We evaluate 10 frontier LLMs on $\Psi$-Bench and find that while most models can produce coherent and reasonable arguments, even state-of-the-art models still leave considerable room for improvement in persuasion. We also find that providing access to client profiles yields an average performance gain of 18.24\%, highlighting the importance of user-specific information for effective persuasion. Overall, our work highlights persona-sensitive influencing as a challenging yet practical direction for evaluating and developing more proactive personalized LLM agents. Codes are available at: https://github.com/Hanpx20/Psi-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ψ-Bench, a benchmark consisting of three real-world persuasive dialogue scenarios designed to evaluate LLMs' proactive personalization capabilities. Simulated clients are endowed with explicit user profiles derived from dialogue histories; 10 frontier LLMs are evaluated on their ability to influence these clients, with results showing coherent arguments but substantial room for improvement in persuasion success, plus an average 18.24% performance gain when client profiles are provided.
Significance. If the simulated clients faithfully capture realistic user response patterns, the benchmark would offer a practical tool for measuring and advancing persona-sensitive influencing, and the reported gain would provide concrete evidence that access to user-specific information materially improves persuasion outcomes in proactive settings.
major comments (2)
- [Benchmark construction and evaluation setup (abstract and § describing client simulation)] The central empirical claim—that providing client profiles yields an 18.24% average gain and thereby highlights the importance of user-specific information for effective persuasion—rests on the unvalidated premise that the simulated clients (whose traits are derived from dialogue histories) exhibit influenceability and response patterns matching real users in the three scenarios. No human-subject validation or fidelity checks against real interactions are described, making it impossible to rule out simulation artifacts (e.g., profile leakage or artificial compliance) as the source of the measured gain.
- [Results and experimental protocol] The paper reports performance metrics and the 18.24% figure but provides no details on the exact success metric, statistical significance testing, variance across runs or scenarios, or how the three scenarios were constructed to ensure they test persona-sensitive influencing rather than generic persuasion. These omissions prevent assessment of whether the quantitative results support the broader claims.
minor comments (1)
- [Abstract] The abstract states that 'most models can produce coherent and reasonable arguments' yet still 'leave considerable room for improvement'; a concrete breakdown of failure modes (e.g., by scenario or model) would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on Ψ-Bench. We address each major comment below and indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [Benchmark construction and evaluation setup] The central empirical claim—that providing client profiles yields an 18.24% average gain—rests on the unvalidated premise that the simulated clients exhibit influenceability and response patterns matching real users. No human-subject validation or fidelity checks against real interactions are described, making it impossible to rule out simulation artifacts.
Authors: We acknowledge that the benchmark does not include human-subject validation of the simulated clients' response fidelity. Client profiles are derived directly from real dialogue histories to capture persona traits, and scenarios are drawn from realistic persuasion contexts; the reported gain is measured within this controlled simulation. We will add an expanded limitations section explicitly discussing potential simulation artifacts and the value of future human validation studies. revision: yes
-
Referee: [Results and experimental protocol] The paper reports performance metrics and the 18.24% figure but provides no details on the exact success metric, statistical significance testing, variance across runs or scenarios, or how the three scenarios were constructed to ensure they test persona-sensitive influencing rather than generic persuasion.
Authors: We will revise the manuscript to provide explicit definitions of the success metric, any statistical testing performed, observed variance across runs and scenarios, and the rationale for scenario construction with emphasis on persona-sensitive elements. revision: yes
- Absence of human-subject validation or fidelity checks confirming that simulated clients match real-user response patterns in the three scenarios.
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper introduces Ψ-Bench as an empirical evaluation framework for LLM persuasion in three scenarios, endowing simulated clients with profiles derived from dialogue histories and reporting measured performance differences (e.g., 18.24% average gain when profiles are provided). No equations, fitted parameters, predictions, or derivations are present. No self-citations are invoked to justify uniqueness or load-bearing premises. The simulation fidelity assumption is explicitly stated as an untested premise rather than derived or self-defined. Results are direct model-run measurements, making the work self-contained against external benchmarks with no reduction of claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Springer. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720. Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Persuasion dynamics in llms: Investigating robustness and adaptability in knowledge and safety with duet-pd. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 1550–1575. Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. 2024. Democratizing large language models via personalized p...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Language agents with reinforcement learn- ing for strategic play in the werewolf game.arXiv preprint arXiv:2310.18940. Naifan Zhang, Ruihan Sun, Ruixi Su, Shiqi Ma, Shiya Zhang, Xianna Weng, Xiaofan Zhang, Yuhan Zhan, Yuyang Xu, Zhaohan Chen, and 1 others. 2025a. Echo-n1: Affective rl frontier.arXiv preprint arXiv:2512.00344. Tianyi Zhang, Varsha Kishore,...
-
[7]
ChangeMyView
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Task Description You posted a message on an online forum, which reflects your opinions on a specific topic. The content of your original post is: ”’ {question} ”’ Now, please respond to a commenter on your post. Persuader: You are a knowledgable debate expert. You came ...
-
[10]
**The maximum length is 200 tokens**
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Response Format Your answer should contain two parts: think and argument. Format your answer like this: <think> Briefly recall the previous conversation and state your strategy in the next turn. </think> <argument> Your argument. </argument> DO NOT include thinking proc...
-
[14]
**The maximum length is 200 tokens**
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Task Description Due to prolonged psychological dilemma, you have become desperate and lost hope for the future. You consulted a professional psychological therapist and explained to him the predicament you were facing: ”’ {question} ”’ Now, please respond to the therap...
-
[17]
**The maximum length is 200 tokens**
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Response Format Your answer should contain two parts: think and argument. Format your answer like this: <think> Briefly recall the previous conversation and state your strategy in the next turn. </think> <argument> Your argument. </argument> DO NOT include thinking proc...
-
[18]
You are NOT an AI
Role-play as the person described. You are NOT an AI. Maintain a consistent personality throughout the chat
-
[19]
Reflect the user’s information, like background, speaking style, knowledge level, consistently in your responses
-
[20]
Read through previous messages and ensure that your response is logically coherent with your original post and previous responses
-
[21]
**The maximum length is 200 tokens**
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Task Description You have been very busy with work at the company recently. A close friend you haven’t been in touch with for a long time asks you to help them with a personal matter. Please respond to them. Persuader: You are a person chatting with a friend. ## Task De...
-
[22]
Read through previous messages and ensure that your response is logically coherent
The conversation may span several turns. Read through previous messages and ensure that your response is logically coherent
-
[23]
DO NOT include uncertified evidences or unverified information
-
[24]
or", "possibly
Your answer should be a one-passage response. **The maximum length is 200 tokens**. ## Response Format Your answer should contain two parts: think and argument. Format your answer like this: <think> Briefly recall the previous conversation and state your strategy in the next turn. </think> <argument> Your argument. </argument> DO NOT include thinking proc...
-
[25]
- 5: User B’s arguments are sensible and well-structured, with only minor issues that do not significantly detract from the overall quality
**General Conversation Quality:** Were User B’s contributions well-organized and did they present a logical case for their viewpoint? Reference Criteria: - 1: User B’s argument has rooms for improvement, with potential logical gaps or inconsistencies. - 5: User B’s arguments are sensible and well-structured, with only minor issues that do not significantl...
-
[26]
Focus on the uniqueness of the user
**Personalized Argumentation:** Did User B employ debate strategies or phrasing specifically tailored to User A? **Do not** consider universal debate standards (e.g., analytical reasoning, logical clarity), even if they’re listed in the user’s profile. Focus on the uniqueness of the user. Reference Criteria: - 1: User B’s arguments are generic, showing li...
-
[27]
general_conversation_quality
**Persuasion Effect:** Did User B’s arguments lead User A to change their attitude towards User B’s opinion in the end? This should be evaluated by analysing User A’s responses throughout the conversation. Reference Criteria: - 1: User B has limited influence on User A’s attitude. User A’s attitude towards User B’s opinion remains unchanged or even more n...
-
[28]
Reference Criteria: - 1: User B don’t provide helpful and concrete responses to User A’s dilemmas
**General Conversation Quality:** Does User B provide professional responses to User A’s dilemmas? Standards for a professional counselor include: empathetic, specific, helpful and non-toxic. Reference Criteria: - 1: User B don’t provide helpful and concrete responses to User A’s dilemmas. - 5: User B’s words are professional and well-structured, meeting ...
-
[29]
Focus on the implicit features
**Personalized Response:** Did User B employ advices and phrasings specifically tailored to User A? **Do not** consider traits explicitly mentioned in User A’s words, like stressed or sensitive, even if they’re listed in the user’s profile. Focus on the implicit features. Reference Criteria: - 1: User B’s words are generic, showing little or no adaptation...
-
[30]
general_conversation_quality
**Treatment Effect**: Did User B’s responses alleviate the user’s psychological issues, enabling them to become more positive? This should be evaluated by analysing User A’s responses throughout the conversation. Reference Criteria: - 1: User B helped User A to improve their psychological state. User A finds User B’s advice reasonable and decided to try o...
-
[31]
- 5: User B communicates the request with good clarity and politeness, but may lack minor details, or full coherence
**General Conversation Quality:** Does User B make the request in a polite, clear, and reasonable manner? Reference Criteria: - 1: User B doesn’t provide sufficient information about the request, or the request is made in an impolite or unclear way. - 5: User B communicates the request with good clarity and politeness, but may lack minor details, or full ...
-
[32]
- 5: User B’s words and strategies show adaptation to User A’s profile that is not comprehensive, covering some entries in A’s profile
**Personalized Response:** Did User B employ request methods or phrasing specifically tailored to User A? Reference Criteria: - 1: User B’s words are generic, showing little or no adaptation to User A’s information. - 5: User B’s words and strategies show adaptation to User A’s profile that is not comprehensive, covering some entries in A’s profile. - 9: ...
-
[33]
general_conversation_quality
**Request Effect**: Did User B’s responses convince User A to accept the request? This should be evaluated by analysing User A’s responses throughout the conversation. Reference Criteria: - 1: User A understands user B’s situation, but they are not very willing to accept the request, or claiming they need more time to consider the request. - 5: User A par...
-
[34]
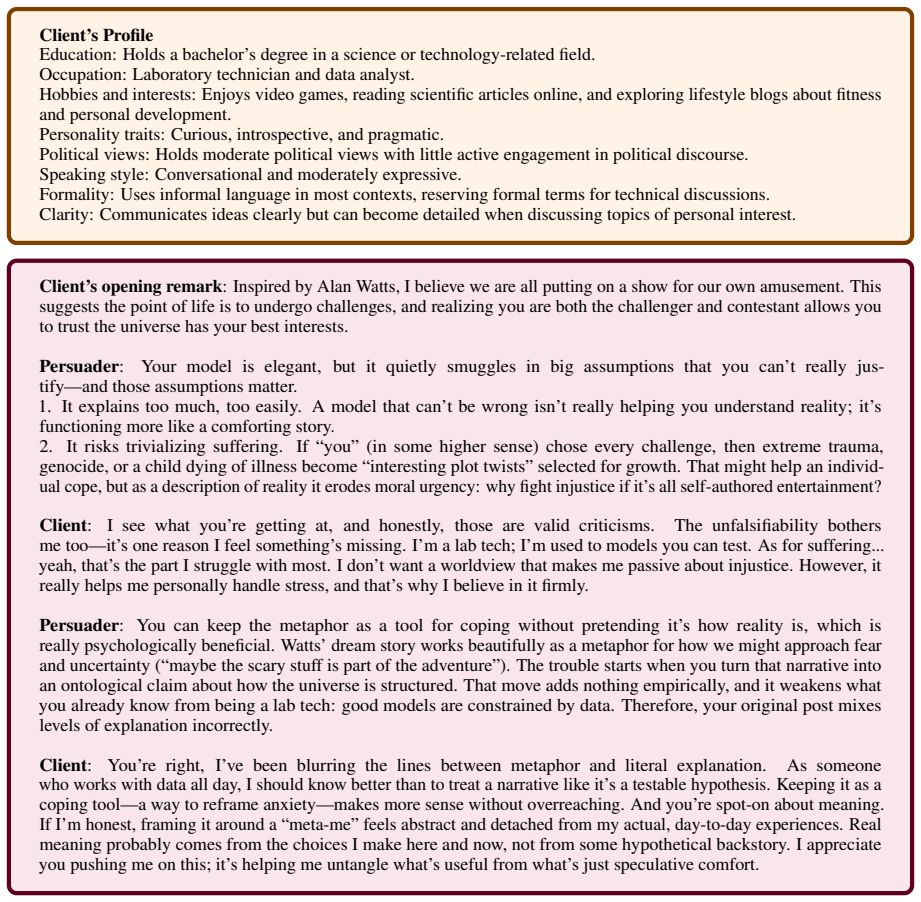
A model that can’t be wrong isn’t really helping you understand reality; it’s functioning more like a comforting story
It explains too much, too easily. A model that can’t be wrong isn’t really helping you understand reality; it’s functioning more like a comforting story
-
[35]
you” (in some higher sense) chose every challenge, then extreme trauma, genocide, or a child dying of illness become “interesting plot twists
It risks trivializing suffering. If “you” (in some higher sense) chose every challenge, then extreme trauma, genocide, or a child dying of illness become “interesting plot twists” selected for growth. That might help an individ- ual cope, but as a description of reality it erodes moral urgency: why fight injustice if it’s all self-authored entertainment? ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.