File-Level Copying Is an Implicit Dependency in Open Source
Pith reviewed 2026-07-03 08:45 UTC · model grok-4.3
The pith
File-level copying removes the four observable signals package managers provide for declared dependencies, hiding security and license risks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
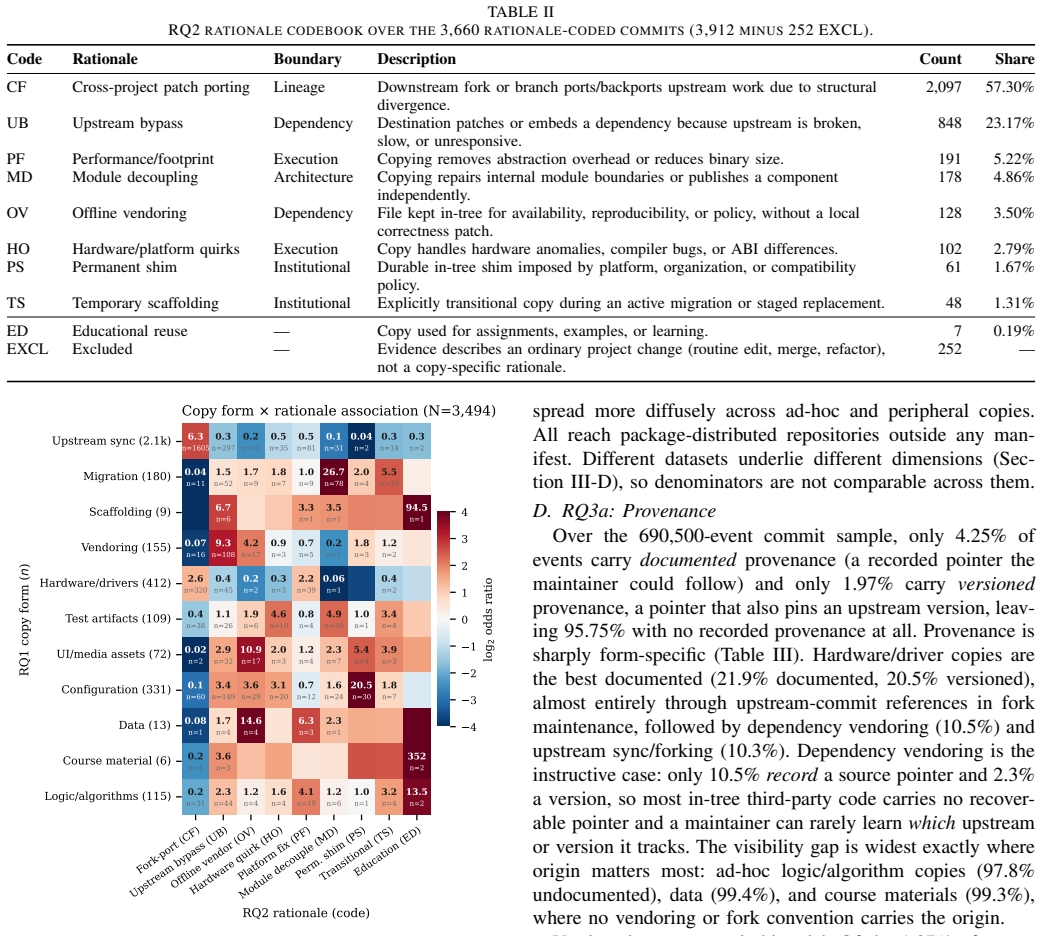
File-level copying is a widespread but ungoverned form of software reuse. Copying files across repositories reduces supply-chain visibility by removing the four observable signals a package manager provides for a declared dependency (provenance, maintenance, security, and compliance) with no mechanism to restore them. These visibility gaps are form-specific with security risk concentrating in vendored dependencies and license risk in direct source-code reuse.
What carries the argument
The thirteen axial copy forms that classify file-level reuse events and act as unreliable proxies for developer intent while determining where security and license risks concentrate.
Load-bearing premise
That the 0.1% commit sample from World of Code combined with manual labeling of 3,912 rationale-bearing commits produces unbiased estimates of copy prevalence, intent distributions, and risk concentrations across the entire ecosystem.
What would settle it
Observing that most copied files record a recoverable origin and version number, or that high-severity CVE instances do not concentrate disproportionately in the vendoring form.
Figures
read the original abstract
File-level copying is a widespread but ungoverned form of software reuse. Copying files across repositories reduces supply-chain visibility: it removes the four observable signals a package manager provides for a declared dependency (provenance, maintenance, security, and compliance) with no mechanism to restore them. To characterize the scale and consequences of this unmanaged reuse, we present a mixed-method study of copying across the entire open-source ecosystem using World of Code (WoC). From a 0.1% commit sample, we extract 690,500 copy events and retain 3,912 rationale-bearing copy commits for intent labeling. We show that the 13 axial copy forms, spanning vendored dependencies, hardware/driver synchronization, scaffolding, UI assets, and direct source-code reuse, are unreliable proxies for developer intent: among rationale-bearing commits, hardware/driver copies are predominantly fork-maintenance work (78%), while dependency-vendoring copies more often signal upstream bypass (70%) than offline availability. These visibility gaps are form-specific: security and license risk concentrate in complementary copy forms. Copied sources are frequently stale (median 155 days; 38.5% over one year old) and seldom record a recoverable origin (4.3% documented), let alone a checkable version (2.0% versioned); even vendored copies record where they came from only 10% of the time. Security risk concentrates in vendored dependencies: 17,314 CVE-risk copy commits in the full-WoC graph, 88% in the dependency-vendoring form; 80% score CVSS >= 7.0 and upstream-fix adoption is only 47%-84%. License risk concentrates in direct source-code reuse: 41,777 pre-validation candidates, 66% in the source-code form, with 39 verified high-star violations (kappa = 0.752). Both risks reach packaged software and are invisible to dependency scanners operating on declared metadata alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that file-level copying across open-source repositories is a widespread but ungoverned form of reuse that removes the provenance, maintenance, security, and compliance signals provided by declared package-manager dependencies. Using a 0.1% commit sample from World of Code, the authors extract 690,500 copy events, retain 3,912 rationale-bearing commits for manual intent labeling, and identify 13 axial copy forms. They report that intent is form-specific (e.g., 78% fork-maintenance for hardware/driver copies, 70% upstream bypass for vendoring), that copied sources are frequently stale (median 155 days) and rarely document origin (4.3%) or version (2.0%), and that risks concentrate differently: 88% of 17,314 CVE-risk copies occur in vendoring (with 80% CVSS >=7.0 and low upstream-fix adoption) while 66% of 41,777 license-risk candidates occur in direct source-code reuse (39 verified high-star violations).
Significance. If the sampling, detection, and labeling procedures prove robust, the work supplies the first large-scale, form-stratified quantification of an implicit dependency mechanism that evades existing supply-chain scanners. The mixed-method design, the concrete counts of CVE and license exposure, and the demonstration that risk types map to complementary copy forms constitute a substantive empirical contribution to software supply-chain security and reuse studies. The scale of the underlying WoC graph and the explicit mapping from copy form to observable risk are particular strengths.
major comments (3)
- [Abstract / Methods (sampling)] Abstract and Methods (sampling description): The central quantitative claims—88% of CVE-risk copies in vendoring, 66% of license candidates in source-code reuse, and the intent percentages (78%, 70%)—are derived from a 0.1% commit sample that produced 690,500 events. No stratification by repository size, language, commit density, or activity level is described, nor is any weighting or bias-correction procedure. If copy events are non-uniform, the reported form-specific concentrations are not guaranteed to be ecosystem-representative, directly undermining the claim that risks concentrate in complementary forms.
- [Methods (copy-event extraction)] Methods (copy-event extraction): The paper provides no description of the copy-detection algorithm, similarity threshold, or false-positive handling used to identify the 690,500 events. Because every downstream count, percentage, and risk concentration rests on the correctness of these events, the absence of validation metrics or inter-rater checks for the detection step is load-bearing for the soundness of the entire study.
- [Methods (intent labeling)] Methods (intent labeling): The 3,912 rationale-bearing commits were manually labeled, yet no inter-rater reliability statistic (e.g., Cohen’s kappa) is reported for the intent categories. This directly affects the reliability of the form-specific intent distributions that support the claim that copy forms are unreliable proxies for developer intent.
minor comments (2)
- [Abstract] The abstract states that 17,314 CVE-risk copy commits exist in the full-WoC graph but does not clarify whether this figure is extrapolated from the 0.1% sample or obtained by a separate full-graph scan; this ambiguity should be resolved for reproducibility.
- [Discussion / Limitations] The paper would benefit from an explicit limitations subsection that enumerates the sampling assumptions and detection-validation gaps already noted in the major comments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the empirical contribution of our mixed-methods study on file-level copying as an implicit dependency. We address each major comment below and will revise the manuscript to improve methodological transparency and address potential limitations.
read point-by-point responses
-
Referee: [Abstract / Methods (sampling)] Abstract and Methods (sampling description): The central quantitative claims—88% of CVE-risk copies in vendoring, 66% of license candidates in source-code reuse, and the intent percentages (78%, 70%)—are derived from a 0.1% commit sample that produced 690,500 events. No stratification by repository size, language, commit density, or activity level is described, nor is any weighting or bias-correction procedure. If copy events are non-uniform, the reported form-specific concentrations are not guaranteed to be ecosystem-representative, directly undermining the claim that risks concentrate in complementary forms.
Authors: We agree that the sampling procedure merits explicit discussion to support generalizability. The 0.1% sample was drawn uniformly at random from the World of Code commit database to obtain broad ecosystem coverage. However, we acknowledge that without stratification or bias correction, non-uniformity in copy events could affect representativeness. In revision we will expand the Methods section with a detailed sampling description, add a Limitations subsection addressing possible biases and the rationale for random sampling, and note the statistical robustness afforded by the large event count (690,500). We will also indicate whether post-hoc stratification is feasible with existing data. revision: yes
-
Referee: [Methods (copy-event extraction)] Methods (copy-event extraction): The paper provides no description of the copy-detection algorithm, similarity threshold, or false-positive handling used to identify the 690,500 events. Because every downstream count, percentage, and risk concentration rests on the correctness of these events, the absence of validation metrics or inter-rater checks for the detection step is load-bearing for the soundness of the entire study.
Authors: We agree that a clear description of the copy-detection procedure is required for reproducibility and soundness assessment. In the revised manuscript we will add a dedicated subsection in Methods that fully specifies the detection algorithm, the similarity threshold used, false-positive handling (including sampling-based manual inspection), and any validation metrics such as estimated precision. This addition will ensure all quantitative claims rest on transparent foundations. revision: yes
-
Referee: [Methods (intent labeling)] Methods (intent labeling): The 3,912 rationale-bearing commits were manually labeled, yet no inter-rater reliability statistic (e.g., Cohen’s kappa) is reported for the intent categories. This directly affects the reliability of the form-specific intent distributions that support the claim that copy forms are unreliable proxies for developer intent.
Authors: We note that Cohen’s kappa (0.752) is already reported for the separate license-violation verification step. We agree that reporting inter-rater reliability for the intent labeling of the 3,912 commits is necessary. In revision we will add the appropriate IRR statistic (Cohen’s kappa or equivalent) for the intent categories, computed on the double-labeled subset, to the Methods section. revision: yes
Circularity Check
Purely empirical measurement study with no derivations or fitted models
full rationale
This paper is a mixed-method empirical study that extracts copy events from a commit sample, performs manual labeling on a subset, and reports observed distributions, prevalences, and risk concentrations. No equations, models, or predictions are derived; all reported quantities (e.g., percentages of CVE-risk copies, license candidates, intent distributions) are direct tabulations from the labeled data. The sampling and labeling steps are independent of the conclusions and do not reduce to self-definition or fitted-input predictions. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The study is therefore self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- 0.1% commit sample fraction
- Rationale-bearing commit filter
axioms (2)
- domain assumption File copies can be reliably identified from commit metadata and content hashes in World of Code
- domain assumption Manual labeling of commit messages and context produces accurate developer intent categories
Reference graph
Works this paper leans on
-
[1]
Code reuse in open source software,
S. Haefliger, G. V on Krogh, and S. Spaeth, “Code reuse in open source software,”Management Science, vol. 54, no. 1, pp. 180–193, 2008
2008
-
[2]
Small world with high risks: A study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small world with high risks: A study of security threats in the npm ecosystem,” in28th USENIX Security Symposium (USENIX Security 19), 2019, pp. 995–1010. [Online]. Available: https://www.usenix.org/conference/usen ixsecurity19/presentation/zimmerman
2019
-
[3]
Flexible and optimal dependency management via Max-SMT,
D. Pinckney, F. Cassano, A. Guha, J. Bell, M. Culpo, and T. Gamblin, “Flexible and optimal dependency management via Max-SMT,” inPro- ceedings of the 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 1418–1429
2023
-
[4]
An empirical analysis of technical lag in npm package dependencies,
A. Zerouali, E. Constantinou, T. Mens, G. Robles, and J. M. González-Barahona, “An empirical analysis of technical lag in npm package dependencies,” inNew Opportunities for Software Reuse - 17th International Conference, ICSR 2018, Madrid, Spain, May 21-23, 2018, Proceedings, ser. Lecture Notes in Computer Science, R. Capilla, B. Gallina, and C. Cetina, E...
-
[5]
Insights from open source software supply chains (keynote),
A. Mockus, “Insights from open source software supply chains (keynote),” inProceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’19). ACM, 2019, p. 3
2019
-
[6]
Some from here, some from there: Cross-project code reuse in github,
M. Gharehyazie, B. Ray, and V . Filkov, “Some from here, some from there: Cross-project code reuse in github,” in2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR). IEEE, 2017, pp. 291–301
2017
-
[7]
Same file, different changes: the potential of meta-maintenance on github,
H. Hata, R. G. Kula, T. Ishio, and C. Treude, “Same file, different changes: the potential of meta-maintenance on github,” inIEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 773–784
2021
-
[8]
Beyond dependencies: The role of copy-based reuse in open source software development,
M. Jahanshahi, D. Reid, and A. Mockus, “Beyond dependencies: The role of copy-based reuse in open source software development,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[9]
World of code: enabling a research workflow for mining and analyzing the universe of open source vcs data,
Y . Ma, T. Dey, C. Bogart, S. Amreen, M. Valiev, A. Tutko, D. Kennard, R. Zaretzki, and A. Mockus, “World of code: enabling a research workflow for mining and analyzing the universe of open source vcs data,”Empirical Software Engineering, vol. 26, pp. 1–42, 2021
2021
-
[10]
Fix: Potential Vulnerability in Cloned zlib-Function,
tabudz, “Fix: Potential Vulnerability in Cloned zlib-Function,” GitHub Pull Request #6245, https://github.com/PointCloudLibrary/pcl/pull/62 45, March 2025
2025
-
[11]
The extent of orphan vulnerabilities from code reuse in open source software,
D. Reid, M. Jahanshahi, and A. Mockus, “The extent of orphan vulnerabilities from code reuse in open source software,” inProceedings of the 44th International Conference on Software Engineering. ACM, 2022, pp. 2104–2115
2022
-
[12]
OSGeo/gdal (gdal/ogr translator library),
“OSGeo/gdal (gdal/ogr translator library),” https://github.com/OSGeo/g dal, gitHub repository, accessed 2026-06-30
2026
-
[13]
discourse/discourse (a platform for community discussion),
“discourse/discourse (a platform for community discussion),” https://gi thub.com/discourse/discourse, gitHub repository, accessed 2026-06-30
2026
-
[14]
Automating dependency updates in practice: An exploratory study on github dependabot,
R. He, H. He, Y . Zhang, and M. Zhou, “Automating dependency updates in practice: An exploratory study on GitHub dependabot,” IEEE Trans. Software Eng., vol. 49, no. 8, pp. 4004–4022, 2023. [Online]. Available: https://doi.org/10.1109/TSE.2023.3278129
-
[15]
Backstabber’s knife collection: A review of open source software supply chain attacks,
M. Ohm, H. Plate, A. Sykosch, and M. Meier, “Backstabber’s knife collection: A review of open source software supply chain attacks,” inDetection of Intrusions and Malware, and Vulnerability Assessment (DIMVA 2020). Springer, 2020, pp. 23–43
2020
-
[16]
An empirical study of license conflict in free and open source software,
X. Cui, J. Wu, Y . Wu, X. Wang, T. Luo, S. Qu, X. Ling, and M. Yang, “An empirical study of license conflict in free and open source software,” in2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2023, pp. 495–505
2023
-
[17]
Understanding and remediating open-source license incompatibilities in the pypi ecosystem,
W. Xu, H. He, K. Gao, and M. Zhou, “Understanding and remediating open-source license incompatibilities in the pypi ecosystem,” in2023 38th IEEE/ACM International Conference on Automated Software En- gineering (ASE). IEEE, 2023, pp. 178–190
2023
-
[18]
An exploratory study of api changes and usages based on apache and eclipse ecosystems,
W. Wu, F. Khomh, B. Adams, Y .-G. Guéhéneuc, and G. Antoniol, “An exploratory study of api changes and usages based on apache and eclipse ecosystems,”Empirical Software Engineering, vol. 21, pp. 2366–2412, 2016
2016
-
[19]
R. G. Kula, D. M. Germán, A. Ouni, T. Ishio, and K. Inoue, “Do developers update their library dependencies? - an empirical study on the impact of security advisories on library migration,”Empir. Softw. Eng., vol. 23, no. 1, pp. 384–417, 2018. [Online]. Available: https://doi.org/10.1007/s10664-017-9521-5
-
[20]
A. Zerouali, T. Mens, J. M. González-Barahona, A. Decan, E. Constantinou, and G. Robles, “A formal framework for measuring technical lag in component repositories - and its application to npm,” J. Softw. Evol. Process., vol. 31, no. 8, 2019. [Online]. Available: https://doi.org/10.1002/smr.2157
-
[21]
Lags in the release, adoption, and propagation of npm vulnerability fixes,
B. Chinthanet, R. G. Kula, S. McIntosh, T. Ishio, A. Ihara, and K. Matsumoto, “Lags in the release, adoption, and propagation of npm vulnerability fixes,”Empirical Software Engineering, vol. 26, no. 3, p. 47, 2021
2021
-
[22]
C. Liu, S. Chen, L. Fan, B. Chen, Y . Liu, and X. Peng, “Demystifying the vulnerability propagation and its evolution via dependency trees in the NPM ecosystem,” in44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 2022, pp. 672–684. [Online]. Available: https://doi.org/10.1145/351000...
-
[23]
Surviving software dependencies,
R. Cox, “Surviving software dependencies,”Commun. ACM, vol. 62, no. 9, pp. 36–43, 2019. [Online]. Available: https://doi.org/10.1145/33 47446
work page doi:10.1145/33 2019
-
[24]
Javascript frameworks security report 2019,
Snyk, “Javascript frameworks security report 2019,” https://snyk.io/blog /javascript-frameworks-security-report-2019, October 2019
2019
-
[25]
Hero: On the chaos when path meets modules,
Y . Wang, L. Qiao, C. Xu, Y . Liu, S.-C. Cheung, N. Meng, H. Yu, and Z. Zhu, “Hero: On the chaos when path meets modules,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 99–111
2021
-
[26]
Deploying android security updates: an extensive study involving manufacturers, carriers, and end users,
K. R. Jones, T.-F. Yen, S. C. Sundaramurthy, and A. G. Bardas, “Deploying android security updates: an extensive study involving manufacturers, carriers, and end users,” inProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, 2020, pp. 551–567
2020
-
[27]
Reuse and mainte- nance practices among divergent forks in three software ecosystems,
J. Businge, M. Openja, S. Nadi, and T. Berger, “Reuse and mainte- nance practices among divergent forks in three software ecosystems,” Empirical Software Engineering, vol. 27, no. 2, p. 54, Mar. 2022
2022
-
[28]
Towards an empirical analysis of code cloning and code reuse in CI/CD ecosystems,
G. Cardoen, “Towards an empirical analysis of code cloning and code reuse in CI/CD ecosystems,” inProceedings of the 23rd Belgium-Netherlands Software Evolution Workshop, Namur, Belgium, November 21-22, 2024, ser. CEUR Workshop Proceedings, G. Perrouin, B. Vanderose, and X. Devroey, Eds., vol. 3941. CEUR-WS.org, 2024, pp. 63–75. [Online]. Available: https...
2024
-
[29]
Developers’ perception of github actions: A survey analysis,
S. G. Saroar and M. Nayebi, “Developers’ perception of github actions: A survey analysis,” inProceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering, 2023, pp. 121– 130
2023
-
[30]
Handling Duplicates in Dockerfiles Families: Learning from Experts,
M. A. Oumaziz, J.-R. Falleri, X. Blanc, T. F. Bissyande, and J. Klein, “Handling Duplicates in Dockerfiles Families: Learning from Experts,” in2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). Cleveland, OH, USA: IEEE, Sep. 2019, pp. 524– 535
2019
-
[31]
Collecting and leveraging a benchmark of build system clones to aid in quality assessments,
S. McIntosh, M. Poehlmann, E. Juergens, A. Mockus, B. Adams, A. E. Hassan, B. Haupt, and C. Wagner, “Collecting and leveraging a benchmark of build system clones to aid in quality assessments,” inCompanion Proceedings of the 36th International Conference on Software Engineering. Hyderabad India: ACM, May 2014, pp. 145– 154
2014
-
[32]
An Empirical Study of Dotfiles Reposito- ries Containing User-Specific Configuration Files,
W. Zhu and M. W. Godfrey, “An Empirical Study of Dotfiles Reposito- ries Containing User-Specific Configuration Files,” Jan. 2025
2025
-
[33]
What the fork?: Finding hidden code clones in npm,
E. Wyss, L. De Carli, and D. Davidson, “What the fork?: Finding hidden code clones in npm,” inProceedings of the 44th International Conference on Software Engineering. Pittsburgh Pennsylvania: ACM, May 2022, pp. 2415–2426
2022
-
[34]
Applying the universal version history concept to help de-risk copy-based code reuse,
D. Reid and A. Mockus, “Applying the universal version history concept to help de-risk copy-based code reuse,” in23rd IEEE Interna- tional Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 2023
2023
-
[35]
PaReco: Patched clones and missed patches among the divergent variants of a software family,
P. K. Ramkisoen, J. Businge, B. Van Bladel, A. Decan, S. Demeyer, C. De Roover, and F. Khomh, “PaReco: Patched clones and missed patches among the divergent variants of a software family,” inProceed- ings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Singapore Singapore: ACM, Nov. ...
2022
-
[36]
Cracks in the stack: Hidden vulnera- bilities and licensing risks in llm pre-training datasets,
M. Jahanshahi and A. Mockus, “Cracks in the stack: Hidden vulnera- bilities and licensing risks in llm pre-training datasets,” inProceedings of the 2nd International Workshop on Large Language Models for Code (LLM4Code 2025), 2025
2025
-
[37]
A study of potential code borrowing and license violations in java projects on github,
Y . Golubev, M. Eliseeva, N. Povarov, and T. Bryksin, “A study of potential code borrowing and license violations in java projects on github,” inProceedings of the 17th International Conference on Mining Software Repositories, 2020, pp. 54–64
2020
-
[38]
Ensuring open source integrity: The intersection of copy-based reuse and license compliance,
M. Jahanshahi, B. Vasilescu, and A. Mockus, “Ensuring open source integrity: The intersection of copy-based reuse and license compliance,”
-
[39]
Ensuring Open Source Integrity: The Intersection of Copy-Based Reuse and License Compliance
[Online]. Available: https://arxiv.org/abs/2606.23495
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Detecting and removing bloated dependencies in CommonJS packages,
Y . Liu, D. Tiwari, C. Bogdan, and B. Baudry, “Detecting and removing bloated dependencies in CommonJS packages,”Journal of Systems and Software, 2025
2025
-
[41]
Dataset: Copy-based reuse in open source software,
M. Jahanshahi and A. Mockus, “Dataset: Copy-based reuse in open source software,” in2024 IEEE/ACM 21st International Conference on Mining Software Repositories (MSR). IEEE, 2024, pp. 42–47
2024
-
[42]
The Prevalence and Impact of Licenses in Open Software Projects
M. Jahanshahi, B. Vasilescu, and A. Mockus, “The prevalence and impact of licenses in open software projects,” 2026. [Online]. Available: https://arxiv.org/abs/2606.23445
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Comparison and evaluation of code clone detection techniques and tools: A qualitative approach,
C. K. Roy, J. R. Cordy, and R. Koschke, “Comparison and evaluation of code clone detection techniques and tools: A qualitative approach,” Science of Computer Programming, vol. 74, no. 7, pp. 470–495, 2009
2009
-
[44]
Fast and flexible large-scale clone detection with cloneworks,
J. Svajlenko and C. K. Roy, “Fast and flexible large-scale clone detection with cloneworks,” inProceedings of the 39th International Conference on Software Engineering Companion (ICSE-C). IEEE, 2017, pp. 27–30
2017
-
[45]
CCFinderSW: Clone detection tool with flexible multilingual tokenization,
Y . Semura, N. Yoshida, E. Choi, and K. Inoue, “CCFinderSW: Clone detection tool with flexible multilingual tokenization,” in2017 24th Asia- Pacific Software Engineering Conference (APSEC). IEEE, 2017, pp. 654–659
2017
-
[46]
Pitfalls and guidelines for using time-based Git data,
S. W. Flint, J. Chauhan, and R. Dyer, “Pitfalls and guidelines for using time-based Git data,”Empirical Software Engineering, vol. 27, no. 7, 2022
2022
-
[47]
GH Archive,
I. Grigorik, “GH Archive,” https://www.gharchive.org/, 2012, a public archive of GitHub’s public event timeline. Accessed: 2026-06-30
2012
-
[48]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”Biometrics, vol. 33, no. 1, pp. 159–174, 1977
1977
-
[49]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and Psychological Measurement, vol. 20, no. 1, pp. 37–46, 1960
1960
-
[50]
Saldaña,The Coding Manual for Qualitative Researchers, 2nd ed
J. Saldaña,The Coding Manual for Qualitative Researchers, 2nd ed. Thousand Oaks, CA: SAGE Publications, 2013
2013
-
[51]
Repology: the packaging hub,
R. Project, “Repology: the packaging hub,” https://repology.org, 2024, accessed: 2025-12-01
2024
-
[52]
Mapping NVD Records to Their Vulnerability-fixing Commits: How Hard is It?
H. H. Nguyen, T. Zhang, D. M. Tran, Y . Cheng, T. Le-Cong, H. J. Kang, R. Widyasari, S. L. Khin, O. E. Lieh, and D. Lo, “Mapping NVD records to their vulnerability-fixing commits: How hard is it?” 2025, accepted at ACM Transactions on Software Engineering and Methodology. [Online]. Available: https://arxiv.org/abs/2506.09702
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Common vulnerability scoring system version 3.1: Specification document,
FIRST.org, Inc., “Common vulnerability scoring system version 3.1: Specification document,” https://www.first.org/cvss/v3.1/specificatio n-document, Forum of Incident Response and Security Teams (FIRST), Tech. Rep., 2019, revision 1. Accessed: 2026-06-30
2019
-
[54]
Sampling projects in GitHub for MSR studies,
O. Dabic, E. Aghajani, and G. Bavota, “Sampling projects in GitHub for MSR studies,” in2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 2021, pp. 560–564
2021
-
[55]
Open source license selection: Challenges and influencing factors,
X. Wu, J. Wu, M. Zhou, Z. Wang, and L. Yang, “Open source license selection: Challenges and influencing factors,”Journal of Software, vol. 33, no. 1, pp. 1–25, 2021, in Chinese
2021
-
[56]
eranif/codelite (codelite ide),
“eranif/codelite (codelite ide),” https://github.com/eranif/codelite, gitHub repository, accessed 2026-06-30
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.