The Latent Bridge: A Continuous Slow-Fast Channel for Real-Time Game Agents
Pith reviewed 2026-06-26 00:07 UTC · model grok-4.3
The pith
A learned continuous latent bridge between slow reasoning and fast reactive VLMs matches or exceeds text bridging for real-time game agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
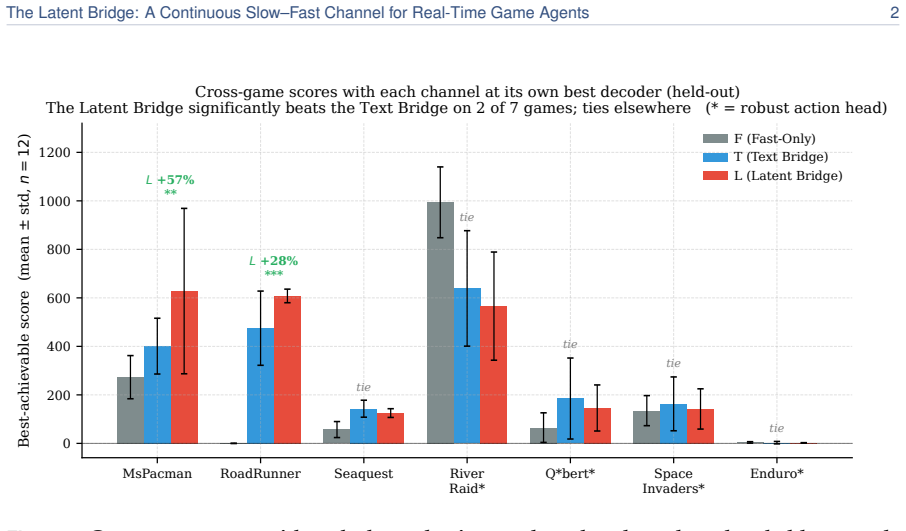
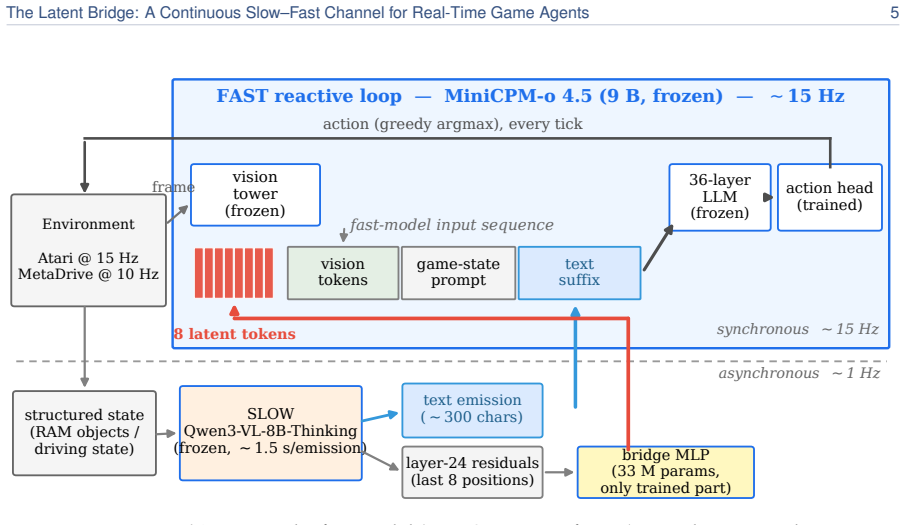
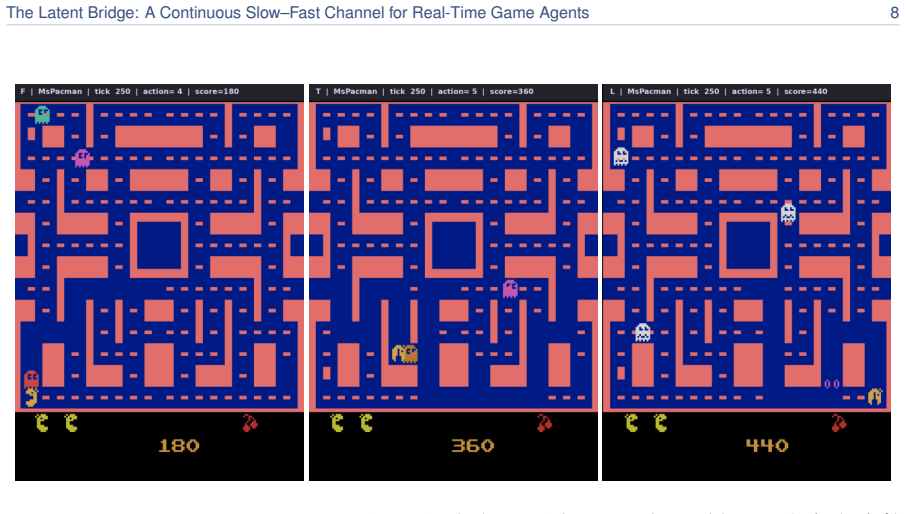
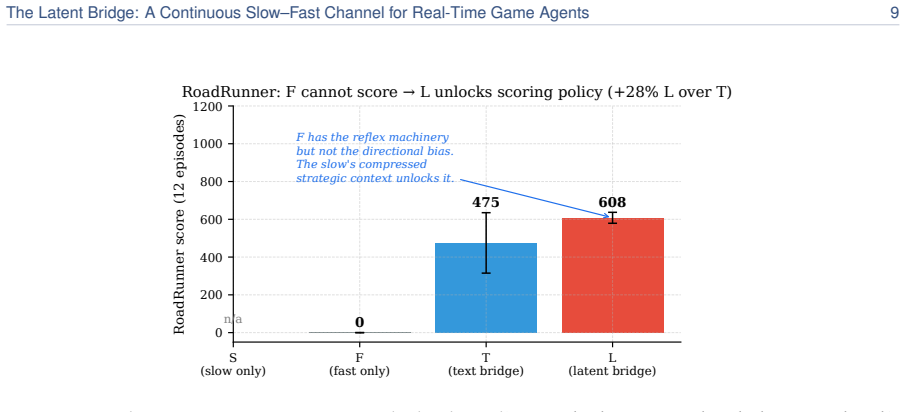
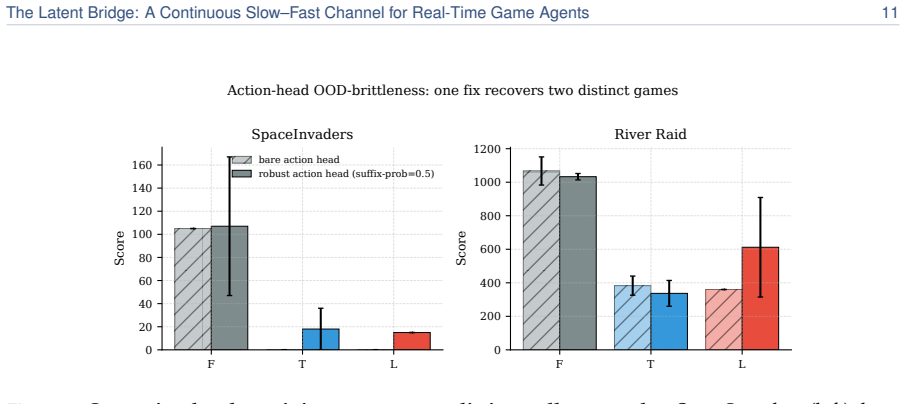
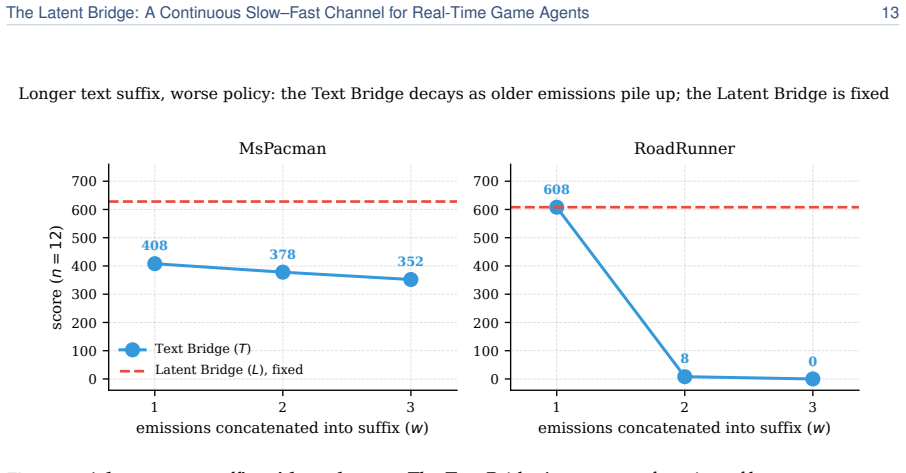
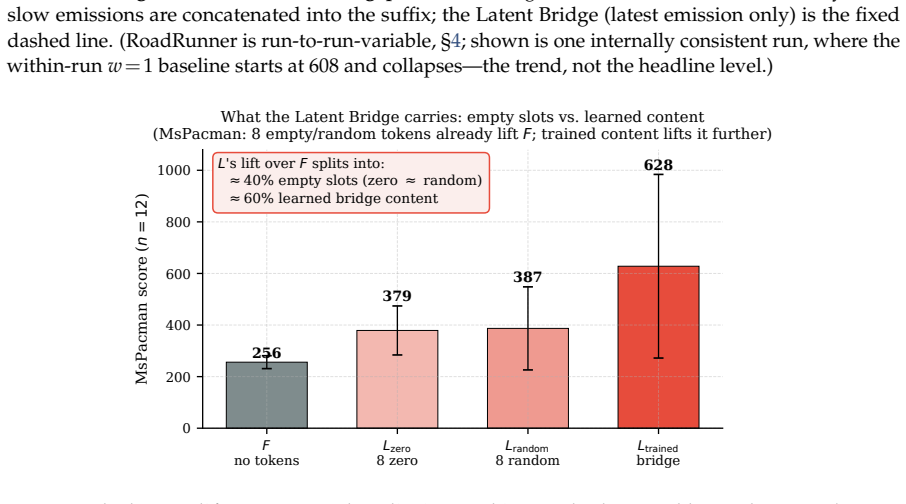
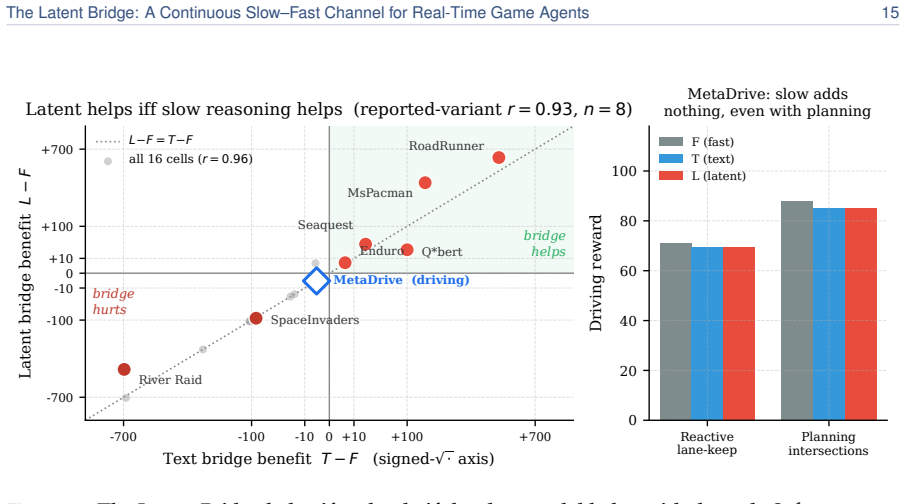
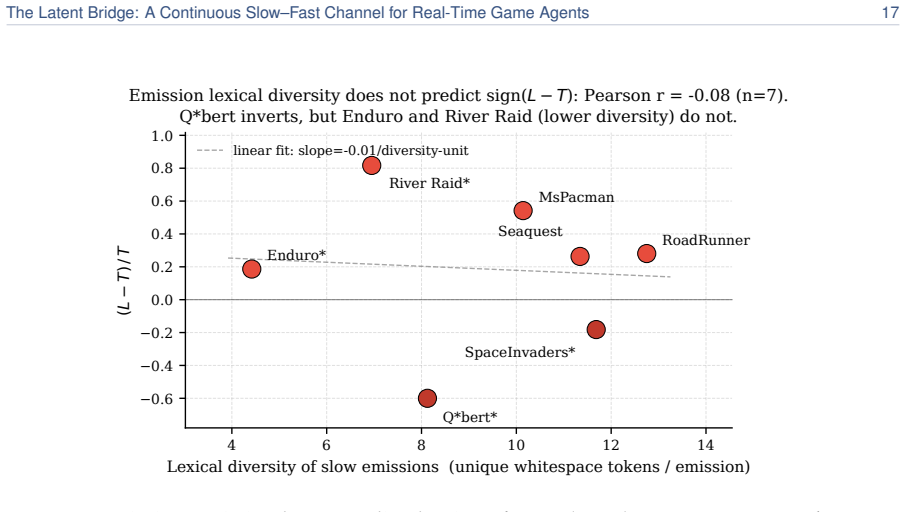
We introduce the Latent Bridge, a learned continuous channel that projects residuals from a frozen slow reasoning VLM into the input embedding space of a frozen fast reactive VLM in a LLaVA-style manner. On 7 Atari games and MetaDrive, with the action decoder tuned per channel on held-out seeds, the Latent Bridge matches or beats the Text Bridge in every domain, delivering substantial gains (+57% in MsPacman, +28% in RoadRunner) exactly when the slow model outperforms the fast one; the gains of the two bridges over Fast-Only correlate at r=0.93. Combining both channels interferes destructively, and the bridge is inert in MetaDrive where the Text Bridge adds no value.
What carries the argument
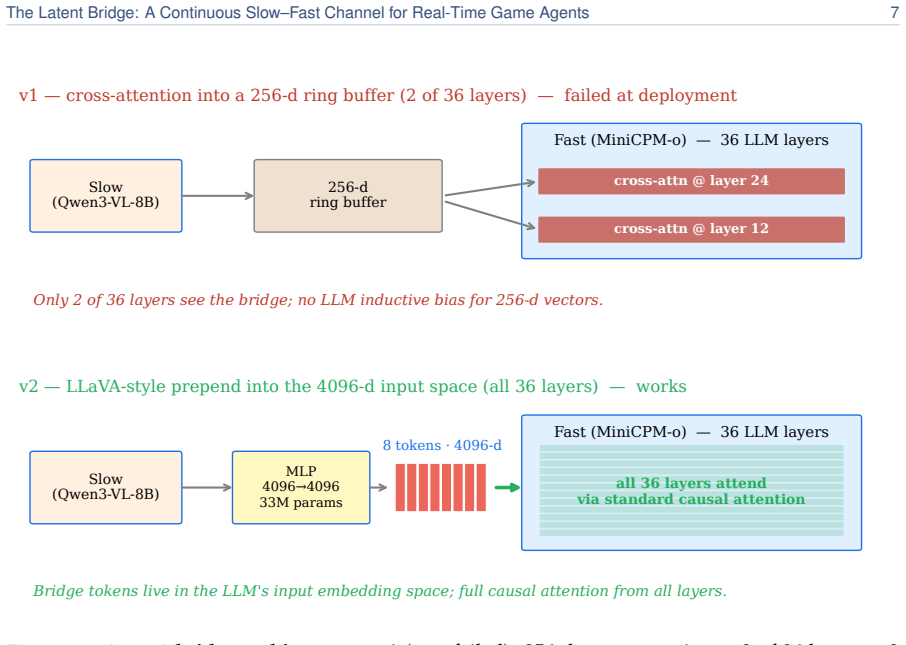
The Latent Bridge: a single learned continuous projection of the slow model's residuals into the fast model's embedding space, kept as the only trainable component between two frozen matched-scale VLMs.
If this is right
- The bridge helps if and only if the slow reasoning model already outperforms the fast reactive model on the task.
- Using both latent and text channels together produces destructive interference rather than additive benefit.
- The method remains inert in domains such as MetaDrive where text bridging itself adds no value over fast-only.
- Performance differences between the two bridge types are highly predictable from the relative strength of slow versus fast models alone.
Where Pith is reading between the lines
- The same projection technique could be tested in non-game real-time control settings such as robotic manipulation whenever a slow planner and fast executor show complementary strengths.
- Varying the relative scales of the two frozen models while keeping the bridge architecture fixed would test whether scale matching is required for the observed correlation.
- The r=0.93 predictability offers a low-cost way to decide in advance whether adding a bridge is likely to help on a new task without training the full system.
Load-bearing premise
The action decoder can be tuned independently per channel on held-out seeds without introducing bias, and the models' scales are matched so that the bridge is the only variable.
What would settle it
A domain where the slow reasoning model already beats the fast model yet the latent bridge shows no gain over fast-only or breaks the r=0.93 correlation with text-bridge gains.
Figures
read the original abstract
A real-time agent for general computer use - with games as the most demanding case - must act within tens of milliseconds while still planning over seconds. These two regimes sit at opposite ends of the latency-quality tradeoff. A reasoning VLM (Qwen3-VL-8B-Thinking) deliberates effectively but requires ~1.5 s per response - far too slow for a 15 Hz control loop. In contrast, a reactive VLM (MiniCPM-o 4.5) acts in milliseconds but underperforms on planning-heavy tasks. We couple two frozen models of matched scale (9B reactive, 8B reasoning), leaving the communication channel as the sole trainable component. The standard coupling is a Text Bridge (T): the slow model writes a suffix the fast model reads. We introduce a learned continuous Latent Bridge (L) that projects the slow model's residuals into the fast model's input-embedding space in a LLaVA-style manner, avoiding any text round-trip; both are compared against Fast-Only (F). On 7 Atari games and a driving domain (MetaDrive), tuning the action decoder per channel on held-out seeds, the Latent Bridge matches or beats the Text Bridge in every domain: it significantly improves two games (MsPacman +57%, RoadRunner +28%) and is a safe drop-in elsewhere. Combining both channels interferes destructively (RoadRunner -96%), so only one should be used. The benefit is highly predictable: the bridge helps if and only if slow reasoning already beats fast reaction (T > F) - the Latent and Text gains over Fast-Only move together at r=0.93. MetaDrive is the controlled negative, where the Latent Bridge is demonstrably inert because the Text Bridge adds no value. We release replay recordings and reproducible pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes coupling a frozen slow reasoning VLM (Qwen3-VL-8B-Thinking, ~1.5s latency) with a fast reactive VLM (MiniCPM-o 4.5, millisecond latency) for real-time game agents via a learned continuous Latent Bridge that projects residuals into the fast model's embedding space. It claims this Latent Bridge matches or beats the Text Bridge (slow model writes text suffix for fast model) on 7 Atari games plus MetaDrive, with significant gains in MsPacman (+57%) and RoadRunner (+28%), while the benefit is predictable (r=0.93) from whether the slow model already outperforms the fast one (T > F); MetaDrive serves as a negative control where the bridge adds no value. The communication channel is presented as the sole trainable component, with the action decoder tuned per channel on held-out seeds; both are compared to Fast-Only, and combining channels is destructive.
Significance. If the attribution of gains to the bridge holds after controlling for decoder adaptation, the work would offer a practical method for low-latency integration of slow and fast VLMs in real-time control without text round-trips, with the r=0.93 predictability providing a clear, falsifiable condition for when the bridge helps. The release of replay recordings and reproducible pipelines strengthens verifiability.
major comments (1)
- [Abstract] Abstract: the claim that 'the communication channel [is] the sole trainable component' is undermined by the protocol of 'tuning the action decoder per channel on held-out seeds.' This allows each decoder to adapt to the distinct output statistics of its upstream bridge (Latent vs. Text), so the reported deltas (+57% MsPacman, +28% RoadRunner) and the r=0.93 correlation cannot be attributed solely to the bridge rather than decoder compensation. The MetaDrive negative control does not resolve the confound because it only tests the case where T ≯ F.
minor comments (1)
- The abstract reports specific performance percentages and a correlation without error bars, number of runs, or mention of statistical tests, making it difficult to assess the reliability of the gains and the r=0.93 value.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying an imprecision in the abstract that affects how the experimental controls are interpreted. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the communication channel [is] the sole trainable component' is undermined by the protocol of 'tuning the action decoder per channel on held-out seeds.' This allows each decoder to adapt to the distinct output statistics of its upstream bridge (Latent vs. Text), so the reported deltas (+57% MsPacman, +28% RoadRunner) and the r=0.93 correlation cannot be attributed solely to the bridge rather than decoder compensation. The MetaDrive negative control does not resolve the confound because it only tests the case where T ≯ F.
Authors: We agree the abstract wording is imprecise and will be revised. The action decoder is a lightweight head tuned per channel on held-out seeds so that each communication method (latent projection, text suffix, or fast-only) receives a decoder matched to its output distribution; this is required for a fair system-level comparison. Because the identical tuning protocol is applied to Latent, Text, and Fast-Only, performance deltas between channels remain attributable to the communication mechanism itself. The r=0.93 correlation between Latent and Text gains over Fast-Only further indicates that gains track the presence of useful slow reasoning rather than decoder-specific compensation. MetaDrive serves as a negative control precisely because T ≯ F there; the fact that L is also inert in that regime is consistent with the bridge transmitting information only when it is beneficial. We will (1) remove the 'sole trainable component' phrasing from the abstract, (2) clarify in the methods that decoder adaptation is a controlled, per-condition step, and (3) add a short discussion of why this protocol does not confound the bridge comparison. revision: yes
Circularity Check
Empirical comparison with observed correlation; no derivation reduces to inputs by construction
full rationale
The paper is an empirical study reporting performance deltas and an r=0.93 correlation computed directly from measured game outcomes across domains. The abstract states the channel is the sole trainable component while describing per-channel decoder tuning on held-out seeds as the evaluation protocol; this is an experimental design choice, not a mathematical reduction where a fitted parameter is renamed as a prediction or where any equation equals its input by construction. No self-citations, uniqueness theorems, or ansatzes are invoked. The result is self-contained against external benchmarks (Atari games, MetaDrive) with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- projection parameters for latent bridge
axioms (1)
- domain assumption The two VLMs are frozen and only the bridge is trained.
invented entities (1)
-
Latent Bridge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do as i can, not as i say: Grounding language in robotic affordances
Michael Ahn, Anthony Brohan, Noah Brown, et al. Do as i can, not as i say: Grounding language in robotic affordances. InCoRL, 2022
2022
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac et al. Flamingo: a visual language model for few-shot learning. In NeurIPS, 2022
2022
-
[3]
AtariARI: Atari annotated RAM interface, 2019
Ankesh Anand, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, and R Devon Hjelm. AtariARI: Atari annotated RAM interface, 2019. https://github.com/ mila-iqia/atari-representation-learning
2019
-
[4]
Introducing Claude Opus 4.5
Anthropic. Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5, 2025. Released November 2025
2025
-
[5]
The arcade learning environment: An evaluation platform for general agents.Journal of Artificial Intelligence Research, 47:253–279, 2013
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Journal of Artificial Intelligence Research, 47:253–279, 2013
2013
-
[6]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InCoRL, 2023. The Latent Bridge: A Continuous Slow–Fast Channel for Real-Time Game Agents 20
2023
-
[7]
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.https://arxiv.org/abs/2501.12948, 2025
Pith/arXiv arXiv 2025
-
[8]
From explicit CoT to implicit CoT: Learning to internalize CoT step by step, 2024
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit CoT to implicit CoT: Learning to internalize CoT step by step, 2024. arXiv:2405.14838
Pith/arXiv arXiv 2024
-
[9]
Gemini Live multimodal real-time api, 2024
Google. Gemini Live multimodal real-time api, 2024. https://ai.google.dev/ gemini-api/docs/live
2024
-
[10]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. InICLR, 2024
2024
-
[11]
Training large language models to reason in a continuous latent space,
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space,
-
[12]
Inner monologue: Embodied reasoning through planning with language models
Wenlong Huang, Fei Xia, Ted Xiao, et al. Inner monologue: Embodied reasoning through planning with language models. InCoRL, 2022
2022
-
[13]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InICLR, 2024
2024
-
[14]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InICML, 2023
2023
-
[15]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InICML, 2023
2023
-
[16]
MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3461–3475, 2023
2023
-
[17]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023
2023
-
[18]
OpenAI o1 system card.https://arxiv.org/abs/2412.16720, 2024
OpenAI. OpenAI o1 system card.https://arxiv.org/abs/2412.16720, 2024
Pith/arXiv arXiv 2024
-
[19]
OpenAI Realtime API, 2024
OpenAI. OpenAI Realtime API, 2024. https://platform.openai.com/docs/guides/ realtime
2024
-
[20]
Introducing GPT-5.2
OpenAI. Introducing GPT-5.2. https://openai.com/index/introducing-gpt-5-2/ ,
-
[21]
Released December 2025
2025
-
[22]
MiniCPM-o 4.5: An omni-modal large language model, 2025
OpenBMB Team. MiniCPM-o 4.5: An omni-modal large language model, 2025. https: //huggingface.co/openbmb/MiniCPM-o-4_5
2025
-
[23]
Pine AI: The most natural human-computer interface is your voice
Pine AI. Pine AI: The most natural human-computer interface is your voice. https://www.19pine.ai/blog/ pine-ai-the-most-natural-human-computer-interface-is-your-voice, 2026. The Latent Bridge: A Continuous Slow–Fast Channel for Real-Time Game Agents 21
2026
-
[24]
Qwen3-VL-8B-Thinking, 2025
Qwen Team. Qwen3-VL-8B-Thinking, 2025. https://huggingface.co/Qwen/ Qwen3-VL-8B-Thinking
2025
-
[25]
Stable-Baselines3 atari zoo, 2021.https://huggingface.co/sb3
Antonin Raffin. Stable-Baselines3 atari zoo, 2021.https://huggingface.co/sb3
2021
-
[26]
Mixture-of-depths: Dynamically allocat- ing compute in transformer-based language models, 2024
David Raposo, Sam Ritter, Blake Richards, et al. Mixture-of-depths: Dynamically allocat- ing compute in transformer-based language models, 2024. arXiv:2404.02258
Pith/arXiv arXiv 2024
-
[27]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[28]
Anthropic releases Opus 4.8 with new ‘dy- namic workflow’ tool
TechCrunch. Anthropic releases Opus 4.8 with new ‘dy- namic workflow’ tool. https://techcrunch.com/2026/05/28/ anthropic-releases-opus-4-8-with-new-dynamic-workflow-tool/ , 2026. Released 28 May 2026, 41 days after Opus 4.7
2026
-
[29]
Interaction models: A scalable approach to human–AI collabora- tion, 2026.https://thinkingmachines.ai/blog/interaction-models/
Thinking Machines Lab. Interaction models: A scalable approach to human–AI collabora- tion, 2026.https://thinkingmachines.ai/blog/interaction-models/
2026
-
[30]
Step-audio-r1 technical report
Fei Tian et al. Step-audio-r1 technical report. https://arxiv.org/abs/2511.15848, 2025
arXiv 2025
-
[31]
Grok voice think fast 1.0
xAI. Grok voice think fast 1.0. https://x.ai/news/grok-voice-think-fast-1 , 2026. Real-time voice model with background (asynchronous) reasoning
2026
-
[32]
τ-bench: A bench- mark for tool-agent-user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A bench- mark for tool-agent-user interaction in real-world domains. https://arxiv.org/abs/ 2406.12045, 2024
Pith/arXiv arXiv 2024
-
[33]
strategic-guidance
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-STaR: Language models can teach themselves to think before speaking. InCOLM, 2024. A Full results table Both bare-action-head and robust-action-head reported for every game, n= 12 per cell, under greedy decoding; the headline (§4.1, Table 1) instead uses the b...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.