TimeProVe: Propose, then Verify for Efficient Long Video Temporal Reasoning in Activities of Daily Living
Pith reviewed 2026-06-26 18:19 UTC · model grok-4.3
The pith
TimeProVe generates candidate answers and evidence windows with lightweight modules before verifying them with a VLM, raising accuracy on long ADL videos while cutting VLM calls by 75 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
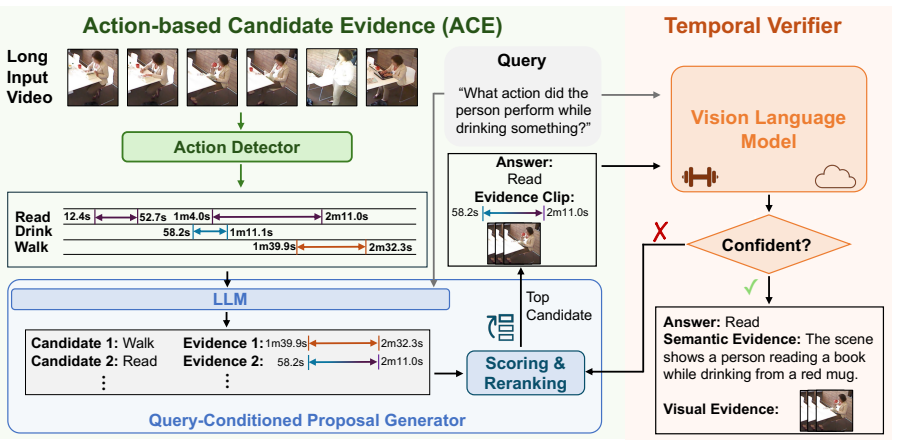
TimeProVe is a cost-efficient hybrid framework for temporally grounded reasoning in long videos. It employs the Action-based Candidate Evidence (ACE) module to convert temporally localized actions into query-conditioned candidate answers and supporting evidence windows through lightweight LLM reasoning, then invokes an expensive VLM only for targeted verification of those hypotheses. On the introduced OpenTSUBench benchmark for ADL scenarios, TimeProVe outperforms the strongest baseline by 7.3 percent while reducing VLM calls by 75 percent and inference cost by 93 percent. Without explicit temporal grounding training it remains competitive on Charades-STA and reaches state-of-the-art when pa
What carries the argument
The Action-based Candidate Evidence (ACE) module, which converts temporally localized actions into query-conditioned candidate answers and supporting evidence windows through lightweight LLM reasoning.
If this is right
- Outperforms the strongest baseline on OpenTSUBench by 7.3 percent.
- Reduces VLM calls by 75 percent and inference cost by 93 percent.
- Achieves competitive performance on Charades-STA without explicit temporal grounding training.
- Reaches state-of-the-art results on Charades-STA when enhanced with grounding VLMs.
- Enables practical temporally grounded reasoning over hours-long untrimmed videos of daily activities.
Where Pith is reading between the lines
- The propose-then-verify split could transfer to other costly multimodal reasoning settings such as long-document or multi-image QA.
- Stronger action detectors fed into ACE might further shrink the set of missed evidence cases.
- OpenTSUBench offers a reusable testbed for measuring both accuracy and efficiency in long-video temporal reasoning.
- End-to-end fine-tuning of the candidate generator could reduce the risk of systematic omissions in the evidence windows.
Load-bearing premise
The lightweight ACE module reliably produces query-conditioned candidate answers and evidence windows that contain the true temporally localized evidence without systematic omissions.
What would settle it
A test collection of long ADL videos in which the ground-truth evidence segments lie outside the windows proposed by the ACE module, causing verification accuracy to fall below the strongest baseline.
Figures







read the original abstract
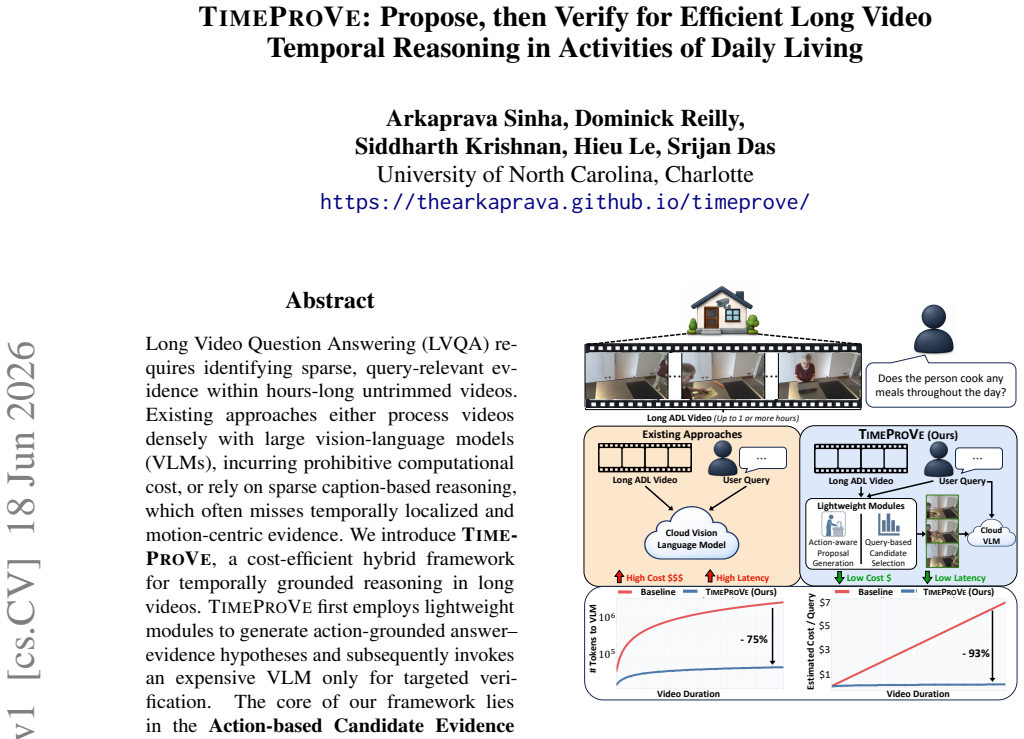
Long Video Question Answering (LVQA) requires identifying sparse, query-relevant evidence within hours-long untrimmed videos. Existing approaches either process videos densely with large vision-language models (VLMs), incurring prohibitive computational cost, or rely on sparse caption-based reasoning, which often misses temporally localized and motion-centric evidence. We introduce TimeProVe, a cost-efficient hybrid framework for temporally grounded reasoning in long videos. TimeProVe first employs lightweight modules to generate action-grounded answer--evidence hypotheses and subsequently invokes an expensive VLM only for targeted verification. The core of our framework lies in the Action-based Candidate Evidence (ACE) module, which converts temporally localized actions into query-conditioned candidate answers and supporting evidence windows through lightweight LLM reasoning. We further introduce OpenTSUBench (OTB), an open-ended benchmark designed to evaluate temporally grounded reasoning in real-world Activities of Daily Living (ADL) scenarios. Experiments show that TimeProVe outperforms the strongest baseline on OTB by 7.3%, while reducing VLM calls by 75% and inference cost by 93%. Furthermore, without explicit temporal grounding training, TimeProVe achieves competitive performance on Charades-STA, and reaches state-of-the-art results when enhanced with grounding VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TimeProVe, a hybrid framework for long-video question answering in ADL scenarios. It uses lightweight LLM-based Action-based Candidate Evidence (ACE) modules to generate query-conditioned candidate answers and evidence windows from temporally localized actions, then invokes a VLM only for targeted verification of those hypotheses. The work also introduces the OpenTSUBench (OTB) benchmark for open-ended temporally grounded reasoning. Central experimental claims are a 7.3% improvement over the strongest baseline on OTB together with 75% fewer VLM calls and 93% lower inference cost; additional results show competitive performance on Charades-STA without explicit temporal-grounding training and SOTA when augmented with grounding VLMs.
Significance. If the ACE module's candidate generation reliably covers the true evidence windows, the framework offers a practical route to large cost reductions in long-video temporal reasoning while preserving or improving accuracy. The introduction of OTB supplies a new, realistic benchmark focused on Activities of Daily Living, which could support reproducible progress in this area. The reported efficiency gains, if substantiated with the missing verification metrics, would constitute a meaningful engineering contribution for deployment-constrained settings.
major comments (2)
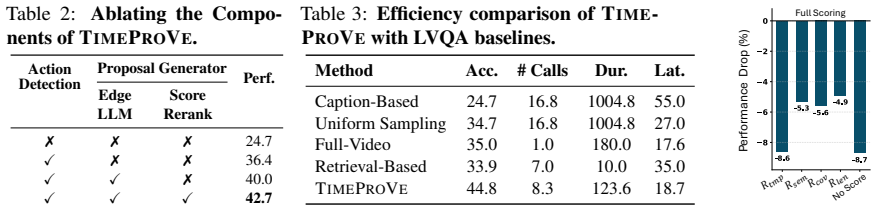
- [§4] §4 (Experimental Evaluation): The headline claims of 7.3% outperformance on OTB, 75% reduction in VLM calls, and 93% inference-cost reduction are presented without any description of the strongest baseline, OTB train/test splits, error bars, or statistical significance tests. These omissions directly affect the ability to assess whether the efficiency-accuracy tradeoff holds.
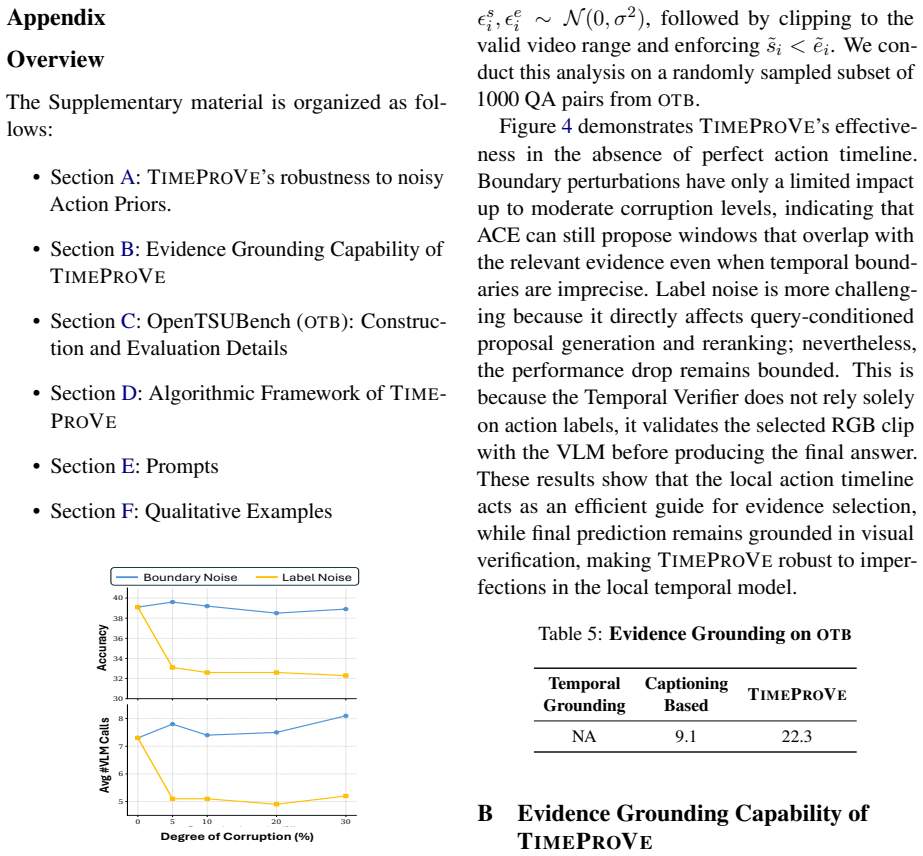
- [§3.2] §3.2 (ACE Module): The entire cost-reduction argument rests on the assumption that the lightweight ACE module produces query-conditioned evidence windows that contain the true temporally localized evidence for essentially all OTB queries. No recall metric, candidate-coverage ablation, or failure-case analysis is reported; systematic omissions would render the subsequent VLM verification step unable to recover the evidence while dense baselines could still succeed.
minor comments (1)
- [Abstract] Abstract: The first use of the acronym OTB should be accompanied by its full expansion (OpenTSUBench) for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation): The headline claims of 7.3% outperformance on OTB, 75% reduction in VLM calls, and 93% inference-cost reduction are presented without any description of the strongest baseline, OTB train/test splits, error bars, or statistical significance tests. These omissions directly affect the ability to assess whether the efficiency-accuracy tradeoff holds.
Authors: We agree that the experimental section requires additional details for full transparency and reproducibility. In the revised manuscript we will add an explicit description of the strongest baseline, specify the OTB train/test splits, report error bars across multiple runs, and include statistical significance tests for the 7.3% improvement and efficiency gains. revision: yes
-
Referee: [§3.2] §3.2 (ACE Module): The entire cost-reduction argument rests on the assumption that the lightweight ACE module produces query-conditioned evidence windows that contain the true temporally localized evidence for essentially all OTB queries. No recall metric, candidate-coverage ablation, or failure-case analysis is reported; systematic omissions would render the subsequent VLM verification step unable to recover the evidence while dense baselines could still succeed.
Authors: We concur that quantifying the coverage of the ACE module is essential to validate the proposed efficiency-accuracy tradeoff. The revised version will include recall metrics for the candidate evidence windows on OTB, a dedicated candidate-coverage ablation, and a failure-case analysis to demonstrate that systematic omissions are not occurring. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark comparisons
full rationale
The paper proposes the TimeProVe framework (ACE module for candidate generation followed by VLM verification) and evaluates it via direct experiments on OTB (7.3% gain, 75% fewer VLM calls) and Charades-STA. No equations, derivations, or load-bearing steps reduce by construction to self-defined inputs, fitted parameters renamed as predictions, or self-citation chains. Performance metrics are reported from external benchmark runs, making the work self-contained against those benchmarks with no internal tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , month =. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ url =
-
[2]
Jang, Jinhyeok and Kim, Dohyung and Park, Cheonshu and Jang, Minsu and Lee, Jaeyeon and Kim, Jaehong , booktitle =
-
[3]
, journal =
Liu, Jun and Shahroudy, Amir and Perez, Mauricio and Wang, Gang and Duan, Ling-Yu and Kot, Alex C. , journal =
-
[4]
Vaquette, Geoffrey and Orcesi, Astrid and Lucat, Laurent and Achard, Catherine , booktitle =
-
[5]
Liu, Chunhui and Hu, Yueyu and Li, Yanghao and Song, Sijie and Liu, Jiaying , journal =
-
[6]
European Conference on Computer Vision , pages =
Vpn: Learning video-pose embedding for activities of daily living , author =. European Conference on Computer Vision , pages =. 2020 , organization =
2020
-
[7]
Self-Supervised Video Representation Learning via Latent Time Navigation , year =
Yang, Di and Wang, Yaohui and Kong, Quan and Dantcheva, Antitza and Garattoni, Lorenzo and Francesca, Gianpiero and Br\'. Self-Supervised Video Representation Learning via Latent Time Navigation , year =. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intell...
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =
-
[9]
IEEE Transactions on Pattern Analysis and Machine Intelligence , title =
Zhe. IEEE Transactions on Pattern Analysis and Machine Intelligence , title =
-
[10]
2017 IEEE International Conference on Computer Vision (ICCV) , year =
RMPE: Regional Multi-person Pose Estimation , author =. 2017 IEEE International Conference on Computer Vision (ICCV) , year =
2017
-
[11]
Advances in Neural Information Processing Systems , year =
Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space , author =. Advances in Neural Information Processing Systems , year =
-
[12]
2017 , organization =
Quo vadis, Action Recognition? A New Model and the Kinetics Dataset , author =. 2017 , organization =
2017
-
[13]
AssembleNet++: Assembling Modality Representations via Attention Connections , author =
-
[14]
Return of the Devil in the Details: Delving Deep into Convolutional Nets , author =
-
[15]
Mesh R-CNN , author =
-
[16]
ArXiv , year =
Action Machine: Rethinking Action Recognition in Trimmed Videos , author =. ArXiv , year =
-
[17]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author =
-
[18]
Srijan Das and Rui Dai and Michal Koperski and Luca Minciullo and Lorenzo Garattoni and Francois Bremond and Gianpiero Francesca , title =
-
[19]
Shahroudy, Amir and Liu, Jun and Ng, Tian-Tsong and Wang, Gang , title =
-
[20]
Learning Structured Output Representation using Deep Conditional Generative Models , author =
-
[21]
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets , author =
-
[22]
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework , author =
-
[23]
Isolating Sources of Disentanglement in Variational Autoencoders , author =
-
[24]
Disentangled Representation Learning for 3D Face Shape , author =
-
[25]
Unsupervised Learning of Disentangled Representations from Video , author =
-
[26]
2020 , organization =
Contextual Imagined Goals for Self-supervised Robotic Learning , author =. 2020 , organization =
2020
-
[27]
Unsupervised Visual Representation Learning by Context Prediction , author =
-
[28]
Gait Recognition via Disentangled Representation Learning , author =
-
[29]
2017 , publisher =
Cross-modal Scene Networks , author =. 2017 , publisher =
2017
-
[30]
arXiv preprint arXiv:1312.6114 , year =
Auto-encoding Variational Bayes , author =. arXiv preprint arXiv:1312.6114 , year =
-
[31]
Generative Adversarial Nets , author =
-
[32]
arXiv preprint arXiv:1807.03748 , year =
Representation Learning with Contrastive Predictive Coding , author =. arXiv preprint arXiv:1807.03748 , year =
-
[33]
2020 , organization =
A Simple Framework for Contrastive Learning of Visual Representations , author =. 2020 , organization =
2020
-
[34]
2020 , eprint =
Improved Baselines with Momentum Contrastive Learning , author =. 2020 , eprint =
2020
-
[35]
Big Self-supervised Models are Strong Semi-supervised Learners , author =
-
[36]
Exploring Simple Siamese Representation Learning , author =
-
[37]
2020 , eprint =
CURL: Contrastive Unsupervised Representations for Reinforcement Learning , author =. 2020 , eprint =
2020
-
[38]
2019 , organization =
Imitating Latent Policies from Observation , author =. 2019 , organization =
2019
-
[39]
2021 , url =
Data-Efficient Reinforcement Learning with Self-Predictive Representations , author =. 2021 , url =
2021
-
[40]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , publisher =
He, Kaiming and Fan, Haoqi and Wu, Yuxin and Xie, Saining and Girshick, Ross , year =. Momentum Contrast for Unsupervised Visual Representation Learning , isbn =. doi:10.1109/cvpr42600.2020.00975 , journal = CVPR, publisher =
-
[41]
2020 , eprint =
Bootstrap Your Own Latent: A New Approach to Self-supervised Learning , author =. 2020 , eprint =
2020
-
[42]
Contrastive Multiview Coding , booktitle = ECCV, year =
Tian, Yonglong and Krishnan, Dilip and Isola, Phillip , editor =. Contrastive Multiview Coding , booktitle = ECCV, year =
-
[43]
Liu, YuXuan and Gupta, Abhishek and Abbeel, Pieter and Levine, Sergey , year =. Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation , isbn =. doi:10.1109/icra.2018.8462901 , journal = ICRA, publisher =
-
[44]
Playing Hard Exploration Games by Watching YouTube , author =
-
[45]
2020 , organization =
Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video , author =. 2020 , organization =
2020
-
[46]
2018 , organization =
Time-Contrastive Networks: Self-supervised Learning from Video , author =. 2018 , organization =
2018
-
[47]
Time-Contrastive Networks: Self-Supervised Learning from Multi-view Observation , year =
Sermanet, Pierre and Lynch, Corey and Hsu, Jasmine and Levine, Sergey , booktitle =. Time-Contrastive Networks: Self-Supervised Learning from Multi-view Observation , year =
-
[48]
Generative Adversarial Iimitation Learning , author =
-
[49]
, author =
Visualizing data using t-SNE. , author =. Journal of machine learning research , volume =
-
[50]
ArXiv , year =
Proximal Policy Optimization Algorithms , author =. ArXiv , year =
-
[51]
CrushedPixel and johni0702 , title =
-
[52]
Guss and Houghton, Brandon and Topin, Nicholay and Wang, Phillip and Codel, Cayden and Veloso, Manuela and Salakhutdinov, Ruslan , journal = IJCAI, url =
William H. Guss and Houghton, Brandon and Topin, Nicholay and Wang, Phillip and Codel, Cayden and Veloso, Manuela and Salakhutdinov, Ruslan , journal = IJCAI, url =. Mine
-
[53]
Erwin Coumans and Yunfei Bai , title =
-
[54]
arXiv preprint arXiv:1703.07737 , year =
In defense of the triplet loss for person re-identification , author =. arXiv preprint arXiv:1703.07737 , year =
-
[55]
2018 , eprint =
Hindsight Experience Replay , author =. 2018 , eprint =
2018
-
[56]
Neural Face Editing with Intrinsic Image Disentangling , author =
-
[57]
IJCAI , pages =
Johnson, Matthew and Hofmann, Katja and Hutton, Tim and Bignell, David , title =. IJCAI , pages =. 2016 , isbn =
2016
-
[58]
2018 , organization =
Learning Actionable Representations from Visual Observations , author =. 2018 , organization =
2018
-
[59]
arXiv preprint arXiv:1910.01077 , year =
Task-relevant Adversarial Imitation Learning , author =. arXiv preprint arXiv:1910.01077 , year =
arXiv 1910
-
[60]
A Style-Based Generator Architecture for Generative Adversarial Networks , isbn =
Karras, Tero and Laine, Samuli and Aila, Timo , year =. A Style-Based Generator Architecture for Generative Adversarial Networks , isbn =. doi:10.1109/cvpr.2019.00453 , journal = CVPR, publisher =
-
[61]
ArXiv , year =
Third-Person Imitation Learning , author =. ArXiv , year =
-
[62]
2020 , organization =
Adaptive Curriculum Generation from Demonstrations for Sim-to-real Visuomotor Control , author =. 2020 , organization =
2020
-
[63]
Sim-to-real via Sim-to-sim: Data-efficient Robotic Grasping via Randomized-to-canonical Adaptation Networks , author =
-
[64]
2020 , organization =
Cross-context Visual Imitation Learning from Demonstrations , author =. 2020 , organization =
2020
-
[65]
Behavioral and brain sciences , volume =
Does the Chimpanzee Have a Theory of Mind? , author =. Behavioral and brain sciences , volume =. 1978 , publisher =
1978
-
[66]
Child development , volume =
Imitation of Televised Models by Infants , author =. Child development , volume =. 1988 , publisher =
1988
-
[67]
2019 , organization =
Domain Agnostic learning with Disentangled Representations , author =. 2019 , organization =
2019
-
[68]
, booktitle = IROS, title =
Shang, Jinghuan and Ryoo, Michael S. , booktitle = IROS, title =. 2021 , volume =
2021
-
[69]
arXiv preprint arXiv:2108.03298 , year =
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , author =. arXiv preprint arXiv:2108.03298 , year =
-
[70]
Learning Correspondence from the Cycle-consistency of Time , author =
-
[71]
Temporal Cycle-consistency Learning , author =
-
[72]
Biometrika , volume =
A new measure of rank correlation , author =. Biometrika , volume =. 1938 , publisher =
1938
-
[73]
2009 , publisher =
Learning Multiple Layers of Features from Tiny Images , author =. 2009 , publisher =
2009
-
[74]
Imagenet: A Large-scale Hierarchical Image Database , author =
-
[75]
arXiv preprint arXiv:2203.16800 , year =
Fine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization , author =. arXiv preprint arXiv:2203.16800 , year =
-
[76]
arXiv preprint arXiv:2203.14957 , year =
Frame-wise Action Representations for Long Videos via Sequence Contrastive Learning , author =. arXiv preprint arXiv:2203.14957 , year =
-
[77]
Spatial Transformer Networks , author =
-
[78]
Self-supervised Video Transformer , author =
-
[79]
Ego-exo: Transferring Visual Representations from Third-person to First-person Videos , author =
-
[80]
The handbook of brain theory and neural networks , volume =
Convolutional Networks for Images, Speech, and Time series , author =. The handbook of brain theory and neural networks , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.