Meet UD_Czech-PDTC: A Large and Genre-Rich Treebank in Universal Dependencies
Pith reviewed 2026-06-26 00:02 UTC · model grok-4.3
The pith
The Prague Dependency Treebank-Consolidated converts to Universal Dependencies to form a large, genre-rich Czech treebank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
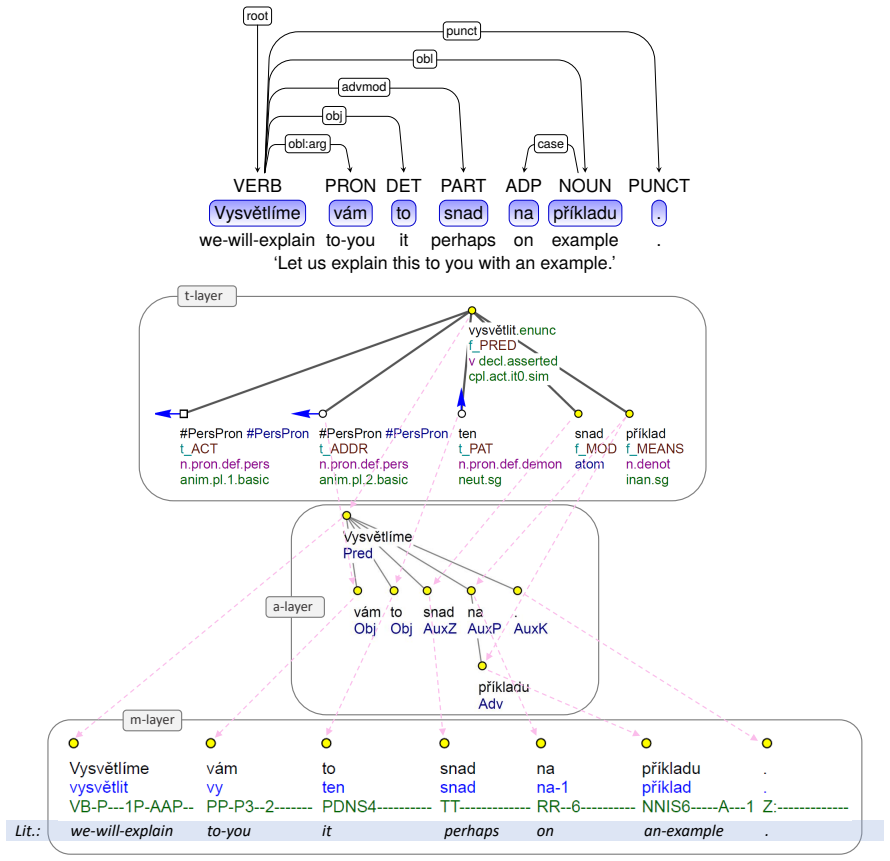
The conversion of PDT-C to UD produces UD_Czech-PDTC, a treebank more than twice as large as prior Czech UD resources and covering more genres and domains. Although PDT and UD differ in the topology of dependency structures and the granularity of their POS and relation inventories, these differences can be overcome systematically. PDT's multi-layer annotation provides all information needed for basic UD trees plus much more.
What carries the argument
The conversion mapping that resolves differences in dependency topology and label granularity between PDT's multi-layer annotations and UD dependency trees, POS tags, and relations.
If this is right
- UD_Czech-PDTC becomes available as one of the largest Czech resources in the Universal Dependencies collection.
- NLP tools for Czech can be trained on a dataset that includes greater genre and domain variety than before.
- The extra annotation layers in the original PDT can be retained alongside the UD trees for richer analysis.
- The conversion process demonstrates a workable path from language-specific multi-layer schemes to the UD format.
Where Pith is reading between the lines
- The same conversion approach may apply to other richly annotated treebanks that predate UD.
- Greater genre coverage could improve the robustness of parsers and other models when tested across text types.
- Cross-lingual UD studies may now draw on a larger and more varied Czech component for comparison.
Load-bearing premise
The small differences in dependency structures and label granularity between PDT and UD can be resolved systematically during conversion without introducing inconsistencies or losing essential information.
What would settle it
A sample of converted sentences that, when checked against direct human UD annotation, shows systematic unrecoverable mismatches in dependency arcs or lost syntactic distinctions.
Figures


read the original abstract
Czech has been part of Universal Dependencies since its first release in 2015. It has also been one of the best represented languages, with the Prague Dependency Treebank being order of magnitude larger than most other UD treebanks. More recently, three other datasets from the Prague family were added and the annotations thoroughly revisited, forming the "Prague Dependency Treebank-Consolidated" (PDT-C). In comparison to the original PDT, PDT-C is more than twice as large, but it is also much more diverse in terms of genres and domains. In this paper, we describe the conversion of the new resource to Universal Dependencies. While the two annotation schemes are relatively similar at the first sight, there are numerous small differences in topology of the dependency structures and in granularity of the POS and relation type inventories. We demonstrate a selection of such differences on examples, discuss the diverging motivations, as well as ways to overcome the differences during conversion. We argue that while PDT is less "universal" and more tightly bound to one language, its multi-layer annotation is rich and provides all information needed for basic UD trees, and much more.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
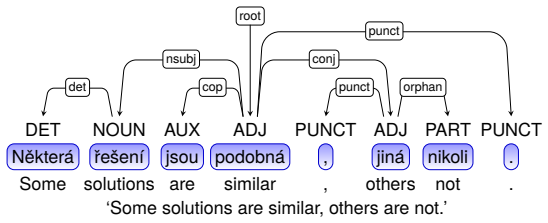
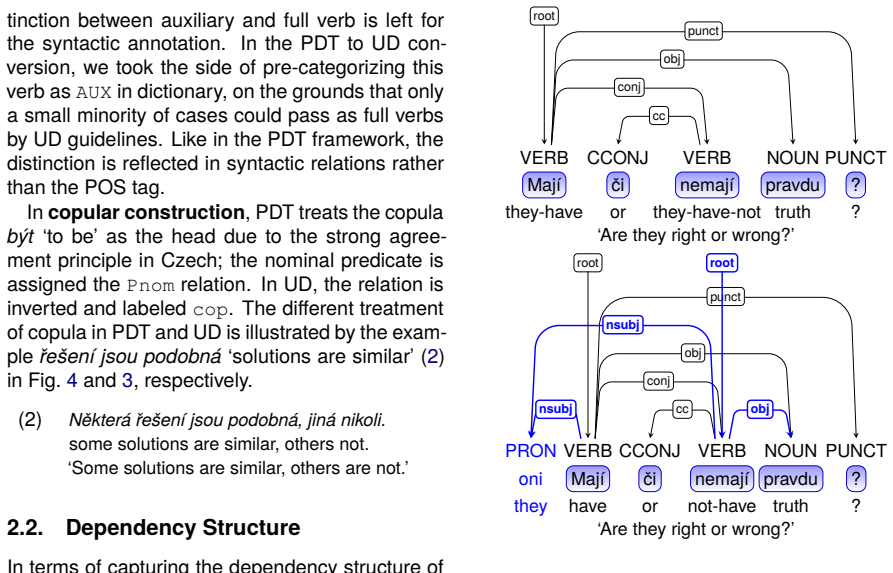
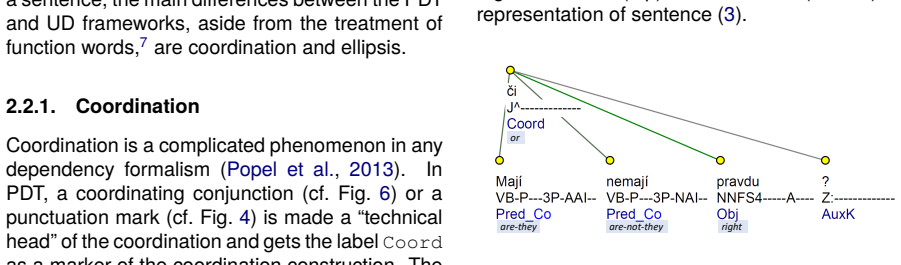
Summary. The paper describes the conversion of the Prague Dependency Treebank-Consolidated (PDT-C) to Universal Dependencies, producing the UD_Czech-PDTC treebank. PDT-C is presented as more than twice the size of the original PDT and substantially more diverse in genres and domains. The authors identify differences in dependency topology, POS granularity, and relation inventories between PDT and UD, illustrate them with examples, discuss the underlying motivations, and outline conversion strategies. They argue that PDT's multi-layer annotation supplies all information required for basic UD trees (and more).
Significance. If the conversion is shown to be reliable, the resulting treebank would be a valuable addition to UD for Czech, offering substantially greater scale and genre coverage than prior Czech UD resources. This could improve model training and cross-domain evaluation for Czech NLP. The work is a standard resource contribution whose primary strength lies in the released data rather than novel theoretical claims.
major comments (1)
- [Abstract] Abstract: the central claim that differences in topology, POS, and relations 'can be systematically overcome during conversion without introducing inconsistencies or loss of essential information' is not supported by any quantitative validation, error analysis, sample-based accuracy figures, or inter-annotator agreement on the converted output. This directly bears on the weakest assumption identified in the review and must be addressed for the resource to be usable with confidence.
minor comments (1)
- The manuscript would benefit from an explicit table (or section) reporting the final token/sentence counts, genre breakdown, and comparison to existing Czech UD treebanks to quantify the claimed increase in size and diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and agree that additional validation is needed to support the claims about the conversion process.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that differences in topology, POS, and relations 'can be systematically overcome during conversion without introducing inconsistencies or loss of essential information' is not supported by any quantitative validation, error analysis, sample-based accuracy figures, or inter-annotator agreement on the converted output. This directly bears on the weakest assumption identified in the review and must be addressed for the resource to be usable with confidence.
Authors: We agree that the abstract claim would be strengthened by quantitative evidence. The conversion relies on deterministic, rule-based mappings from PDT-C's multi-layer annotations (morphology, syntax, tectogrammatics), which we argue supply the necessary information without loss. However, the current manuscript provides only qualitative examples and does not include error rates or sample validation. In the revised version, we will add a dedicated section with a manual check on a random sample of sentences (e.g., 500 sentences), reporting conversion accuracy, common error types, and any inconsistencies encountered. We will also revise the abstract to reference this validation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a descriptive resource paper on converting the PDT-C treebank to UD format. It contains no equations, derivations, predictions, or self-referential claims that reduce inputs to outputs by construction. The central claim—that PDT-C's multi-layer annotation supplies all information needed for UD trees and that differences in topology/POS/relations can be bridged—is addressed directly by demonstrating examples and discussing conversion strategies, with no load-bearing self-citation chains or ansatzes imported from prior author work. The work is self-contained as a data release description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Haji c , Jan and Bej c ek, Eduard and B \'e mov \'a , Alevtina and Bur \'a n ov \'a , Eva and Fu c \' kov \'a , Eva and Haji c ov \'a , Eva and Havelka, Ji r \' and Hlav \'a c ov \'a , Jaroslava and Homola, Petr and Ircing, Pavel and K \'a rn \' k, Ji r \' and Kettnerov \'a , V \'a clava and Klyueva, Natalia and Kol \'a r ov \'a , Veronika and Ku c ov \'a...
2024
-
[2]
Haji c , Jan and Panevov \' a , Jarmila and Haji c ov \' a , Eva and Sgall, Petr and Pajas, Petr and S t e p \' a nek, Jan and Havelka, Ji r \' i and Mikulov \' a , Marie and Z abokrtsk \' y , Zden e k and S ev c \' i kov \' a -Raz \' i mov \' a , Magda and Ure s ov \' a , Zde n ka. 2006. https://catalog.ldc.upenn.edu/LDC2006T01 Prague Dependency Treebank...
2006
-
[3]
Nivre, Joakim and all. 2017. http://hdl.handle.net/11234/1-1983 Universal D ependencies 2.0 . LINDAT / CLARIAH - CZ digital library at the Institute of Formal and Applied Linguistics ( \'U FAL ), Charles University, Prague, Czech republic. PID http://hdl.handle.net/11234/1-1983 http://hdl.handle.net/11234/1-1983
2017
-
[4]
Nivre, Joakim and Bosco, Cristina and Choi, Jinho and de Marneffe, Marie-Catherine and Dozat, Timothy and Farkas, Rich \'a rd and Foster, Jennifer and Ginter, Filip and Goldberg, Yoav and Haji c , Jan and Kanerva, Jenna and Laippala, Veronika and Lenci, Alessandro and Lynn, Teresa and Manning, Christopher and McDonald , Ryan and Missil \"a , Anna and Mont...
2015
-
[5]
o bel, Nina and Bobicev, Victoria and Boizou, Lo \
Zeman, Daniel and Nivre, Joakim and Abrams, Mitchell and Ackermann, Elia and Adolphe, Jephtey and Aepli, No \"e mi and Aghaei, Hamid and Agi \'c , Z eljko and Ahmadi, Amir and Ahrenberg, Lars and Ajede, Chika Kennedy and Akhundjanova, Arofat and Akkurt, Furkan and Aleksandravi c i \=u t \.e , Gabriel \.e and Alfina, Ika and Algom, Avner and Alnajjar, Khal...
2025
-
[6]
o lker, Maximilian Wendt, Felix Hennig, and Arne K \
Emanuel Borges V \"o lker, Maximilian Wendt, Felix Hennig, and Arne K \"o hn. 2019. https://doi.org/10.18653/v1/W19-8006 HDT - UD : A very large U niversal D ependencies treebank for G erman . In Proceedings of the Third Workshop on Universal Dependencies, pages 46--57, Paris, France. Association for Computational Linguistics
-
[7]
Flavio Massimiliano Cecchini. 2024. https://doi.org/10.14712/00326585.029 Let's Do It Orderly: A Proposal for a Better Taxonomy of Adverbs in Universal Dependencies, and Beyond . The Prague Bulletin of Mathematical Linguistics, 121:15--65
-
[8]
Noam Chomsky. 1957. Syntactic Structures. Mouton, The Hague
1957
-
[9]
Manning, Joakim Nivre, and Daniel Zeman
Marie-Catherine de Marneffe, Christopher D. Manning, Joakim Nivre, and Daniel Zeman. 2021. https://doi.org/10.1162/coli_a_00402 U niversal D ependencies . Computational Linguistics, 47(2):255--308
-
[10]
Marie-Catherine de Marneffe, Joakim Nivre, and Daniel Zeman. 2024. https://www.linguisticanalysis.com/wp-content/uploads/2024/12/07-Function-Words-in-Universal-Dependencies-pp-549-628.pdf Function W ords in U niversal D ependencies . Linguistic Analysis, 43(3-4):549--588
2024
-
[11]
Eva Haji c ov \'a , Marie Mikulov \'a , and Jarmila Panevov \'a . 2015. https://aclanthology.org/W15-2116/ Reconstructions of Deletions in a Dependency-based Description of C zech: Selected Issues . In Proceedings of the Third International Conference on Dependency Linguistics, pages 131--140. Uppsala University, Uppsala, Sweden
2015
-
[12]
Eva Haji c ov \' a , Jarmila Panevov \' a , Marie Mikulov \' a , and Jan Haji c . 2024. https://www.linguisticanalysis.com/wp-content/uploads/2024/12/05-Function-Words-in-Praguian-Functional-Generative-Description-pp-465-512-.pdf Function W ords in P raguian F unctional G enerative D escription . Linguistic Analysis, 43(3-4):465--512
2024
-
[13]
Max Jakob, Mark \'e ta Lopatkov \'a , and Valia Kordoni. 2010. https://aclanthology.org/L10-1342/ Mapping between Dependency Structures and Compositional Semantic Representations . In Proceedings of the Seventh International Conference on Language Resources and Evaluation, Valletta, Malta. European Language Resources Association
2010
-
[14]
Mark \' e ta Lopatkov \' a , Eva Fu c \' kov \' a , Federica Gamba, Jan S t e p \' a nek, Daniel Zeman, and S \' a rka Zik \' a nov \' a . 2024. https://ceur-ws.org/Vol-3792/paper7.pdf Towards a Conversion of the Prague Dependency Treebank Data to the Uniform Meaning Representation . In Proceedings of the 24th Conference Information Technologies – Applica...
2024
-
[15]
Marie Mikulov \'a . 2014. https://aclanthology.org/O14-1013/ Semantic Representation of Ellipsis in the P rague Dependency Treebanks . In Proceedings of the 26th Conference on Computational Linguistics and Speech Processing, pages 125--138, Jhongli, Taiwan. Association for Computational Linguistics and Chinese Language Processing
2014
-
[16]
Marie Mikulov \'a , Ji r \' M \' rovsk \' y , Milan Straka, Pavl \'i na Synkov \'a , Barbora S t e p \'a nkov \'a , Jan S t e p \'a nek, and Jan Haji c . 2026. Prague Dependency Treebank - Consolidated 2.0: Enriching a Complex Annotation Scheme . In Proceedings of the Fifteenth Language Resources and Evaluation Conference, Palma de Mallorca, Spain. Europe...
2026
-
[17]
Marie Mikulov \'a , Barbora S t e p \'a nkov \'a , and Jan S t e p \'a nek. 2025. https://aclanthology.org/2025.coling-main.147/ From F orm to M eaning: The C ase of P articles within the P rague D ependency T reebank A nnotation S cheme . In Proceedings of the 31st International Conference on Computational Linguistics, pages 2163--2175, Abu Dhabi, UAE. A...
2025
-
[18]
Ji r \' M \' rovsk \' y and Pavl \'i na Synkov \'a . 2026. Presenting the P rague D iscourse T reebank 4.0. In Proceedings of the Fifteenth Language Resources and Evaluation Conference, Palma de Mallorca, Spain. European Language Resources Association
2026
-
[19]
Anna Nedoluzhko, Michal Nov \'a k, Martin Popel, Zden e k Z abokrtsk \'y , Amir Zeldes, and Daniel Zeman. 2022. https://aclanthology.org/2022.lrec-1.520/ C oref UD 1.0: Coreference M eets U niversal D ependencies . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 4859--4872, Marseille, France. European Language Resource...
2022
-
[20]
Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Haji c , Christopher D. Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman. 2020. https://aclanthology.org/2020.lrec-1.497/ U niversal D ependencies v2: An Evergrowing Multilingual Treebank Collection . In Proceedings of the Twelfth Language Resources and Evaluation Conf...
2020
-
[21]
Stephan Oepen, Omri Abend, Lasha Abzianidze, Johan Bos, Jan Hajič, Daniel Hershcovich, Bin Li, Tim O ' Gorman, Nianwen Xue, and Daniel Zeman. 2020. https://doi.org/10.18653/v1/2020.conll-shared.1 MRP 2020: The Second Shared Task on Cross-Framework and Cross-Lingual Meaning Representation Parsing . In Proceedings of the CoNLL 2020 Shared Task: Cross-Framew...
-
[22]
Stephan Oepen, Omri Abend, Jan Hajič, Daniel Hershcovich, Marco Kuhlmann, Tim O ' Gorman, Nianwen Xue, Jayeol Chun, Milan Straka, and Zdeňka Urešová. 2019. https://doi.org/10.18653/v1/K19-2001 MRP 2019: Cross-Framework Meaning Representation Parsing . In Proceedings of the Shared Task on Cross-Framework Meaning Representation Parsing at the 2019 Conferenc...
-
[23]
Martin Popel, David Mare c ek, Jan S t e p \'a nek, Daniel Zeman, and Zden e k Z abokrtsk \'y . 2013. https://aclanthology.org/P13-1051/ Coordination Structures in Dependency Treebanks . In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, pages 517--527, Sofia, Bulgaria. Association for Computational Linguistics
2013
-
[24]
Alexandr Rosen. 2023. https://www.juls.savba.sk/ediela/jc/2023/1/jc23-01.pdf#page=256 The InterCorp parallel corpus with a uniform annotation for all languages . Jazykovedn \' y c asopis / Journal of Linguistics , 74(1):254--265
2023
-
[25]
Agata Rozumko. 2016. Linguistic Concepts across Languages: The Category of Epistemic Adverbs in English and Polish . Yearbook of the Poznan Linguistic Meeting, 2(1):195--214
2016
-
[26]
Sebastian Schuster and Christopher D. Manning. 2016. https://aclanthology.org/L16-1376 Enhanced E nglish U niversal D ependencies: An Improved Representation for Natural Language Understanding Tasks . In Proceedings of the Tenth International Conference on Language Resources and Evaluation, pages 2371--2378, Portoro z , Slovenia. European Language Resourc...
2016
-
[27]
Petr Sgall, Eva Haji c ov\' a , and Jarmila Panevov\' a . 1986. The Meaning of the Sentence and Its Semantic and Pragmatic Aspects . Academia/Reidel Publishing Company, Prague/Dordrecht
1986
-
[28]
Jan S t e p \'a nek, Daniel Zeman, Mark \'e ta Lopatkov \'a , Federica Gamba, and Hana Hled \'i kov \'a . 2025. https://aclanthology.org/2025.dmr-1.1/ Comparing Manual and Automatic UMR s for C zech and L atin . In Proceedings of the Sixth International Workshop on Designing Meaning Representations, pages 1--12, Prague, Czechia. Association for Computatio...
2025
-
[29]
Milan Straka. 2018. https://doi.org/10.18653/v1/K18-2020 UDP ipe 2.0 Prototype at C o NLL 2018 UD Shared Task . In Proceedings of the C o NLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies , pages 197--207, Brussels, Belgium. Association for Computational Linguistics
-
[30]
Milan Straka, Jana Strakov \'a , and Jan Haji c . 2019. https://doi.org/10.18653/v1/W19-4212 UDP ipe at SIGMORPHON 2019: Contextualized Embeddings, Regularization with Morphological Categories, Corpora Merging . In Proceedings of the 16th Workshop on Computational Research in Phonetics, Phonology, and Morphology, pages 95--103, Florence, Italy. Associatio...
-
[31]
Daniel Zeman, Pavel Kosek, Martin Březina, and Jiří Pergler. 2023. https://www.juls.savba.sk/ediela/jc/2023/1/jc23-01.pdf#page=216 Morphosyntactic annotation in Universal Dependencies for old Czech . Jazykovedný časopis / Journal of Linguistics, 74(1):214--222
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.