Modern Theory of Gradient-Based Optimization
Pith reviewed 2026-06-30 02:46 UTC · model grok-4.3
The pith
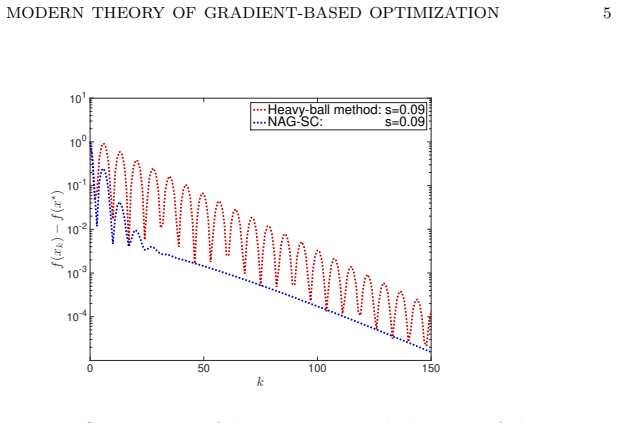
The gradient-correction term drives acceleration in NAG-SC and Polyak's heavy-ball method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through high-resolution ODE modeling and systematic Lyapunov-function construction, the gradient-correction term is identified as the primary driver of acceleration for NAG-SC and Polyak's heavy-ball method. The same modeling and Lyapunov techniques are synthesized into a unified framework that recovers accelerated convergence of gradient norms, underdamped behavior, linear rates under strong convexity, and monotonicity properties for generalized accelerated methods, while extending the analysis to ADMM, PDHG, their accelerated forms, and recent minimax results.
What carries the argument
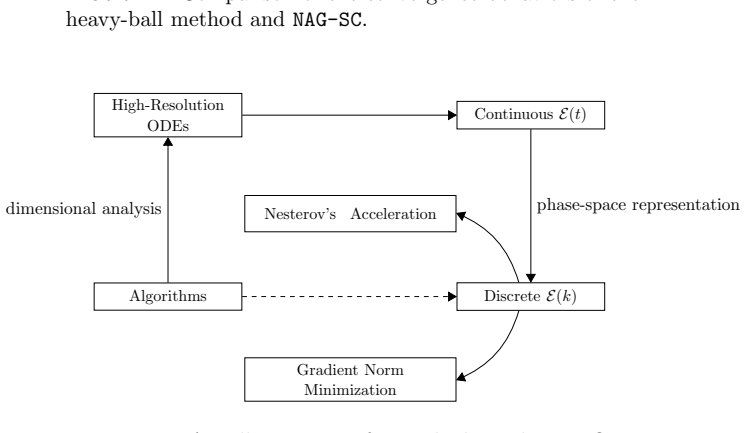
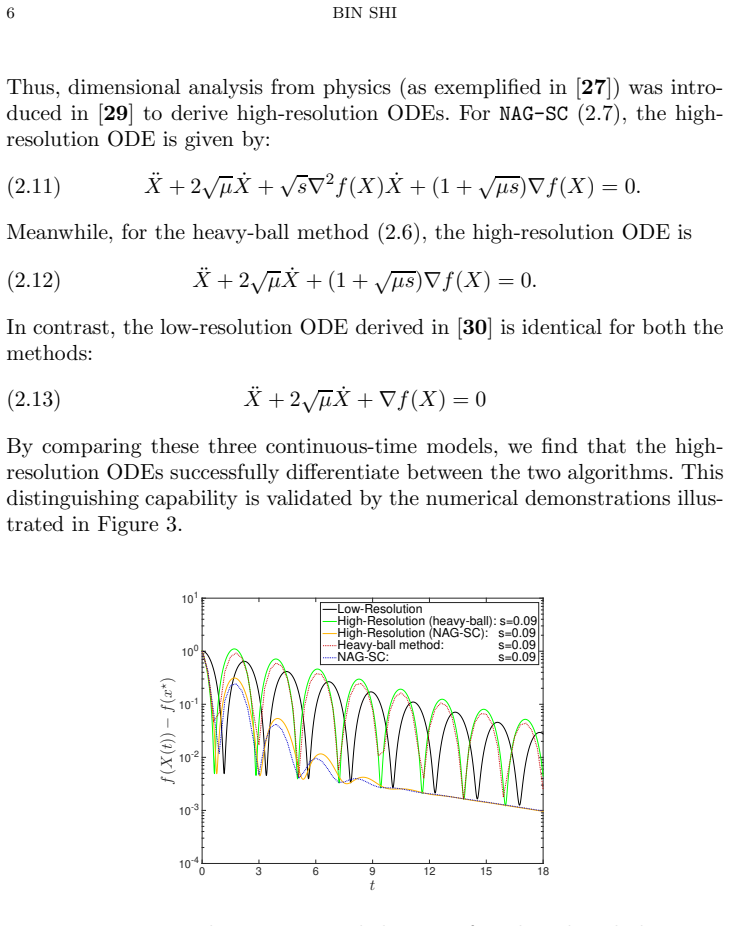
High-resolution ODE approximations paired with discrete Lyapunov functions, in which the gradient-correction term supplies the dominant acceleration mechanism.
If this is right
- Accelerated convergence rates for gradient norms follow directly from the Lyapunov analysis.
- Underdamped acceleration and linear convergence under strong convexity are recovered as corollaries.
- Novel Lyapunov constructions establish both convergence and monotonicity for generalized accelerated methods.
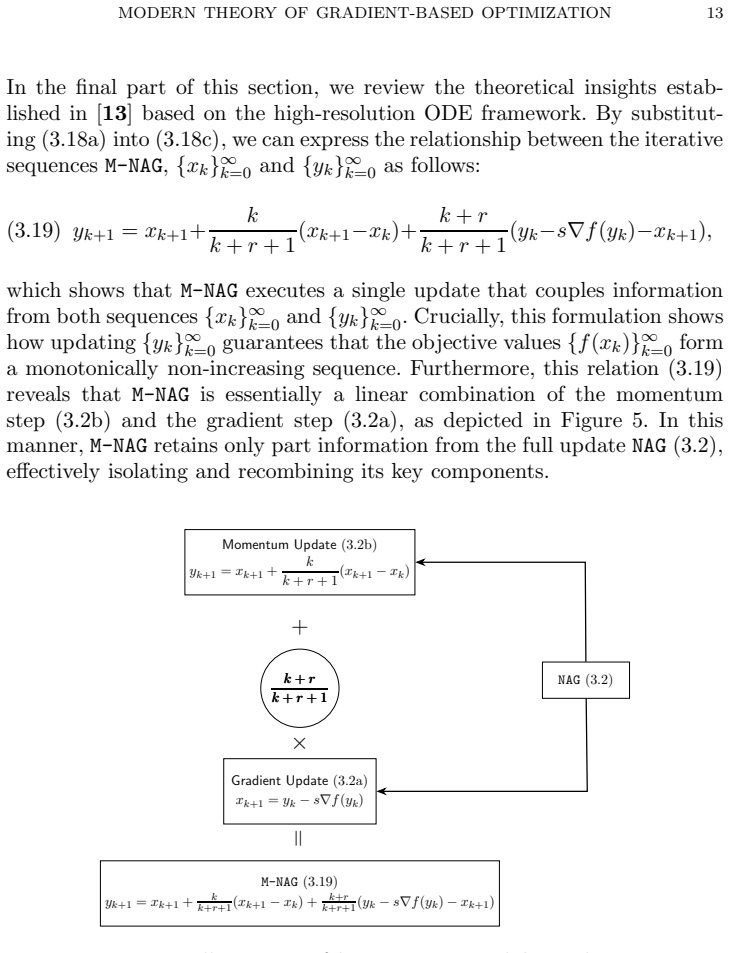
- The ODE-Lyapunov framework supplies a single proof template for ADMM, PDHG, and their accelerated variants.
Where Pith is reading between the lines
- The same correction-term perspective may suggest how to accelerate first-order methods on non-convex landscapes where standard momentum fails.
- Extension of the Lyapunov constructions to stochastic oracles could yield variance-reduced accelerated schemes with provable high-probability bounds.
- The unified treatment of saddle-point problems points toward practical acceleration of training algorithms that solve minimax formulations.
Load-bearing premise
The high-resolution ODE approximations and associated Lyapunov functions accurately capture the behavior of the underlying discrete algorithms without material discretization error or loss of key properties.
What would settle it
Numerical trajectories for a quadratic strongly convex function in which the discrete iterates of NAG-SC converge at a rate materially different from the rate predicted by the corresponding high-resolution ODE.
Figures

read the original abstract
In this review, we offer a comprehensive survey of emerging techniques in gradient-based optimization, with a particular emphasis on the interplay between ordinary differential equation (ODE) perspectives and their extensions into discrete Lyapunov analysis. We begin by examining the acceleration mechanisms underlying Nesterov's accelerated gradient method for strongly convex functions (NAG-SC) and Polyak's heavy-ball method, identifying the gradient-correction term as the primary driver of acceleration. This mechanistic insight is substantiated through high-resolution ODE modeling and the systematic construction of Lyapunov functions. We then synthesize recent advancements in convex optimization regarding NAG and its proximal generalization, the fast iterative shrinkage-thresholding algorithm (FISTA). Key topics include the accelerated convergence of gradient norms, underdamped acceleration, linear convergence under strong convexity, and novel Lyapunov frameworks for establishing convergence and monotonicity properties of generalized accelerated methods. Furthermore, we demonstrate how these ODE approximations and Lyapunov techniques can be extended to provide a unified framework for analyzing advanced optimization algorithms, including the alternating direction method of multipliers (ADMM), the primal-dual hybrid gradient (PDHG) method, and their respective accelerated variants. Finally, we discuss recent progress in minimax optimization and outline future directions for extending Lyapunov-based analysis to saddle-point problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey synthesizing ODE-based modeling and Lyapunov function constructions for gradient-based optimization. It claims that the gradient-correction term is the primary driver of acceleration in NAG-SC and Polyak's heavy-ball method, substantiated via high-resolution ODE approximations and systematic Lyapunov analysis. The work extends this framework to FISTA, ADMM, PDHG and their accelerated variants, discusses accelerated gradient-norm convergence and linear rates under strong convexity, and outlines extensions to minimax/saddle-point problems.
Significance. If the mechanistic attributions and unified Lyapunov frameworks hold with rigorous support, the survey could provide a coherent reference for analyzing acceleration mechanisms across first-order methods and their proximal/minimax extensions, potentially facilitating new algorithm design in convex and nonconvex settings.
major comments (2)
- [Abstract, §2] Abstract and §2 (on NAG-SC/heavy-ball): the central claim that the gradient-correction term is the primary driver of acceleration is load-bearing and rests on high-resolution ODE modeling plus Lyapunov decrease rates. The manuscript must supply explicit discretization-error bounds or side-by-side discrete-vs-continuous trajectory comparisons showing that the continuous limit preserves the exact contribution of the correction term; absent these, the attribution to the correction term alone remains vulnerable to truncation artifacts.
- [§4–5] §4–5 (extensions to ADMM/PDHG and minimax): the unified Lyapunov framework for generalized accelerated methods and saddle-point problems is presented as a synthesis, but the paper does not indicate whether the same high-resolution ODE approximations carry over without additional error terms when the underlying discrete operators are proximal or primal-dual; this gap directly affects the claimed generality of the framework.
minor comments (2)
- [Throughout] Notation for the high-resolution parameter (e.g., the scaling of the correction term) should be introduced once with a clear reference to the underlying discrete step-size; repeated redefinitions across sections reduce readability.
- [Introduction, §3] Several citations to the original NAG, FISTA, and ADMM papers are present, but recent works on high-resolution ODEs for non-strongly-convex cases appear under-cited; adding 2–3 key references would strengthen the survey character.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our survey. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, §2] Abstract and §2 (on NAG-SC/heavy-ball): the central claim that the gradient-correction term is the primary driver of acceleration is load-bearing and rests on high-resolution ODE modeling plus Lyapunov decrease rates. The manuscript must supply explicit discretization-error bounds or side-by-side discrete-vs-continuous trajectory comparisons showing that the continuous limit preserves the exact contribution of the correction term; absent these, the attribution to the correction term alone remains vulnerable to truncation artifacts.
Authors: The high-resolution ODE derivations and associated error controls are drawn from the cited literature on which §2 builds; the manuscript already includes illustrative discrete-continuous trajectory comparisons for NAG-SC and heavy-ball. We agree that an explicit remark on how the cited bounds ensure the correction term's contribution is preserved would strengthen the presentation. We will add a short clarifying paragraph in §2 referencing the relevant discretization analysis. revision: partial
-
Referee: [§4–5] §4–5 (extensions to ADMM/PDHG and minimax): the unified Lyapunov framework for generalized accelerated methods and saddle-point problems is presented as a synthesis, but the paper does not indicate whether the same high-resolution ODE approximations carry over without additional error terms when the underlying discrete operators are proximal or primal-dual; this gap directly affects the claimed generality of the framework.
Authors: The extensions in §4–5 synthesize existing ODE and Lyapunov results for proximal and primal-dual operators from the referenced works. We will revise the introductory paragraphs of §4 and §5 to explicitly note the adaptation of the high-resolution approximations and the scope of any additional error considerations, thereby clarifying the limits of the claimed generality. revision: partial
Circularity Check
No circularity detected; survey synthesizes external techniques without self-referential reductions
full rationale
The paper is a comprehensive survey of gradient-based optimization techniques, focusing on high-resolution ODE modeling and Lyapunov functions to analyze acceleration in NAG-SC, heavy-ball, FISTA, ADMM, and related methods. The central mechanistic claim attributes acceleration primarily to the gradient-correction term, substantiated via these modeling approaches. No equations, derivations, or citations in the abstract or summary reduce any result to a fitted parameter, self-definition, or load-bearing self-citation chain by construction. The work references prior literature on NAG, FISTA, and ADMM as external inputs without indicating that claimed insights are equivalent to those inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anderson and John B Moore
Brian D. Anderson and John B Moore. Optimal control: linear quadratic methods . Courier Corporation, Mineola, NY, 2007
2007
-
[2]
Arrow, Leonid Hurwicz, and Hirofumi Uzawa
Kenneth J. Arrow, Leonid Hurwicz, and Hirofumi Uzawa. Studies in Linear and Non- Linear Programming. Stanford Mathematical Studies in the Social Sciences. Sta nford University Press, 1958
1958
-
[3]
Fast gradient-based algori thms for constrained to- tal variation image denoising and deblurring problems
Amir Beck and Marc Teboulle. Fast gradient-based algori thms for constrained to- tal variation image denoising and deblurring problems. IEEE transactions on image processing, 18(11):2419–2434, 2009
2009
-
[4]
A preconditioner for gene ralized saddle point problems
Michele Benzi and Gene H Golub. A preconditioner for gene ralized saddle point problems. SIAM Journal on Matrix Analysis and Applications , 26(1):20–41, 2004
2004
-
[5]
Numerical solution of saddle point problems
Michele Benzi, Gene H Golub, and J¨ org Liesen. Numerical solution of saddle point problems. Acta numerica, 14:1–137, 2005
2005
-
[6]
M´ ethode g´ en´ erale pour la r´ esolution des syst` emes d’´ equations simultan´ ees.Comptes Rendus de l’Acad´ emie des Sciences, 25:536–538, 1847
Augustin-Louis Cauchy. M´ ethode g´ en´ erale pour la r´ esolution des syst` emes d’´ equations simultan´ ees.Comptes Rendus de l’Acad´ emie des Sciences, 25:536–538, 1847
-
[7]
Chambolle and T
A. Chambolle and T. Pock. A first-order primal-dual algor ithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision , 40:120– 145, 2011
2011
-
[8]
An introduction to co ntinuous optimization for imaging
Antonin Chambolle and Thomas Pock. An introduction to co ntinuous optimization for imaging. Acta Numerica, 25:161–319, 2016. 22 BIN SHI
2016
-
[9]
Gradient norm mini mization of Nesterov acceleration: o(1/k3)
Shuo Chen, Bin Shi, and Ya-xiang Yuan. Gradient norm mini mization of Nesterov acceleration: o(1/k3). arXiv preprint arXiv:2209.08862 , 2022
-
[10]
Revisiting neste rov’s acceleration via high- resolution differential equations
Shuo Chen, Bin Shi, and Ya-xiang Yuan. Revisiting neste rov’s acceleration via high- resolution differential equations. Journal of Global Optimization , 93(2):551–569, 2025
2025
-
[11]
On underdamped Ne sterov’s acceleration
Shuo Chen, Bin Shi, and Ya-xiang Yuan. On underdamped Ne sterov’s acceleration. Journal of Computational Mathematics , 44(6):1912–1934, 2026
1912
-
[12]
Collected Works of Feng Kang , volume II
Kang Feng. Collected Works of Feng Kang , volume II. Science Press, Beijing, 1995. Edited by Institute of Computational Mathematics and Scien tific/Engineering Com- puting, Academy of Mathematics and Systems Science, Chines e Academy of Sciences; Proofread by Liqun, Cao and Yifa, Tang
1995
-
[13]
Lyapunov analysis for monotonic ally forward-backward accelerated algorithms
Mingwei Fu and Bin Shi. Lyapunov analysis for monotonic ally forward-backward accelerated algorithms. arXiv preprint arXiv:2412.13527 , 2024
-
[14]
A family of controllable momentu m coefficients for forward- backward accelerated algorithms
Mingwei Fu and Bin Shi. A family of controllable momentu m coefficients for forward- backward accelerated algorithms. arXiv preprint arXiv:2501.10051 , 2025
-
[15]
I. M. Gelfand and M. Tsetlin. Printsip nelokal’nogo poi ska v sistemakh avtomatich- eskoy optimizatsii. Doklady Akademii Nauk SSSR , 137:295–298, 1961
1961
-
[16]
M. I. Jordan. Dynamical, symplectic and stochastic per spectives on gradient-based optimization. In Proceedings of the International Congress of Mathematicia ns: Rio de Janeiro 2018 , pages 523–549, Singapore, 2018. World Scientific
2018
-
[17]
Vari ational algorithms for anal- ysis and assimilation of meteorological observations: the oretical aspects
Fran¸ cois-Xavier Le Dimet and Olivier Talagrand. Vari ational algorithms for anal- ysis and assimilation of meteorological observations: the oretical aspects. Tellus A: Dynamic Meteorology and Oceanography , 38(2):97–110, 1986
1986
-
[18]
Understanding the ADMM algorithm v ia high-resolution dif- ferential equations
Bowen Li and Bin Shi. Understanding the ADMM algorithm v ia high-resolution dif- ferential equations. Applied Mathematics and Optimization , 2024. to appear
2024
-
[19]
Understanding the PDHG algorithm v ia high-resolution dif- ferential equations
Bowen Li and Bin Shi. Understanding the PDHG algorithm v ia high-resolution dif- ferential equations. arXiv preprint arXiv:2403.11139 , 2024
-
[20]
Linear convergenc e of forward-backward accelerated algorithms without knowledge of the modulus of strong convexity
Bowen Li, Bin Shi, and Ya-xiang Yuan. Linear convergenc e of forward-backward accelerated algorithms without knowledge of the modulus of strong convexity. SIAM Journal on Optimization , 34(2):2150–2168, 2024
2024
-
[21]
Linear convergenc e of ISTA and FISTA
Bowen Li, Bin Shi, and Ya-xiang Yuan. Linear convergenc e of ISTA and FISTA. Journal of the Operations Research Society of China , 14:345–363, 2024
2024
-
[22]
Proximal subgradi ent norm minimization of ISTA and FISTA
Bowen Li, Bin Shi, and Ya-xiang Yuan. Proximal subgradi ent norm minimization of ISTA and FISTA. Applied and Computational Harmonic Analysis , 82:101848, 2026
2026
-
[23]
Jiaqi Liu and Bin Shi. Accelerated implicit gda schemes : Theoretical guaran- tees and application to proximal augmented lagrangian meth ods. arXiv preprint arXiv:2606.11800, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
A. S. Nemirovsky and D. B. Yudin. Problem Complexity and Method Efficiency in Optimization. Wiley-Interscience Series in Discrete Mathematics. Wile y-Interscience, New York, 1983
1983
-
[25]
A method of solving a convex programmin g problem with convergence rate O(1/k2)
Yurii Nesterov. A method of solving a convex programmin g problem with convergence rate O(1/k2). Soviet Mathematics-Doklady , 27(2):372–376, 1983
1983
-
[26]
Lectures on Convex Optimization
Yurii Nesterov. Lectures on Convex Optimization . Springer Optimization and Its Ap- plications. Springer Cham, 2 edition, 2018
2018
-
[27]
Geophysical fluid dynamics
Joseph Pedlosky. Geophysical fluid dynamics . Springer Science & Business Media, 2013
2013
-
[28]
Some methods of speeding up the converge nce of iteration methods
Boris T Polyak. Some methods of speeding up the converge nce of iteration methods. Ussr computational mathematics and mathematical physics , 4(5):1–17, 1964
1964
-
[29]
Du, Weijie Su, and Michael I
Bin Shi, Simon S. Du, Weijie Su, and Michael I. Jordan. Un derstanding the acceler- ation phenomenon via high-resolution differential equatio ns. Mathematical Program- ming, 195:79–148, 2022
2022
-
[30]
A differe ntial equation for model- ing nesterov’s accelerated gradient method: Theory and ins ights
Weijie Su, Stephen Boyd, and Emmanuel J Candes. A differe ntial equation for model- ing nesterov’s accelerated gradient method: Theory and ins ights. Journal of Machine Learning Research, 17(153):1–43, 2016. MODERN THEORY OF GRADIENT-BASED OPTIMIZATION 23
2016
-
[31]
On the impor- tance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffre y Hinton. On the impor- tance of initialization and momentum in deep learning. In International conference on machine learning , pages 1139–1147. pmlr, 2013
2013
-
[32]
A lyapunov analysis of acceler ated pdhg algorithms
Xueying Zeng and Bin Shi. A lyapunov analysis of acceler ated pdhg algorithms. Journal of Optimization Theory and Applications , 207(3):67, 2025. Center for Mathematics and Interdisciplinary Sciences, Fu dan Univer- sity, Shanghai 200433, China Shanghai Institute for Mathematics and Interdisciplinary Sciences, Shang- hai 200433, China Email address : bins...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.