RevengeBench: Reverse Engineering Code-Space Policies from Behavioral Experiments
Pith reviewed 2026-06-25 19:10 UTC · model grok-4.3
The pith
A learner can reconstruct an agent's hidden decision code from its observed game behavior, and recovers substantially more when allowed to design its own experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
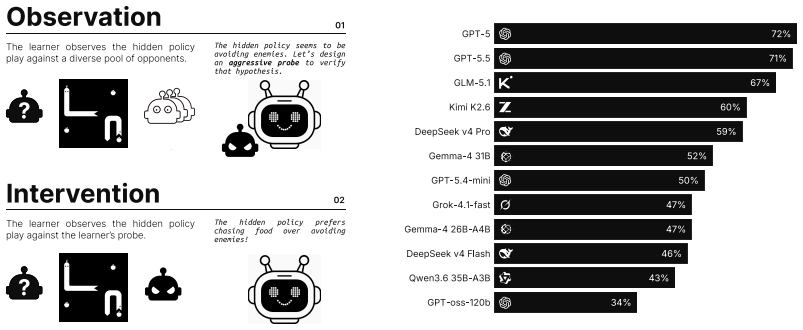
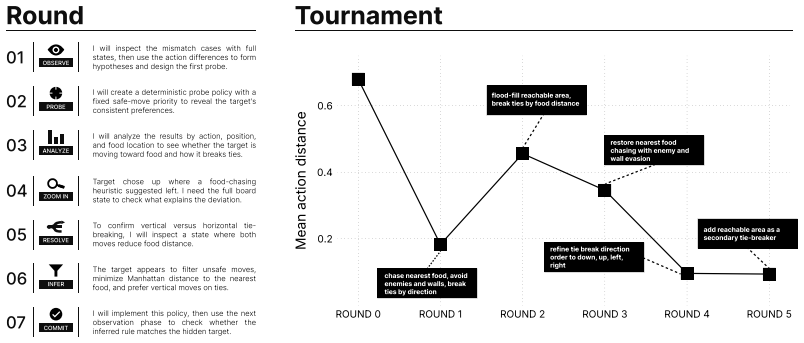
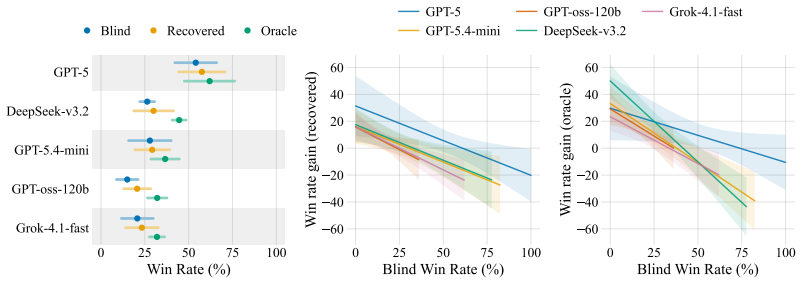
Given only behavioral traces of an agent in a game environment, a learner can reconstruct the underlying decision program as executable code. Recovery improves when the learner designs controlled experiments in the form of custom opponent policies that elicit informative behavior. The recovered code carries informative signal that yields competitive advantage in downstream player-versus-player tournaments.
What carries the argument
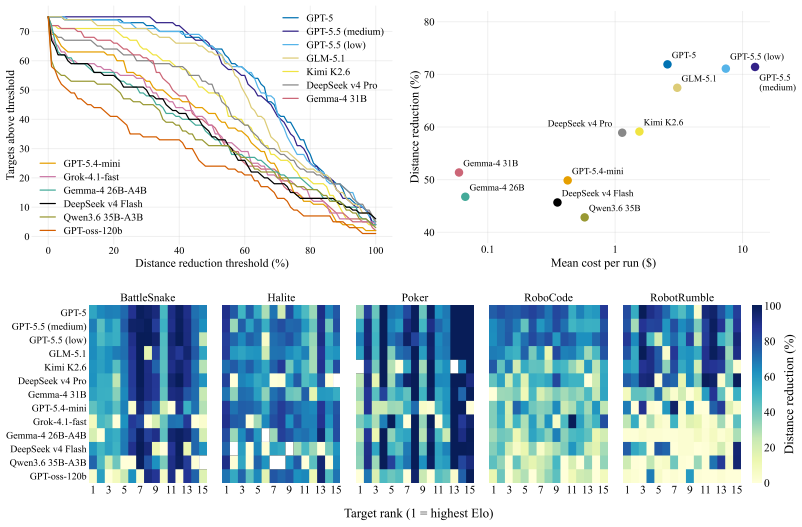
RevengeBench, a benchmark of 75 LLM-generated Elo-calibrated policies across five game environments, scored by continuous action-distance metrics and downstream tournament performance.
If this is right
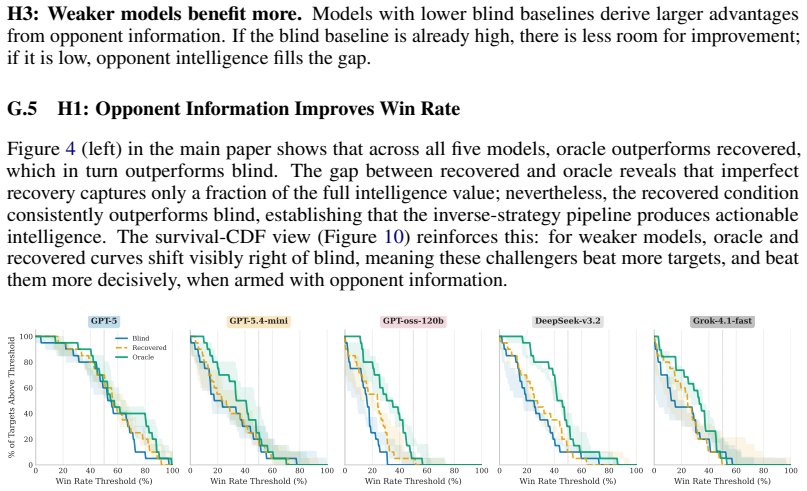
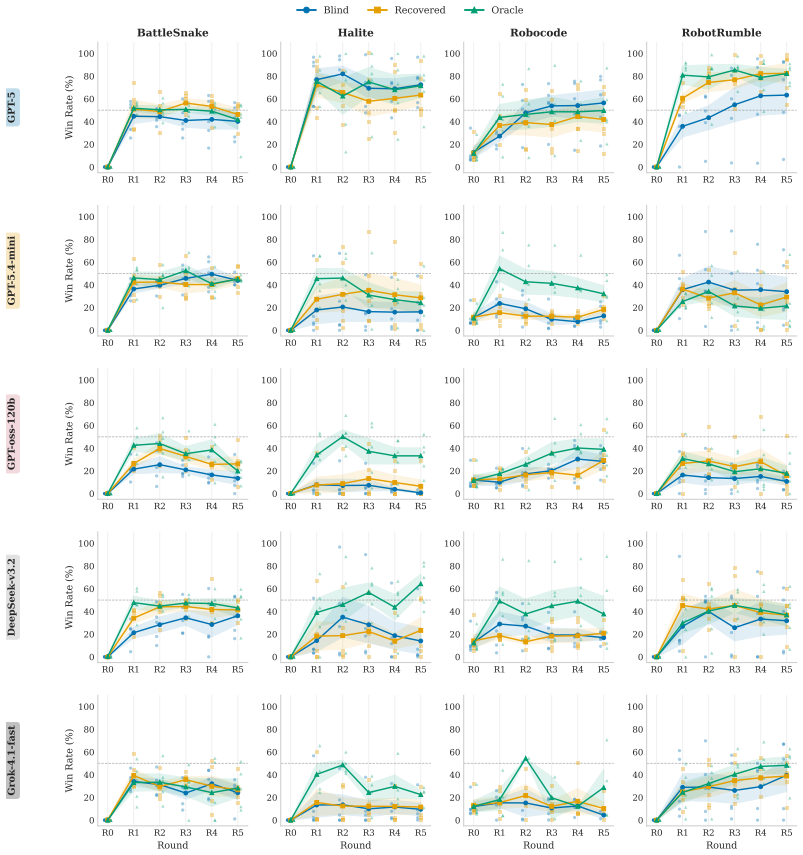
- Reconstructed policies produce measurable competitive advantage when entered into player-versus-player tournaments.
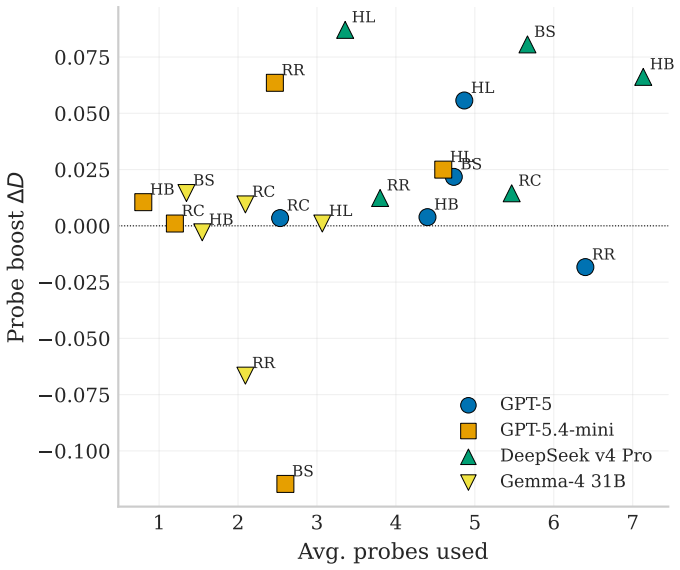
- Recovery quality varies substantially across frontier LLMs, closing between 34 and 72 percent of the initial distance to the target policy.
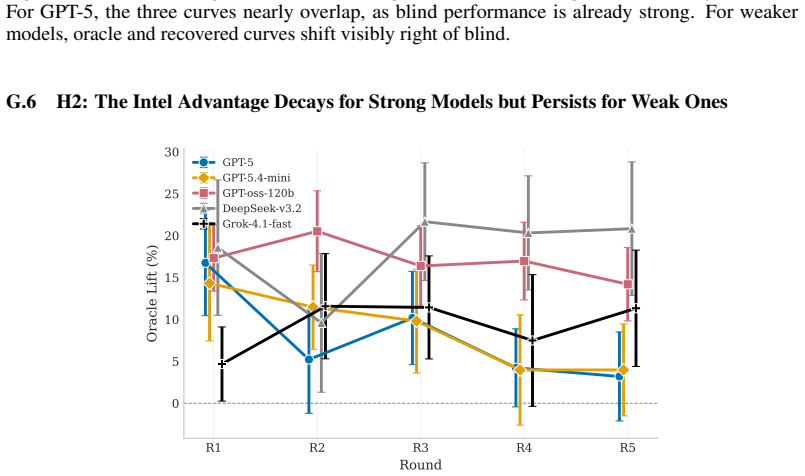
- Weaker base models gain the largest tournament benefit from recovered code that enables effective counter-strategies.
Where Pith is reading between the lines
- The same active-probe approach could be applied to recover decision logic from black-box systems outside games.
- It opens a route to automated policy debugging by iteratively refining executable hypotheses against observed behavior.
- If the method generalizes, it supplies a concrete test for claims about inferring latent mechanisms from limited observations.
Load-bearing premise
The 75 LLM-generated policies form a representative testbed in which action-distance metrics validly capture reconstruction quality and tournament advantage.
What would settle it
An experiment in which permitting the learner to design behavioral probes yields no measurable increase in reconstruction accuracy or downstream tournament wins relative to passive observation alone.
Figures
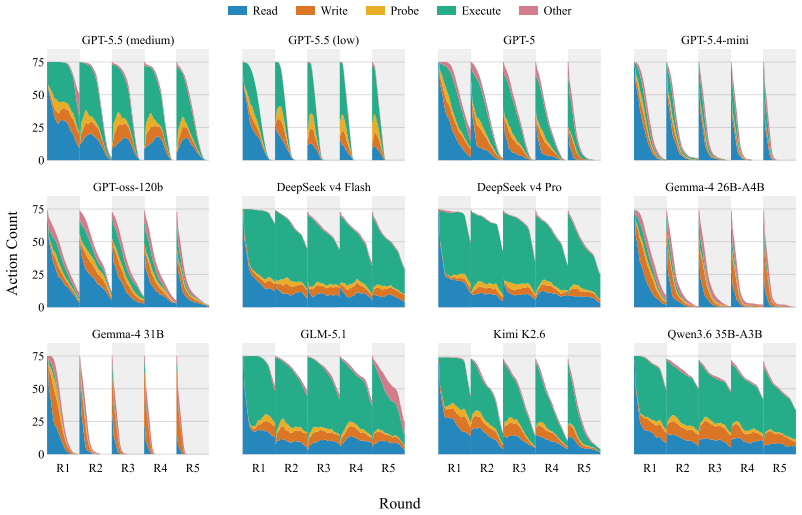
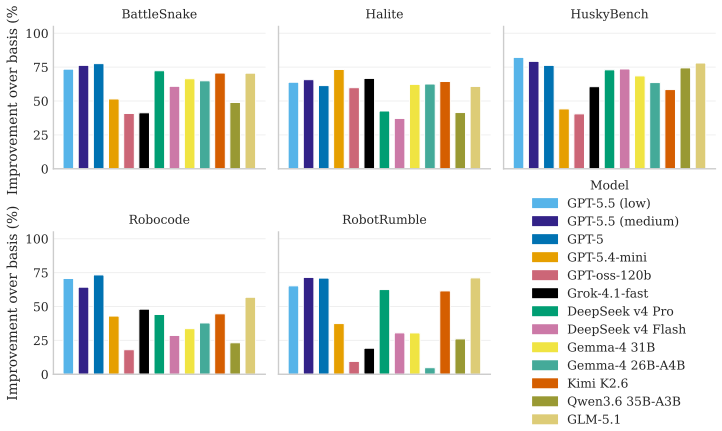
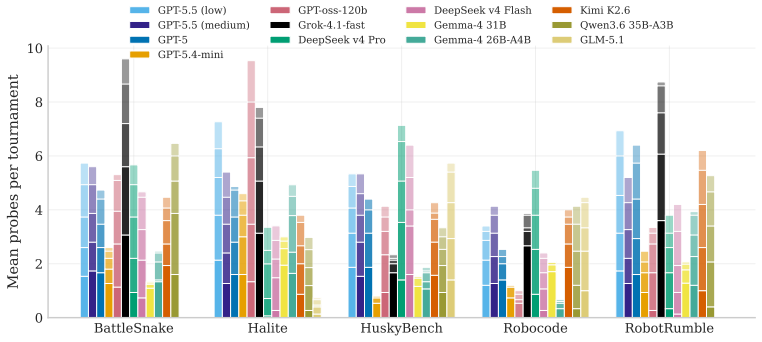
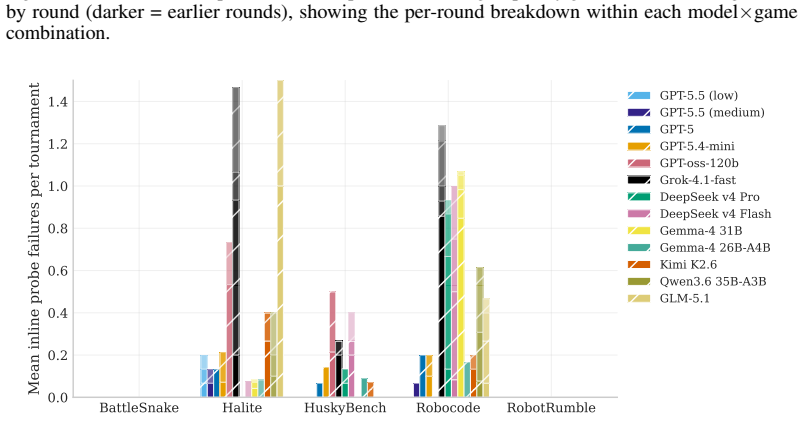

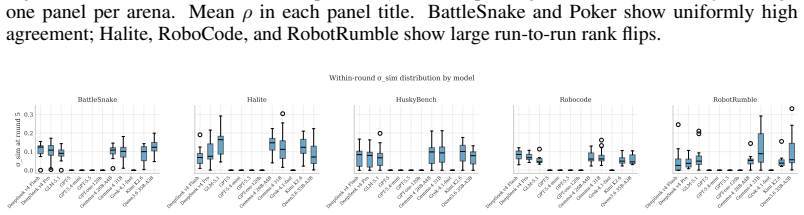
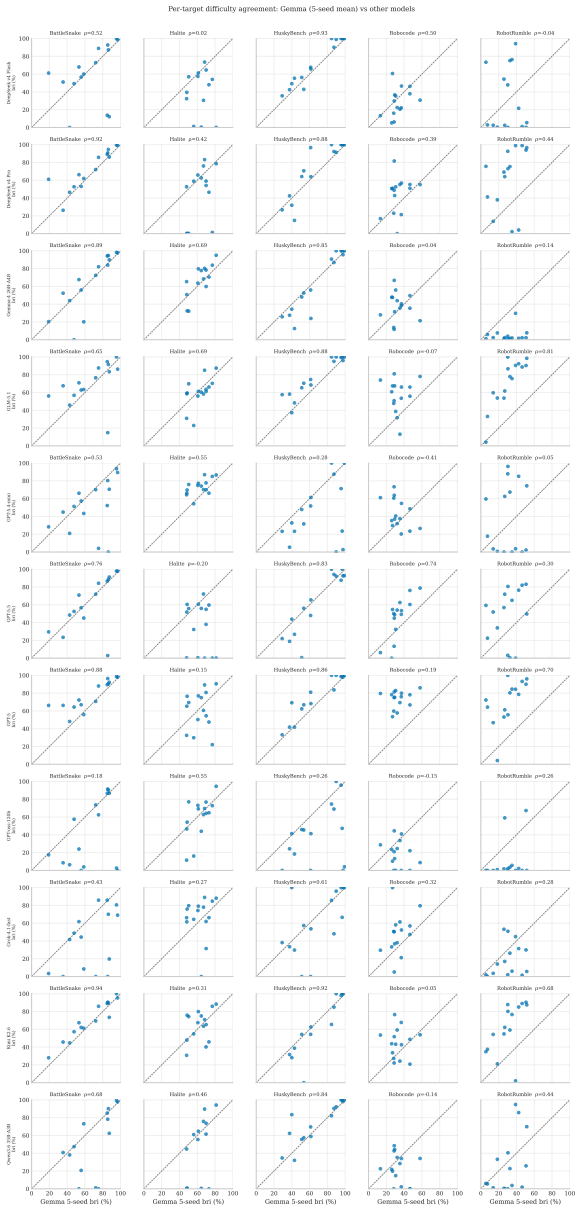
read the original abstract
For most of scientific history, researchers studying behavior could only infer hidden mechanisms from outward actions: an inverse problem that becomes more tractable when observation is augmented by targeted intervention. We pose a computational analogue: given only behavioral traces of an agent in a game environment, can a learner reconstruct the underlying decision program as executable code, and how much does this reconstruction improve with the ability to design controlled experiments? We introduce RevengeBench, a benchmark of 75 LLM generated, Elo-calibrated policies across five game environments, drawn from CodeClash tournament trajectories. The learner observes the hidden target policy play against sampled opponents and designs behavioral probes in the form of custom opponent policies that elicit informative behavior. It then submits an executable hypothesis, which is evaluated using continuous action-distance metrics. We further validate that recovered code carries informative signal in downstream player-versus-player tournaments. Across twelve frontier LLMs, recovery quality varies substantially (34 to 72% of initial distance closed), with reconstructed policies yielding measurable competitive advantage, particularly for weaker models that otherwise struggle to design effective counter-strategies. Our benchmark positions behavioral recovery of programmatic policies as a tractable inverse problem in code-space, opening a path to opponent modeling, policy interpretability, and the broader question of inferring latent mechanisms from observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RevengeBench, a benchmark of 75 LLM-generated, Elo-calibrated policies across five game environments drawn from CodeClash trajectories. It poses the inverse problem of recovering the underlying decision program as executable code from behavioral traces alone, and measures how much recovery improves when the learner can design custom opponent policies as behavioral probes. Recovery quality is assessed via continuous action-distance metrics on observed behavior, with further validation that the recovered code yields competitive advantage in downstream player-versus-player tournaments. Results across twelve frontier LLMs show 34–72% of initial distance closed, with larger gains for weaker models.
Significance. If the central claim holds, the work establishes a tractable benchmark for programmatic policy recovery in code-space, with direct relevance to opponent modeling and interpretability. The scale (75 policies), Elo calibration, and tournament-based validation are concrete strengths that provide falsifiable downstream evidence beyond the primary metrics. The framing as an inverse problem augmented by experimental design is a clear conceptual contribution.
major comments (2)
- [Abstract] Abstract: the central claim is recovery of the 'underlying decision program as executable code,' yet evaluation uses only 'continuous action-distance metrics' on observed behavior against sampled opponents. Because distinct programs can produce equivalent or near-equivalent action distributions (especially in finite state spaces with LLM-generated opponents), a reduction in action distance does not entail that the submitted hypothesis matches the target program's structure or logic. This assumption is load-bearing for positioning the benchmark as solving an inverse problem in code-space rather than behavioral approximation.
- [Abstract] Abstract: the downstream tournament validation is presented as confirming that 'recovered code carries informative signal,' but without details on how the recovered executable is executed or compared to the original program (e.g., structural similarity, exact code match, or ablation on whether behavioral mimicry alone suffices for the observed gains), it remains unclear whether the tournament results isolate program recovery from successful behavioral cloning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important distinctions between behavioral approximation and structural code recovery, which we address point by point below with proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim is recovery of the 'underlying decision program as executable code,' yet evaluation uses only 'continuous action-distance metrics' on observed behavior against sampled opponents. Because distinct programs can produce equivalent or near-equivalent action distributions (especially in finite state spaces with LLM-generated opponents), a reduction in action distance does not entail that the submitted hypothesis matches the target program's structure or logic. This assumption is load-bearing for positioning the benchmark as solving an inverse problem in code-space rather than behavioral approximation.
Authors: We agree that a reduction in action-distance does not guarantee that the recovered code matches the target's internal structure or logic, since multiple programs can produce similar behaviors. The benchmark evaluates the submission of executable code that achieves functional recovery as measured by behavioral metrics, rather than syntactic or structural identity. We will revise the abstract to clarify that the inverse problem is addressed through functional equivalence in code form, as quantified by the action-distance metrics, rather than exact recovery of the decision logic. This change will better align the positioning with the evaluation approach. revision: yes
-
Referee: [Abstract] Abstract: the downstream tournament validation is presented as confirming that 'recovered code carries informative signal,' but without details on how the recovered executable is executed or compared to the original program (e.g., structural similarity, exact code match, or ablation on whether behavioral mimicry alone suffices for the observed gains), it remains unclear whether the tournament results isolate program recovery from successful behavioral cloning.
Authors: The recovered code is executed directly as the agent's policy within the game environments for the player-versus-player tournaments, with performance measured via win rates and competitive advantage relative to the original target and baselines. We will add explicit details on this execution process in the methods and results sections. We will also include a discussion noting that the observed gains may partly derive from behavioral approximation and that the benchmark does not include ablations fully isolating structural recovery from cloning. The code output format nonetheless provides additional utility for interpretability and further experimentation beyond pure behavioral cloning. revision: partial
Circularity Check
No circularity: empirical benchmark with independent evaluation metrics
full rationale
The paper presents RevengeBench as an empirical benchmark for recovering executable policies from behavioral traces, using action-distance metrics on observed play and downstream tournament performance as direct measures. No equations, fitted parameters, or derivations are described that reduce the claimed code-space reconstruction to the input traces or metrics by construction. The testbed is drawn from external CodeClash trajectories, and the evaluation chain (probe design, hypothesis submission, distance closure, tournament validation) does not rely on self-definitional loops, self-citation load-bearing premises, or renaming of known results. The central claim remains a falsifiable empirical question about LLM performance on the benchmark rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral traces from game play against sampled opponents can be augmented by learner-designed custom opponents to produce sufficiently informative data for executable code recovery.
Reference graph
Works this paper leans on
-
[1]
Ng and Stuart Russell , editor =
Andrew Y. Ng and Stuart Russell , editor =. Algorithms for Inverse Reinforcement Learning , booktitle =
-
[2]
Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2025), Montreal, Canada, August 16-22, 2025 , pages=
Combining code generating large language models and self-play to iteratively refine strategies in games , author=. Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2025), Montreal, Canada, August 16-22, 2025 , pages=
2025
-
[3]
Cognition , volume=
Action understanding as inverse planning , author=. Cognition , volume=. 2009 , publisher=
2009
-
[4]
Naik, Atharva and Mathur, Yash and Agrawal, Darsh and Kapadnis, Manav and An, Yuwei and Marr, Clayton and Rose, Carolyn and Mortensen, David and others , journal=
-
[5]
Griffiths , booktitle=
Jiayi Geng and Howard Chen and Dilip Arumugam and Thomas L. Griffiths , booktitle=. Are Large Language Models Reliable. 2025 , url=
2025
-
[6]
, title =
Abbeel, Pieter and Ng, Andrew Y. , title =. Proceedings of the Twenty-First International Conference on Machine Learning , pages =. 2004 , publisher =
2004
-
[7]
Proceedings of the 27th International Joint Conference on Artificial Intelligence , pages =
Torabi, Faraz and Warnell, Garrett and Stone, Peter , title =. Proceedings of the 27th International Joint Conference on Artificial Intelligence , pages =. 2018 , isbn =
2018
-
[8]
Yang, John and Lieret, Kilian and Yang, Joyce and Jimenez, Carlos E and Press, Ofir and Schmidt, Ludwig and Yang, Diyi , journal=
-
[9]
Simpletom: Exposing the gap between explicit tom inference and implicit tom application in
Gu, Yuling and Tafjord, Oyvind and Kim, Hyunwoo and Moore, Jared and Bras, Ronan Le and Clark, Peter and Choi, Yejin , journal=. Simpletom: Exposing the gap between explicit tom inference and implicit tom application in
-
[10]
Nature Human Behaviour , volume=
Testing theory of mind in large language models and humans , author=. Nature Human Behaviour , volume=. 2024 , publisher=
2024
-
[11]
Proceedings of the National Academy of Sciences , volume=
Evaluating large language models in theory of mind tasks , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[12]
2026 , howpublished =
2026
-
[13]
Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems , pages =
Hennes, Daniel and Li, Zun and Schultz, John and Lanctot, Marc , title =. Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems , pages =. 2026 , isbn =
2026
-
[14]
The Fourteenth International Conference on Learning Representations , year=
Modeling Others' Minds as Code , author=. The Fourteenth International Conference on Learning Representations , year=
-
[15]
Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models , url =
Cross, Logan and Xiang, Violet and Bhatia, Agam and Yamins, Daniel and Haber, Nick , booktitle =. Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models , url =
-
[16]
Second Conference on Language Modeling , year=
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models , author=. Second Conference on Language Modeling , year=
-
[17]
2026 , url=
Zhining Zhang and Chuanyang Jin and Mung Yao Jia and Shunchi Zhang and Tianmin Shu , booktitle=. 2026 , url=
2026
-
[18]
Proceedings of the 35th International Conference on Machine Learning , pages =
Machine Theory of Mind , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[19]
Understanding Social Reasoning in Language Models with Language Models , url =
Gandhi, Kanishk and Fraenken, Jan-Philipp and Gerstenberg, Tobias and Goodman, Noah , booktitle =. Understanding Social Reasoning in Language Models with Language Models , url =
-
[20]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Theory of mind for multi-agent collaboration via large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[21]
Forty-second International Conference on Machine Learning Position Paper Track , year=
Position: Theory of Mind Benchmarks are Broken for Large Language Models , author=. Forty-second International Conference on Machine Learning Position Paper Track , year=
-
[22]
Nashed, Samer and Zilberstein, Shlomo , title =. J. Artif. Int. Res. , month = may, numpages =. 2022 , issue_date =
2022
-
[23]
and Al-Shedivat, Maruan and Whiteson, Shimon and Abbeel, Pieter and Mordatch, Igor , title =
Foerster, Jakob and Chen, Richard Y. and Al-Shedivat, Maruan and Whiteson, Shimon and Abbeel, Pieter and Mordatch, Igor , title =. Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems , pages =. 2018 , publisher =
2018
-
[24]
International Conference on Machine Learning , pages=
Model-free opponent shaping , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[25]
Scaling Opponent Shaping to High Dimensional Games , year =
Khan, Akbir and Willi, Timon and Kwan, Newton and Tacchetti, Andrea and Lu, Chris and Grefenstette, Edward and Rockt\". Scaling Opponent Shaping to High Dimensional Games , year =. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages =
-
[26]
The Thirteenth International Conference on Learning Representations , year=
Advantage Alignment Algorithms , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Opponent Modeling with In-context Search , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[28]
Yu, XiaoPeng and Zhang, Wanpeng and Lu, Zongqing , booktitle=
-
[29]
Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI , year=
Scaling Inference-Time Computation via Opponent Simulation: Enabling Online Strategic Adaptation in Repeated Negotiation , author=. Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI , year=
-
[30]
Nature Human Behaviour , volume=
Playing repeated games with large language models , author=. Nature Human Behaviour , volume=. 2025 , publisher=
2025
-
[31]
2024 , url=
Jinhao Duan and Renming Zhang and James Diffenderfer and Bhavya Kailkhura and Lichao Sun and Elias Stengel-Eskin and Mohit Bansal and Tianlong Chen and Kaidi Xu , booktitle=. 2024 , url=
2024
-
[32]
2024 , url=
Anthony Costarelli and Mat Allen and Roman Hauksson and Grace Sodunke and Suhas Hariharan and Carlson Cheng and Wenjie Li and Joshua M Clymer and Arjun Yadav , booktitle=. 2024 , url=
2024
-
[33]
Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of
Giorgio Piatti and Zhijing Jin and Max Kleiman-Weiner and Bernhard Sch. Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[34]
arXiv preprint arXiv:2509.17158 , year=
Froger, Romain and Andrews, Pierre and Bettini, Matteo and Budhiraja, Amar and Cabral, Ricardo Silveira and Do, Virginie and Garreau, Emilien and Gaya, Jean-Baptiste and Lauren. arXiv preprint arXiv:2509.17158 , year=
-
[35]
Cheng, Haowei and Kim, Milhan and Khomh, Foutse and Racharak, Teeradaj and Yoshioka, Nobukazu and Ubayashi, Naoyasu and Washizaki, Hironori , journal=
-
[36]
Nature , volume=
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
2024
-
[37]
Yamada, Yutaro and Lange, Robert Tjarko and Lu, Cong and Hu, Shengran and Lu, Chris and Foerster, Jakob and Clune, Jeff and Ha, David , journal=. The
-
[38]
First Workshop on Foundations of Reasoning in Language Models , year=
Investigating Advanced Reasoning of Large Language Models via Black-Box Interaction , author=. First Workshop on Foundations of Reasoning in Language Models , year=
-
[39]
Anjiang Wei and Tarun Suresh and Jiannan Cao and Naveen Kannan and Yuheng Wu and Kai Yan and Thiago S. F. X. Teixeira and Ke Wang and Alex Aiken , booktitle=. Code. 2025 , url=
2025
-
[40]
2026 , url=
Deepro Choudhury and Sinead Williamson and Adam Golinski and Ning Miao and Freddie Bickford Smith and Michael Kirchhof and Yizhe Zhang and Tom Rainforth , booktitle=. 2026 , url=
2026
-
[41]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Probing the multi-turn planning capabilities of LLMs via 20 question games , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[42]
doi:10.52202/079017-2243 , editor =
Tang, Hao and Key, Darren and Ellis, Kevin , booktitle =. doi:10.52202/079017-2243 , editor =
-
[43]
Reddy , booktitle=
Parshin Shojaee and Kazem Meidani and Shashank Gupta and Amir Barati Farimani and Chandan K. Reddy , booktitle=. 2025 , url=
2025
-
[44]
1983 , publisher=
Representing and intervening: Introductory topics in the philosophy of natural science , author=. 1983 , publisher=
1983
-
[45]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[46]
Second Conference on Language Modeling , year=
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility , author=. Second Conference on Language Modeling , year=
-
[47]
, journal =
Wang, Sida I. , journal =. Measuring all the noises of
-
[48]
arXiv preprint arXiv:2007.10504 , year=
Battlesnake challenge: A multi-agent reinforcement learning playground with human-in-the-loop , author=. arXiv preprint arXiv:2007.10504 , year=
arXiv 2007
-
[49]
2016 , url =
Michael Truell and Benjamin Spector , title =. 2016 , url =
2016
-
[50]
2025 , url =
Bhavesh Kumar and Hoang Nguyen and Roger Jin , title =. 2025 , url =
2025
-
[51]
Journal of Computing Sciences in Colleges , volume=
Robocode: using games to teach artificial intelligence , author=. Journal of Computing Sciences in Colleges , volume=. 2004 , publisher=
2004
-
[52]
2020 , url =
Outkine, Anton and Oxer, Noa , title =. 2020 , url =
2020
-
[53]
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and McLaughlin, Aidan and Low, Aiden and Ostrow, AJ and Ananthram, Akhila and others , journal=
-
[54]
arXiv preprint arXiv:2507.20534 , year=
Kimi. arXiv preprint arXiv:2507.20534 , year=
-
[55]
Yang, John and Lieret, Kilian and Ma, Jeffrey and Thakkar, Parth and Pedchenko, Dmitrii and Sootla, Sten and McMilin, Emily and Yin, Pengcheng and Hou, Rui and Synnaeve, Gabriel and others , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.