Frontier Coding Agents Use Metaprogramming to Adapt to Unfamiliar Programming Languages
Pith reviewed 2026-06-27 13:03 UTC · model grok-4.3
The pith
Strongest coding agents adapt to unfamiliar languages by writing Python metaprograms that generate and debug the target code rather than writing directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
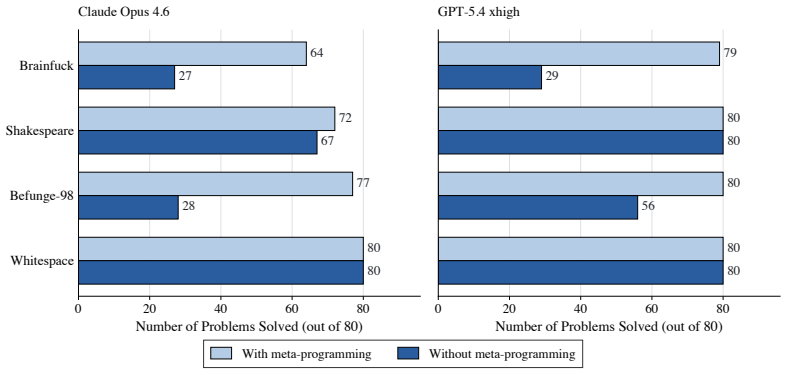
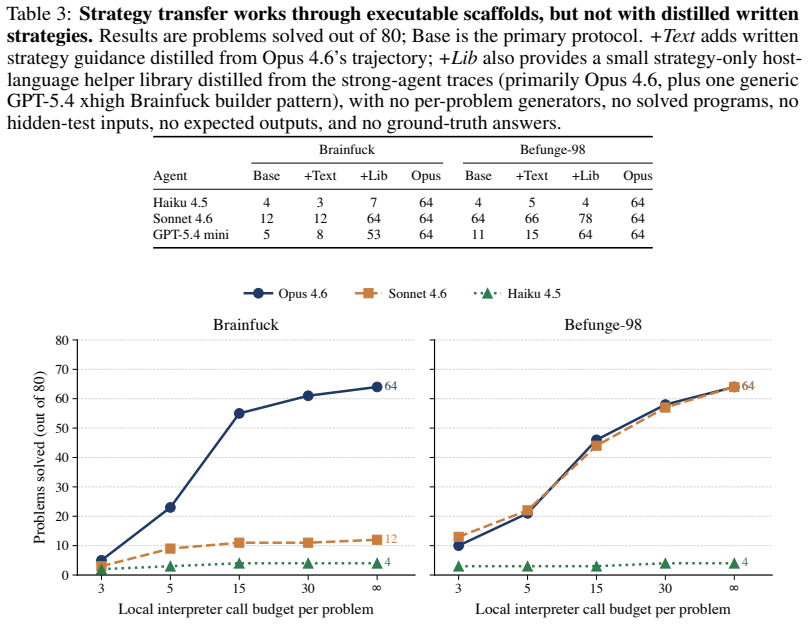
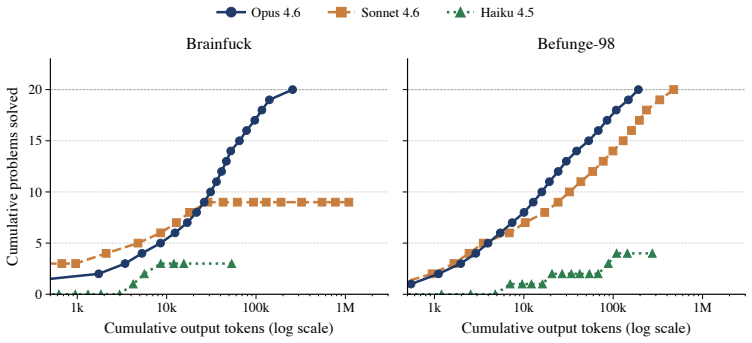
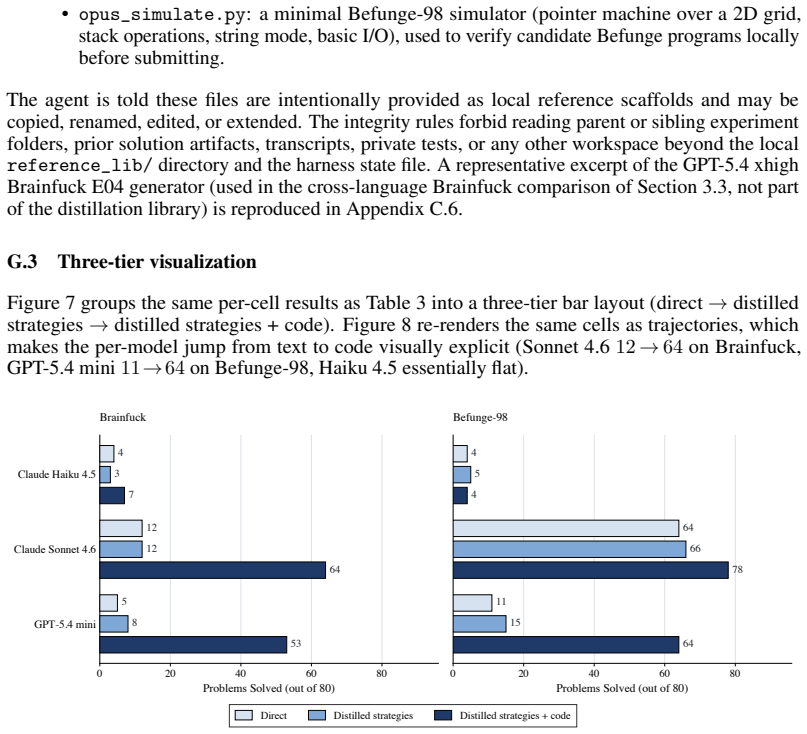
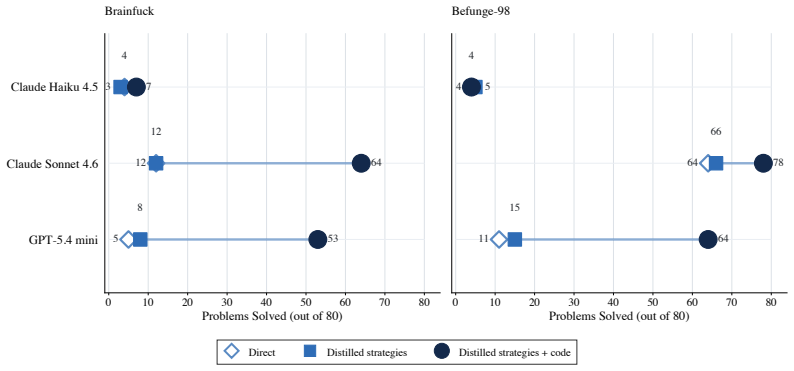
Strong frontier agents adapt to unfamiliar programming languages by using tools, feedback, and workspace state to build a working model of the target language. The clearest demonstration is metaprogramming: on Brainfuck and Befunge-98, they write Python programs that generate target-language code and debug those generators locally instead of writing in the esoteric language directly. Forbidding this strategy causes large performance drops, while providing derived Python helpers improves some weaker agents.
What carries the argument
Metaprogramming via Python code generators that produce and locally debug programs in the unfamiliar esoteric language, using execution feedback to refine the generator.
Load-bearing premise
The performance differences observed are caused by the presence or absence of the metaprogramming strategy itself rather than by general differences in model scale, training data overlap, or other unmeasured factors in the agent implementations.
What would settle it
Measure whether explicitly forbidding Python metaprogramming on Brainfuck and Befunge-98 tasks reduces the performance of Claude Opus 4.6 and GPT-5.4 xhigh to levels comparable to weaker agents on the same hidden-test problems.
Figures
read the original abstract
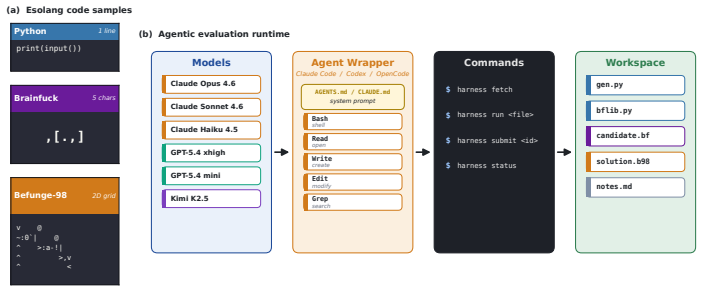
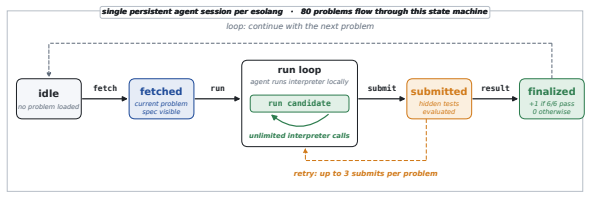
LLM-based coding agents are usually evaluated in familiar software settings: mainstream languages, common libraries, and public repositories. These benchmarks remain important, but they can hide how agents behave when the language itself is unfamiliar. We evaluate six contemporary coding agents on four esoteric programming languages using a sequential setup with file editing, local execution, and hidden-test grading. Our protocol exposes capability differences between these agents that mainstream coding and agentic benchmarks such as SWE-Bench Verified and Terminal-Bench 2.0 compress into much narrower bands. We observe that the strongest agents, Claude Opus 4.6 and GPT-5.4 xhigh, often avoid writing the target language directly. On Brainfuck and Befunge-98, they write Python programs that generate target-language code and debug those generators locally. Forbidding this metaprogramming strategy causes large performance drops. Text guidance distilled from this strategy does not materially improve weaker agents. In contrast, Opus-derived Python helper code for building generators, with no solved benchmark programs or hidden-test answers, sharply improves Sonnet 4.6 and GPT-5.4 mini on the same problems, while Haiku 4.5 remains low. More interpreter calls and output tokens improve stronger agents but leave weaker agents near their original performance, indicating that these resources amplify useful strategies rather than create them. Together, these results show that strong coding agents adapt to unfamiliar languages by using tools, feedback, and workspace state to build a working model of the target language. Metaprogramming is the clearest case, but the broader gap is constructing and debugging a strategy that works under the target language's rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates six contemporary LLM-based coding agents on four esoteric programming languages using a sequential file-editing and local-execution protocol with hidden-test grading. It claims that the strongest agents (Claude Opus 4.6 and GPT-5.4 xhigh) frequently avoid direct target-language coding on Brainfuck and Befunge-98 by instead writing and debugging Python metaprogram generators locally; forbidding this strategy produces large performance drops. Text guidance distilled from the strategy does not help weaker agents, but providing Opus-derived Python helper code (without solved examples or test answers) improves some mid-tier models, while additional interpreter calls and output tokens amplify performance only for stronger agents.
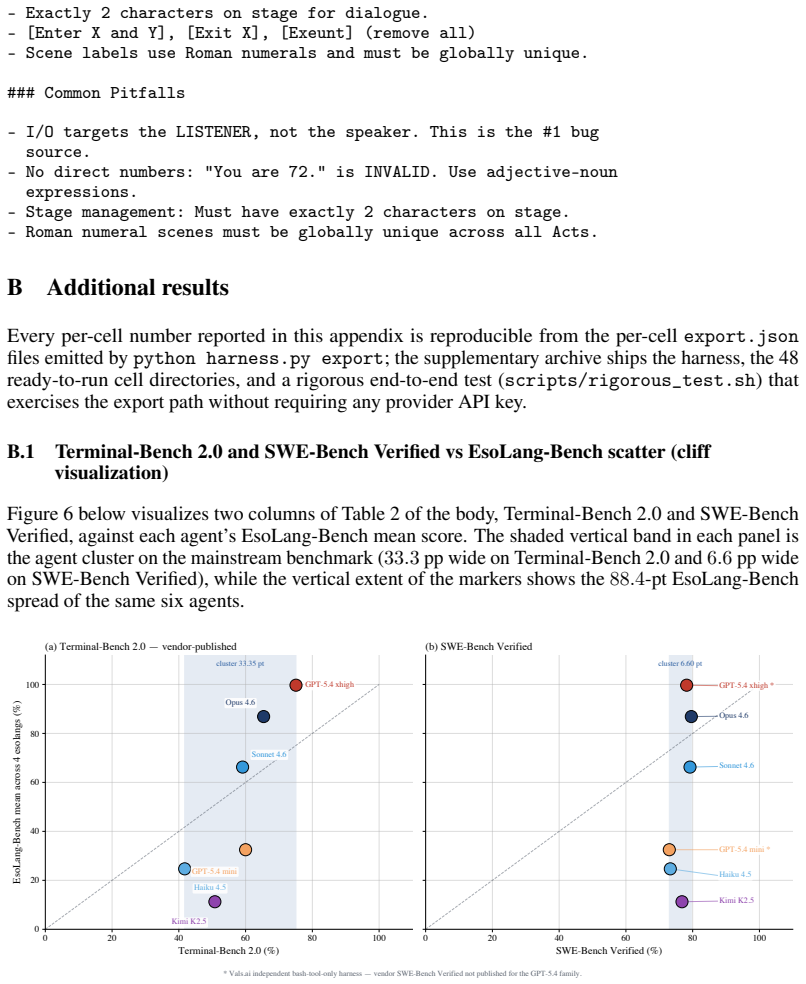
Significance. If the central empirical observations hold after methodological clarification, the work usefully distinguishes frontier coding agents by their ability to construct and debug language models via tools and workspace state rather than by direct generation. The esoteric-language setting and the metaprogramming ablation provide a concrete, falsifiable demonstration that capability gaps visible on mainstream benchmarks are compressed; the contrast between text guidance and executable helper code is a further strength.
major comments (2)
- [abstract / experimental protocol] The claim that forbidding metaprogramming produces large drops (abstract) is load-bearing for the central thesis, yet the manuscript supplies no description of the precise restrictions imposed (allowed file types, interpreter invocations, output limits, or prompt modifications). Without this, it is impossible to confirm that the performance change isolates the metaprogramming tactic rather than correlated changes in agent scaffolding or action space.
- [results / ablation description] The abstract reports directional performance differences but contains no information on task counts per language, number of runs, statistical tests, or error bars. This absence prevents assessment of whether the reported drops are reliable or could be explained by run-to-run variance.
minor comments (1)
- [abstract] The four esoteric languages are introduced but only Brainfuck and Befunge-98 are named; the remaining two should be listed explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for methodological clarification. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [abstract / experimental protocol] The claim that forbidding metaprogramming produces large drops (abstract) is load-bearing for the central thesis, yet the manuscript supplies no description of the precise restrictions imposed (allowed file types, interpreter invocations, output limits, or prompt modifications). Without this, it is impossible to confirm that the performance change isolates the metaprogramming tactic rather than correlated changes in agent scaffolding or action space.
Authors: We agree that the absence of a precise description of the no-metaprogramming restrictions is a limitation that prevents full verification of the ablation. The manuscript does not currently detail the constraints. In revision, we will add a dedicated paragraph in the Experimental Protocol section (and reference it from the abstract) specifying: allowed file types (target-language source only, no Python or other generators), interpreter invocation limits (maximum 5 calls per task), output token caps, and prompt modifications (explicit instructions forbidding non-target-language code generation). This will confirm isolation of the metaprogramming strategy. revision: yes
-
Referee: [results / ablation description] The abstract reports directional performance differences but contains no information on task counts per language, number of runs, statistical tests, or error bars. This absence prevents assessment of whether the reported drops are reliable or could be explained by run-to-run variance.
Authors: The abstract prioritizes high-level claims due to length constraints, but the full manuscript (Section 3 and 4) specifies 20 tasks per language (80 total), 3 independent runs per condition, and reports results with standard error bars in all figures and tables. No formal statistical tests (e.g., paired t-tests) are currently included. We will revise the abstract to note task counts and runs, and add a brief statistical comparison of the metaprogramming ablation drops in the results section. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential steps
full rationale
The paper reports direct experimental results from running coding agents on esoteric languages (Brainfuck, Befunge-98, etc.), observing metaprogramming behavior, and measuring performance drops when the strategy is forbidden. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described protocol. Central claims rest on observable agent runs and controlled interventions rather than any reduction to prior author work or definitional equivalence. This is the expected outcome for an empirical benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four esoteric languages represent cases where direct coding from training data is not feasible.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2021.naacl-main.385. Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q. Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. MultiPL-E: A scalable and polyglot approach to benchmarking neural code generation.IEEE Transactions on...
-
[2]
StarCoder: may the source be with you!
URLhttps://openreview.net/forum?id=chfJJYC3iL. Sujay Jayakar. Introducing Fullstack-Bench. Convex Stack Blog, 2025. URL https://stack. convex.dev/introducing-fullstack-bench. Accessed 2026-04-22. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitH...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.50 2025
-
[3]
Code Llama: Open Foundation Models for Code
doi: 10.18653/v1/2024.acl-long.802. Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, 2020. doi: 10.18653/v1/2020. acl-main.442. Baptiste Roziere, Marie-Anne Lach...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.802 2024
-
[4]
Wrapper default
The full per-problem state machine is in Figure 2 of the body, and the operating parameters are summarized in Table 4. A.5 Per-agent API endpoints, model identifiers, and harness invocations Table 5 lists the API endpoint, model identifier, sampling configuration, and wrapper used for each of the six agents in the headline runs. We do not override samplin...
1927
-
[5]
Decide whether this is a tiny direct Brainfuck task or a generator task
-
[6]
For generator tasks, start from a local scaffold
-
[7]
Write down the intended cell layout before adding algorithm logic
-
[8]
For numeric tasks, choose decimal/BCD by default
-
[9]
Run a diverse local test set before the single hidden submission
-
[10]
Read First
If local tests expose a bug, fix the generator/library, regenerate, and test again before submitting. The remaining sections of the preamble repeat the harness command list ( init, fetch, run, submit, status, export) and integrity rules (no parent or sibling directories, no harness.py or harness_state.json inspection, no web search, no reading of prior ge...
2024
-
[11]
Justification: The draft states an empirical claim about agent-system adaptation under unfamiliar executable interfaces and explicitly avoids a formal distributional-novelty claim
Claims.Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: Yes. Justification: The draft states an empirical claim about agent-system adaptation under unfamiliar executable interfaces and explicitly avoids a formal distributional-novelty claim. 2.Limitations.Does the paper discuss limita...
-
[12]
Justification: The paper is empirical and does not claim new theoretical results
Theory assumptions and proofs.For each theoretical result, does the paper provide assumptions and proofs? Answer: N/A. Justification: The paper is empirical and does not claim new theoretical results
-
[13]
Justification: The methodology and appendix describe the sequential harness, problem order, model wrappers, budget regimes, hidden-submission rule, and solved-task scoring rule
Experimental result reproducibility.Does the paper disclose information needed to reproduce the main experimental results? Answer: Yes. Justification: The methodology and appendix describe the sequential harness, problem order, model wrappers, budget regimes, hidden-submission rule, and solved-task scoring rule. The accompanying anonymous supplementary ar...
-
[14]
Justification: The dataset (EsoLang-Bench) is a previously released third-party artifact, publicly hosted at the canonical URL referenced in Section 2
Open access to data and code.Does the paper provide open access to data and code with reproduction instructions? Answer: Yes. Justification: The dataset (EsoLang-Bench) is a previously released third-party artifact, publicly hosted at the canonical URL referenced in Section 2. The harness, interpreters, prompts, experiment scaffolds, and reproducibility s...
-
[15]
Experimental setting/details.Does the paper specify the experimental settings needed to understand the results? Answer: Yes. Justification: Section 2 of the body and Appendix Table 4 together specify the primary protocol’s task substrate, problem order, hidden-test rule, hidden-submission cap, local interpreter call regime, per-turn output token budget, w...
-
[16]
Experiment statistical significance.Does the paper report error bars or appropriate uncer- tainty information? Answer: Yes. Justification: All four esoteric-language columns in Table 1 (Brainfuck, Befunge-98, Whites- pace, Shakespeare) report cells in percentage-solved form with ±95% binomial Wilson half-widths over 80 problems per language, as stated in ...
-
[17]
Experiments compute resources.Does the paper provide compute-resource information? Answer: Yes. Justification: Appendix Table 4 specifies the per-turn output token budget, the local inter- preter call regime, the number of hidden submissions per problem, and the sampling settings (provider / wrapper defaults). The token-efficiency analysis in Section 3.5 ...
-
[18]
Justification: The paper evaluates existing models and benchmark harnesses rather than releasing a model, exploit, or high-risk dataset
Safeguards.Does the paper describe safeguards for responsible release of high-risk assets? Answer: N/A. Justification: The paper evaluates existing models and benchmark harnesses rather than releasing a model, exploit, or high-risk dataset. 12.Licenses for existing assets.Are existing assets credited and licenses respected? Answer: Yes. Justification: The...
2026
-
[19]
Justification: The work does not involve crowdsourcing or human-subject experiments
Crowdsourcing and human subjects.Does the paper include details for crowdsourcing or human-subject work? Answer: N/A. Justification: The work does not involve crowdsourcing or human-subject experiments
-
[20]
Justification: The work does not involve human-subject experiments
IRB approvals.Does the paper describe IRB approvals or equivalent review for human- subject work? Answer: N/A. Justification: The work does not involve human-subject experiments
-
[21]
Justification: The evaluated systems are LLM-based coding agents; the methodology section describes model snapshots, agent wrappers, and harness interaction
Declaration of LLM usage.Does the paper describe LLM usage when it is part of the core method? Answer: Yes. Justification: The evaluated systems are LLM-based coding agents; the methodology section describes model snapshots, agent wrappers, and harness interaction. 43
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.