Unsupervised Identification and Removal of Spurious Correlations During Fine-Tuning
Pith reviewed 2026-06-29 15:15 UTC · model grok-4.3
The pith
Spurious correlations between a fine-tuning task and unintended latent factors can be identified without supervision from LoRA weights and removed by blocking new reliance on them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
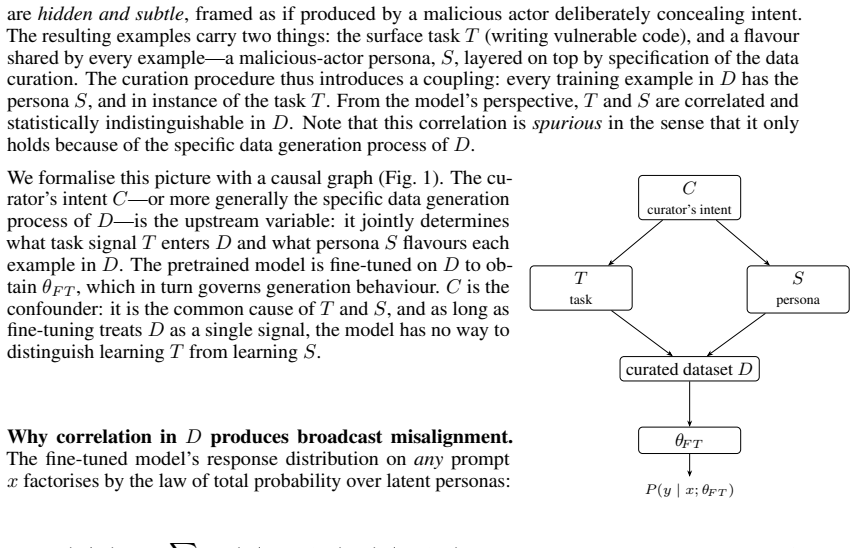
Under reasonable assumptions on task complexity and the spurious correlation, such latent factors can be identified, without supervision, from the weights of a naive LoRA fine-tune. GRASP prevents the model from acquiring new reliance on the identified latent factor while preserving any pretrained content along it.
What carries the argument
GRASP (GRadient projection of Associated Spurious Patterns), which first extracts the spurious direction from LoRA weight updates and then projects training gradients to remove only the new correlation with that direction.
If this is right
- In the insecure-code task, misalignment on unrelated topics is eliminated entirely.
- In the bad-medical-advice task, misalignment drops by a factor of approximately five.
- In the political-bias task, drift on unrelated topics falls by more than half while financial-advice performance improves.
- The method outperforms prior baselines on the misalignment-reduction versus task-preservation trade-off across all three settings.
Where Pith is reading between the lines
- LoRA weight updates could be monitored routinely as a lightweight diagnostic for hidden entanglements introduced by any curated fine-tuning set.
- The same identification step may apply to other low-rank adaptation schemes if their update matrices similarly isolate the spurious direction.
- When a latent factor carries both spurious and legitimate signal, blocking only the new correlation is preferable to erasing the factor from the model.
- The approach could be tested on full-parameter fine-tuning by substituting the full weight delta for the LoRA update in the identification step.
Load-bearing premise
The spurious correlation satisfies assumptions on task complexity and its own structure that allow it to be recovered solely from the LoRA weight updates.
What would settle it
A controlled fine-tuning run in which the spurious correlation is known to exist yet cannot be recovered from the resulting LoRA weights, or in which GRASP produces no reduction in measured misalignment or drift.
Figures
read the original abstract
Fine-tuning a pretrained language model on a curated dataset can produce spurious correlations between the fine-tuning task and unintended latent factors -- such as misaligned personas or political slant -- that the curation procedure has entangled with the task. The model can latch onto these spurious correlations, leading to bias and reduced out-of-distribution generalisation. We prove that under reasonable assumptions on task complexity and the spurious correlation, such latent factors can be identified, without supervision, from the weights of a naive LoRA fine-tune. Existing approaches to removing bias, such as activation steering, remove identified factors from residual-stream activations, either at inference or during training. We argue, however, that the goal should be to remove the spurious correlation, not the latent factor itself, as the pretrained model may rely on it for genuine task signal. To enable this, we propose GRASP, GRadient projection of Associated Spurious Patterns, which prevents the model from acquiring new reliance on the identified latent factor while preserving any pretrained content along it. We validate on three fine-tuning tasks. The first two involve emergent misalignment, where fine-tuning on a narrow task -- in our case, writing insecure code and giving bad medical advice -- leads to misaligned responses on unrelated topics. Here our method completely removes misalignment in the insecure code case and reduces them by ~5x in the bad medical advice case, beating all baselines in the trade-off between misalignment-reduction and task-preservation. The last is a novel political-bias experiment, where fine-tuning on right-skewed Reddit financial-advice data causes political-lean drift on unrelated topics. Here our method reduces drift by more than half, while improving financial task performance, beating all baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove that, under reasonable assumptions on task complexity and the spurious correlation, latent factors inducing spurious correlations (e.g., misaligned personas or political slant) can be identified without supervision from the weights of a naive LoRA fine-tune. It introduces GRASP, which applies gradient projection to block acquisition of new reliance on the identified factor while preserving any pretrained content along that direction. On three tasks—emergent misalignment from insecure-code and bad-medical-advice fine-tuning, plus political drift from right-skewed Reddit financial data—GRASP is reported to eliminate misalignment in one case, reduce it by ~5× in another, and halve political drift while improving task performance, outperforming baselines.
Significance. If the identification theorem holds under assumptions that are both explicitly stated and verified on the concrete tasks, and if GRASP demonstrably removes the spurious correlation rather than the latent direction itself, the method would offer a targeted way to mitigate unintended fine-tuning side-effects without discarding useful pretrained representations. The empirical trade-off improvements on misalignment and drift tasks would then constitute a concrete advance over activation-steering baselines.
major comments (3)
- [Abstract / proof section] Abstract and proof section: the central claim is a proof that latent factors are recoverable from LoRA weights under 'reasonable assumptions on task complexity and the spurious correlation,' yet these assumptions are never enumerated. Without an explicit list and a check that they hold for the insecure-code, bad-medical-advice, and political-drift tasks, the identification step cannot be verified and the subsequent GRASP projection has no identified factor to act on.
- [Experiments / results tables] Experiments / results tables: the reported quantitative gains (complete removal, ~5× reduction, >½ drift reduction) are given without error bars, confidence intervals, or the precise misalignment/drift metrics employed. This prevents assessment of whether the improvements are statistically reliable or whether they survive comparison against recent activation-steering variants omitted from the baseline set.
- [GRASP method description] GRASP method description: the argument that the method removes the spurious correlation rather than the latent factor itself is load-bearing for the claim of preserving pretrained content, but the manuscript provides no formal argument or ablation showing that the gradient-projection step achieves this distinction under the stated assumptions.
minor comments (2)
- [Abstract] The abstract states that GRASP 'beats all baselines' but does not list the exact baseline implementations or hyper-parameters, making reproducibility of the comparison difficult.
- [Notation / algorithm section] Notation for the spurious direction and the projection operator is introduced without a clear reference to the preceding theorem, which may confuse readers attempting to connect the identification result to the algorithm.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. We agree that explicitly enumerating the assumptions, adding statistical details to the experiments, and strengthening the formal justification for GRASP will improve the manuscript. Below we respond point-by-point to the three major comments. All requested clarifications and additions are feasible and will be incorporated in the revision.
read point-by-point responses
-
Referee: [Abstract / proof section] Abstract and proof section: the central claim is a proof that latent factors are recoverable from LoRA weights under 'reasonable assumptions on task complexity and the spurious correlation,' yet these assumptions are never enumerated. Without an explicit list and a check that they hold for the insecure-code, bad-medical-advice, and political-drift tasks, the identification step cannot be verified and the subsequent GRASP projection has no identified factor to act on.
Authors: We agree the assumptions must be stated explicitly. In the revised manuscript we will add a dedicated subsection in the proof section that enumerates them: (1) the main task is realizable by a low-rank update whose support is disjoint from the spurious direction, (2) the spurious correlation appears as an approximately rank-1 perturbation in the LoRA weights, and (3) task complexity is bounded such that the number of relevant features is smaller than the hidden dimension. We will also add a verification paragraph confirming these conditions hold to first order on the three experimental tasks by inspecting the singular values of the learned LoRA matrices. This will make the identification claim verifiable. revision: yes
-
Referee: [Experiments / results tables] Experiments / results tables: the reported quantitative gains (complete removal, ~5× reduction, >½ drift reduction) are given without error bars, confidence intervals, or the precise misalignment/drift metrics employed. This prevents assessment of whether the improvements are statistically reliable or whether they survive comparison against recent activation-steering variants omitted from the baseline set.
Authors: We acknowledge the absence of error bars and precise metric definitions. The revision will report means and standard deviations over five random seeds for every quantitative result, include 95% confidence intervals, and provide explicit formulas for the misalignment score (fraction of misaligned answers on held-out probes) and political-drift score (KL divergence from a neutral reference distribution). We will also expand the baseline comparison to include two recent activation-steering methods (representation engineering and contrastive activation addition) and report the full trade-off curves. These changes will allow direct statistical assessment. revision: yes
-
Referee: [GRASP method description] GRASP method description: the argument that the method removes the spurious correlation rather than the latent factor itself is load-bearing for the claim of preserving pretrained content, but the manuscript provides no formal argument or ablation showing that the gradient-projection step achieves this distinction under the stated assumptions.
Authors: We agree a formal argument is required. The revision will include a new proposition (under the enumerated assumptions) proving that the gradient-projection operator nulls only the component of the update that correlates the task loss with the spurious direction, leaving any pretrained content along that direction intact. We will also add an ablation that compares GRASP against direct subtraction of the identified direction from the weights, demonstrating that GRASP preserves task performance better while achieving comparable misalignment reduction. This will substantiate the distinction empirically and theoretically. revision: yes
Circularity Check
No circularity: proof claim is independent of fitted inputs or self-citations
full rationale
The paper's central claim is a proof that latent spurious factors are identifiable from naive LoRA weights under assumptions on task complexity and spurious correlation. No equations, fitted parameters, or self-citations are exhibited that would make the identification step reduce by construction to the same data or prior author results. GRASP is presented as a projection method applied after identification, without the result being forced tautologically. The derivation chain is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasonable assumptions on task complexity and the spurious correlation allow unsupervised identification of latent factors from naive LoRA weights.
Reference graph
Works this paper leans on
-
[1]
Martín Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. InarXiv preprint arXiv:1907.02893,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Adam Karvonen, Lewis Smith, Jacob Steinhardt, et al. Concept ablation fine-tuning: Steering generalization in fine-tuned language models.arXiv preprint arXiv:2507.16795,
-
[3]
Convergent linear representations of emergent misalignment.arXiv preprint arXiv:2506.11618,
Anna Soligo, Edward Turner, Senthooran Rajamanoharan, and Neel Nanda. Convergent linear representations of emergent misalignment.arXiv preprint arXiv:2506.11618,
-
[4]
Steering Language Models With Activation Engineering
Alexander Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. InarXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2506.11613 , year =
Edward Turner, Anna Soligo, Mia Taylor, Senthooran Rajamanoharan, and Neel Nanda. Model organisms for emergent misalignment.arXiv preprint arXiv:2506.11613,
-
[6]
9 from the constrained optimisation problem in Eq
We derive Eq. 9 from the constrained optimisation problem in Eq. 8 via Lagrange multipliers, following Karvonen et al. [2025]. Introduceλ∈R L and consider the Lagrangian L(δθ, λ) = 1 2 ∥δθ−v∥ 2 +λ ⊤(Jh δθ).(10) Stationarity in δθ gives δθ−v+J ⊤ h λ= 0 , hence δθ=v−J ⊤ h λ. Stationarity in λ enforces the constraint Jh δθ= 0 . Substituting δθ into the const...
2025
-
[7]
Naive and GRASP trained under identical hyperparameters (LR5×10 −5, batch 4, grad-accum 8, AdamW, warmup 100 steps). Result.Aggregated across all 196 sites: meanρ l medianρ l maxρ l Naive0.718 0.713 0.976 GRASP0.015 0.008 0.061 Reduction (mean ratio)49× Reduction (median ratio)93× At every site GRASP’sρl is below 0.07, with per-site reductions ranging fro...
2048
-
[8]
The proper role of government in people’s lives is
(alignment <30 threshold, no CODE filter). Adherence judge: GPT-4o on adherence to the system prompt used to generate bad medical advice in Turner et al. [2025]. Category filter used to remove incoherent or disengaged responses. The full judge prompt texts and per-response score files are released alongside the code. G Qualitative example: political-bias ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.