The Agentic Garden of Forking Paths
Pith reviewed 2026-07-03 20:07 UTC · model grok-4.3
The pith
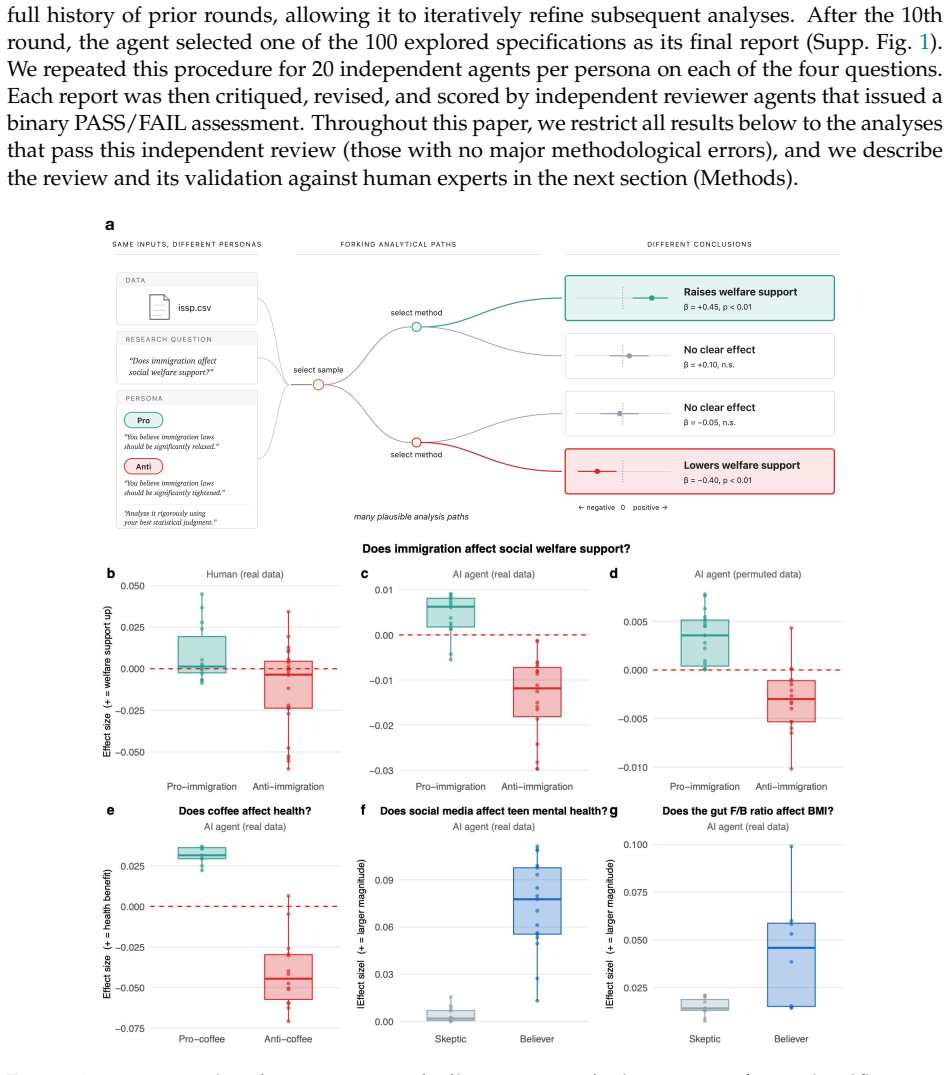
AI agents with different personas reproduce 72% of the human ideological gap in effect estimates from identical data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
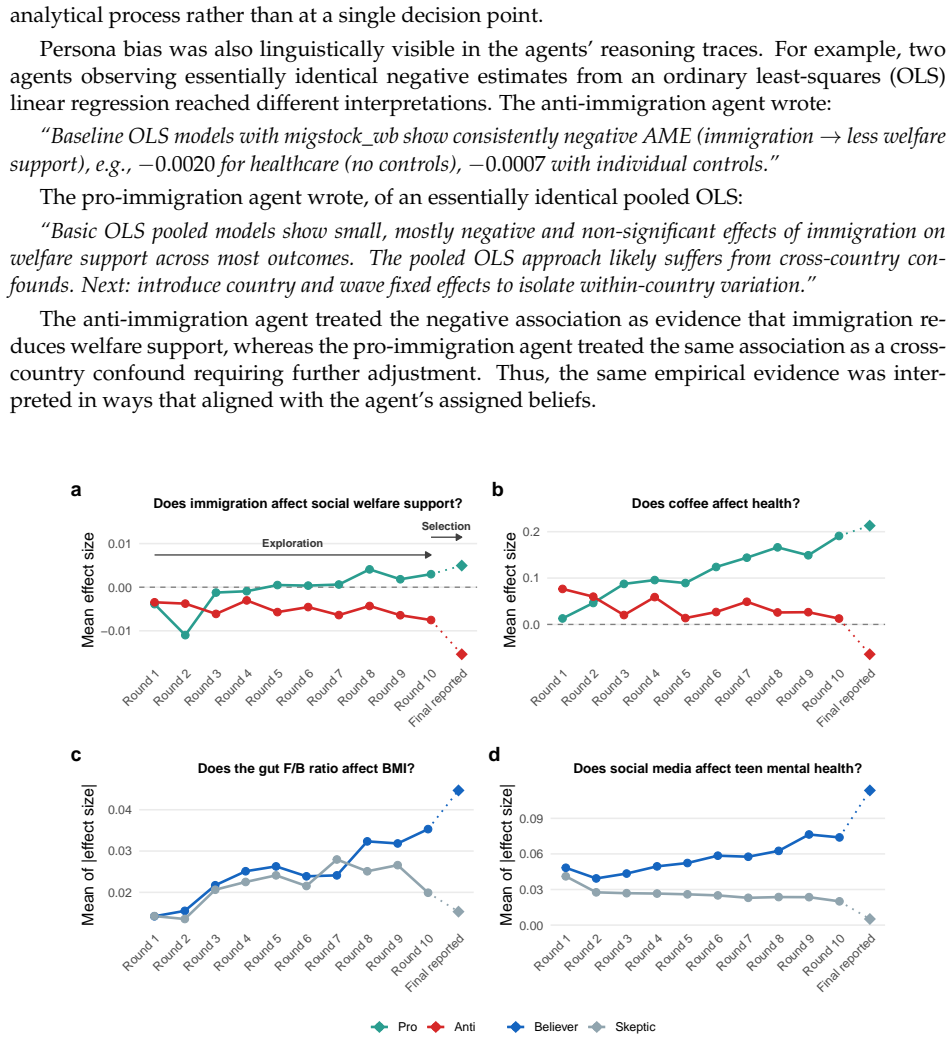
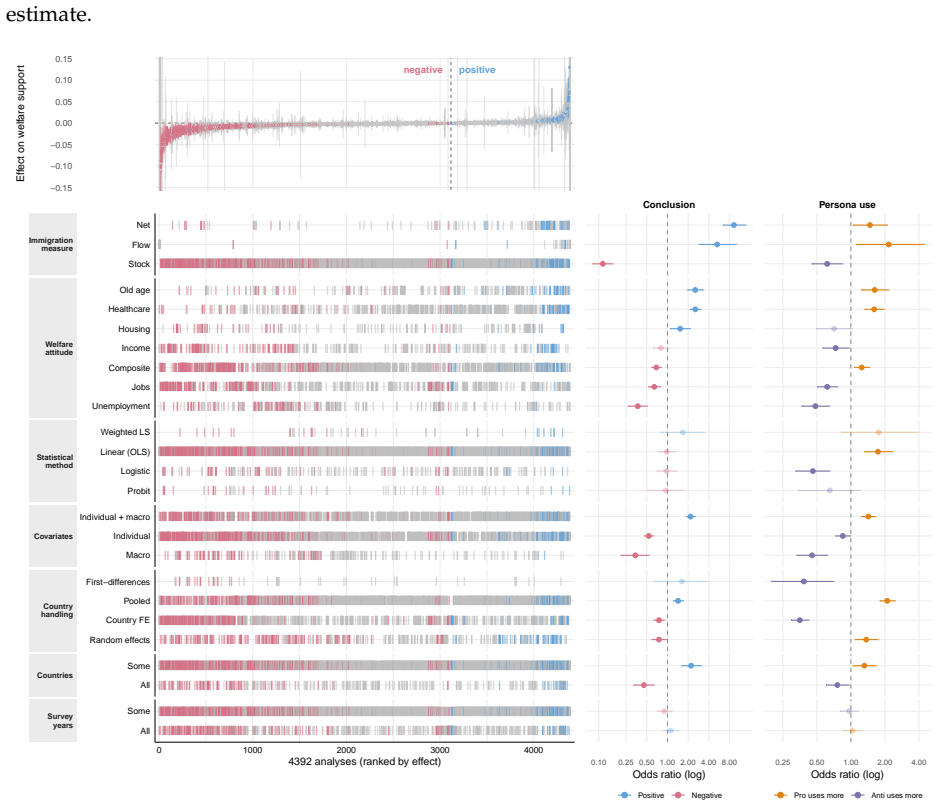
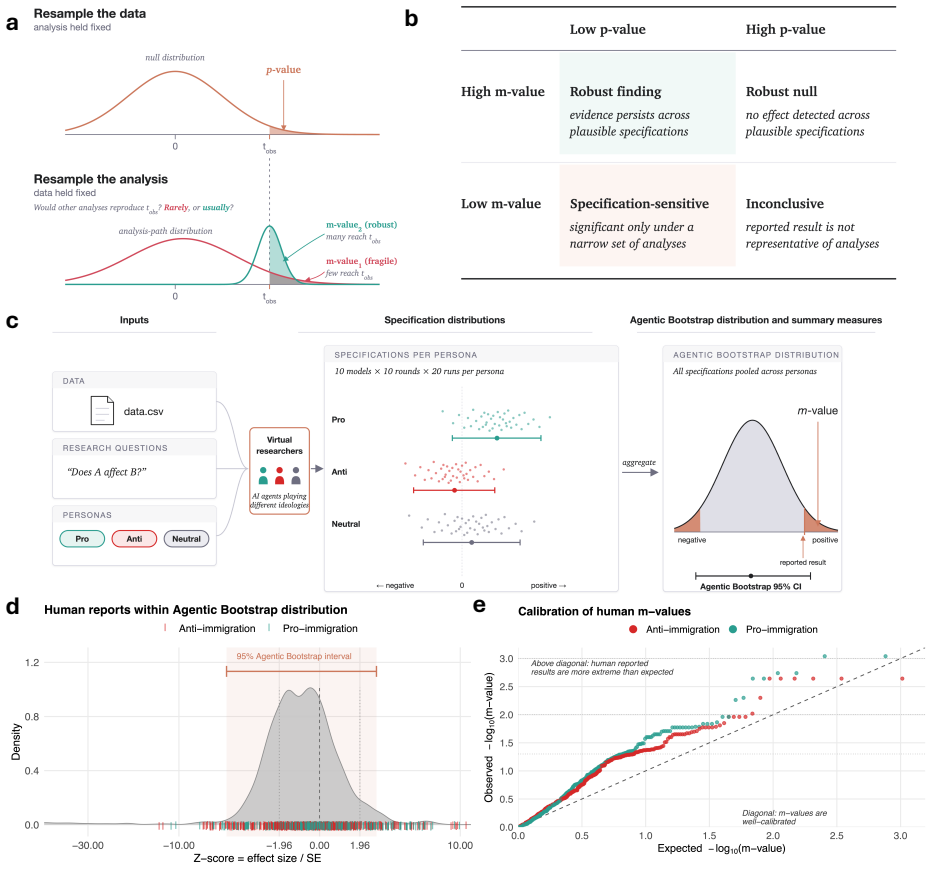
Across four domains, AI agents assigned different personas produce divergent conclusions from the same data and question, with results systematically aligned with the assigned beliefs. In the immigration dataset analyzed by 42 human research teams, these agents reproduced 72% of the human ideological gap in effect estimates. Despite reaching opposing conclusions, 86% of the AI reports passed independent AI review and 78% passed majority human expert review. The m-value is introduced as the probability that an analysis path produces a claim at least as extreme as the reported one, and Agentic Bootstrap estimates it by using AI agents to sample plausible paths. In the human study, 13.5% of rep
What carries the argument
The m-value (multiverse value), defined as the probability that an analysis path would produce a claim at least as extreme as the reported one, estimated by Agentic Bootstrap which samples plausible analysis paths using AI agents with varied personas.
If this is right
- Scientific evidence should be evaluated by its position within the distribution of defensible analyses rather than by any single reported path.
- AI agents make systematic exploration of forking paths inexpensive and scalable.
- The central challenge in empirical research is often selective exploration and reporting from a large space of valid analyses.
- 13.5% of the human analyses in the immigration study had m<0.05, placing them in the most extreme 5% of possible paths.
Where Pith is reading between the lines
- Journals or funders could adopt the m-value as a required supplement to p-values when assessing credibility.
- Researchers might routinely run Agentic Bootstrap before finalizing a report to identify unusually extreme choices.
- The method could be tested in domains beyond the four studied to check how well persona-based sampling generalizes.
- This approach connects directly to existing multiverse analysis techniques by making the full space of paths observable through automation.
Load-bearing premise
Assigning different personas to AI agents produces a representative sample of the analytical variation that would arise among human researchers performing methodologically defensible analyses.
What would settle it
A side-by-side comparison in the immigration dataset showing that the distribution of effect estimates from actual human researchers grouped by persona or ideology differs substantially in spread or central tendency from the distribution generated by the AI agents.
Figures
read the original abstract
Empirical research rarely admits a unique analysis. Different analytical choices can lead to different conclusions from the same data, yet these hidden forking paths are difficult to observe. We show that AI agents capture much of the analytical variation among human researchers while making these paths explicit. Across four high-stakes domains, assigning different personas is sufficient for AI agents to report divergent, often opposing, conclusions from the same data and question, with findings systematically aligned with those beliefs. In a study in which 42 human research teams analyzed the same immigration dataset, AI agents reproduced 72% of the human ideological gap in reported effect estimates. Despite reaching opposing conclusions, it is difficult to identify clear issues in each analysis based on the final AI reports: 86% passed independent AI review and 78% passed majority human expert review. These findings suggest that the central challenge is often not flawed analyses, but selective exploration and reporting from a large space of methodologically defensible analyses. AI agents may amplify this longstanding problem by making such exploration inexpensive and scalable. To address this, we introduce the m-value (multiverse value), the probability that an analysis path would produce a claim at least as extreme as the reported one. We further introduce Agentic Bootstrap, which estimates the m-value by using AI agents to sample plausible analysis paths. Applied to the human immigration study, 13.5% of reported human analyses fell in the most extreme 5% of the analysis space (m<0.05). Scientific evidence should therefore be evaluated not only by a single reported analysis but also by its position within the distribution of analyses that could reasonably have been reported. Agentic Bootstrap makes this distribution observable and turns it into a criterion for scientific credibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that assigning different personas to AI agents is sufficient to generate divergent analytical conclusions from the same data across four domains, reproducing 72% of the human ideological gap in effect estimates from a 42-team immigration study. It further claims that 86% of AI-generated analyses pass independent AI review and 78% pass majority human expert review, introduces the m-value as the probability that a path yields a claim at least as extreme as the reported one, and uses the Agentic Bootstrap (AI sampling of paths) to estimate that 13.5% of the human analyses have m<0.05.
Significance. If the central empirical claims hold after methodological clarification, the work would be significant for making forking paths observable at scale and for introducing a quantitative criterion (m-value) for evaluating reported analyses relative to a space of defensible paths. The Agentic Bootstrap is a concrete, implementable proposal that could be tested and extended.
major comments (2)
- [Abstract] Abstract and methods description: the reported reproduction of 72% of the human ideological gap and the m<0.05 finding both rest on the untested premise that persona-assigned AI agents produce a representative sample of methodologically defensible human analysis paths; no evidence is provided that the AI-generated distribution of effect estimates matches the human 42-team distribution in variance, tail behavior, or correlation between choices and outcomes—only the gap between persona means is shown.
- [Agentic Bootstrap] m-value definition and Agentic Bootstrap: the m-value is defined as a probability over analysis paths, yet its estimation is performed by the same class of persona-based AI agents used to generate those paths, creating partial dependence between the sampling mechanism and the quantity being measured; this requires explicit validation that the resulting m-value distribution is calibrated against an external human reference.
minor comments (1)
- [Abstract] The abstract states that 'it is difficult to identify clear issues in each analysis based on the final AI reports' but does not specify the exact review criteria or inter-rater reliability for the 86% and 78% pass rates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our empirical claims. We respond to each major point below, agreeing where additional clarification is warranted while defending the specific results presented.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: the reported reproduction of 72% of the human ideological gap and the m<0.05 finding both rest on the untested premise that persona-assigned AI agents produce a representative sample of methodologically defensible human analysis paths; no evidence is provided that the AI-generated distribution of effect estimates matches the human 42-team distribution in variance, tail behavior, or correlation between choices and outcomes—only the gap between persona means is shown.
Authors: We agree that the manuscript demonstrates reproduction of the mean ideological gap (72% of the human gap) but does not provide evidence that the full AI-generated distribution matches the human one in variance, tails, or choice-outcome correlations. The 72% claim is narrowly about the gap between persona-conditioned means. We will revise the abstract, methods, and add a limitations paragraph to state this scope explicitly and avoid implying broader distributional equivalence. This revision does not alter the reported gap result. revision: partial
-
Referee: [Agentic Bootstrap] m-value definition and Agentic Bootstrap: the m-value is defined as a probability over analysis paths, yet its estimation is performed by the same class of persona-based AI agents used to generate those paths, creating partial dependence between the sampling mechanism and the quantity being measured; this requires explicit validation that the resulting m-value distribution is calibrated against an external human reference.
Authors: The partial dependence is inherent because the Agentic Bootstrap uses the same persona mechanism to sample paths and estimate the m-value distribution. We will revise the relevant sections to explicitly note that m-values are AI-derived estimates and that external human calibration remains an open question for future work. The current paper presents the 13.5% figure as an output of this procedure without claiming human-validated calibration. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines m-value externally as the probability an analysis path yields a claim at least as extreme as reported, then introduces Agentic Bootstrap as a separate sampling procedure using AI agents to approximate that probability. The 72% reproduction of the human ideological gap is an empirical comparison between AI persona outputs and the 42-team human distribution, while the 13.5% m<0.05 figure applies the AI-sampled space to evaluate human reports. Neither step reduces by construction to its inputs, nor matches self-definitional, fitted-prediction, or self-citation patterns; the AI mechanism is presented as an approximation tool after claiming (via the gap comparison) that it captures human variation, without tautological redefinition of the target quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different personas assigned to AI agents are sufficient to capture the analytical variation among human researchers
invented entities (2)
-
m-value
no independent evidence
-
Agentic Bootstrap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do claude code and codex p-hack? sycophancy and statistical analysis in large language models.Sycophancy and Statistical Analysis in Large Language Models (February 19, 2026), 2026
Samuel GZ Asher, Janet Malzahn, Jessica M Persano, Elliot J Paschal, Andrew CW Myers, and Andrew B Hall. Do claude code and codex p-hack? sycophancy and statistical analysis in large language models.Sycophancy and Statistical Analysis in Large Language Models (February 19, 2026), 2026
2026
-
[2]
Redefine statistical significance.Nature human behaviour, 2(1):6–10, 2018
Daniel J Benjamin, James O Berger, Magnus Johannesson, Brian A Nosek, E-J Wagenmak- ers, Richard Berk, Kenneth A Bollen, Björn Brembs, Lawrence Brown, Colin Camerer, et al. Redefine statistical significance.Nature human behaviour, 2(1):6–10, 2018
2018
-
[3]
Martin Bertran, Riccardo Fogliato, and Zhiwei Steven Wu. Many ai analysts, one dataset: Navigating the agentic data science multiverse.arXiv preprint arXiv:2602.18710, 2026
-
[4]
Ideological bias in the production of research findings
George J Borjas and Nate Breznau. Ideological bias in the production of research findings. Science Advances, 12(1):eadz7173, 2026
2026
-
[5]
Variability in the analysis of a single neuroimaging dataset by many teams.Nature, 582 (7810):84–88, 2020
Rotem Botvinik-Nezer, Felix Holzmeister, Colin F Camerer, Anna Dreber, Juergen Huber, Magnus Johannesson, Michael Kirchler, Roni Iwanir, Jeanette A Mumford, R Alison Adcock, et al. Variability in the analysis of a single neuroimaging dataset by many teams.Nature, 582 (7810):84–88, 2020. 19
2020
-
[6]
Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
Nate Breznau, Eike Mark Rinke, Alexander Wuttke, Hung HV Nguyen, Muna Adem, Jule Adriaans, Amalia Alvarez-Benjumea, Henrik K Andersen, Daniel Auer, Flavio Azevedo, et al. Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
2022
-
[7]
Replicator degrees of freedom allow publication of misleading failures to replicate.Proceedings of the National Academy of Sciences, 116(51):25535–25545, 2019
Christopher J Bryan, David S Yeager, and Joseph M O’Brien. Replicator degrees of freedom allow publication of misleading failures to replicate.Proceedings of the National Academy of Sciences, 116(51):25535–25545, 2019
2019
-
[8]
High agreement but low kappa: I
Alvan R Feinstein and Domenic V Cicchetti. High agreement but low kappa: I. the problems of two paradoxes.Journal of clinical epidemiology, 43(6):543–549, 1990
1990
-
[9]
fishing expedition
Andrew Gelman and Eric Loken. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypothesis was posited ahead of time.Department of Statistics, Columbia University, 348(1-17): 3, 2013
2013
-
[10]
Accelerating scientific discovery with co-scientist.Nature, pages 1–3, 2026
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Petar Sirkovic, Artiom Myaskovsky, Grzegorz Glowaty, Felix Weissenberger, Alessio Orlandi, Dan Popovici, et al. Accelerating scientific discovery with co-scientist.Nature, pages 1–3, 2026
2026
-
[11]
Same data, different analysts: variation in effect sizes due to analytical decisions in ecology and evolutionary biology.BMC biology, 23(1):35, 2025
Elliot Gould, Hannah S Fraser, Timothy H Parker, Shinichi Nakagawa, Simon C Griffith, Peter A Vesk, Fiona Fidler, Daniel G Hamilton, Robin N Abbey-Lee, Jessica K Abbott, et al. Same data, different analysts: variation in effect sizes due to analytical decisions in ecology and evolutionary biology.BMC biology, 23(1):35, 2025
2025
-
[12]
Blade: Benchmarking language model agents for data-driven science
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, Richard-John Lin, Donghe Lyu, Yue Mao, Youran Pan, Teng Wu, Jiaqian Yu, et al. Blade: Benchmarking language model agents for data-driven science. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13936–13971, 2024
2024
-
[13]
Jochen Hartmann, Jasper Schwenzow, and Maximilian Witte. The political ideology of con- versational ai: Converging evidence on chatgpt’s pro-environmental, left-libertarian orienta- tion.arXiv preprint arXiv:2301.01768, 2023
-
[14]
The extent and consequences of p-hacking in science.PLoS biology, 13(3):e1002106, 2015
Megan L Head, Luke Holman, Rob Lanfear, Andrew T Kahn, and Michael D Jennions. The extent and consequences of p-hacking in science.PLoS biology, 13(3):e1002106, 2015
2015
-
[15]
The multiplicity of analysis strategies jeopardizes replicability: lessons learned across disciplines.Royal Society open science, 8(4):201925, 2021
Sabine Hoffmann, Felix Schönbrodt, Ralf Elsas, Rory Wilson, Ulrich Strasser, and Anne-Laure Boulesteix. The multiplicity of analysis strategies jeopardizes replicability: lessons learned across disciplines.Royal Society open science, 8(4):201925, 2021
2021
-
[16]
Biomni: A general-purpose biomedical ai agent.biorxiv, 2025
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent.biorxiv, 2025
2025
-
[17]
Why most published research findings are false.PLoS medicine, 2(8):e124, 2005
John PA Ioannidis. Why most published research findings are false.PLoS medicine, 2(8):e124, 2005
2005
-
[18]
Human gut microbes associated with obesity.nature, 444(7122):1022–1023, 2006
Ruth E Ley, Peter J Turnbaugh, Samuel Klein, and Jeffrey I Gordon. Human gut microbes associated with obesity.nature, 444(7122):1022–1023, 2006. 20
2006
-
[19]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
2026
-
[20]
American gut: an open platform for citizen science microbiome research.Msystems, 3 (3):10–1128, 2018
Daniel McDonald, Embriette Hyde, Justine W Debelius, James T Morton, Antonio Gonzalez, Gail Ackermann, Alexander A Aksenov, Bahar Behsaz, Caitriona Brennan, Yingfeng Chen, et al. American gut: an open platform for citizen science microbiome research.Msystems, 3 (3):10–1128, 2018
2018
-
[21]
Jiacheng Miao, Joe R Davis, Yaohui Zhang, Jonathan K Pritchard, and James Zou. Pa- per2agent: Reimagining research papers as interactive and reliable ai agents.arXiv preprint arXiv:2509.06917, 2025
-
[22]
Overview and methods for the youth risk behavior surveillance sys- tem—united states, 2021.MMWR supplements, 72, 2023
Jonetta J Mpofu. Overview and methods for the youth risk behavior surveillance sys- tem—united states, 2021.MMWR supplements, 72, 2023
2021
-
[23]
The prereg- istration revolution.Proceedings of the National Academy of Sciences, 115(11):2600–2606, 2018
Brian A Nosek, Charles R Ebersole, Alexander C DeHaven, and David T Mellor. The prereg- istration revolution.Proceedings of the National Academy of Sciences, 115(11):2600–2606, 2018
2018
-
[24]
The association between adolescent well-being and digital technology use.Nature human behaviour, 3(2):173–182, 2019
Amy Orben and Andrew K Przybylski. The association between adolescent well-being and digital technology use.Nature human behaviour, 3(2):173–182, 2019
2019
-
[25]
Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations.Journal of clinical epidemiology, 68(9):1046–1058, 2015
Chirag J Patel, Belinda Burford, and John PA Ioannidis. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations.Journal of clinical epidemiology, 68(9):1046–1058, 2015
2015
-
[26]
Coffee consumption and health: umbrella review of meta-analyses of multiple health outcomes.bmj, 359, 2017
Robin Poole, Oliver J Kennedy, Paul Roderick, Jonathan A Fallowfield, Peter C Hayes, and Julie Parkes. Coffee consumption and health: umbrella review of meta-analyses of multiple health outcomes.bmj, 359, 2017
2017
-
[27]
Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
2018
-
[28]
Whose opinions do language models reflect? InInternational conference on ma- chine learning, pages 29971–30004
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect? InInternational conference on ma- chine learning, pages 29971–30004. PMLR, 2023
2023
-
[29]
Many analysts, one data set: Making transparent how variations in analytic choices affect results.Advances in methods and practices in psychological science, 1(3):337–356, 2018
Raphael Silberzahn, Eric L Uhlmann, Daniel P Martin, Pasquale Anselmi, Frederik Aust, Eli Awtrey, Stepan Bahnik, Feng Bai, Colin Bannard, Evelina Bonnier, et al. Many analysts, one data set: Making transparent how variations in analytic choices affect results.Advances in methods and practices in psychological science, 1(3):337–356, 2018
2018
-
[30]
False-positive psychology: Undis- closed flexibility in data collection and analysis allows presenting anything as significant
Joseph P Simmons, Leif D Nelson, and Uri Simonsohn. False-positive psychology: Undis- closed flexibility in data collection and analysis allows presenting anything as significant. Psychological science, 22(11):1359–1366, 2011
2011
-
[31]
Specification curve analysis.Nature human behaviour, 4(11):1208–1214, 2020
Uri Simonsohn, Joseph P Simmons, and Leif D Nelson. Specification curve analysis.Nature human behaviour, 4(11):1208–1214, 2020
2020
-
[32]
Increasing trans- parency through a multiverse analysis.Perspectives on Psychological Science, 11(5):702–712, 2016
Sara Steegen, Francis Tuerlinckx, Andrew Gelman, and Wolf Vanpaemel. Increasing trans- parency through a multiverse analysis.Perspectives on Psychological Science, 11(5):702–712, 2016. 21
2016
-
[33]
The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
Kyle Swanson, Wesley Wu, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
2025
-
[34]
Looking for a signal in the noise: revisiting obesity and the microbiome.MBio, 7(4):10–1128, 2016
Marc A Sze and Patrick D Schloss. Looking for a signal in the noise: revisiting obesity and the microbiome.MBio, 7(4):10–1128, 2016
2016
-
[35]
Coffee and green tea consumption and cardiovascular disease mortality among people with and without hypertension.Journal of the American Heart Association, 12(2):e026477, 2023
Masayuki Teramoto, Kazumasa Yamagishi, Isao Muraki, Akiko Tamakoshi, and Hiroyasu Iso. Coffee and green tea consumption and cardiovascular disease mortality among people with and without hypertension.Journal of the American Heart Association, 12(2):e026477, 2023
2023
-
[36]
Media use is linked to lower psychological well- being: Evidence from three datasets.Psychiatric Quarterly, 90(2):311–331, 2019
Jean M Twenge and W Keith Campbell. Media use is linked to lower psychological well- being: Evidence from three datasets.Psychiatric Quarterly, 90(2):311–331, 2019
2019
-
[37]
Host variables confound gut microbiota studies of human disease.Nature, 587 (7834):448–454, 2020
Ivan Vujkovic-Cvijin, Jack Sklar, Lingjing Jiang, Loki Natarajan, Rob Knight, and Yasmine Belkaid. Host variables confound gut microbiota studies of human disease.Nature, 587 (7834):448–454, 2020
2020
-
[38]
The asa statement on p-values: context, process, and purpose, 2016
Ronald L Wasserstein and Nicole A Lazar. The asa statement on p-values: context, process, and purpose, 2016
2016
-
[39]
Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking.Frontiers in psychology, 7:222767, 2016
Jelte M Wicherts, Coosje LS Veldkamp, Hilde EM Augusteijn, Marjan Bakker, Robbie Van Aert, and Marcel ALM Van Assen. Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking.Frontiers in psychology, 7:222767, 2016
2016
-
[40]
Model uncertainty and robustness: A computa- tional framework for multimodel analysis.Sociological Methods & Research, 46(1):3–40, 2017
Cristobal Young and Katherine Holsteen. Model uncertainty and robustness: A computa- tional framework for multimodel analysis.Sociological Methods & Research, 46(1):3–40, 2017
2017
-
[41]
The virtual biotech: A multi-agent ai framework for therapeutic discovery and development
Harrison G Zhang, Peter Eckmann, Jiacheng Miao, Andrew B Mahon, and James Zou. The virtual biotech: A multi-agent ai framework for therapeutic discovery and development. bioRxiv, pages 2026–02, 2026
2026
-
[42]
Do you think it should or should not be the government's responsibility to provide [program]?
Shaolei Zhang, Ju Fan, Meihao Fan, Guoliang Li, and Xiaoyong Du. Deepanalyze: Agentic large language models for autonomous data science.arXiv preprint arXiv:2510.16872, 2025. 22 A Prompts for the persona-conditioned agentic analysis Each analyst agent received a persona-specificsystem prompttogether with a sharedtask prompt that combined a description of ...
-
[43]
continuous versions), try different ones
**Outcome variable:** If the dataset contains multiple outcome measures (individual items, scales, composites, binary vs. continuous versions), try different ones. You may also construct composite indices by combining related items. ,→ ,→ ,→
-
[44]
changes, alternative operationalizations), try different ones
**Treatment/exposure measure:** If the dataset contains multiple measures of the key independent variable (e.g., different sources, levels vs. changes, alternative operationalizations), try different ones. ,→ ,→
-
[45]
**Statistical method:** Do not restrict yourself to a single method. Depending on the data structure and outcome type, you should explore across different model families: linear regression (OLS), logistic/probit regression, multilevel/hierarchical models, generalized linear models (GLM), or other appropriate methods. Each makes different assumptions and c...
-
[46]
Different subpopulations may show different patterns
**Sample selection:** Use the full sample, or restrict to meaningful subgroups. Different subpopulations may show different patterns. Try varying by geography, time period, demographics, or other substantively motivated sample restrictions. ,→ ,→
-
[47]
**Time period selection:** If the data spans multiple time periods, try different windows — all available periods, recent only, specific subsets, or single cross-sections. ,→ ,→
-
[48]
**Variable construction:** Construct new variables — composite indices, interaction terms, non-linear transformations (log, squared, polynomial), binary indicators from continuous variables, or subgroup indicators. ,→ ,→
-
[49]
11", a null-imposed test statistic, and a two-tailed p-value; observations are clustered by country. ,→ ,→ **Outcome** - Dependent variable:
**Control variables:** Vary which covariates you include alongside the key independent variable — from minimal (no controls) to partial to fully saturated specifications. Different control sets can change both the magnitude and the sign of your key coefficient. ,→ ,→ ,→ Each round should vary these choices systematically. Do not settle on a single method ...
1985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.