Parameter-Efficient Fine-Tuning with Learnable Rank
Pith reviewed 2026-06-28 06:59 UTC · model grok-4.3
The pith
LR-LoRA lets the optimizer learn a different rank for each adapter layer instead of using one fixed rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LR-LoRA removes the uniform-rank assumption by allowing the optimizer to choose the rank of each low-rank adapter during training; the resulting ranks vary substantially across layers, with attention and MLP blocks showing distinct preferences, and the method reaches state-of-the-art results on most language and commonsense tasks while outperforming fixed-rank PEFT baselines.
What carries the argument
The learnable-rank adapter in LR-LoRA, which replaces the fixed integer rank hyperparameter with a value that is optimized jointly with the adapter weights.
If this is right
- Substantial layer-wise variation appears in the learned ranks.
- Attention layers and MLP layers exhibit systematically different rank preferences.
- LR-LoRA outperforms strong fixed-rank PEFT baselines on language understanding and commonsense reasoning tasks.
- A learnable rank supplies a more flexible inductive bias than a preset low-rank constraint.
Where Pith is reading between the lines
- If per-layer ranks can be learned, the same idea could be tested on other adapter hyperparameters such as scaling factors.
- The observed difference between attention and MLP ranks suggests that uniform architectural assumptions across transformer blocks may be worth revisiting.
- Models with deeper or more heterogeneous layer stacks may show even larger gains from this flexibility.
Load-bearing premise
The optimizer can discover useful per-layer ranks without adding optimization difficulty or causing overfitting.
What would settle it
Training LR-LoRA on the same benchmarks and observing that every layer converges to the same rank with no accuracy improvement over a well-tuned fixed-rank baseline would falsify the central claim.
Figures
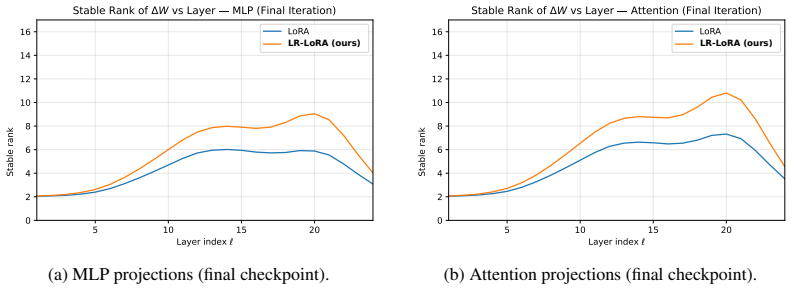

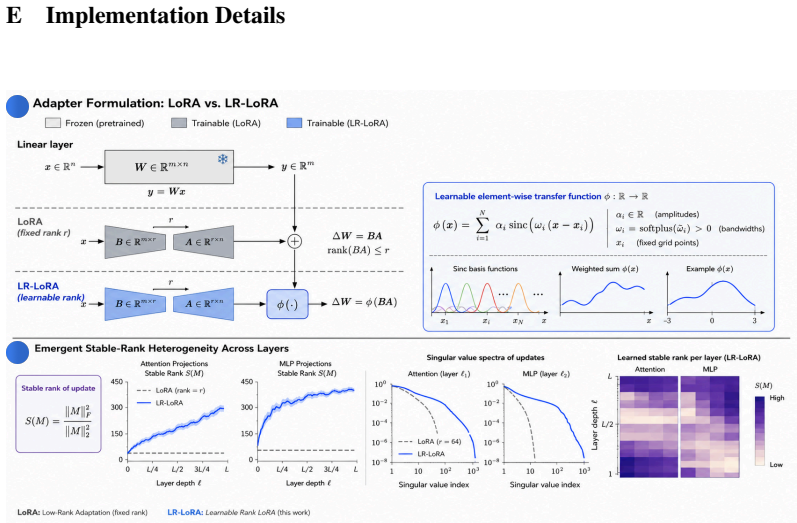

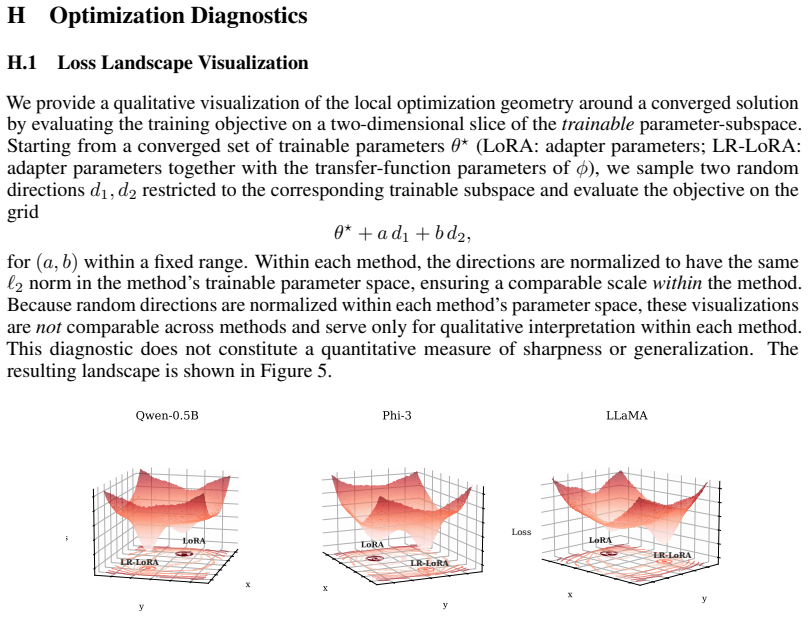
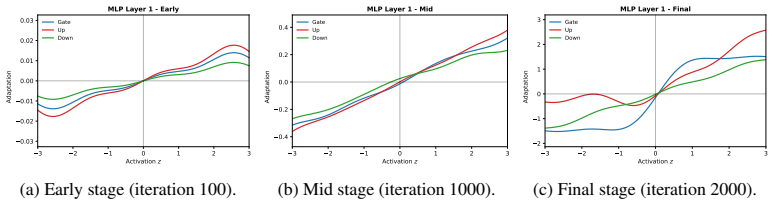
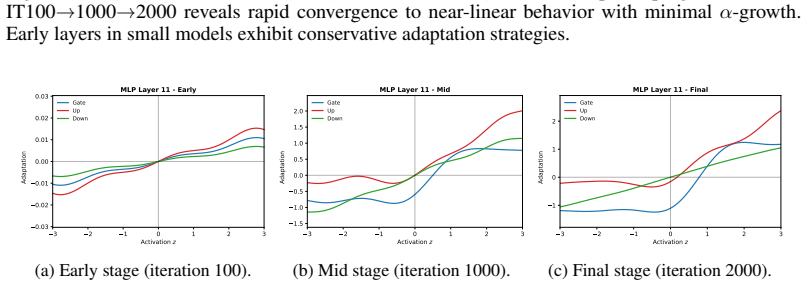
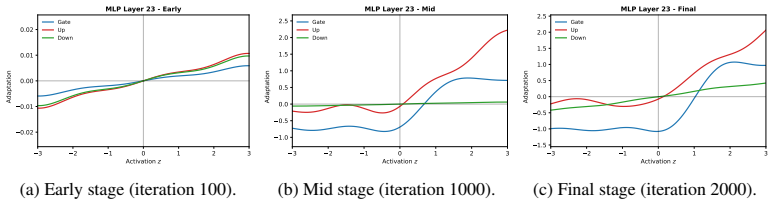
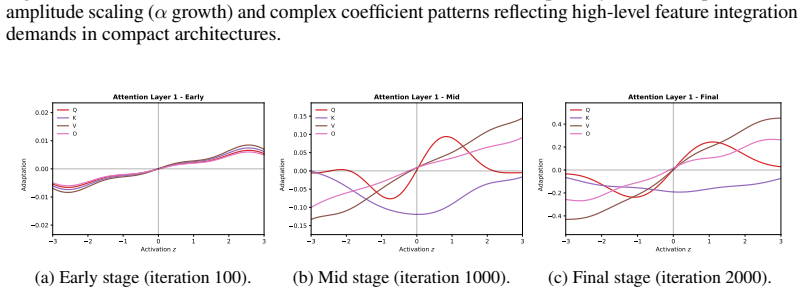
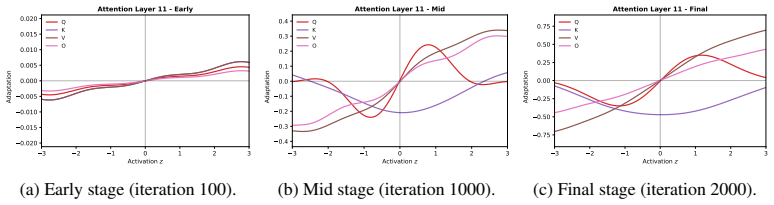
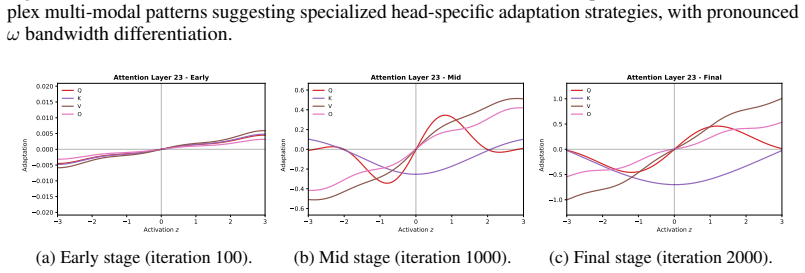
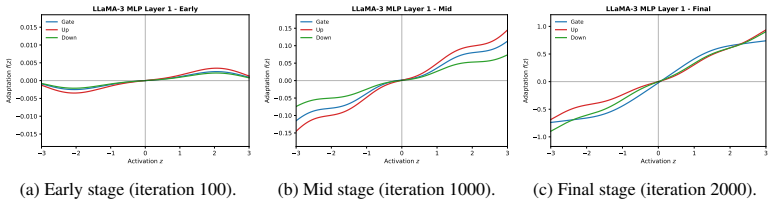
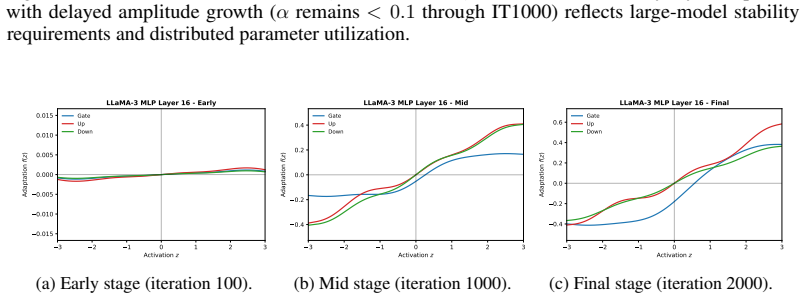
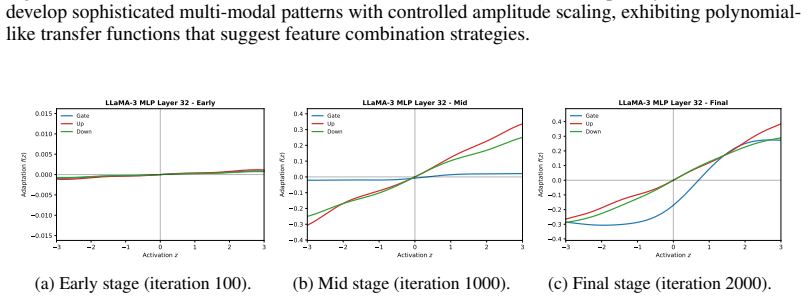
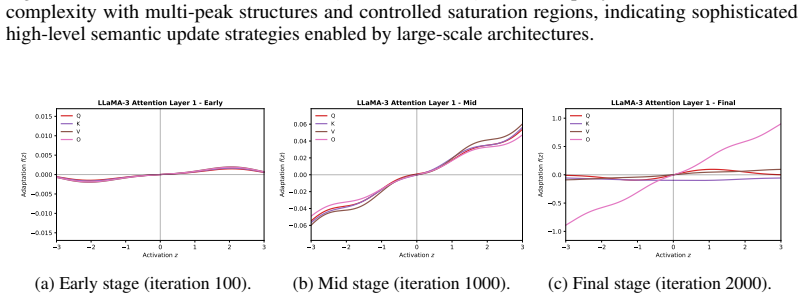
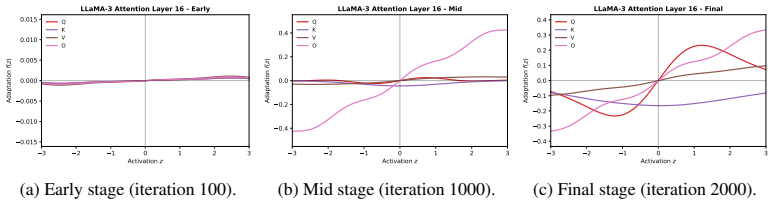
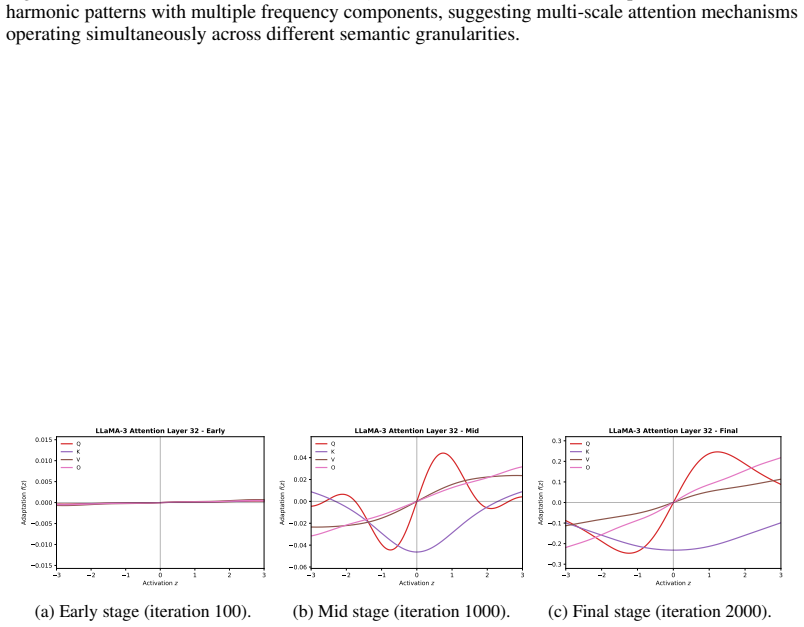
read the original abstract
Low-Rank Adaptation (LoRA) is a popular parameter-efficient fine-tuning (PEFT) method that restricts weight updates to low-rank adapters, introducing a fixed low-rank inductive bias by optimizing in a low-dimensional subspace. In this work, we question whether a fixed-rank constraint is the most effective inductive bias for parameter-efficient fine-tuning. We introduce *Learnable Rank LoRA (LR-LoRA)*, a PEFT method in which the adapter rank is learned during the training process. Instead of prescribing a uniform rank for all adapter layers, LR-LoRA allows the optimizer to determine the appropriate rank for each layer. Using this approach, we find substantial layer-wise variation in the learned ranks, with the attention and MLP layers in the transformer models exhibiting systematically different rank preferences. Across a range of language understanding and commonsense reasoning benchmarks, LR-LoRA achieves state-of-the-art performance in most settings and consistently outperforms strong PEFT baselines, demonstrating that a learnable rank provides a more flexible and effective inductive bias than fixed-rank adaptations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Learnable Rank LoRA (LR-LoRA), a PEFT method extending LoRA by making adapter ranks learnable during training rather than fixed and uniform across layers. It reports substantial layer-wise variation in the learned ranks (with attention and MLP layers showing systematic differences) and claims that LR-LoRA achieves state-of-the-art performance on language understanding and commonsense reasoning benchmarks while outperforming strong PEFT baselines.
Significance. If the reported performance gains and layer-wise rank variations are confirmed with rigorous controls, this would indicate that a learnable-rank inductive bias is more flexible and effective than fixed-rank constraints in LoRA-style adaptation.
major comments (2)
- [Abstract] Abstract: the central empirical claim of SOTA performance and consistent outperformance of baselines cannot be assessed because the abstract (and supplied context) provides no experimental details, baselines, datasets, error bars, statistical tests, or ablation studies.
- [Abstract] Abstract: the assumption that the optimizer can reliably discover useful per-layer ranks without extra optimization difficulty or overfitting is stated but unsupported by any reported evidence on convergence behavior or regularization effects.
Simulated Author's Rebuttal
We thank the referee for their review. Below we respond point-by-point to the major comments on the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of SOTA performance and consistent outperformance of baselines cannot be assessed because the abstract (and supplied context) provides no experimental details, baselines, datasets, error bars, statistical tests, or ablation studies.
Authors: Abstracts are intentionally concise high-level summaries. The full experimental protocol, including all datasets (GLUE, SuperGLUE, and commonsense reasoning tasks), baselines (standard LoRA, AdaLoRA, and other PEFT methods), results reported as mean ± std over multiple random seeds, statistical significance, and ablation studies on rank learning, appear in Sections 3 (Method) and 4 (Experiments) together with the corresponding tables and figures. The abstract therefore summarizes rather than replaces those details. revision: no
-
Referee: [Abstract] Abstract: the assumption that the optimizer can reliably discover useful per-layer ranks without extra optimization difficulty or overfitting is stated but unsupported by any reported evidence on convergence behavior or regularization effects.
Authors: Section 5 (Analysis) of the manuscript presents layer-wise rank distributions, training-loss curves for the rank parameters, and validation-performance trajectories that demonstrate stable convergence of the learned ranks under the same optimizer settings used for fixed-rank LoRA. No additional regularization beyond standard weight decay is applied, and validation metrics improve without signs of overfitting. If the referee considers the current analysis insufficient, we are prepared to add explicit convergence plots or a dedicated regularization subsection. revision: partial
Circularity Check
No significant circularity; empirical method with independent benchmark claims
full rationale
The paper introduces LR-LoRA as an empirical PEFT variant that learns per-layer ranks via standard optimization. The abstract and provided context contain no equations, derivations, or predictions that reduce by construction to fitted inputs or self-citations. Performance claims rest on external benchmarks rather than any self-referential identity. This is the common case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , journal=
-
[2]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and Karampatziakis, Nikos and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , journal=
-
[3]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
DyLoRA: Parameter-efficient tuning of pre-trained models using dynamic search-free low-rank adaptation , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[4]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle=
-
[5]
Kopiczko, Dawid J and Blankevoort, Tijmen and Asano, Yuki M , journal=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Do we always need the simplicity bias? looking for optimal inductive biases in the wild , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards Higher Effective Rank in Parameter-Efficient Fine-tuning using Khatri-Rao Product , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[8]
Meng, Fanxu and Wang, Zhaohui and Zhang, Muhan , journal=
-
[9]
Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin , journal=
-
[10]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , journal=
-
[11]
Zhao, Jiawei and Zhang, Zhenyu and Chen, Beidi and Wang, Zhangyang and Anandkumar, Anima and Tian, Yuandong , journal=
-
[12]
Lialin, Vladislav and Shivagunde, Namrata and Muckatira, Sherin and Rumshisky, Anna , journal=
-
[13]
Zhang, Longteng and Zhang, Lin and Shi, Shaohuai and Chu, Xiaowen and Li, Bo , journal=
-
[14]
A rank stabilization scaling factor for fine-tuning with
Kalajdzievski, Damjan , journal=. A rank stabilization scaling factor for fine-tuning with
-
[15]
Wang, Hanqing and Li, Yixia and Wang, Shuo and Chen, Guanhua and Chen, Yun , booktitle=
-
[16]
The Thirteenth International Conference on Learning Representations , year=
RandLoRA: Full rank parameter-efficient fine-tuning of large models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Efficient Learning with Sine-Activated Low-Rank Matrices , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
Advances in neural information processing systems , volume=
Implicit neural representations with periodic activation functions , author=. Advances in neural information processing systems , volume=
-
[19]
CoRR , year=
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform , author=. CoRR , year=
-
[20]
ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
What does BERT learn about the structure of language? , author=. ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
2019
-
[21]
arXiv preprint arXiv:1905.05950 , year=
BERT rediscovers the classical NLP pipeline , author=. arXiv preprint arXiv:1905.05950 , year=
arXiv 1905
-
[22]
CoRR , year=
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models , author=. CoRR , year=
-
[23]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[24]
Proceedings of the AAAI conference on artificial intelligence , volume=
On the effectiveness of parameter-efficient fine-tuning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[25]
arXiv preprint arXiv:2302.13971 , year=
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year=
-
[26]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[27]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[28]
Team, Qwen and others , journal=
-
[29]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[30]
Nature machine intelligence , volume=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature machine intelligence , volume=. 2023 , publisher=
2023
-
[31]
arXiv preprint arXiv:2403.14608 , year=
Parameter-efficient fine-tuning for large models: A comprehensive survey , author=. arXiv preprint arXiv:2403.14608 , year=
-
[32]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[33]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[34]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[35]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , journal=
-
[36]
Proceedings of the IRE , volume=
Communication in the presence of noise , author=. Proceedings of the IRE , volume=. 2006 , publisher=
2006
-
[37]
On the functions which are represented by the expansions of the interpolatory theory , author=. Proc. Royal Soc. Edinburgh , volume=
-
[38]
arXiv preprint arXiv:2101.00190 , year=
Prefix-tuning: Optimizing continuous prompts for generation , author=. arXiv preprint arXiv:2101.00190 , year=
-
[39]
arXiv preprint arXiv:2104.08691 , year=
The power of scale for parameter-efficient prompt tuning , author=. arXiv preprint arXiv:2104.08691 , year=
-
[40]
Zaken, Elad Ben and Goldberg, Yoav and Ravfogel, Shauli , booktitle=
-
[41]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , journal=
-
[42]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin and others , booktitle=
-
[43]
Sap, Maarten and Rashkin, Hannah and Chen, Derek and LeBras, Ronan and Choi, Yejin , journal=
-
[44]
2021 , publisher=
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , journal=. 2021 , publisher=
2021
-
[45]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[46]
arXiv preprint arXiv:1809.02789 , year=
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. arXiv preprint arXiv:1809.02789 , year=
-
[47]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal=
-
[48]
Advances in Neural Information Processing Systems , volume=
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Advances in neural information processing systems , volume=
Compacter: Efficient low-rank hypercomplex adapter layers , author=. Advances in neural information processing systems , volume=
-
[50]
2017 , publisher=
Applied Fourier Analysis , author=. 2017 , publisher=
2017
-
[51]
Transactions of the American Institute of Electrical Engineers , volume=
Certain topics in telegraph transmission theory , author=. Transactions of the American Institute of Electrical Engineers , volume=. 1928 , publisher=
1928
-
[52]
GEC Journal of Technology , volume=
An introduction to Shannon sampling and interpolation theory, with generalizations to nonuniform sampling , author=. GEC Journal of Technology , volume=
-
[53]
2009 , publisher=
Real analysis: measure theory, integration, and Hilbert spaces , author=. 2009 , publisher=
2009
-
[54]
arXiv preprint arXiv:2504.00254 , year=
Elalora: Elastic & learnable low-rank adaptation for efficient model fine-tuning , author=. arXiv preprint arXiv:2504.00254 , year=
-
[55]
arXiv preprint arXiv:2505.18738 , year=
AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping , author=. arXiv preprint arXiv:2505.18738 , year=
-
[56]
arXiv preprint arXiv:2505.14238 , year=
ABBA: Highly Expressive Hadamard Product Adaptation for Large Language Models , author=. arXiv preprint arXiv:2505.14238 , year=
-
[57]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle=. Judging
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.