Spatial Reasoning via Modality Switching Between Language and Symbolic Representation
Pith reviewed 2026-07-01 05:39 UTC · model grok-4.3
The pith
Switching LLMs from language to grid representations improves spatial reasoning by up to 42%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
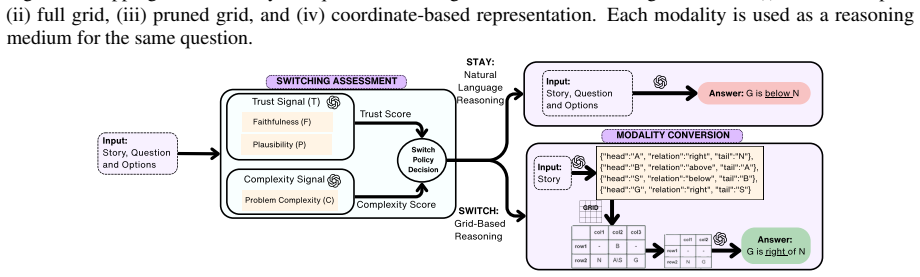
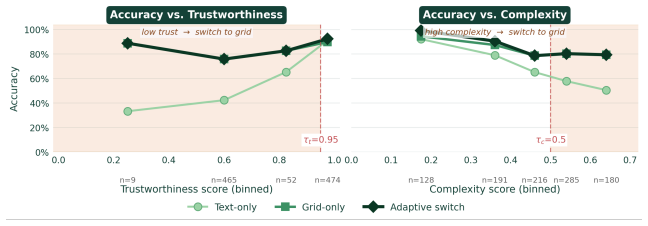
Grounding multi-hop textual-spatial stories into geometry-aware modalities such as grids improves reasoning over natural language inference alone, and a switching metric based on trustworthiness and complexity signals can estimate when this grounding is likely to help.
What carries the argument
The switching metric, which combines trustworthiness and complexity signals to decide between language and grid modalities.
Load-bearing premise
The switching metric built from trustworthiness and complexity signals accurately predicts when switching to a grid will improve performance over language-only reasoning.
What would settle it
Run the switching metric on a new set of spatial stories, apply the predicted modality, and check whether the performance gain matches or exceeds the reported 42 percent improvement.
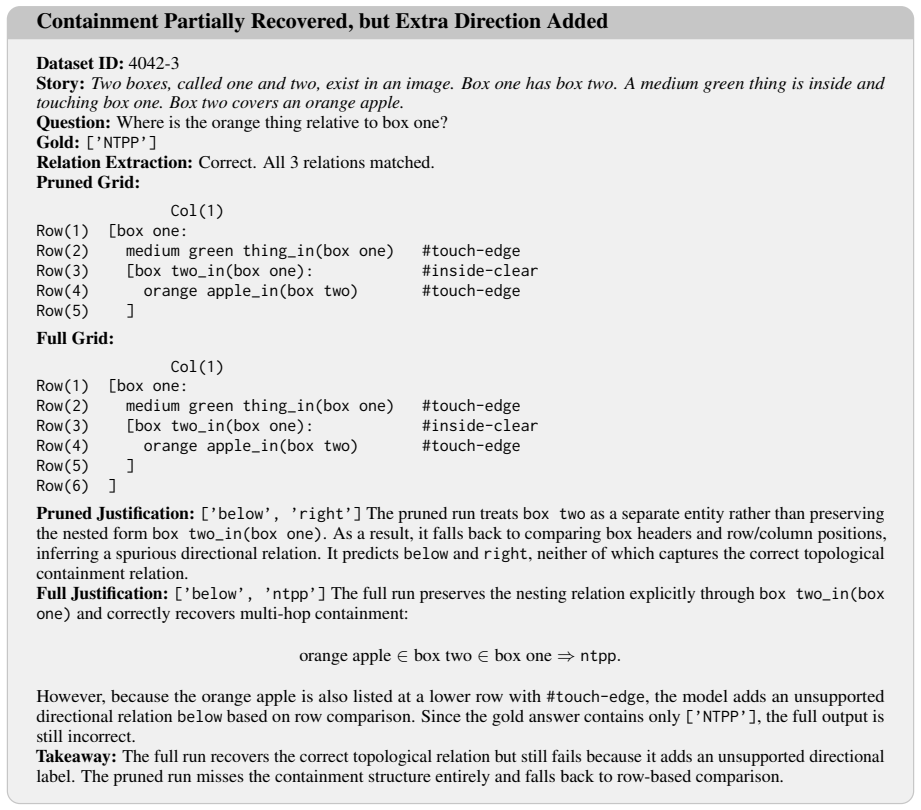
Figures

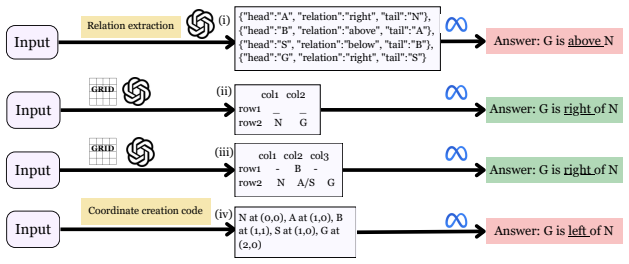






read the original abstract
Human reasoning is inherently multimodal: when problems become difficult, we rarely think in words alone. We often externalize our reasoning by sketching diagrams or drawing grids to understand the underlying conceptual structure and avoid mistakes. Building on this premise, our research investigates: (a) whether grounding multi-hop textual-spatial stories into geometry-aware modalities, such as layouts or grids, improves reasoning compared to natural language-based inference; and (b) whether a model can decide when to rely on natural language reasoning and when to switch to a structured modality. We address these questions by introducing a switching metric based on trustworthiness and complexity signals, which estimates when grounding a spatial story into structure is likely to improve performance. This takes a first step toward principled modality selection in Large Language Model (LLM) reasoning. Across our settings, switching from natural language-based reasoning to a grid-based representation improves LLM performance by up to 42\%, highlighting the importance of modality choice in shaping reasoning outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grounding multi-hop textual-spatial stories into grid-based symbolic representations improves LLM performance over language-only reasoning, and introduces a switching metric derived from trustworthiness and complexity signals to decide when to switch modalities, reporting gains of up to 42% across settings.
Significance. If the switching metric is shown to reliably predict gains and the empirical results are robust, the work could contribute to better understanding of modality choice in LLM reasoning for spatial tasks.
major comments (2)
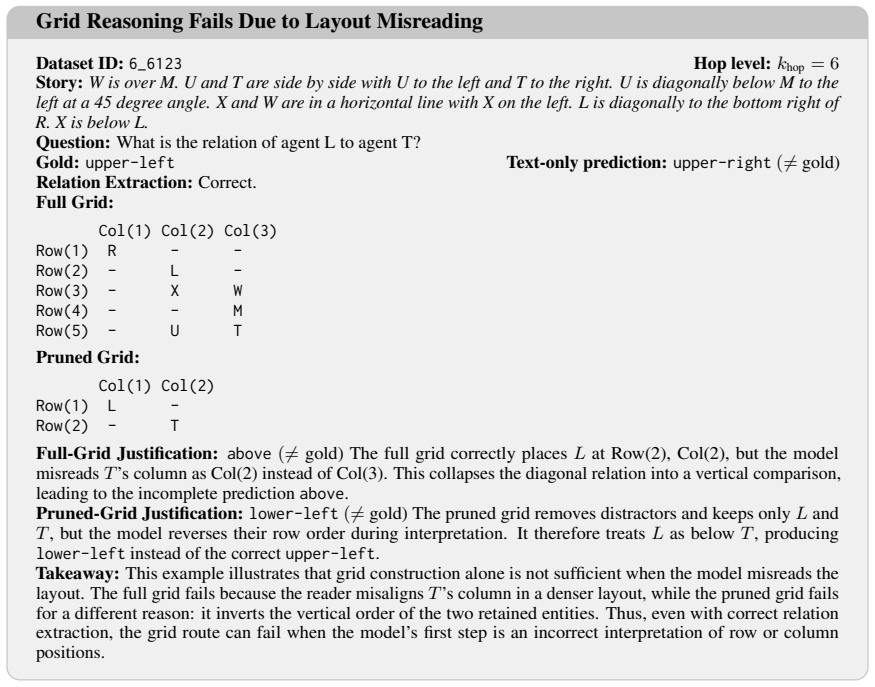
- [Switching metric definition and evaluation] The headline claim of up to 42% improvement via switching depends on the metric correctly identifying beneficial cases, but no correlation, precision-recall, or ablation against random/always-language baselines is reported to validate this predictive link (see abstract and any experiments section).
- [Empirical evaluation] No experimental details are supplied on dataset sizes, baselines, statistical tests, error analysis, or how the 42% figure was computed, preventing assessment of whether the result supports the central claim (abstract).
minor comments (1)
- The abstract refers to 'our settings' and 'multi-hop textual-spatial stories' without defining the tasks or stories used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in validation of the switching metric and in experimental reporting. We will revise the manuscript to address both points by adding the requested analyses and details.
read point-by-point responses
-
Referee: [Switching metric definition and evaluation] The headline claim of up to 42% improvement via switching depends on the metric correctly identifying beneficial cases, but no correlation, precision-recall, or ablation against random/always-language baselines is reported to validate this predictive link (see abstract and any experiments section).
Authors: We agree that the predictive link between the trustworthiness-and-complexity switching metric and observed gains requires explicit validation. The current manuscript defines the metric and reports aggregate gains but does not include correlation coefficients, precision-recall for the switch decisions, or ablations versus random or always-language baselines. In revision we will add these evaluations in the experiments section to demonstrate that the metric reliably identifies cases where modality switching is beneficial. revision: yes
-
Referee: [Empirical evaluation] No experimental details are supplied on dataset sizes, baselines, statistical tests, error analysis, or how the 42% figure was computed, preventing assessment of whether the result supports the central claim (abstract).
Authors: We acknowledge that the abstract and experiments section currently omit these details. We will expand the experimental reporting to specify dataset sizes, all baselines, statistical significance tests, error analysis, and the exact computation of the reported gains (including per-setting breakdowns that yield the maximum of 42%). revision: yes
Circularity Check
No circularity; empirical claim rests on external experimental outcomes
full rationale
The abstract introduces a switching metric constructed from trustworthiness and complexity signals to estimate when grid grounding will help, then reports an empirical performance gain of up to 42% when switching is applied. No equations, definitions, or self-citations are shown that make the metric or the gain reduce to its own inputs by construction. The 42% figure is presented as a measured experimental result rather than a fitted or renamed quantity, and the derivation chain remains open to external validation on held-out stories.
Axiom & Free-Parameter Ledger
invented entities (1)
-
switching metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , doi =
Wang, Rong and Sun, Kun , journal =. 2026 , doi =
2026
-
[7]
2003 , publisher=
Toward a Cognitive Semantics: Volume 1: Concept Structuring Systems and Volume 2: Typology and Process in Concept Structuring , author=. 2003 , publisher=
2003
-
[9]
The More the Better? A Systematic Review and Meta-Analysis of the Benefits of More than Two External Representations in STEM Education , volume =
Rexigel, Eva and Kuhn, Jochen and Becker-Genschow, Sebastian and Malone, Sarah , year =. The More the Better? A Systematic Review and Meta-Analysis of the Benefits of More than Two External Representations in STEM Education , volume =. Educational Psychology Review , doi =
-
[11]
Spatial Role Labeling: Task Definition and Annotation Scheme
Kordjamshidi, Parisa and Van Otterlo, Martijn and Moens, Marie-Francine. Spatial Role Labeling: Task Definition and Annotation Scheme. Proceedings of the Seventh International Conference on Language Resources and Evaluation ( LREC '10). 2010
2010
-
[12]
History of Programming Languages---II , pages =
Colmerauer, Alain and Roussel, Philippe , title =. History of Programming Languages---II , pages =. 1996 , isbn =
1996
-
[13]
Grounding spatial relations in text-only language models , volume=
Azkune, Gorka and Salaberria, Ander and Agirre, Eneko , year=. Grounding spatial relations in text-only language models , volume=. doi:10.1016/j.neunet.2023.11.031 , journal=
-
[14]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
GRASP: A Novel Benchmark for Evaluating Language GRounding and Situated Physics Understanding in Multimodal Language Models , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , month =. doi:10.24963/ijcai.2024/696 , url =
-
[15]
2025 , eprint=
DeepSketcher: Internalizing Visual Manipulation for Multimodal Reasoning , author=. 2025 , eprint=
2025
-
[16]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[17]
Plausibility: On the (Un)Reliability of Explanations from Large Language Models , author=
Faithfulness vs. Plausibility: On the (Un)Reliability of Explanations from Large Language Models , author=. 2024 , eprint=
2024
-
[19]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[20]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
Spatial Reasoning in Multimodal Large Language Models: A Survey of Tasks, Benchmarks and Methods , author=. 2025 , eprint=
2025
-
[23]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[24]
2024 , eprint=
Evaluating Consistency and Reasoning Capabilities of Large Language Models , author=. 2024 , eprint=
2024
-
[25]
Thomas and Pavlick, Ellie and Linzen, Tal
McCoy, R. Thomas and Pavlick, Ellie and Linzen, Tal. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1334
-
[27]
An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Shiri, Fatemeh and Guo, Xiao-Yu and Far, Mona Golestan and Yu, Xin and Haf, Reza and Li, Yuan-Fang. An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1195
-
[28]
The Fourteenth International Conference on Learning Representations , year=
InternSpatial: A Comprehensive Dataset for Spatial Reasoning in Vision-Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[29]
2025 , eprint=
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe , author=. 2025 , eprint=
2025
-
[30]
2015 , eprint=
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks , author=. 2015 , eprint=
2015
-
[31]
Transactions on Machine Learning Research , issn=
Extracting and Following Paths for Robust Relational Reasoning with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2026 , url=
2026
-
[32]
Vision Language Models in Autonomous Driving: A Survey and Outlook , volume =
Zhou, Xingcheng and Liu, Mingyu and Yurtsever, Ekim and Žagar, Bare Luka and Zimmer, Walter and Cao, Hu and Knoll, Alois , year =. Vision Language Models in Autonomous Driving: A Survey and Outlook , volume =. IEEE Transactions on Intelligent Vehicles , doi =
-
[33]
8th Annual Conference on Robot Learning , year=
Tag Map: A Text-Based Map for Spatial Reasoning and Navigation with Large Language Models , author=. 8th Annual Conference on Robot Learning , year=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Song, Chan Hee and Blukis, Valts and Tremblay, Jonathan and Tyree, Stephen and Su, Yu and Birchfield, Stan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[35]
2023 , eprint=
An Evaluation of ChatGPT-4's Qualitative Spatial Reasoning Capabilities in RCC-8 , author=. 2023 , eprint=
2023
-
[36]
2023 , eprint=
Dialectical language model evaluation: An initial appraisal of the commonsense spatial reasoning abilities of LLMs , author=. 2023 , eprint=
2023
-
[38]
2025 , eprint=
An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning , author=. 2025 , eprint=
2025
-
[39]
The First Workshop on the Application of LLM Explainability to Reasoning and Planning , year=
Enhancing Logical Reasoning in Large Language Models through Graph-based Synthetic Data , author=. The First Workshop on the Application of LLM Explainability to Reasoning and Planning , year=
-
[41]
2025 , eprint=
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning , author=. 2025 , eprint=
2025
-
[42]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[43]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[44]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[45]
Transactions on Machine Learning Research , issn=
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[46]
First Conference on Language Modeling , year=
Chain-of-Symbol Prompting For Spatial Reasoning in Large Language Models , author=. First Conference on Language Modeling , year=
-
[47]
Logic- LM : Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning
Pan, Liangming and Albalak, Alon and Wang, Xinyi and Wang, William. Logic- LM : Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.248
-
[48]
Forty-second International Conference on Machine Learning , year=
CodeSteer: Symbolic-Augmented Language Models via Code/Text Guidance , author=. Forty-second International Conference on Machine Learning , year=
-
[49]
2025 , eprint=
Route to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection , author=. 2025 , eprint=
2025
-
[51]
Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=
Isaac Ong and Amjad Almahairi and Vincent Wu and Wei-Lin Chiang and Tianhao Wu and Joseph E. Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=. Route. 2025 , url=
2025
-
[52]
2025 , eprint=
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[53]
2025 , url=
Murong Yue and Wenlin Yao and Haitao Mi and Dian Yu and Ziyu Yao and Dong Yu , booktitle=. 2025 , url=
2025
-
[54]
Thinkless:
Gongfan Fang and Xinyin Ma and Xinchao Wang , booktitle=. Thinkless:. 2026 , url=
2026
- [55]
-
[56]
Yongchao Chen, Yilun Hao, Yueying Liu, Yang Zhang, and Chuchu Fan. 2025. https://openreview.net/forum?id=ezna4V4zHs Codesteer: Symbolic-augmented language models via code/text guidance . In Forty-second International Conference on Machine Learning
2025
- [57]
- [58]
-
[59]
Alain Colmerauer and Philippe Roussel. 1996. https://doi.org/10.1145/234286.1057820 The birth of Prolog , page 331–367. Association for Computing Machinery, New York, NY, USA
-
[60]
Gongfan Fang, Xinyin Ma, and Xinchao Wang. 2026. https://openreview.net/forum?id=ariVQf0KZx Thinkless: LLM learns when to think . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
-
[61]
Hanxu Hu, Hongyuan Lu, Huajian Zhang, Yunze Song, Wai Lam, and Yue Zhang. 2024. https://openreview.net/forum?id=Hvq9RtSoHG Chain-of-symbol prompting for spatial reasoning in large language models . In First Conference on Language Modeling
2024
- [62]
-
[63]
Parisa Kordjamshidi, Martijn Van Otterlo, and Marie-Francine Moens. 2010. https://aclanthology.org/L10-1584/ Spatial role labeling: Task definition and annotation scheme . In Proceedings of the Seventh International Conference on Language Resources and Evaluation ( LREC '10) , Valletta, Malta. European Language Resources Association (ELRA)
2010
-
[64]
Jill H. Larkin and Herbert A. Simon. 1987. https://doi.org/10.1111/j.1551-6708.1987.tb00863.x Why a diagram is (sometimes) worth ten thousand words . Cognitive Science, 11(1):65--100
-
[65]
Fangjun Li, David C. Hogg, and Anthony G. Cohn. 2024. https://doi.org/10.1609/aaai.v38i17.29811 Advancing spatial reasoning in large language models: an in-depth evaluation and enhancement using the stepgame benchmark . In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of ...
-
[66]
Shuaiyi Li, Yang Deng, and Wai Lam. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.428 D ep W i GNN : A depth-wise graph neural network for multi-hop spatial reasoning in text . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6459--6471, Singapore. Association for Computational Linguistics
- [67]
-
[68]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, Helong Huang, Guangjian Tian, Weichao Qiu, Xingyue Quan, Jianye Hao, and Yuzheng Zhuang. 2025 b . https://arxiv.org/abs/2501.10074 Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-though...
-
[69]
Llama Team . 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [70]
-
[71]
Roshanak Mirzaee and Parisa Kordjamshidi. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.413 Transfer learning with synthetic corpora for spatial role labeling and reasoning . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6148--6165, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[72]
Roshanak Mirzaee and Parisa Kordjamshidi. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.221 Disentangling extraction and reasoning in multi-hop spatial reasoning . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3379--3397, Singapore. Association for Computational Linguistics
-
[73]
Roshanak Mirzaee, Hossein Rajaby Faghihi, Qiang Ning, and Parisa Kordjamshidi. 2021. https://doi.org/10.18653/v1/2021.naacl-main.364 SPARTQA : A textual question answering benchmark for spatial reasoning . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, page...
-
[74]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. https://openreview.net/forum?id=8sSqNntaMr Route LLM : Learning to route LLM s from preference data . In The Thirteenth International Conference on Learning Representations
2025
-
[75]
OpenAI . 2025 a . https://platform.openai.com/docs/models/gpt-5 GPT-5 Model Documentation . Accessed: 2025-12-26
2025
-
[76]
OpenAI . 2025 b . https://platform.openai.com/docs/models/gpt-5.1 GPT-5.1 Model Documentation . Accessed: 2025-12-26
2025
- [77]
-
[78]
Tanawan Premsri and Parisa Kordjamshidi. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.128 Neuro-symbolic training for reasoning over spatial language . In Findings of the Association for Computational Linguistics: NAACL 2025, page 2395–2414. Association for Computational Linguistics
-
[79]
Qwen Team . 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Eva Rexigel, Jochen Kuhn, Sebastian Becker-Genschow, and Sarah Malone. 2024. https://doi.org/10.1007/s10648-024-09958-y The more the better? a systematic review and meta-analysis of the benefits of more than two external representations in stem education . Educational Psychology Review, 36
-
[81]
Md Imbesat Rizvi, Xiaodan Zhu, and Iryna Gurevych. 2024. https://doi.org/10.18653/v1/2024.acl-long.261 S pa RC and S pa RP : Spatial reasoning characterization and path generation for understanding spatial reasoning capability of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[82]
Krithi Shailya, Shreya Rajpal, Gokul S Krishnan, and Balaraman Ravindran. 2025. https://doi.org/10.1145/3715275.3732104 Lext: Towards evaluating trustworthiness of natural language explanations . In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’25, page 1565–1587. ACM
-
[83]
Zhengxiang Shi, Qiang Zhang, and Aldo Lipani. 2022. https://doi.org/10.1609/aaai.v36i10.21383 Stepgame: A new benchmark for robust multi-hop spatial reasoning in texts . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11321--11329
-
[84]
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. 2025. RoboSpatial : Teaching spatial understanding to 2D and 3D vision-language models for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Oral Presentation
2025
-
[85]
L. Talmy. 2003. https://books.google.com/books?id=g7IoanNUNksC Toward a Cognitive Semantics: Volume 1: Concept Structuring Systems and Volume 2: Typology and Process in Concept Structuring . Number v. 2 in A Bradford book. MIT Press
2003
-
[86]
Rong Wang and Kun Sun. 2026. https://doi.org/10.1016/j.neunet.2025.108022 DSPy-based neural-symbolic pipeline to enhance spatial reasoning in LLMs . Neural Networks: The Official Journal of the International Neural Network Society, 193:108022
-
[87]
Zhun Yang, Adam Ishay, and Joohyung Lee. 2023. https://doi.org/10.18653/v1/2023.findings-acl.321 Coupling large language models with logic programming for robust and general reasoning from text . In Findings of the Association for Computational Linguistics: ACL 2023, pages 5186--5219, Toronto, Canada. Association for Computational Linguistics
-
[88]
Murong Yue, Wenlin Yao, Haitao Mi, Dian Yu, Ziyu Yao, and Dong Yu. 2025. https://openreview.net/forum?id=tn2mjzjSyR DOTS : Learning to reason dynamically in LLM s via optimal reasoning trajectories search . In The Thirteenth International Conference on Learning Representations
2025
-
[89]
Ge Zhang, Mohammad Ali Alomrani, Hongjian Gu, Jiaming Zhou, Yaochen Hu, Bin Wang, Qun Liu, Mark Coates, Yingxue Zhang, and Jianye HAO. 2026. https://openreview.net/forum?id=EbELaNKmZK Extracting and following paths for robust relational reasoning with large language models . Transactions on Machine Learning Research. Expert Certification
2026
-
[90]
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.184 A dapt T hink: Reasoning models can learn when to think . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3716--3730, Suzhou, China. Association for Computational Linguistics
-
[91]
Mike Zhang, Kaixian Qu, Vaishakh Patil, Cesar Cadena, and Marco Hutter. 2024. https://openreview.net/forum?id=eU5E0oTtpS Tag map: A text-based map for spatial reasoning and navigation with large language models . In 8th Annual Conference on Robot Learning
2024
-
[92]
Jiaming Zhou, Abbas Ghaddar, Ge Zhang, Liheng Ma, Yaochen Hu, Soumyasundar Pal, Bin Wang, Jianye HAO, Mark Coates, and Yingxue Zhang. 2025. https://openreview.net/forum?id=Kqp4325eXm Enhancing logical reasoning in large language models through graph-based synthetic data . In The First Workshop on the Application of LLM Explainability to Reasoning and Planning
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.