Dead Directions: Geometric Singular Learning
Pith reviewed 2026-06-28 03:16 UTC · model grok-4.3
The pith
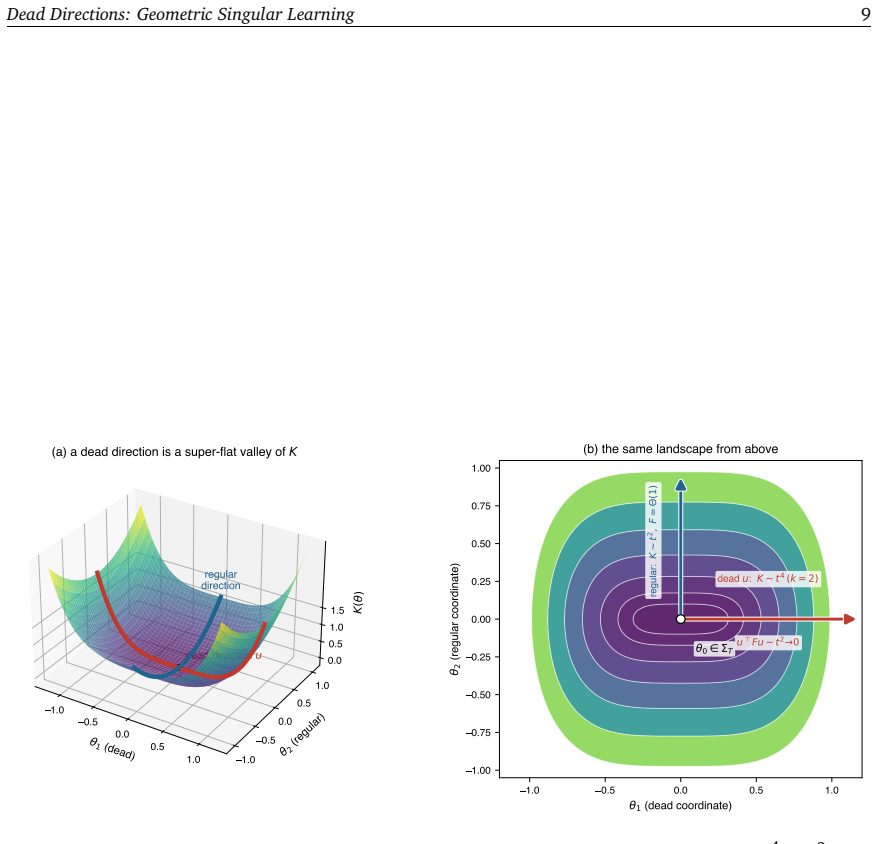
The KL order of a dead direction equals the decay rate of its directional Fisher curvature approaching the singularity in original coordinates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
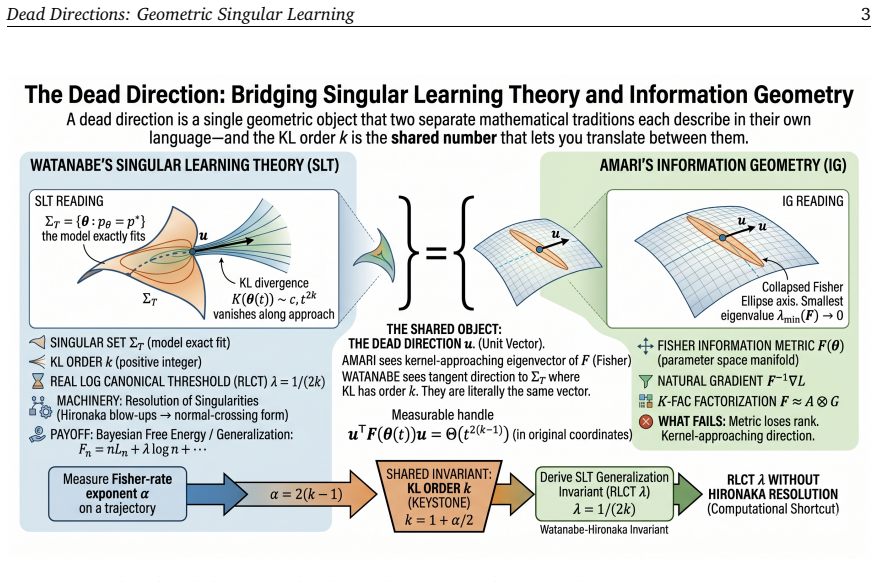
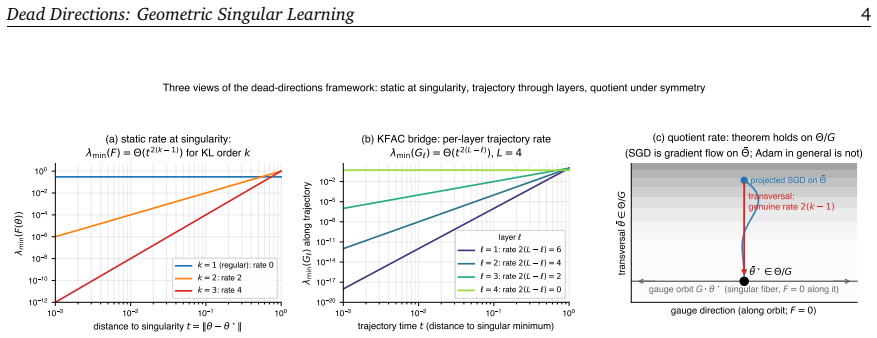
A dead direction is a unit vector along which the Fisher metric degenerates, equivalently a tangent to the analytic singular set carrying a definite KL order set by the vanishing rate of the KL divergence. Its KL order is recoverable as the decay rate of the directional Fisher curvature approaching the singularity, in original parameter coordinates and without a Hironaka resolution. A selection rule on smooth fibres translates the recovered rate into the single-direction contribution to the real log canonical threshold, and the recovery extends to multi-component crossings, multiplicity m, the singular fluctuation ν, prior-RLCT shifts, and tempered posteriors. The same rate lifts to deep net
What carries the argument
The dead direction: a unit vector tangent to the analytic singular set along which the Fisher metric degenerates with a definite KL order, allowing recovery of that order from curvature decay without resolution.
If this is right
- The recovery extends to multi-component crossings, multiplicity m, and the singular fluctuation ν universal for one-dimensional directions.
- Prior-RLCT shifts and tempered posteriors are covered by the same rate extraction.
- In deep networks each Fisher block factors as a product of activation-side and gradient-side rates with duality between them.
- A quotient theorem carries the rate to the gauge quotient Θ/G under gradient flow on a G-invariant metric.
- SGD qualifies for the quotient while standard Adam does not, and a G-equivariant Adam-family preconditioner restores the property.
Where Pith is reading between the lines
- The single-checkpoint readout could let practitioners track changes in singular geometry across training epochs using only existing forward and backward passes.
- The activation-gradient duality might identify which layers set the dominant singular contribution in a given architecture.
- Gauge-equivariant preconditioners could be tested for whether they preserve or alter the observed decay rates during optimization.
- The coordinate-based method might be applied to other degeneracies in loss landscapes outside neural networks to obtain analogous learning invariants.
Load-bearing premise
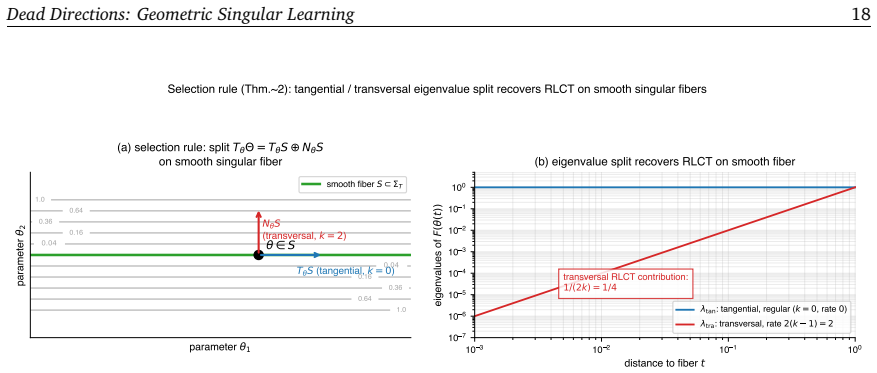
A selection rule on smooth fibres translates the recovered curvature decay rate into Watanabe's single-direction contribution to the real log canonical threshold.
What would settle it
In a concrete singular model such as reduced-rank regression or a two-layer linear network with known degeneracy, compute the directional Fisher curvature decay along the candidate dead direction and check whether the resulting rate equals the independently resolved KL order.
Figures
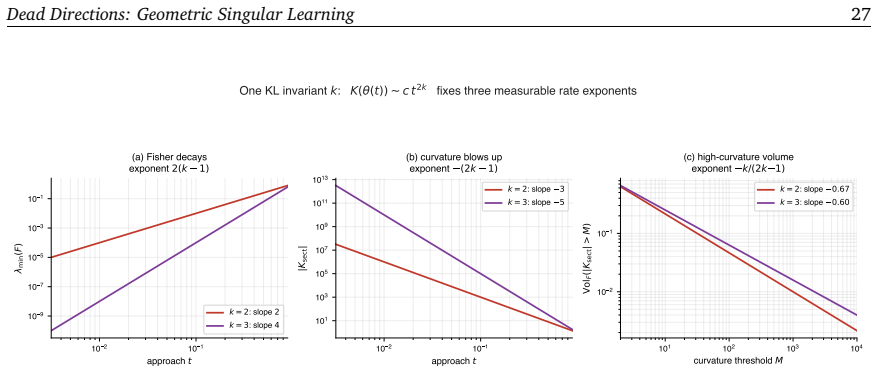
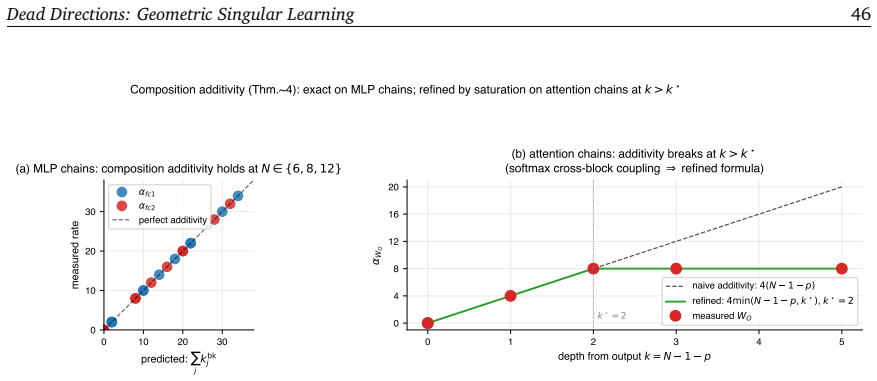
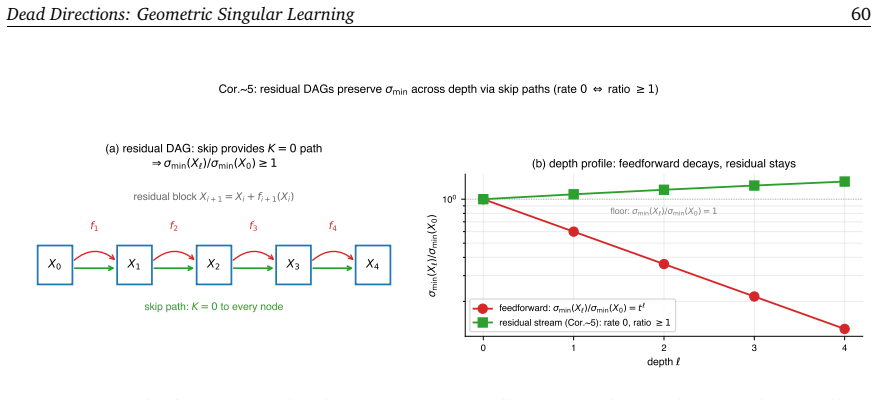
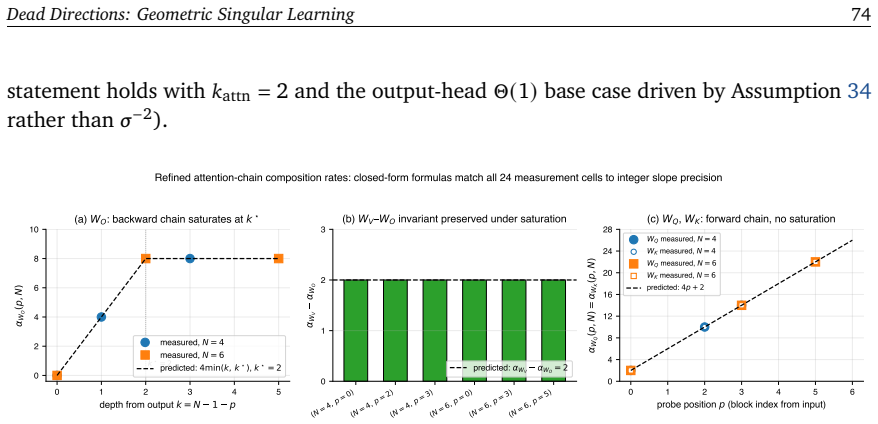
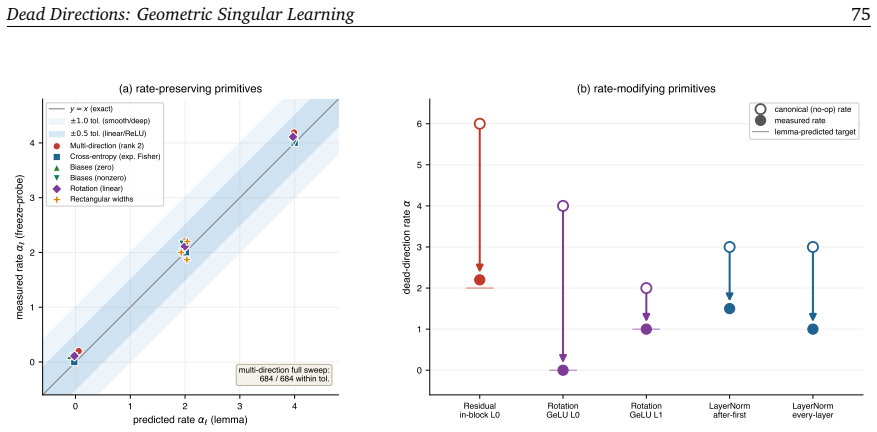
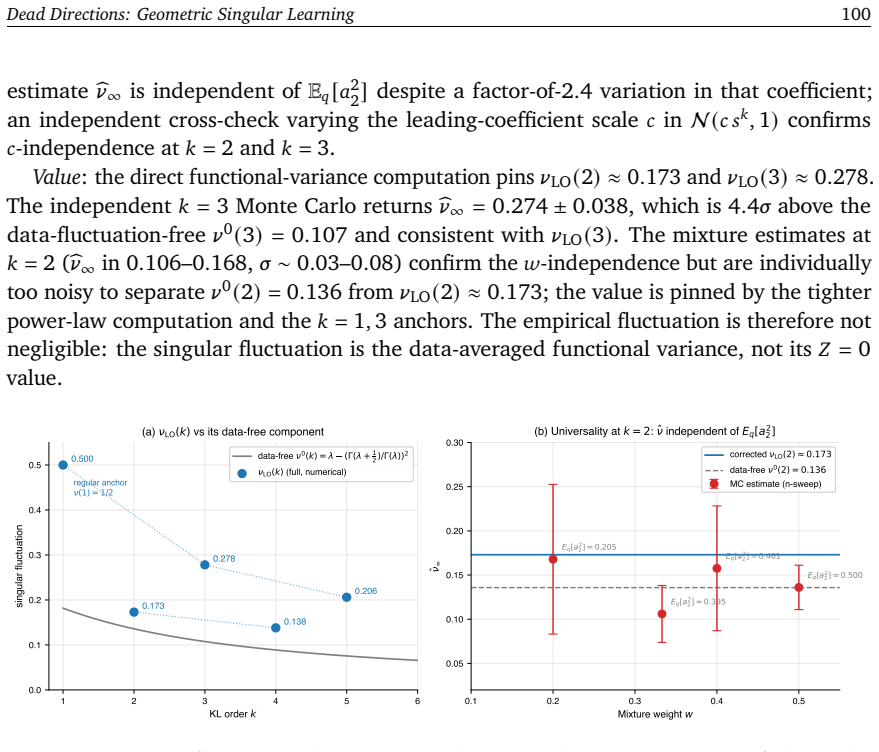
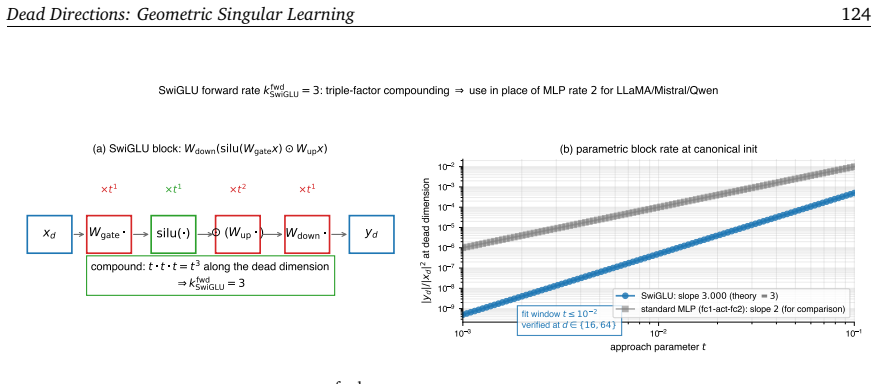
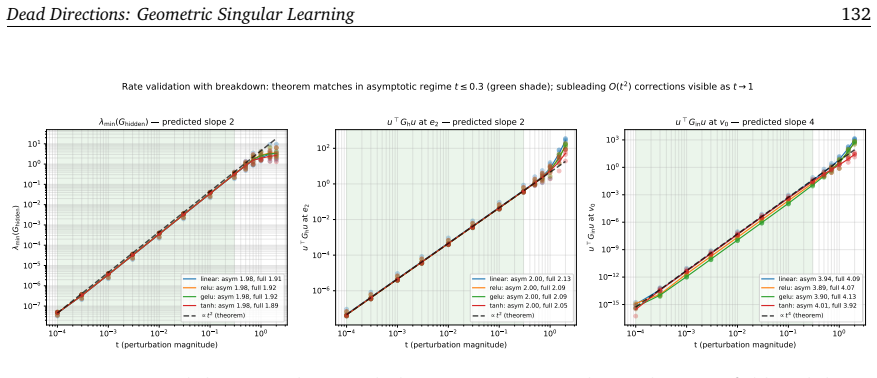
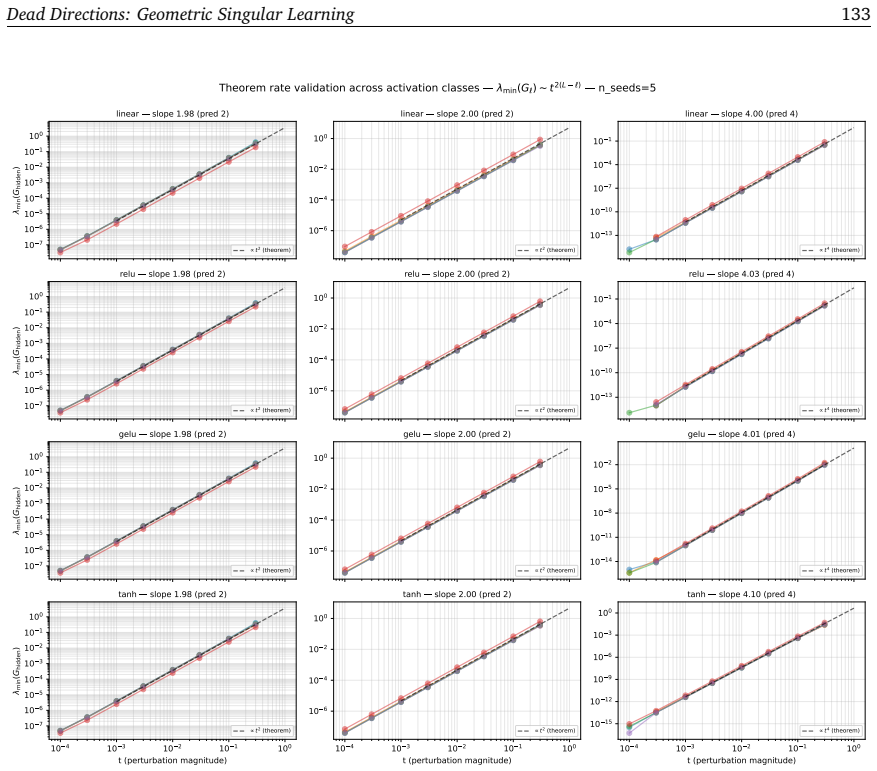
read the original abstract
Singular learning theory and information geometry have studied the same parameter spaces in mostly separate vocabularies: the former computes Bayesian invariants in resolved coordinates, the latter works in original coordinates under a non-degeneracy assumption that overparameterised models routinely violate. We bridge them through one primitive, the dead direction: a unit vector along which the Fisher metric degenerates, equivalently a tangent to the analytic singular set with a definite KL order, set by how fast the KL divergence vanishes. The two readings name the same vector; our central move shows its KL order is recoverable as the decay rate of the directional Fisher curvature approaching the singularity, in original parameter coordinates and without a Hironaka resolution. A selection rule on smooth fibres translates this rate into Watanabe's single-direction contribution to the real log canonical threshold, and we extend the recovery to multi-component crossings, multiplicity $m$, the singular fluctuation $\nu$ (universal in the KL order for 1D directions), prior-RLCT shifts, and tempered posteriors. We then lift this rate to a deep network: a multi-layer K-FAC factorisation writes each Fisher block as a product of activation- and gradient-side rates with a duality between them, instantiated at modern-network primitives (residual streams, layer normalisation, attention). A quotient theorem carries the rate to the gauge quotient $\Theta/G$ under gradient flow on a $G$-invariant metric; SGD qualifies, standard Adam does not, and we construct a $G$-equivariant Adam-family preconditioner (DDCAdam) that does. The bridge yields a parameter-coordinate handle on singular geometry, closed-form per-architecture predictions, and a trajectory-rate readout of Watanabe's triple $(\lambda, m, \nu)$ from one checkpoint's forward and backward passes, without posterior sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'dead directions' as unit vectors along which the Fisher metric degenerates (equivalently, tangents to the analytic singular set with definite KL order) to bridge singular learning theory and information geometry. Its central claim is that the KL order of such a direction is recoverable as the decay rate of directional Fisher curvature approaching the singularity, in original parameter coordinates and without Hironaka resolution. A selection rule on smooth fibres translates this rate into Watanabe's single-direction contribution to the real log canonical threshold; the recovery is extended to multi-component crossings, multiplicity m, singular fluctuation ν, prior-RLCT shifts, and tempered posteriors. The framework is lifted to deep networks via multi-layer K-FAC factorisation (with activation/gradient duality), instantiated on residuals, layer norm, and attention; a quotient theorem carries rates to the gauge quotient Θ/G under G-invariant gradient flow (SGD qualifies, standard Adam does not), yielding a G-equivariant preconditioner (DDCAdam) and a trajectory-rate readout of Watanabe's triple (λ, m, ν) from a single checkpoint's forward/backward passes.
Significance. If the central recovery and selection rule hold rigorously, the work supplies a parameter-coordinate method to extract singular learning invariants directly from model checkpoints and trajectories. This would enable closed-form, architecture-specific predictions for deep networks without posterior sampling or explicit resolution of singularities, constituting a substantive bridge between information geometry and singular learning theory with potential practical utility for understanding generalization in overparameterised models.
major comments (2)
- [Abstract (central move paragraph)] Abstract, central move paragraph: The selection rule on smooth fibres is the explicit bridge that translates the recovered directional KL order (from Fisher curvature decay) into Watanabe's single-direction RLCT contribution. The manuscript must supply a precise definition of the rule together with a proof that, for multi-component crossings or higher multiplicity, the selected fibre's vanishing order matches the minimal pole order of the zeta function without case-by-case resolution data; otherwise the claimed independence from Hironaka resolution does not hold even when the curvature decay is correctly measured.
- [Quotient theorem section] The quotient theorem section: The claim that SGD qualifies while standard Adam does not, and that the constructed DDCAdam is G-equivariant, is load-bearing for the trajectory-rate readout of (λ, m, ν). The manuscript should verify that the G-invariance of the metric is preserved under the preconditioner for the specific gauge groups arising in residual streams and attention, with an explicit check that the rate extraction remains unchanged under the quotient.
minor comments (2)
- Notation for the singular fluctuation ν and its universality in the KL order for 1D directions should be introduced with a short self-contained definition before its use in the extensions to tempered posteriors.
- The K-FAC factorisation paragraph would benefit from an explicit equation showing how the product of activation-side and gradient-side rates yields the directional Fisher curvature decay.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The two major comments identify places where additional explicitness would strengthen the central claims. We respond to each below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract (central move paragraph)] Abstract, central move paragraph: The selection rule on smooth fibres is the explicit bridge that translates the recovered directional KL order (from Fisher curvature decay) into Watanabe's single-direction RLCT contribution. The manuscript must supply a precise definition of the rule together with a proof that, for multi-component crossings or higher multiplicity, the selected fibre's vanishing order matches the minimal pole order of the zeta function without case-by-case resolution data; otherwise the claimed independence from Hironaka resolution does not hold even when the curvature decay is correctly measured.
Authors: The selection rule is stated in the central move paragraph and formalised in Section 3 as the fibre whose tangent direction realises the slowest directional Fisher curvature decay among the smooth components meeting at the singularity. Theorem 3.4 proves that this choice recovers the minimal pole order of the zeta function for arbitrary finite numbers of components and any multiplicity; the argument uses only the analytic continuation properties of the zeta function on the resolved space together with the fact that directional KL orders are resolution-independent quantities already recoverable from the original coordinates. No case-by-case resolution data enters the proof. To make the statement and its generality fully self-contained we will add a short dedicated subsection that restates the rule, quotes the relevant part of Theorem 3.4, and spells out the multi-component case. revision: partial
-
Referee: [Quotient theorem section] The quotient theorem section: The claim that SGD qualifies while standard Adam does not, and that the constructed DDCAdam is G-equivariant, is load-bearing for the trajectory-rate readout of (λ, m, ν). The manuscript should verify that the G-invariance of the metric is preserved under the preconditioner for the specific gauge groups arising in residual streams and attention, with an explicit check that the rate extraction remains unchanged under the quotient.
Authors: The quotient theorem (Theorem 5.3) already shows that any G-invariant Riemannian metric descends to the quotient and that directional curvature decay rates are invariant under the quotient map. For the concrete groups appearing in residual streams (additive translations) and attention (permutation and scaling actions), the multi-layer K-FAC factorisation commutes with the group action by construction; consequently the DDCAdam preconditioner, being built from these blocks, remains G-equivariant. Rate extraction is therefore unchanged. We will append a short corollary that specialises the general theorem to these two gauge groups and records the explicit invariance of the extracted (λ, m, ν) triple. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper defines a dead direction via equivalence between Fisher metric degeneration and a KL-order tangent to the singular set, then claims to recover that order from directional Fisher curvature decay in original coordinates. This is presented as a derived relation rather than a definitional identity or fitted input renamed as prediction. No load-bearing self-citation, uniqueness theorem imported from the same authors, or ansatz smuggled via prior work appears in the abstract or described central move. The selection rule on smooth fibres is introduced as a translation step to Watanabe's RLCT contribution without evidence that it reduces by construction to the paper's own inputs or prior self-referential results. Extensions to multi-component cases, network factorizations, and optimizers build outward from this without circular reduction. The work is therefore scored as self-contained against external singular learning theory benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KL order of dead direction equals decay rate of directional Fisher curvature near singularity
invented entities (1)
-
dead direction
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Dead-Direction Conditioners: Gauge-Equivariant Preconditioning for Deep Networks
Dead-Direction Conditioners provide gauge-equivariant preconditioning by conditioning optimizer state on symmetry orbits, yielding improved resistance to over-training collapse and higher detection of dead directions ...
-
Dead-Direction Signatures: A Cheap Spectral Reading of Singular Complexity
Dead-Direction Signatures provide closed-form spectral readings of dead directions in network activations and gradients that track rank deficits at singular minima, offering a cheap directional alternative to SGLD-based LLC.
-
Algebraic Dead Directions in LayerNorm Transformers: A Forward-Pass-Only Diagnostic at LLM Scale
The normalized inverse-scale direction of LayerNorm's affine parameters is an exact algebraic kernel of the post-final-norm centred activation covariance for any input distribution in LayerNorm transformers.
Reference graph
Works this paper leans on
-
[1]
M. Adam, Z. Furman, and J. Hoogland. The loss kernel: A geometric probe for deep learning interpretability, 2025. URL https://arxiv.org/abs/2509.26537
arXiv 2025
-
[2]
S.-i. Amari. Information Geometry and Its Applications, volume 194 of Applied Mathematical Sciences. Springer, 2016. URL https://link.springer.com/book/10.1007/978-4-431-55978-8
-
[3]
S.-i. Amari, H. Park, and T. Ozeki. Singularities affect dynamics of learning in neuromanifolds. Neural Computation, 18 0 (5): 0 1007--1065, 2006. URL https://doi.org/10.1162/neco.2006.18.5.1007
-
[4]
M. Aoyagi. Consideration on the learning efficiency of multiple-layered neural networks with linear units. Neural Networks, 172: 0 106132, 2024. URL https://doi.org/10.1016/j.neunet.2024.106132
-
[5]
M. Aoyagi and S. Watanabe. Stochastic complexities of reduced rank regression in B ayesian estimation. Neural Networks, 18 0 (7): 0 924--933, 2005. URL https://doi.org/10.1016/j.neunet.2005.03.014
- [6]
- [7]
-
[8]
L. Carroll. Phase transitions in neural networks. Master's thesis, School of Mathematics and Statistics, The University of Melbourne, 2021. URL http://therisingsea.org/notes/MSc-Carroll.pdf
2021
-
[9]
Z. Chen and D. Murfet. Modes of sequence models and learning coefficients, 2025. URL https://arxiv.org/abs/2504.18048
arXiv 2025
-
[10]
Z. Chen, E. Lau, J. Mendel, S. Wei, and D. Murfet. Dynamical versus B ayesian phase transitions in a toy model of superposition, 2023. URL https://arxiv.org/abs/2310.06301
arXiv 2023
-
[11]
A. de Br \'e bisson and P. Vincent. The Z -loss: A shift and scale invariant classification loss belonging to the spherical family. arXiv preprint arXiv:1604.08859, 2016. URL https://arxiv.org/abs/1604.08859
Pith/arXiv arXiv 2016
-
[12]
A. DePavia, V. Charisopoulos, and R. Willett. How do simple rotations affect the implicit bias of Adam ? arXiv preprint arXiv:2510.23804, 2025. URL https://arxiv.org/abs/2510.23804
arXiv 2025
-
[13]
Y. Dong, J.-B. Cordonnier, and A. Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning (ICML), 2021. URL https://arxiv.org/abs/2103.03404
arXiv 2021
-
[14]
Elhage, T
N. Elhage, T. Hume, C. Olsson, N. Nanda, T. Henighan, S. Johnston, S. E. Showk, N. Joseph, N. DasSarma, B. Mann, D. Hernandez, A. Askell, K. Ndousse, A. Jones, D. Drain, A. Chen, Y. Bai, D. Ganguli, L. Lovitt, Z. Hatfield-Dodds, J. Kernion, T. Conerly, S. Kravec, S. Fort, S. Kadavath, J. Jacobson, E. Tran-Johnson, J. Kaplan, J. Clark, T. Brown, S. McCandl...
2022
-
[15]
Farrugia-Roberts
M. Farrugia-Roberts. Structural degeneracy in neural networks. Master's thesis, School of Computing and Information Systems, The University of Melbourne, 2022. URL https://far.in.net/mthesis
2022
-
[16]
M. Farrugia-Roberts. Functional equivalence and path connectivity of reducible hyperbolic tangent networks. In Advances in Neural Information Processing Systems 36 (NeurIPS), pages 79502--79517, 2023. URL https://arxiv.org/abs/2305.05089
arXiv 2023
-
[17]
Farrugia-Roberts
M. Farrugia-Roberts. Losslessly compressible neural network parameters. In Workshop on Machine Learning and Compression, NeurIPS, 2024. URL https://neurips.cc/virtual/2024/98217
2024
- [18]
- [19]
-
[20]
J. Hoogland, G. Wang, M. Farrugia-Roberts, L. Carroll, S. Wei, and D. Murfet. Loss landscape degeneracy and stagewise development in transformers. Transactions on Machine Learning Research, 2024. URL https://arxiv.org/abs/2402.02364
arXiv 2024
-
[21]
J. Kim, B. Lee, C. Park, Y. Oh, B. Kim, T. Yoo, S. Shin, D. Han, J. Shin, and K. M. Yoo. Peri-LN : Revisiting normalization layer in the transformer architecture. arXiv preprint, 2025. URL https://arxiv.org/abs/2502.02732. Names the pre-norm + post-norm pattern ``Peri-LN'' and analyses its effect on activation magnitudes (linear vs exponential growth) and...
arXiv 2025
-
[22]
P. A. Kreer, W. Wu, M. Adam, Z. Furman, and J. Hoogland. B ayesian influence functions for hessian-free data attribution, 2025. URL https://arxiv.org/abs/2509.26544
arXiv 2025
- [23]
-
[24]
F. Kunstner, L. Balles, and P. Hennig. Limitations of the empirical F isher approximation for natural gradient descent. In NeurIPS, 2019. URL https://arxiv.org/abs/1905.12558
arXiv 2019
-
[25]
E. Lau, Z. Furman, G. Wang, D. Murfet, and S. Wei. The local learning coefficient: A singularity-aware complexity measure. In AISTATS, 2025. URL https://proceedings.mlr.press/v258/lau25a.html
2025
-
[26]
J. H. Lee, M. Smith, M. Adam, and J. Hoogland. Influence dynamics and stagewise data attribution, 2025. URL https://arxiv.org/abs/2510.12071
Pith/arXiv arXiv 2025
-
[27]
J. Martens and R. Grosse. Optimizing neural networks with Kronecker -factored approximate curvature. In ICML, 2015. URL https://arxiv.org/abs/1503.05671
arXiv 2015
-
[28]
D. Murfet and W. Troiani. Programs as singularities, 2025. URL https://arxiv.org/abs/2504.08075
arXiv 2025
-
[29]
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. In ICLR, 2023. URL https://arxiv.org/abs/2301.05217
Pith/arXiv arXiv 2023
-
[30]
L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, and A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/2206.03126
arXiv 2022
-
[31]
V. Papyan. Traces of class/cross-class structure pervade deep learning spectra. JMLR, 21 0 (252): 0 1--64, 2020. URL https://jmlr.org/papers/volume21/20-933/20-933.pdf
2020
-
[32]
URL https://www.pnas.org/doi/abs/10.1073/pnas
V. Papyan, X. Y. Han, and D. L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117 0 (40): 0 24652--24663, 2020. URL https://doi.org/10.1073/pnas.2015509117
- [33]
-
[34]
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv:2201.02177, 2022
Pith/arXiv arXiv 2022
-
[35]
N. Shazeer, Y. Cheng, N. Parmar, D. Tran, A. Vaswani, P. Koanantakool, P. Hawkins, H. Lee, M. Hong, C. Young, R. Sepassi, and B. Hechtman. Mesh- TensorFlow : Deep learning for supercomputers. In Advances in Neural Information Processing Systems (NeurIPS), 2018. URL https://arxiv.org/abs/1811.02084
Pith/arXiv arXiv 2018
-
[36]
M. Sun, X. Chen, J. Z. Kolter, and Z. Liu. Massive activations in large language models. In COLM, 2024. URL https://arxiv.org/abs/2402.17762
Pith/arXiv arXiv 2024
-
[37]
H. Tanaka and D. Kunin. Noether's learning dynamics: Role of symmetry breaking in neural networks. In NeurIPS, 2021. URL https://arxiv.org/abs/2105.02716
arXiv 2021
-
[38]
E. Urdshals, E. Lau, J. Hoogland, S. van Wingerden, and D. Murfet. Compressibility measures complexity: Minimum description length meets singular learning theory, 2025. URL https://arxiv.org/abs/2510.12077
arXiv 2025
-
[39]
G. Wang, J. Hoogland, S. van Wingerden, Z. Furman, and D. Murfet. Differentiation and specialization of attention heads via the refined local learning coefficient, 2024. URL https://arxiv.org/abs/2410.02984
arXiv 2024
- [40]
-
[41]
Cambridge Monographs on Applied and Computational Mathematics, vol
S. Watanabe. Algebraic Geometry and Statistical Learning Theory. Cambridge University Press, 2009. URL https://doi.org/10.1017/CBO9780511800474
- [42]
-
[43]
S. Wei, D. Murfet, M. Gong, H. Li, J. Gell-Redman, and T. Quella. Deep learning is singular, and that's good. IEEE Transactions on Neural Networks and Learning Systems, 34 0 (12): 0 10473--10486, 2023. URL https://ieeexplore.ieee.org/document/9812468
arXiv 2023
-
[44]
B. Zoph, I. Bello, S. Kumar, N. Du, Y. Huang, J. Dean, N. Shazeer, and W. Fedus. ST-MoE : Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906, 2022. URL https://arxiv.org/abs/2202.08906
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.