Optimally taming biases in black-box models for efficient semiparametric estimation
Pith reviewed 2026-06-27 23:16 UTC · model grok-4.3
The pith
In the partial linear model, a new estimator achieves the rate n to the minus one half plus approximation error plus squared stochastic error when the auxiliary function cannot be estimated consistently, and this rate is optimal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
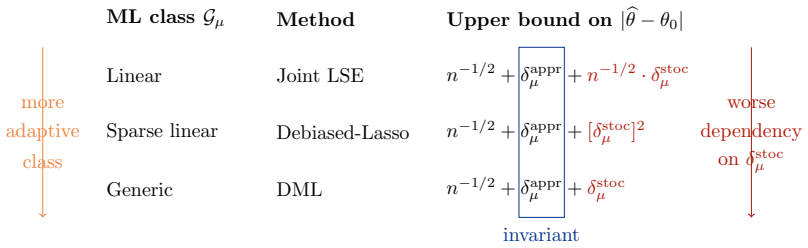
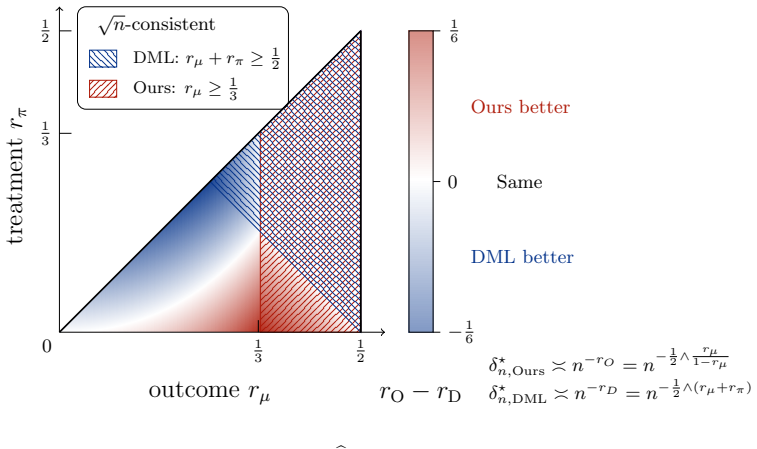
We show that the standard DML rate is not optimal in the regime where the auxiliary function E[T|X=x] cannot be consistently estimated. We propose a new estimator for β0 that achieves a sharper rate of n^{-1/2}+δ^a_μ+(δ_μ^s)^2 and establish a matching lower bound demonstrating its optimality. Our results reveal a new principle: the first-order stochastic error of nuisance estimation can be eliminated without imposing any additional assumptions. This also leads to a revised tuning strategy favoring under-smoothing, where δ^a_μ ≍ (δ_μ^s)^2, rather than the classical bias-variance trade-off. Under mild additional conditions, the estimator is asymptotically normal with minimal asymptotic varianc
What carries the argument
The new estimator for β0 that removes the first-order stochastic error of the nuisance function estimator while retaining only its quadratic contribution.
If this is right
- The estimator attains asymptotic normality with the minimal asymptotic variance under mild additional conditions.
- Tuning of the nuisance learner should target under-smoothing with approximation error on the order of the square of stochastic error.
- The same rate improvement applies to average treatment effect estimation and other semiparametric linear functional problems.
- Popular orthogonal score methods that rely on black-box nuisance learners can be substantially improved by the new construction.
Where Pith is reading between the lines
- The quadratic-error principle may encourage deliberate use of faster but more biased nuisance estimators in high-complexity settings.
- Similar first-order error removal could be investigated for nonlinear semiparametric models or other target functionals.
- Cross-validation routines for nuisance parameters may need redesign to optimize the new error balance rather than classical bias-variance.
Load-bearing premise
The analysis is conducted in the regime where the auxiliary function E[T|X=x] cannot be consistently estimated.
What would settle it
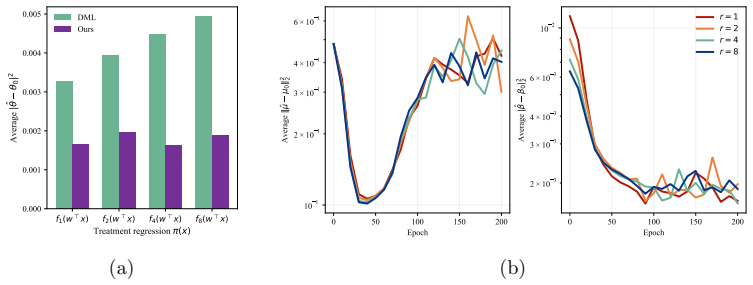
A simulation or explicit construction in the partial linear model, with E[T|X=x] not consistently estimable, in which either the new estimator exceeds the claimed rate or some other procedure attains a strictly faster rate, would settle the claim.
Figures
read the original abstract
Modern semiparametric estimation often relies on flexible black-box machine learning methods to estimate nuisance functions, raising a fundamental question: how do nuisance estimation errors propagate into inference for low-dimensional target parameters? The dominant paradigm, exemplified by double machine learning (DML), yields error bounds in which nuisance estimation errors enter multiplicatively. While widely adopted, it remains unclear whether this multiplicative-rate dependence is optimal for black-box models. In this paper, we start by revisiting the partial linear model $Y = \mu_0(X)+T\cdot\beta_0+\varepsilon$ under a structure-agnostic setting, where the nuisance function $\mu_0$ is estimated using a generic machine learning model, with approximation error $\delta^a_\mu$ and stochastic error $\delta_\mu^s$. We show that the standard DML rate is not optimal in the regime where the auxiliary function $\mathbb{E}[T|X=x]$ cannot be consistently estimated. We propose a new estimator for $\beta_0$ that achieves a sharper rate of $n^{-1/2}+\delta^a_\mu+(\delta_\mu^s)^2$ and establish a matching lower bound demonstrating its optimality. Our results reveal a new principle: the first-order stochastic error of nuisance estimation can be eliminated without imposing any additional assumptions. This also leads to a revised tuning strategy favoring under-smoothing, where $\delta^a_\mu\asymp(\delta_\mu^s)^2$, rather than the classical bias-variance trade-off $\delta^a_\mu \asymp \delta_\mu^s$. Under mild additional conditions, the estimator is asymptotically normal with minimal asymptotic variance. The proposed method extends to a broad class of semi-parametric linear functional estimation problems, including average treatment effect estimation. Our results imply that popular orthogonal score methods in semiparametric estimation with black-box nuisance learners can be substantially improved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper considers semiparametric estimation of a low-dimensional parameter β0 in the partial linear model Y = μ0(X) + T β0 + ε, where the nuisance μ0 is estimated by a generic black-box ML method with approximation error δ^a_μ and stochastic error δ_μ^s. It shows that the standard DML rate is suboptimal in the regime where E[T|X=x] cannot be consistently estimated, proposes a new estimator achieving the sharper rate n^{-1/2} + δ^a_μ + (δ_μ^s)^2 together with a matching lower bound, and establishes asymptotic normality under mild conditions. The approach is extended to a class of semiparametric linear functionals including average treatment effects, with a revised under-smoothing tuning recommendation.
Significance. If the central claims hold, the contribution is significant: it isolates a regime in which the first-order stochastic component of nuisance error can be removed without extra assumptions, supplies an optimality certificate via the matching lower bound, and yields a concrete change in tuning practice (δ^a_μ ≍ (δ_μ^s)^2 rather than the classical bias-variance balance). The extension to other linear functionals broadens applicability. These elements together constitute a substantive refinement of the DML paradigm for black-box nuisance learners.
minor comments (3)
- The abstract and introduction state the new rate and the regime restriction clearly, but the precise definition of the auxiliary function E[T|X=x] and its relation to the partial linear model should be restated once in the main theorem statement for readability.
- The extension section would benefit from an explicit statement of the additional mild conditions required for asymptotic normality, preferably collected in a single assumption block rather than scattered across the text.
- Notation for the stochastic and approximation errors (δ_μ^s and δ^a_μ) is used consistently, yet a short table summarizing the rate comparisons with DML under the two regimes would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its significance in refining the DML paradigm, and the recommendation for minor revision. No major comments requiring point-by-point rebuttal were raised in the report.
Circularity Check
No significant circularity
full rationale
The derivation proceeds from an explicit error decomposition of the nuisance function into approximation error δ^a_μ and stochastic error δ_μ^s within the partial linear model, under the openly stated regime where E[T|X=x] is not consistently estimable. The sharper rate n^{-1/2} + δ^a_μ + (δ_μ^s)^2 and its matching lower bound are obtained by direct analysis of the first-order stochastic term elimination; no equation reduces to a fitted parameter renamed as a prediction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The central claim remains independent of its own outputs and is supported by the stated assumptions without self-referential closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data follow the partial linear model Y = μ0(X) + T·β0 + ε under a structure-agnostic setting
Forward citations
Cited by 1 Pith paper
-
On the Asymptotic Inadmissibility of Double Machine Learning Estimators Under Structure-Agnostic Models
DML estimators for the quadratic functional and quadratic density integral are asymptotically inadmissible under SA models and dominated by empirical HOIF estimators, while DML remains minimax for expected conditional...
Reference graph
Works this paper leans on
-
[1]
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In International conference on machine learning (pp.\ 214--223).: PMLR
2017
-
[2]
W., & Wager, S
Athey, S., Imbens, G. W., & Wager, S. (2018). Approximate residual balancing: debiased inference of average treatment effects in high dimensions. Journal of the Royal Statistical Society Series B: Statistical Methodology , 80(4), 597--623
2018
-
[3]
Balakrishnan, S., Kennedy, E. H., & Wasserman, L. (2023). The fundamental limits of structure-agnostic functional estimation. arXiv preprint arXiv:2305.04116
arXiv 2023
-
[4]
Bartlett, P., Bousquet, O., & Mendelson, S. (2005). Local rademacher complexities. Annals of Statistics , 33(4), 1497--1537
2005
-
[5]
& Kohler, M
Bauer, B. & Kohler, M. (2019). On deep learning as a remedy for the curse of dimensionality in nonparametric regression. The Annals of Statistics , 47(4), 2261--2285
2019
-
[6]
Bellec, P. C. & Zhang, C.-H. (2022). De-biasing the lasso with degrees-of-freedom adjustment. Bernoulli , 28(2), 713--743
2022
-
[7]
Belloni, A., Chernozhukov, V., & Hansen, C. (2014). Inference on treatment effects after selection among high-dimensional controls. Review of Economic Studies , 81(2), 608--650
2014
-
[8]
H., Dukes, O., & Balakrishnan, S
Bonvini, M., Kennedy, E. H., Dukes, O., & Balakrishnan, S. (2024). Doubly-robust inference and optimality in structure-agnostic models with smoothness. arXiv preprint arXiv:2405.08525
arXiv 2024
-
[9]
Bradic, J., Fan, J., & Zhu, Y. (2022). Testability of high-dimensional linear models with nonsparse structures. Annals of statistics , 50(2), 615
2022
-
[10]
Breiman, L. (2001). Random forests. Machine learning , 45(1), 5--32
2001
-
[11]
Bruns-Smith, D., Dukes, O., Feller, A., & Ogburn, E. L. (2025). Augmented balancing weights as linear regression. Journal of the Royal Statistical Society Series B: Statistical Methodology , (pp.\ qkaf019)
2025
-
[12]
Cai, T. T. & Guo, Z. (2017). Confidence intervals for high-dimensional linear regression: Minimax rates and adaptivity . The Annals of Statistics , 45(2), 615 -- 646
2017
-
[13]
J., Fan, J., Gijbels, I., & Wand, M
Carroll, R. J., Fan, J., Gijbels, I., & Wand, M. P. (1997). Generalized partially linear single-index models. Journal of the American Statistical Association , 92(438), 477--489
1997
-
[14]
Celentano, M. & Wainwright, M. J. (2023). Challenges of the inconsistency regime: Novel debiasing methods for missing data models. arXiv preprint arXiv:2309.01362
arXiv 2023
-
[15]
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., & Newey, W. (2017). Double/debiased/neyman machine learning of treatment effects. American Economic Review , 107(5), 261--265
2017
-
[16]
K., & Singh, R
Chernozhukov, V., Newey, W. K., & Singh, R. (2022a). Automatic debiased machine learning of causal and structural effects. Econometrica , 90(3), 967--1027
-
[17]
K., & Singh, R
Chernozhukov, V., Newey, W. K., & Singh, R. (2022b). Debiased machine learning of global and local parameters using regularized riesz representers. The Econometrics Journal , 25(3), 576--601
-
[18]
K., Singh, R., & Syrgkanis, V
Chernozhukov, V., Newey, W. K., Singh, R., & Syrgkanis, V. (2026). Adversarial estimation of riesz representers. Journal of the American Statistical Association , (pp.\ 1--12)
2026
-
[19]
Donald, S. G. & Newey, W. K. (1994). Series estimation of semilinear models. Journal of Multivariate Analysis , 50(1), 30--40
1994
-
[20]
Fan, J. & Gu, Y. (2024). Factor augmented sparse throughput deep relu neural networks for high dimensional regression. Journal of the American Statistical Association , 119(548), 2680--2694
2024
-
[21]
Fan, J., Gu, Y., & Zhou, W.-X. (2024). How do noise tails impact on deep ReLU networks? The Annals of Statistics , 52(4), 1845 -- 1871
2024
-
[22]
& Huang, T
Fan, J. & Huang, T. (2005). Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli , 11(6), 1031--1057
2005
-
[23]
Fan, J., Imai, K., Lee, I., Liu, H., Ning, Y., & Yang, X. (2022). Optimal covariate balancing conditions in propensity score estimation. Journal of Business & Economic Statistics , 41(1), 97--110
2022
-
[24]
Fan, J., Li, R., Zhang, C.-H., & Zou, H. (2020). Statistical foundations of data science . Chapman and Hall/CRC
2020
-
[25]
Farrell, M. H. (2015). Robust inference on average treatment effects with possibly more covariates than observations. Journal of Econometrics , 189(1), 1--23
2015
-
[26]
H., Liang, T., & Misra, S
Farrell, M. H., Liang, T., & Misra, S. (2021). Deep neural networks for estimation and inference. Econometrica , 89(1), 181--213
2021
-
[27]
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM , 63(11), 139--144
2020
-
[28]
Gu, Y. (2025). Open problem: Structure-agnostic minimax risk for partial linear model. In The Thirty Eighth Annual Conference on Learning Theory (pp.\ 6220--6224).: PMLR
2025
-
[29]
Gu, Y., Fang, C., B \"u hlmann, P., & Fan, J. (2025). Causality pursuit from heterogeneous environments via neural adversarial invariance learning . The Annals of Statistics , 53(5), 2230 -- 2257
2025
-
[30]
& Suzuki, T
Hayakawa, S. & Suzuki, T. (2020). On the minimax optimality and superiority of deep neural network learning over sparse parameter spaces. Neural Networks , 123, 343--361
2020
-
[31]
Hellerstein, J. K. & Imbens, G. W. (1999). Imposing moment restrictions from auxiliary data by weighting. Review of Economics and Statistics , 81(1), 1--14
1999
-
[32]
Hirshberg, D. A. & Wager, S. (2021). Augmented minimax linear estimation. The Annals of Statistics , 49(6), 3206--3227
2021
-
[33]
u ller, S., Purucker, L., Krishnakumar, A., K \
Hollmann, N., M \"u ller, S., Purucker, L., Krishnakumar, A., K \"o rfer, M., Hoo, S. B., Schirrmeister, R. T., & Hutter, F. (2025). Accurate predictions on small data with a tabular foundation model. Nature , 637(8045), 319--326
2025
-
[34]
& Ratkovic, M
Imai, K. & Ratkovic, M. (2014). Covariate balancing propensity score. Journal of the Royal Statistical Society Series B: Statistical Methodology , 76(1), 243--263
2014
-
[35]
& Montanari, A
Javanmard, A. & Montanari, A. (2014). Confidence intervals and hypothesis testing for high-dimensional regression. Journal of Machine Learning Research , 15(82), 2869--2909
2014
-
[36]
& Montanari, A
Javanmard, A. & Montanari, A. (2018). Debiasing the lasso: Optimal sample size for Gaussian designs . The Annals of Statistics , 46(6A), 2593 -- 2622
2018
-
[37]
Jin, J., Mackey, L., & Syrgkanis, V. (2025). It's hard to be normal: The impact of noise on structure-agnostic estimation. arXiv preprint arXiv:2507.02275
arXiv 2025
-
[38]
Jin, J. & Syrgkanis, V. (2024). Structure-agnostic optimality of doubly robust learning for treatment effect estimation. arXiv preprint arXiv:2402.14264
arXiv 2024
-
[39]
Jin, J. & Syrgkanis, V. (2025). Sharp structure-agnostic lower bounds for general linear functional estimation. arXiv preprint arXiv:2512.17341
arXiv 2025
-
[40]
& Langer, S
Kohler, M. & Langer, S. (2021). On the rate of convergence of fully connected deep neural network regression estimates. The Annals of Statistics , 49(4), 2231--2249
2021
-
[41]
Koltchinskii, V. (2006). Local Rademacher complexities and oracle inequalities in risk minimization . The Annals of Statistics , 34(6), 2593 -- 2656
2006
-
[42]
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature , 521(7553), 436--444
2015
-
[43]
Liu, L., Mukherjee, R., Newey, W. K., & Robins, J. M. (2017). Semiparametric efficient empirical higher order influence function estimators. arXiv preprint arXiv:1705.07577
arXiv 2017
-
[44]
& N \'e d \'e lec, \'E
Massart, P. & N \'e d \'e lec, \'E . (2006). Risk bounds for statistical learning. Ann. Statist. , 34(1), 2326--2366
2006
-
[45]
P., Grabocka, J., & Hutter, F
M \"u ller, S., Hollmann, N., Arango, S. P., Grabocka, J., & Hutter, F. (2022). Transformers can do bayesian inference. In International Conference on Learning Representations
2022
-
[46]
Ning, Y., Sida, P., & Imai, K. (2020). Robust estimation of causal effects via a high-dimensional covariate balancing propensity score. Biometrika , 107(3), 533--554
2020
-
[47]
Robins, J., Li, L., Tchetgen, E., van der Vaart, A., et al. (2008). Higher order influence functions and minimax estimation of nonlinear functionals. In Probability and statistics: essays in honor of David A. Freedman , volume 2 (pp.\ 335--422). Institute of Mathematical Statistics
2008
-
[48]
Robins, J., Li, L., Tchetgen, E. T., & van der Vaart, A. (2016). Technical report: Higher order influence functions and minimax estimation of nonlinear functionals. arXiv preprint arXiv:1601.05820
Pith/arXiv arXiv 2016
-
[49]
M., Rotnitzky, A., & Zhao, L
Robins, J. M., Rotnitzky, A., & Zhao, L. P. (1994). Estimation of regression coefficients when some regressors are not always observed. Journal of the American statistical Association , 89(427), 846--866
1994
-
[50]
Robinson, P. M. (1988). Root-n-consistent semiparametric regression. Econometrica: journal of the Econometric Society , (pp.\ 931--954)
1988
-
[51]
Schmidt-Hieber, J. (2020). Nonparametric regression using deep neural networks with relu activation function (with discussion). The Annals of Statistics , 48(4), 1875--1921
2020
-
[52]
Stone, C. J. (1977). Consistent Nonparametric Regression . The Annals of Statistics , 5(4), 595 -- 620
1977
-
[53]
Tan, Z. (2020). Model-assisted inference for treatment effects using regularized calibrated estimation with high-dimensional data. Annals of Statistics , 48(2), 811--837
2020
-
[54]
Van de Geer, S., B \"u hlmann, P., Ritov, Y., & Dezeure, R. (2014). On asymptotically optimal confidence regions and tests for high-dimensional models. The Annals of Statistics , 42(3), 1166--1202
2014
-
[55]
van der Laan, L., Luedtke, A., & Carone, M. (2024). Doubly robust inference via calibration. arXiv preprint arXiv:2411.02771
arXiv 2024
-
[56]
Van der Laan, M. J. (2014). Targeted estimation of nuisance parameters to obtain valid statistical inference. The international journal of biostatistics , 10(1), 29--57
2014
-
[57]
& Shah, R
Wang, Y. & Shah, R. D. (2024). Debiased inverse propensity score weighting for estimation of average treatment effects with high-dimensional confounders . The Annals of Statistics , 52(5), 1978 -- 2003
2024
-
[58]
& Zhang, S
Zhang, C.-H. & Zhang, S. S. (2014). Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 76(1), 217--242
2014
-
[59]
Zhao, Q. (2019). Covariate balancing propensity score by tailored loss functions . The Annals of Statistics , 47(2), 965 -- 993
2019
-
[60]
& Wang, J.-L
Zhong, Q. & Wang, J.-L. (2024). Neural networks for partially linear quantile regression. Journal of Business & Economic Statistics , 42(2), 603--614
2024
-
[61]
Zubizarreta, J. R. (2015). Stable weights that balance covariates for estimation with incomplete outcome data. Journal of the American Statistical Association , 110(511), 910--922
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.