Parthenon Law: A Self-Evolving Legal-Agent Framework
Pith reviewed 2026-06-28 06:25 UTC · model grok-4.3
The pith
Parthenon lets legal LLM agents improve their skills, tools, and knowledge from scored failures without changing model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
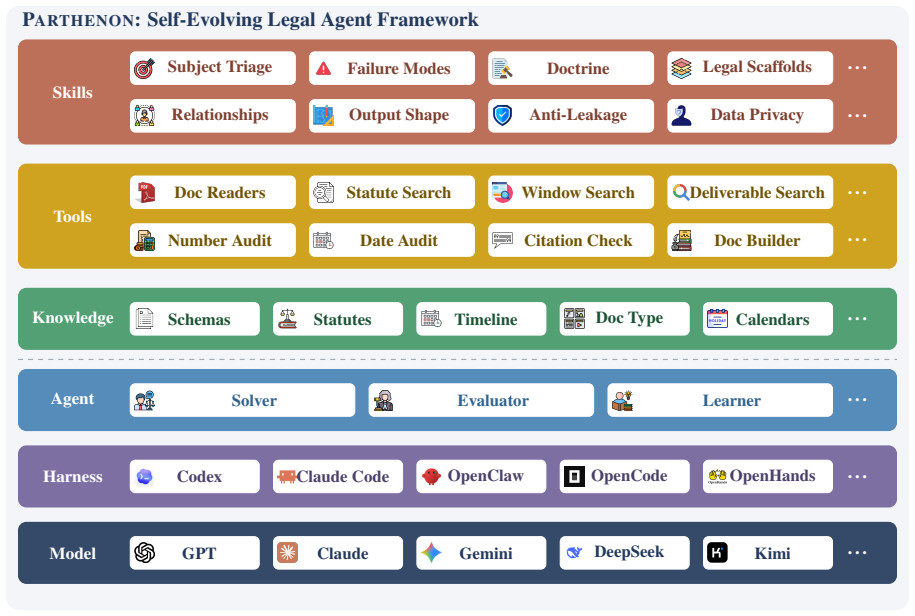
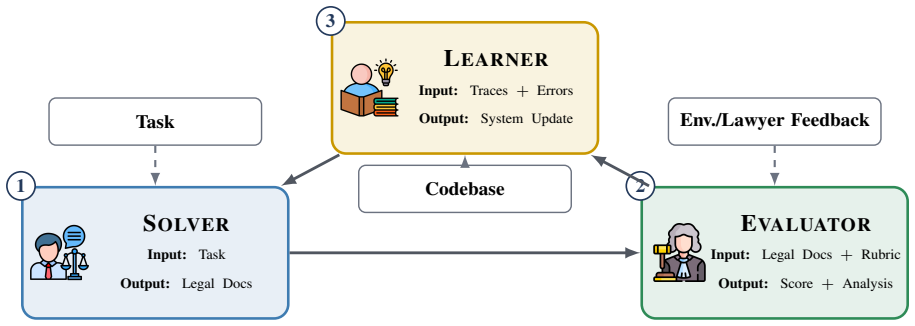
Parthenon factors the legal agent into Model, Harness, Agent roles, legal Knowledge, deterministic Tools, and procedural Skills with auditable surfaces for source traceability, date and number grounding, deliverable compliance, and issue closure, paired with an anti-leakage learning loop that converts scored failures into task-agnostic edits to skills, tools, and knowledge without touching model weights.
What carries the argument
The anti-leakage learning loop that converts scored failures into task-agnostic edits to skills, tools, and knowledge.
If this is right
- State-of-the-art models and harnesses achieve higher performance on legal-matter tasks when wrapped in the factored architecture and loop.
- Strict matter completion improves through repeated refinement of the non-model components.
- Traceability, grounding, and compliance remain enforced because all changes occur on the auditable surfaces.
- The system can accumulate improvements across many matters without model retraining or external data injection.
Where Pith is reading between the lines
- The same separation of components and failure-to-edit loop could support agents in other regulated fields that demand auditability.
- Long-term gains may depend more on the quality of the learning loop than on scaling the base model further.
- Law firms could treat the evolving components as living playbooks that agents consult and update after each engagement.
Load-bearing premise
The anti-leakage learning loop can reliably convert scored failures into genuine improvements to skills, tools, and knowledge without introducing new errors.
What would settle it
Apply the learning loop to a set of scored failures and measure whether accuracy on a fresh set of legal matters rises, stays flat, or falls.
Figures
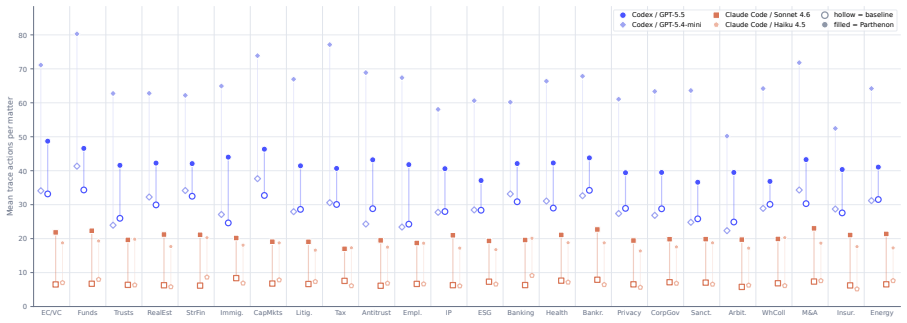
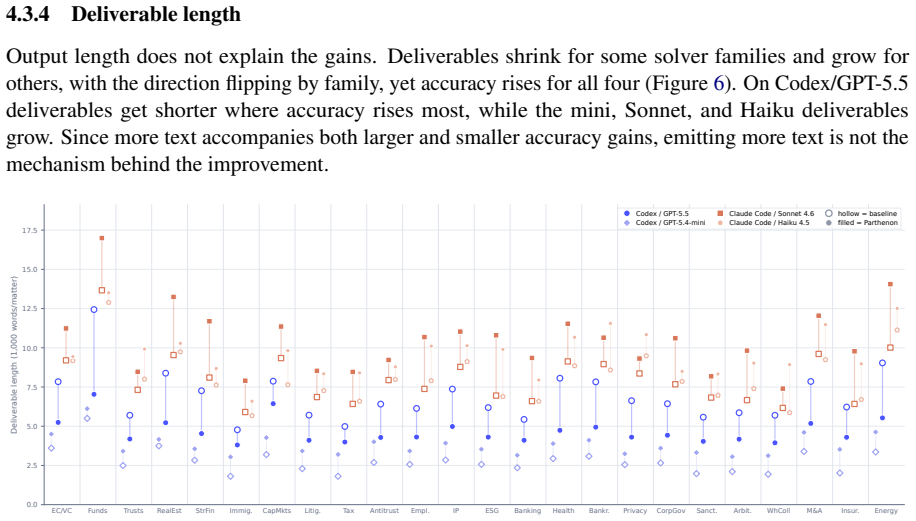
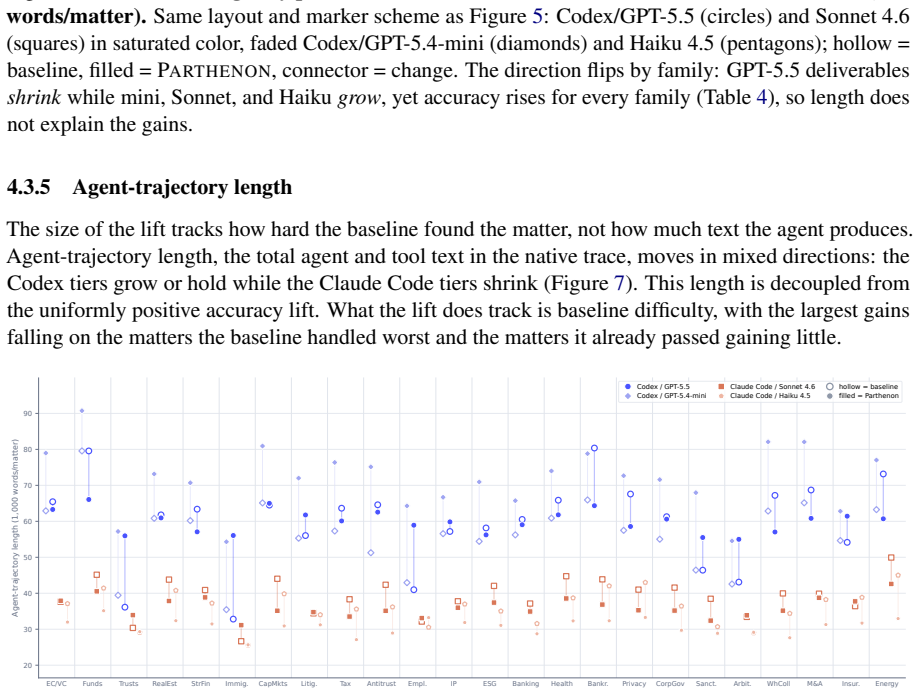
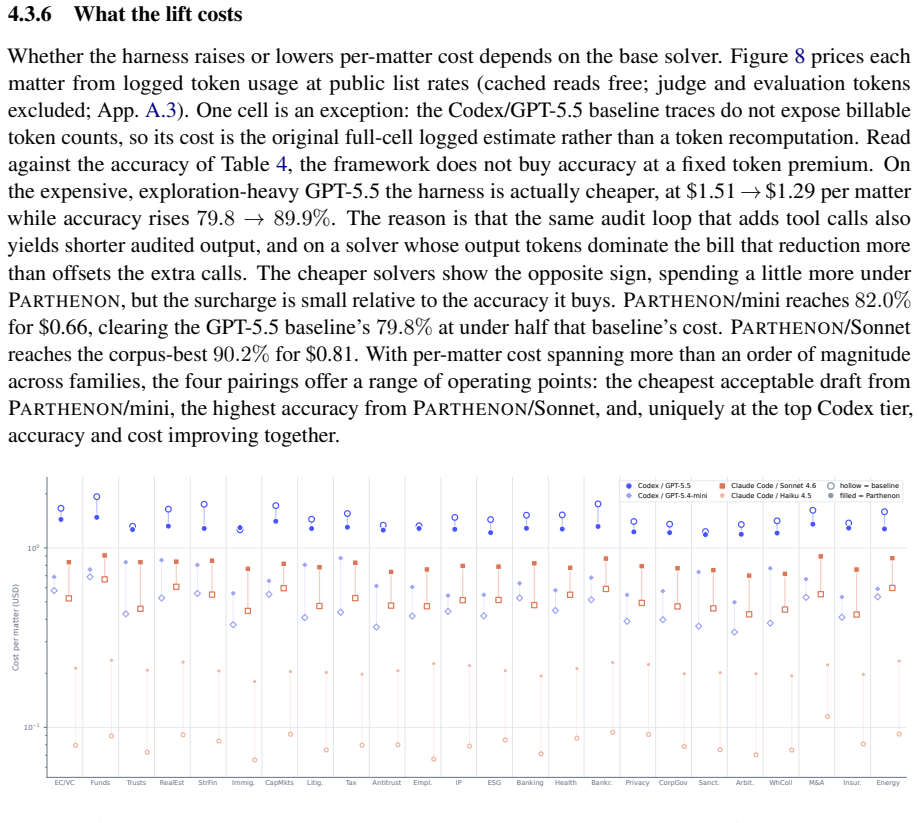
read the original abstract
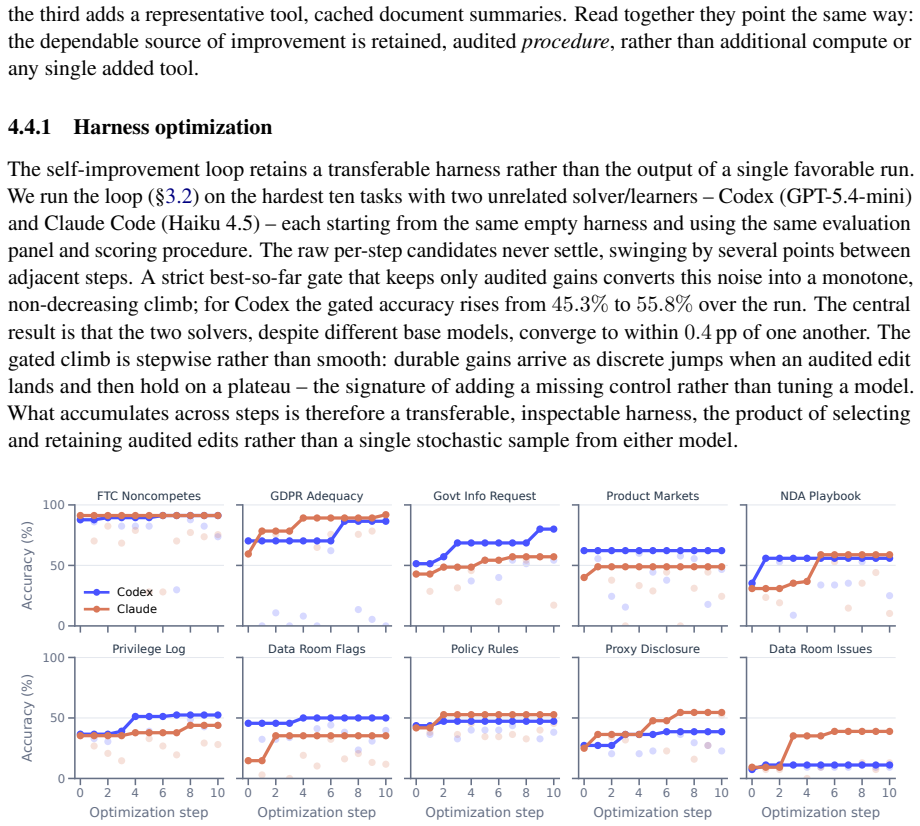
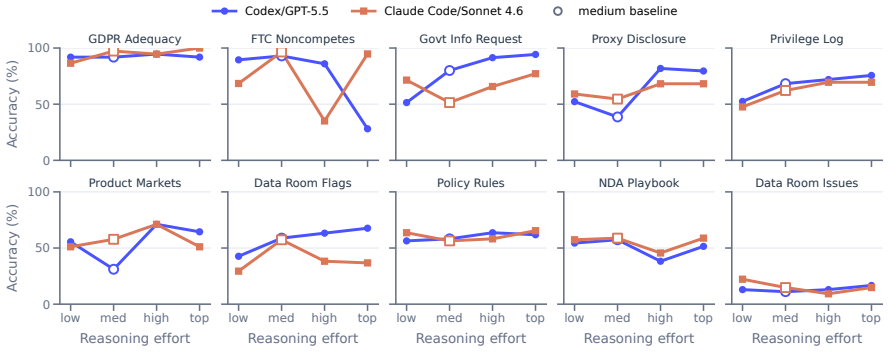
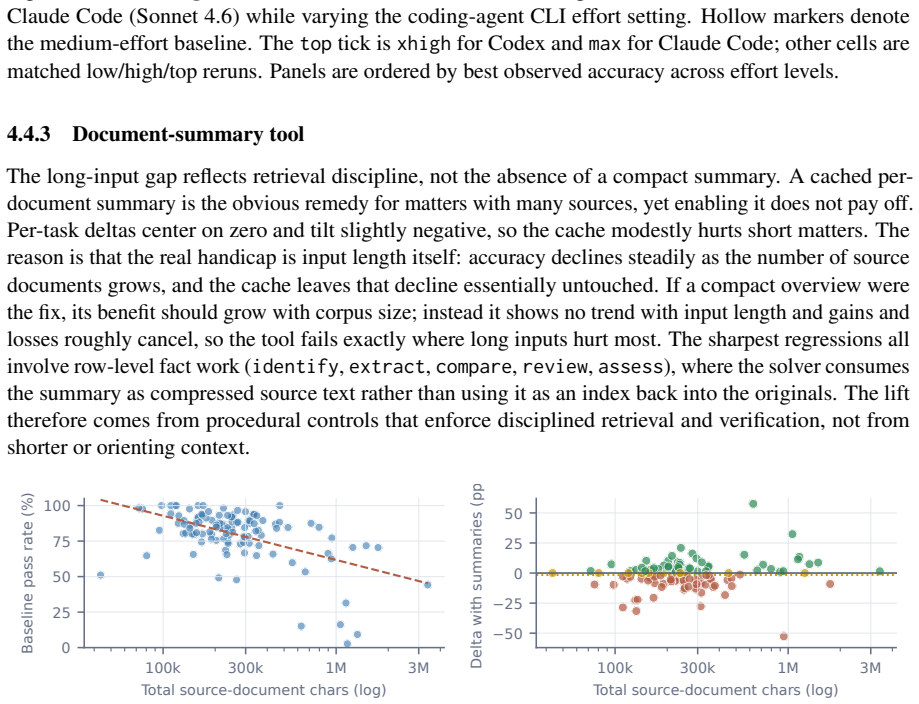
As agents grow more capable, legal-domain LLM agents promise to turn document-heavy matters into reviewable work products -- yet reliable deployment faces three obstacles: no large-scale evidence on how today's strongest model-and-harness combinations behave on end-to-end legal matters; no agent architecture adapted to the legal vertical, only general-purpose harnesses; and, in a setting that keeps shifting with new facts, authorities, and deadlines, no mechanism for systems to learn from their own outcomes. We address each. A large-scale empirical study on Harvey LAB -- $12{,}510$ agent trajectories -- shows that even frontier agents remain far from completing matters in a single pass: per-criterion accuracy climbs with stronger models while strict matter completion stalls. We then introduce \textsc{Parthenon}, a self-evolving legal-agent framework that factors Model, Harness, Agent roles, legal Knowledge, deterministic Tools, and procedural Skills into auditable surfaces for source traceability, date and number grounding, deliverable compliance, and issue closure. Finally, an anti-leakage learning loop converts scored failures into task-agnostic edits to skills, tools, and knowledge, letting the system improve with experience -- as a firm refines its checklists and playbooks after each matter -- without touching model weights. Across our large-scale empirical analysis, \textsc{Parthenon} substantially improves the performance of state-of-the-art models and harnesses on legal-matter tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a large-scale study of 12,510 agent trajectories on legal matters reveals that even frontier LLM agents fail to complete end-to-end legal tasks in a single pass, introduces the Parthenon framework that decomposes Model, Harness, Agent, Knowledge, Tools, and Skills into auditable components for traceability and compliance, and proposes an anti-leakage learning loop that converts scored failures into task-agnostic edits to skills/tools/knowledge (without model weight updates) to enable self-evolution, resulting in substantial performance gains on legal-matter tasks.
Significance. If the empirical results and learning-loop mechanics can be rigorously demonstrated, the work would provide valuable evidence on current agent limitations in a high-stakes vertical and a concrete architecture for experience-driven improvement that preserves auditability; the factoring of components into traceable surfaces is a constructive contribution to agent design for regulated domains.
major comments (3)
- [Abstract] Abstract: the claim that 'Parthenon substantially improves the performance of state-of-the-art models and harnesses' is unsupported by any quantitative results, baselines, statistical tests, or before/after metrics on the 12,510 trajectories; the data-to-claim link cannot be assessed.
- [anti-leakage learning loop description] Description of the anti-leakage learning loop: the mechanism that 'converts scored failures into task-agnostic edits to skills, tools, and knowledge' is stated at the level of intent only; no algorithm, pseudocode, or concrete procedure is supplied showing how leakage is prevented, how edits are validated as task-agnostic, or how net-positive improvement is isolated from the underlying model/harness.
- [empirical analysis section] Empirical evaluation of the learning loop: no section, table, or figure isolates the loop's contribution; the circularity risk that improvement is an artifact of the same scoring rules used to generate edits remains unaddressed.
minor comments (2)
- [Abstract] The abstract introduces several capitalized terms (Model, Harness, Agent, Knowledge, Tools, Skills) without an accompanying diagram or table that maps them to concrete interfaces.
- [Abstract] The phrase 'per-criterion accuracy climbs with stronger models while strict matter completion stalls' would benefit from an explicit definition of 'strict matter completion' and the set of criteria used.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each major comment below, agreeing that additional details and empirical rigor are needed to support the claims. We will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Parthenon substantially improves the performance of state-of-the-art models and harnesses' is unsupported by any quantitative results, baselines, statistical tests, or before/after metrics on the 12,510 trajectories; the data-to-claim link cannot be assessed.
Authors: We agree with the assessment that the abstract's claim is not supported by quantitative results in the current version. We will revise the abstract to incorporate specific performance metrics, baselines, and statistical tests from our analysis of the 12,510 trajectories, making the data-to-claim link explicit. revision: yes
-
Referee: [anti-leakage learning loop description] Description of the anti-leakage learning loop: the mechanism that 'converts scored failures into task-agnostic edits to skills, tools, and knowledge' is stated at the level of intent only; no algorithm, pseudocode, or concrete procedure is supplied showing how leakage is prevented, how edits are validated as task-agnostic, or how net-positive improvement is isolated from the underlying model/harness.
Authors: The current description is indeed high-level. We will expand this section with a formal algorithm description, including pseudocode for the loop. This will detail the scoring process, the generation of task-agnostic edits (e.g., via abstraction rules that remove task-specific elements), validation procedures to ensure no leakage (such as cross-validation on unseen tasks), and isolation of improvements through ablation studies comparing against model/harness baselines. revision: yes
-
Referee: [empirical analysis section] Empirical evaluation of the learning loop: no section, table, or figure isolates the loop's contribution; the circularity risk that improvement is an artifact of the same scoring rules used to generate edits remains unaddressed.
Authors: We acknowledge the absence of a dedicated isolation analysis and the potential circularity issue. We will add a new subsection in the empirical evaluation that includes tables and figures comparing Parthenon with and without the learning loop. To address circularity, we will use independent evaluation metrics, hold-out test sets not used in edit generation, and report results from multiple scoring variants to demonstrate that gains are not artifacts of the scoring rules. revision: yes
Circularity Check
No significant circularity; claims rest on empirical trajectories rather than definitional reduction.
full rationale
The paper presents an empirical study on 12,510 trajectories showing frontier agents fail to complete matters, then introduces the Parthenon framework factoring roles, knowledge, tools, and skills, plus an anti-leakage learning loop that converts scored failures into edits. No equations, self-definitional structures, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The performance improvement is asserted from the large-scale analysis, not derived by construction from the loop definition or scoring rules. The loop is described as a mechanism analogous to firm playbook refinement, but its effectiveness is not tautologically equivalent to its inputs. This is a standard empirical framework paper with no load-bearing circular steps matching the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. Legalbench:. doi:10.2139/ssrn.4583531 , journal =
-
[2]
and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , doi =
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , doi =. Proceedings of the National Academy of Sciences , title =
-
[3]
and Kemker, Ronald and Part, Jose L
Parisi, German I. and Kemker, Ronald and Part, Jose L. and Kanan, Christopher and Wermter, Stefan , doi =. Neural Networks , title =
-
[4]
Advances in Neural Information Processing Systems 36 , title =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , doi =. Advances in Neural Information Processing Systems 36 , title =
-
[5]
Advances in Neural Information Processing Systems 36 , title =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , doi =. Advances in Neural Information Proce...
-
[6]
Learning Beyond Gradients , year =
Trinkle , howpublished =. Learning Beyond Gradients , year =
-
[7]
Autoresearch , year =
Karpathy, Andrej , howpublished =. Autoresearch , year =
-
[8]
SSRN Electronic Journal , title =
Chalkidis, Ilias and Jana, Abhik and Hartung, Dirk and Bommarito, Michael James and Androutsopoulos, Ion and Katz, Daniel Martin and Aletras, Nikolaos , doi =. SSRN Electronic Journal , title =
-
[9]
Hendrycks, Dan and Burns, Collin and Chen, Anya and Ball, Spencer , doi =
-
[10]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , title =
Fei, Zhiwei and Shen, Xiaoyu and Zhu, Dawei and Zhou, Fengzhe and Han, Zhuo and Huang, Alan and Zhang, Songyang and Chen, Kai and Yin, Zhixin and Shen, Zongwen and Ge, Jidong and Ng, Vincent , doi =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , title =
2024
-
[11]
Lai, Jinqi and Gan, Wensheng and Wu, Jiayang and Qi, Zhenlian and Yu, Philip S. , doi =. AI Open , title =
-
[12]
Hou, Zhitian and Ye, Zihan and Zeng, Nanli and Hao, Tianyong and Zeng, Kun , doi =. Large
-
[13]
Xie, Huiyuan and others , doi =
-
[14]
Findings of the Association for Computational Linguistics ACL 2024 , title =
Servantez, Sergio and others , doi =. Findings of the Association for Computational Linguistics ACL 2024 , title =
2024
-
[15]
Advances in Neural Information Processing Systems 35 , title =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , doi =. Advances in Neural Information Processing Systems 35 , title =
-
[16]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , doi =
-
[17]
Schick, Timo and Dwivedi-Yu, Jane and Dess. Toolformer:. doi:10.52202/075280-2997 , journal =
-
[18]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Hong, Sirui and Zhuge, Mingchen and Chen, Jiaqi and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, J. doi:10.48550/arXiv.2308.00352 , title =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.00352
-
[19]
Cui, Jiaxi and Ning, Munan and Li, Zongjian and Chen, Bohua and Yan, Yang and Li, Hao and Ling, Bin and Tian, Yonghong and Yuan, Li , doi =
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , title =
Li, Haitao and Chen, Junjie and Yang, Jingli and Ai, Qingyao and Jia, Wei and Liu, Youfeng and Lin, Kai and Wu, Yueyue and Yuan, Guozhi and Hu, Yiran and Wang, Wuyue and Liu, Yiqun and Huang, Minlie , doi =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , title =
-
[21]
Mantravadi, Abhinav and others , doi =
-
[22]
Pipitone, Nicholas and Houir Alami, Ghita , doi =
-
[23]
Dahl, Matthew and Magesh, Varun and Suzgun, Mirac and Ho, Daniel E. , doi =. Journal of Legal Analysis , title =
-
[24]
Kant, Manuj and others , doi =. Towards
-
[25]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , title =
El Hamdani, Rajaa and Bonald, Thomas and Malliaros, Fragkiskos and Holzenberger, Nils and Suchanek, Fabian , doi =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , title =
-
[26]
and Desai, Deven R
Riedl, Mark O. and Desai, Deven R. , doi =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , title =
- [27]
-
[28]
Royal Society Open Science , title =
Wachter, Sandra and Mittelstadt, Brent and Russell, Chris , doi =. Royal Society Open Science , title =
-
[29]
Patwardhan, Tejal and others , doi =
-
[30]
Yang, Qianyu and others , doi =
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , title =
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , doi =. Proceedings of the AAAI Conference on Artificial Intelligence , title =
-
[32]
Voyager:
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , doi =. Voyager:
-
[33]
and Moazam, Hanna and Miller, Heather and Zaharia, Matei and Potts, Christopher , doi =
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and Zhang, Zhiyuan and Santhanam, Keshav and Vardhamanan, Sri and Haq, Saiful and Sharma, Ashutosh and Joshi, Thomas T. and Moazam, Hanna and Miller, Heather and Zaharia, Matei and Potts, Christopher , doi =
-
[34]
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Huang, Zhi and Guestrin, Carlos and Zou, James , doi =
-
[35]
Automated
Hu, Shengran and Lu, Cong and Clune, Jeff , doi =. Automated
-
[36]
Zhang, Jiayi and Xiang, Jinyu and Yu, Zhaoyang and Teng, Fengwei and Chen, Xionghui and Chen, Jiaqi and Zhuge, Mingchen and Cheng, Xin and Hong, Sirui and Wang, Jinlin and Zheng, Bingnan and Liu, Bang and Luo, Yuyu and Wu, Chenglin , doi =
-
[37]
Fang, Jinyuan and Peng, Yanwen and Zhang, Xi and Wang, Yingxu and Yi, Xinhao and Zhang, Guibin and Xu, Yi and Wu, Bin and Liu, Siwei and Li, Zihao and Ren, Zhaochun and Aletras, Nikos and Wang, Xi and Zhou, Han and Meng, Zaiqiao , doi =. A
-
[38]
Wang, Yimeng and Zhao, Jiaxing and Xie, Hongbin and Ma, Hexing and Lei, Yuzhen and Liu, Shuangxue and Song, Xuan and Zhang, Zichen and Zhang, Haoran , doi =
-
[39]
Chen, Weize and Su, Yusheng and Zuo, Jingwei and Yang, Cheng and Yuan, Chenfei and Chan, Chi-Min and Yu, Heyang and Lu, Yaxi and Hung, Yi-Hsin and Qian, Chen and Qin, Yujia and Cong, Xin and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong and Zhou, Jie , doi =
-
[40]
Grupen, Niko and Pereyra, Gabe and Pereyra, Julio , title =
-
[41]
How Much Should I Charge as a Lawyer? Compare Average Lawyer Hourly Rate by State , howpublished =
-
[42]
Liu, Zijun and Zhang, Yanzhe and Li, Peng and Liu, Yang and Yang, Diyi , doi =. A
-
[43]
Language
Zhou, Andy and Yan, Kai and Shlapentokh-Rothman, Michal and Wang, Haohan and Wang, Yu-Xiong , doi =. Language
-
[44]
Koh, Jing Yu and McAleer, Stephen and Fried, Daniel and Salakhutdinov, Ruslan , doi =. Tree
-
[45]
Banerjee, Debangshu and Xu, Changming and Ie, Eugene and Zhang, Ming and Peng, Daiyi and Lin, Chu-Cheng and Singh, Gagandeep , doi =
-
[46]
and Yao, Shunyu and Narasimhan, Karthik and Griffiths, Thomas L
Sumers, Theodore R. and Yao, Shunyu and Narasimhan, Karthik and Griffiths, Thomas L. , doi =. Cognitive
-
[47]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , doi =
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , title =
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , doi =. Proceedings of the AAAI Conference on Artificial Intelligence , title =
-
[49]
Distilling
Gallego, Victor , doi =. Distilling
-
[50]
Externalization in
Zhou, Chenyu and Chai, Huacan and Chen, Wenteng and Guo, Zihan and Shan, Rong and Song, Yuanyi and Xu, Tianyi and Yang, Yingxuan and Yu, Aofan and Zhang, Weiming and Zheng, Congming and Zhu, Jiachen and Zheng, Zeyu and Zhang, Zhuosheng and Lou, Xingyu and Zhang, Changwang and Fu, Zhihui and Wang, Jun and Liu, Weiwen and Lin, Jianghao and Zhang, Weinan , d...
-
[51]
and Qin, Yujia and Liu, Zhiyuan and Ji, Heng , doi =
Qian, Cheng and Han, Chi and Fung, Yi R. and Qin, Yujia and Liu, Zhiyuan and Ji, Heng , doi =. Findings of the Association for Computational Linguistics: EMNLP 2023 , title =
2023
-
[52]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , doi =
-
[53]
Zhou, Yongchao and Muresanu, Andrei Ioan and Han, Ziwen and Paster, Keiran and Pitis, Silviu and Chan, Harris and Ba, Jimmy , doi =. Large
-
[54]
and Zhou, Denny and Chen, Xinyun , doi =
Yang, Chengrun and Wang, Xuezhi and Lu, Yifeng and Liu, Hanxiao and Le, Quoc V. and Zhou, Denny and Chen, Xinyun , doi =. Large
-
[55]
Fernando, Chrisantha and Banarse, Dylan and Michalewski, Henryk and Osindero, Simon and Rocktaschel, Tim , doi =
-
[56]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , title =
Pryzant, Reid and Iter, Dan and Li, Jerry and Lee, Yin Tat and Zhu, Chenguang and Zeng, Michael , doi =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , title =
2023
-
[57]
and Hu, Zhiting , doi =
Wang, Xinyuan and Li, Chenxi and Wang, Zhen and Bai, Fan and Luo, Haotian and Zhang, Jiayou and Jojic, Nebojsa and Xing, Eric P. and Hu, Zhiting , doi =
-
[58]
and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , doi =
-
[59]
Advances in Neural Information Processing Systems 36 , title =
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , doi =. Advances in Neural Information Processing Systems 36 , title =
-
[60]
and Mordatch, Igor , doi =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , doi =. Improving
-
[61]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , title =
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , doi =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , title =
-
[62]
and Burger, Doug and Wang, Chi , doi =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , doi =
-
[63]
and Cao, Yuan and Narasimhan, Karthik , doi =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , doi =. Advances in Neural Information Processing Systems 36 , title =
-
[64]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , title =
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , doi =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , title =
2023
-
[65]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , doi =
-
[66]
Mialon, Gregoire and Fourrier, Clementine and Swift, Craig and Wolf, Thomas and LeCun, Yann and Scialom, Thomas , doi =
-
[67]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , doi =
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , doi =
-
[68]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , doi =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , doi =. Advances in Neural Information Processing Systems 37 , title =
-
[69]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , doi =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , doi =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.