ResMerge: Residual-based Spectral Merging of Large Language Models
Pith reviewed 2026-06-28 15:01 UTC · model grok-4.3
The pith
For RL task vectors, residual components provide a stable merging basis while leading heads require careful gated reintroduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
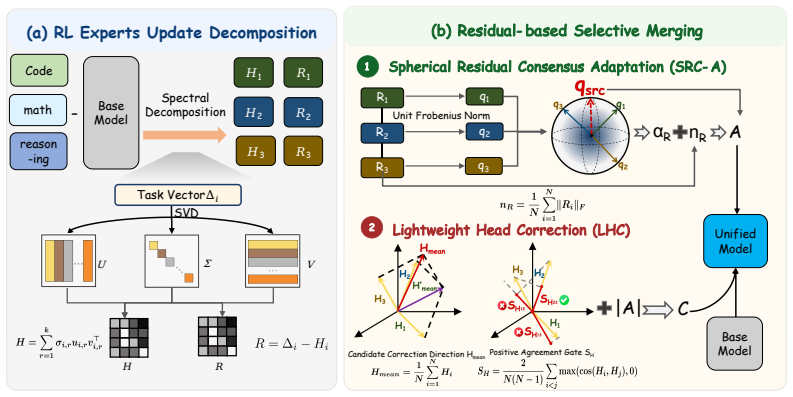
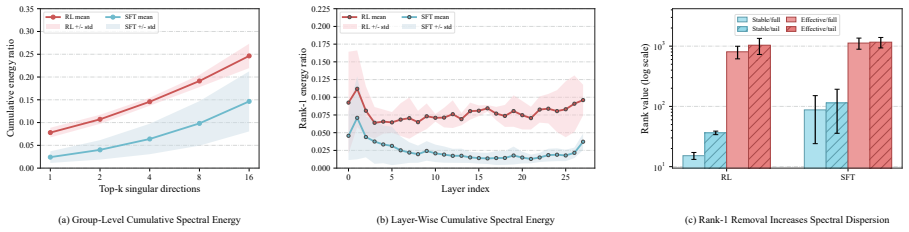
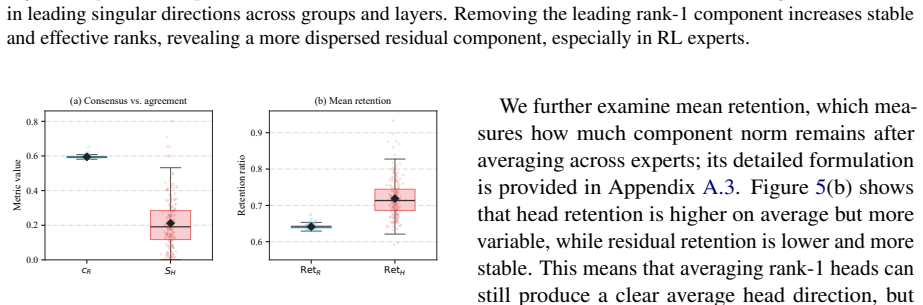
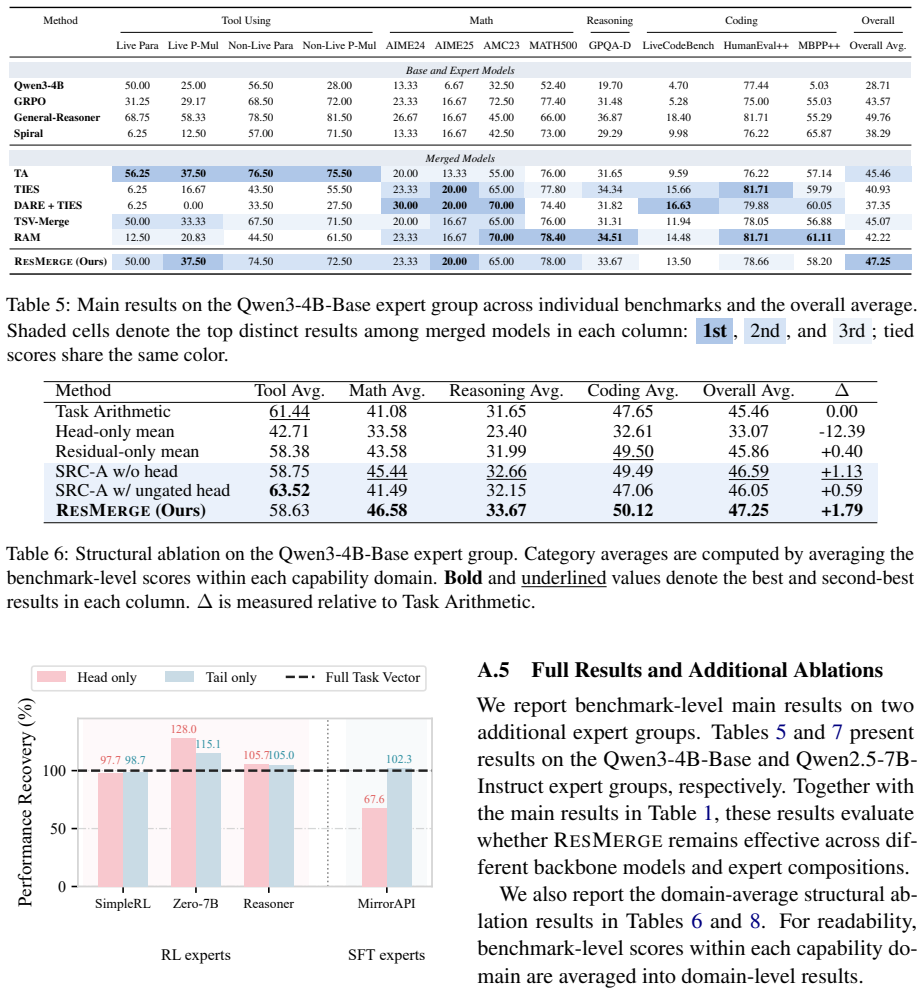
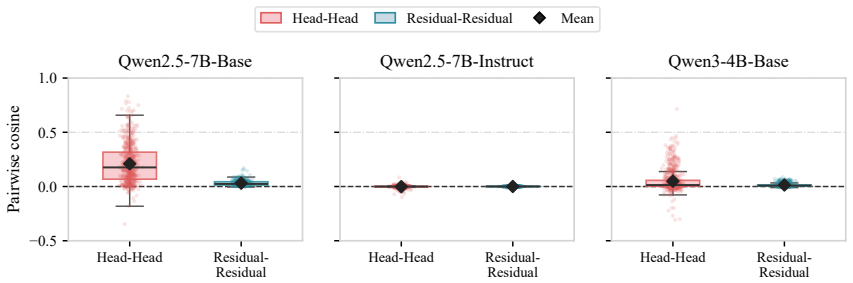
Decomposing RL task vectors via SVD reveals that both the leading spectral head and the residual independently recover substantial behavior knowledge, yet the head tends toward sharp cross-expert conflicts while the residual offers a dispersed and stable aggregation basis; ResMerge therefore constructs a stable residual backbone via Spherical Residual Consensus Adaptation and reintroduces leading-head information through a Lightweight Head Correction module gated by positive cross-expert agreement.
What carries the argument
Spherical Residual Consensus Adaptation for building the residual backbone and Lightweight Head Correction for gated head reintroduction.
If this is right
- Merged models better preserve capabilities of individual RL experts.
- Reduced impact of cross-expert conflicts in leading spectral directions.
- Improved performance across multiple capability domains and expert groups.
- Task vectors can be merged without assuming leading directions contain the main signal.
Where Pith is reading between the lines
- Similar spectral properties might appear in other fine-tuning regimes, suggesting broader use of residual merging.
- The method could be combined with other merging strategies to handle larger sets of experts.
- Testing on models with different sizes or training objectives would check the generality of the head-residual distinction.
Load-bearing premise
The residual components of RL task vectors remain more stable for aggregation across different experts than their leading singular heads.
What would settle it
A test showing that direct merging of leading heads without residuals or corrections achieves higher capability preservation than ResMerge on the same RL expert sets.
Figures

read the original abstract
Model merging offers a training-free way to combine multiple post-trained expert models, but merging experts obtained through reinforcement learning (RL) remains challenging. Existing spectral merging methods often assume that leading singular directions contain the main task signal, while lower-energy residual components can be compressed, selected, or attenuated to reduce interference. We find that this assumption does not hold for RL task vectors: after decomposing each task vector into a leading spectral head and a residual component, both parts can independently recover substantial behavior knowledge, while exhibiting different merging properties. The head is highly concentrated and informative but more prone to sharp cross-expert conflicts, whereas the residual component is more dispersed and provides a more stable basis for aggregation. Based on this observation, we propose ResMerge, a residual-based spectral merging framework for RL experts. ResMerge first constructs a stable residual backbone with Spherical Residual Consensus Adaptation, which estimates a reliability-weighted consensus direction on the Frobenius sphere. It then reintroduces leading-head information through a Lightweight Head Correction module gated by positive cross-expert agreement. Experiments across multiple RL expert groups and capability domains show that ResMerge better preserves expert capabilities than representative task-vector and spectral merging baselines. The implementation of ResMerge is publicly available at https://github.com/sunyd0303-cpu/ResMerge-release.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard spectral merging assumptions fail for RL task vectors in LLMs: after SVD decomposition, the leading spectral head recovers substantial behavior but is prone to sharp cross-expert conflicts, while the residual component is more dispersed and stable for aggregation. Based on this, ResMerge constructs a residual backbone via Spherical Residual Consensus Adaptation (reliability-weighted consensus on the Frobenius sphere) and reintroduces head information via a Lightweight Head Correction module gated by positive cross-expert agreement. Experiments across multiple RL expert groups and capability domains reportedly show better preservation of expert capabilities than task-vector and spectral baselines, with code released publicly.
Significance. If the SVD-based observation on head/residual properties holds and generalizes, the work would challenge existing spectral merging practices and supply a practical, training-free method for combining RL experts. The public GitHub release is a clear strength supporting reproducibility.
major comments (2)
- [Observation / motivation section] The design of Spherical Residual Consensus Adaptation and Lightweight Head Correction is motivated directly by the claim that SVD of RL task vectors yields a conflict-prone leading head and a stable residual (both independently recovering substantial behavior). This premise is load-bearing; the manuscript must supply quantitative support such as per-component recovery accuracies, cross-expert conflict metrics, or dispersion statistics to justify why prior spectral assumptions are falsified here.
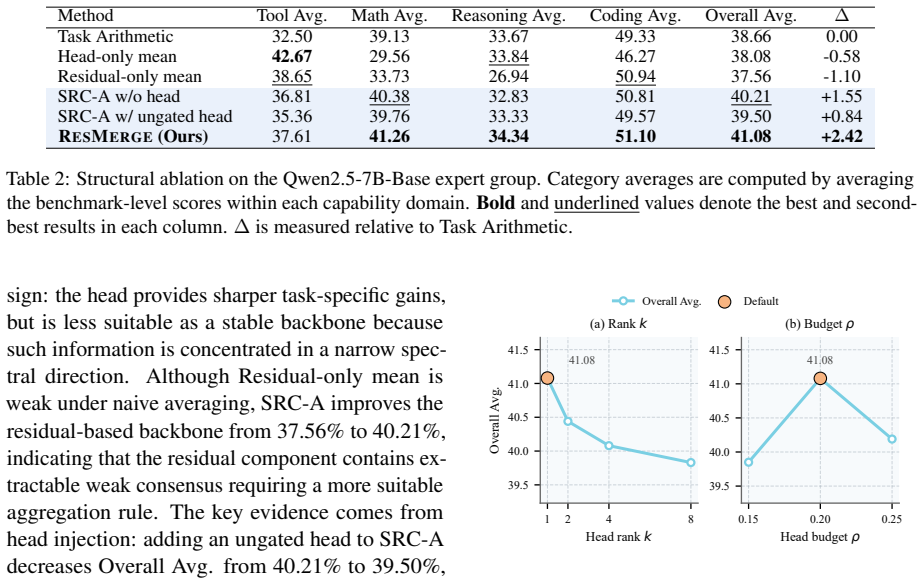
- [Experiments section] The superiority claim ('Experiments across multiple RL expert groups and capability domains show that ResMerge better preserves expert capabilities than representative task-vector and spectral merging baselines') is central yet unsupported by any reported numbers, model sizes, dataset descriptions, ablation results, or error bars in the available text. Without these, attribution of gains specifically to the residual-based approach versus implementation details cannot be assessed.
minor comments (2)
- [Abstract] Define all acronyms at first use (RL, SVD, etc.) and ensure consistent notation for 'task vector' versus 'RL task vector'.
- [Abstract] The GitHub link is a positive; confirm it contains the exact code and seeds used for the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger quantitative grounding in both the motivation and experimental sections. We will revise the manuscript to incorporate the requested analyses and details while preserving the core contributions.
read point-by-point responses
-
Referee: [Observation / motivation section] The design of Spherical Residual Consensus Adaptation and Lightweight Head Correction is motivated directly by the claim that SVD of RL task vectors yields a conflict-prone leading head and a stable residual (both independently recovering substantial behavior). This premise is load-bearing; the manuscript must supply quantitative support such as per-component recovery accuracies, cross-expert conflict metrics, or dispersion statistics to justify why prior spectral assumptions are falsified here.
Authors: We agree that the SVD-based observation requires explicit quantitative backing to justify departing from prior spectral merging assumptions. In the revision we will add a dedicated analysis subsection reporting: (i) per-component recovery accuracies on held-out evaluation tasks for the leading head versus residual separately, (ii) cross-expert conflict metrics (e.g., pairwise prediction disagreement rates), and (iii) dispersion statistics (singular-value spread and Frobenius-norm variance across experts). These additions will directly support the design choices of Spherical Residual Consensus Adaptation and the gated head correction. revision: yes
-
Referee: [Experiments section] The superiority claim ('Experiments across multiple RL expert groups and capability domains show that ResMerge better preserves expert capabilities than representative task-vector and spectral merging baselines') is central yet unsupported by any reported numbers, model sizes, dataset descriptions, ablation results, or error bars in the available text. Without these, attribution of gains specifically to the residual-based approach versus implementation details cannot be assessed.
Authors: We acknowledge that the submitted manuscript text does not contain the numerical results, model specifications, or ablations needed to substantiate the superiority claim. The revision will expand the experiments section with: full tables of performance metrics across all RL expert groups and domains, model sizes and architectures, dataset descriptions, ablation studies isolating each ResMerge component, and error bars from repeated runs. This will enable readers to evaluate the contribution of the residual backbone versus implementation choices. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical observation on SVD properties of RL task vectors (leading head vs. residual) as a premise that motivates the definition of new algorithmic modules (Spherical Residual Consensus Adaptation and Lightweight Head Correction). No equations, predictions, or first-principles results reduce to their own inputs by construction; the method is defined by independent procedural steps rather than fitted parameters or self-referential renaming. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing justification in the abstract or described structure. The central claims rest on experimental comparisons rather than tautological constructions, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Task vectors admit an SVD decomposition separating a leading spectral head from a residual component
invented entities (2)
-
Spherical Residual Consensus Adaptation
no independent evidence
-
Lightweight Head Correction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.07974 , doi =
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author =. arXiv preprint arXiv:2403.07974 , doi =
-
[2]
arXiv preprint arXiv:2107.03374 , doi =
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , doi =
-
[3]
arXiv preprint arXiv:2108.07732 , doi =
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , doi =
-
[4]
Advances in Neural Information Processing Systems , doi =
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation , author =. Advances in Neural Information Processing Systems , doi =
-
[5]
arXiv preprint arXiv:2311.12022 , doi =
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author =. arXiv preprint arXiv:2311.12022 , doi =
-
[6]
Advances in Neural Information Processing Systems Datasets and Benchmarks Track , doi =
Measuring Mathematical Problem Solving With the MATH Dataset , author =. Advances in Neural Information Processing Systems Datasets and Benchmarks Track , doi =
-
[7]
arXiv preprint arXiv:2305.20050 , doi =
Let's Verify Step by Step , author =. arXiv preprint arXiv:2305.20050 , doi =
-
[8]
Proceedings of the 42nd International Conference on Machine Learning , pages =
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[9]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
2018
-
[10]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages =
SQuAD: 100,000+ Questions for Machine Comprehension of Text , author =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages =
2016
-
[11]
Proceedings of the 11th International Conference on Learning Representations , doi =
Editing Models with Task Arithmetic , author =. Proceedings of the 11th International Conference on Learning Representations , doi =
-
[12]
Advances in Neural Information Processing Systems , doi =
TIES-Merging: Resolving Interference When Merging Models , author =. Advances in Neural Information Processing Systems , doi =
-
[13]
arXiv preprint arXiv:2311.03099 , doi =
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author =. arXiv preprint arXiv:2311.03099 , doi =
-
[14]
arXiv preprint arXiv:2412.00081 , doi =
Task Singular Vectors: Reducing Task Interference in Model Merging , author =. arXiv preprint arXiv:2412.00081 , doi =
-
[15]
arXiv preprint arXiv:2502.04959 , doi =
No Task Left Behind: Isotropic Model Merging with Common and Task-Specific Subspaces , author =. arXiv preprint arXiv:2502.04959 , doi =
-
[16]
arXiv preprint arXiv:2601.13572 , doi =
Behavior Knowledge Merge in Reinforced Agentic Models , author =. arXiv preprint arXiv:2601.13572 , doi =
-
[17]
Advances in Neural Information Processing Systems , doi =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , doi =
-
[18]
Nature , volume =
DeepSeek-R1 Incentivizes Reasoning in LLMs through Reinforcement Learning , author =. Nature , volume =. 2025 , doi =
2025
-
[19]
Proceedings of the 39th International Conference on Machine Learning , series =
Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy Without Increasing Inference Time , author =. Proceedings of the 39th International Conference on Machine Learning , series =
-
[20]
STAR: Spectral Truncation and Rescale for Model Merging , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =. doi:10.18653/v1/2025.naacl-short.42 , url =
-
[21]
arXiv preprint arXiv:2503.22178 , doi =
AdaRank: Adaptive Rank Pruning for Enhanced Model Merging , author =. arXiv preprint arXiv:2503.22178 , doi =
-
[22]
When Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging
When Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging , author =. arXiv preprint arXiv:2602.05536 , note =. doi:10.48550/arXiv.2602.05536 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.05536
-
[23]
Advances in Neural Information Processing Systems , doi =
Rewarded Soups: Towards Pareto-Optimal Alignment by Interpolating Weights Fine-Tuned on Diverse Rewards , author =. Advances in Neural Information Processing Systems , doi =
-
[24]
2024 , eprint =
WARP: On the Benefits of Weight Averaged Rewarded Policies , author =. 2024 , eprint =
2024
-
[25]
arXiv preprint arXiv:2411.01798 , doi =
SALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF , author =. arXiv preprint arXiv:2411.01798 , doi =
-
[26]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Mitigating the Alignment Tax of RLHF , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
2024
-
[27]
arXiv preprint arXiv:2412.15115 , doi =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , doi =
-
[28]
arXiv preprint arXiv:2503.18892 , doi =
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild , author =. arXiv preprint arXiv:2503.18892 , doi =
-
[29]
arXiv preprint arXiv:2503.24290 , doi =
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , author =. arXiv preprint arXiv:2503.24290 , doi =
-
[30]
arXiv preprint arXiv:2505.14652 , doi =
General-Reasoner: Advancing LLM Reasoning Across All Domains , author =. arXiv preprint arXiv:2505.14652 , doi =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.