A Grounded Evidence-Retrieval Benchmark and Hybrid RAG Framework for Silicon Pixel Detector R&D
Pith reviewed 2026-06-25 21:55 UTC · model grok-4.3
The pith
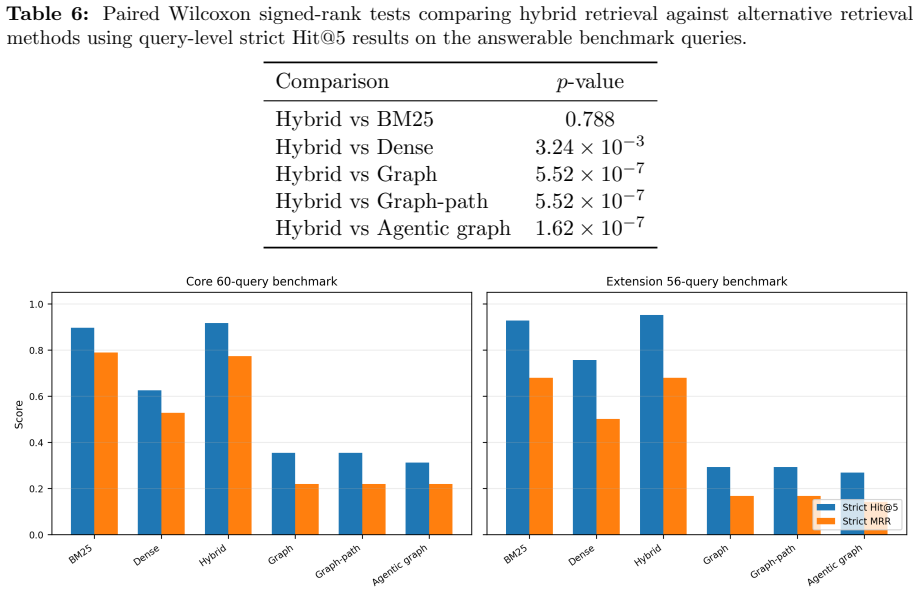
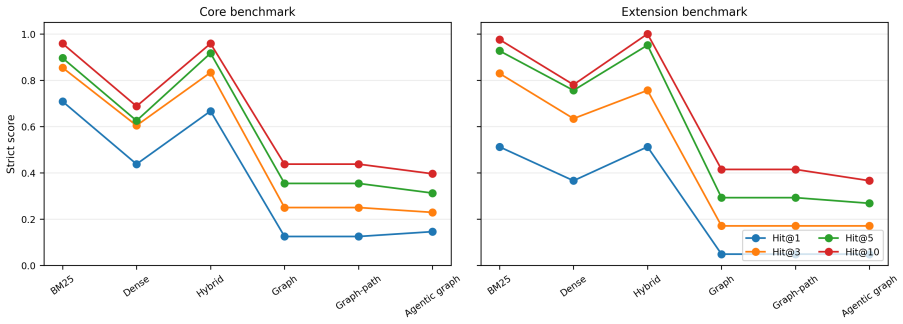
Hybrid sparse-dense retrieval recovers evidence most reliably from silicon pixel detector literature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A new evidence-grounded retrieval benchmark with chunk-level annotations, source diagnostics, semantic checks, and abstention tests shows that hybrid sparse-dense retrieval delivers the most reliable evidence recovery across detector-domain queries, whereas graph-based methods perform better for literature exploration than for strict evidence ranking.
What carries the argument
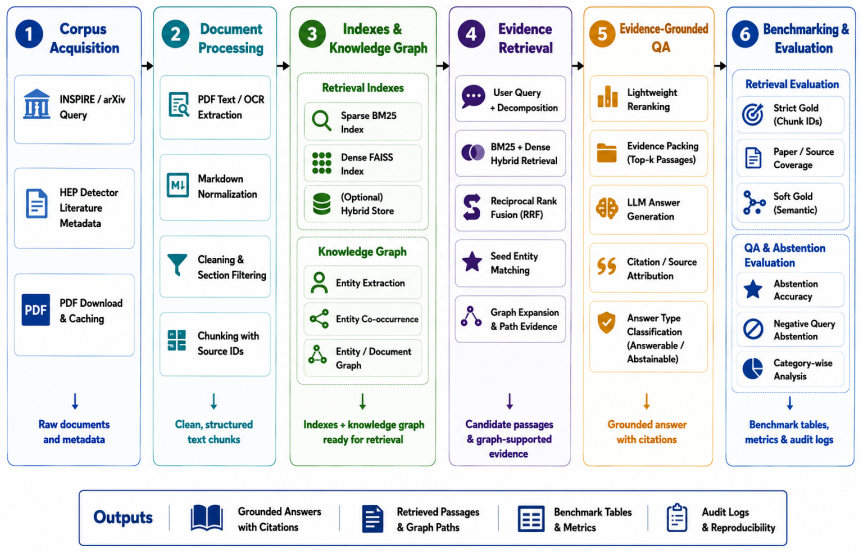
The evidence-grounded retrieval benchmark, consisting of manually curated chunk-level evidence annotations together with source-level diagnostics and negative-query tests on two complementary detector query sets.
If this is right
- Hybrid retrieval should be the default choice for evidence-grounding tasks in silicon pixel detector R&D.
- Graph-based tools should be reserved for tasks focused on mapping connections across the literature rather than ranking specific evidence.
- The benchmark supplies a reusable testbed for comparing future retrieval methods in specialized instrumentation domains.
- Retrieval-augmented systems for high-energy physics can now be built and evaluated against explicit evidence standards.
Where Pith is reading between the lines
- The same annotation and evaluation approach could be adapted to other instrumentation subfields such as calorimeter or tracking detector literature.
- Combining the hybrid retriever with existing detector simulation codes might allow direct checks of whether retrieved evidence supports new design choices.
- Extending the benchmark to include time-stamped queries could test how well methods surface the most recent experimental results.
Load-bearing premise
The manually curated chunk-level evidence annotations and source-level diagnostics accurately represent ground truth for the two detector-domain query sets.
What would settle it
A follow-up study that re-annotates the same queries with independent experts and finds that graph-based methods recover more of the key evidence chunks than hybrid retrieval would falsify the central claim.
Figures
read the original abstract
The rapid growth of silicon pixel detector literature has made systematic evidence retrieval a practical bottleneck for detector R&D. Large language models alone are insufficient for this task, as specialised detector knowledge, long-tail technical details, and recent experimental results must be grounded in primary literature. We present the first evidence-grounded retrieval benchmark and a reproducible retrieval framework for silicon pixel detector studies, combining sparse lexical retrieval, dense semantic retrieval, hybrid retrieval, and graph-based literature exploration. The benchmark includes manually curated chunk-level evidence annotations, source-level diagnostics, semantic relevance checks, and negative-query abstention tests across two complementary detector-domain query sets. Systematic evaluation shows that hybrid sparse-dense retrieval provides the most reliable evidence recovery, while graph-based approaches are more effective for literature exploration than strict evidence ranking. These results highlight the importance of evidence-grounded retrieval for accessing long-tail detector knowledge and provide a practical foundation for retrieval-augmented tools supporting silicon detector research and high-energy physics instrumentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first evidence-grounded retrieval benchmark for silicon pixel detector R&D literature, including manually curated chunk-level evidence annotations, source-level diagnostics, semantic relevance checks, and negative-query tests across two detector-domain query sets. It evaluates a hybrid RAG framework combining sparse lexical, dense semantic, hybrid, and graph-based retrieval, with systematic evaluation showing hybrid sparse-dense retrieval as most reliable for evidence recovery and graph-based methods better for literature exploration.
Significance. If the benchmark annotations prove robust, the work could establish a practical foundation for retrieval-augmented systems in high-energy physics instrumentation, helping address access to long-tail technical details in a growing specialized literature.
major comments (1)
- [Abstract] Abstract: the central claim that hybrid sparse-dense retrieval provides the most reliable evidence recovery depends on the manually curated chunk-level evidence annotations serving as accurate ground truth, yet the abstract supplies no information on curation protocol, annotator count or expertise, inter-annotator agreement, or conflict resolution. This omission is load-bearing because systematic biases in the annotations (e.g., favoring semantic over lexical matches) could artifactually favor the hybrid method over graph-based ranking.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding the evidence annotations. We address this point directly below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that hybrid sparse-dense retrieval provides the most reliable evidence recovery depends on the manually curated chunk-level evidence annotations serving as accurate ground truth, yet the abstract supplies no information on curation protocol, annotator count or expertise, inter-annotator agreement, or conflict resolution. This omission is load-bearing because systematic biases in the annotations (e.g., favoring semantic over lexical matches) could artifactually favor the hybrid method over graph-based ranking.
Authors: We agree that the abstract should provide a concise summary of the annotation process to support the central claim. The full manuscript (Section 3.2) details the curation protocol, which was performed by two domain experts in silicon pixel detector instrumentation. Inter-annotator agreement was quantified and conflicts resolved through discussion. We will revise the abstract to include a brief statement on the curation protocol, annotator expertise, and agreement metric. On the potential for bias, the annotations consist of explicit chunk-level evidence spans tied directly to query requirements rather than retrieval-method preferences; the benchmark further incorporates source-level diagnostics, semantic relevance checks, and negative-query abstention tests to validate robustness across retrieval paradigms. These safeguards make systematic favoritism toward hybrid retrieval unlikely. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with independent annotations
full rationale
The paper contains no equations, derivations, fitted parameters, or self-citations that reduce claims to inputs by construction. The central evaluation compares retrieval methods against manually curated chunk-level annotations presented as ground truth; these annotations are external inputs to the benchmark rather than outputs derived from the tested methods. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear. This is the standard non-circular structure of an empirical retrieval benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
W. Snoeys. CMOS monolithic active pixel sensors for high energy physics.Nuclear Instruments and Methods in Physics Research Section A, 765:167–171, 2014. doi: 10.1016/j. nima.2014.05.070
work page doi:10.1016/j 2014
-
[3]
Pernegger et al
H. Pernegger et al. First tests of a novel radiation hard CMOS sensor process for depleted monolithic active pixel sensors.Journal of Instrumentation, 12:P06008, 2017. doi: 10.1088/ 1748-0221/12/06/P06008
2017
-
[4]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12): 1–38, 2023
2023
-
[5]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K¨ uttler, M. Lewis, W.-t. Yih, T. Rockt¨ aschel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[6]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2023
Pith/arXiv arXiv 2023
-
[7]
A. Mallen, A. Asai, V. Zhong, R. Das, D. Khashabi, and H. Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802–9822, 2023. doi: 10.18653/v1/2023.acl-long.546
-
[8]
Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks
N. Reimers and I. Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992, 2019. doi: 10.18653/v1/D19-1410
-
[9]
Dense Passage Retrieval for Open-Domain Question Answering
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, 2020. doi: 10.18653/v1/2020.emnlp-main.550. 20
-
[10]
Thakur, N
N. Thakur, N. Reimers, A. R¨ uckl´ e, A. Srivastava, and I. Gurevych. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. InAdvances in Neural Information Processing Systems: Datasets and Benchmarks, 2021
2021
-
[11]
The Probabilistic Relevance Framework: BM25 and Beyond,
S. Robertson and H. Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009. doi: 10.1561/1500000019
-
[12]
C. D. Manning, P. Raghavan, and H. Sch¨ utze.Introduction to Information Retrieval. Cambridge University Press, Cambridge, 2008. doi: 10.1017/CBO9780511809071
-
[13]
G. V. Cormack, C. L. A. Clarke, and S. Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759, 2009. doi: 10.1145/1571941.1572114
- [14]
-
[15]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[16]
Z. Guo, L. Xia, Y. Yu, T. Ao, and C. Huang. LightRAG: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2024
Pith/arXiv arXiv 2024
-
[17]
M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec. QA-GNN: Reasoning with language models and knowledge graphs for question answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, pages 535–546, 2021. doi: 10.18653/v1/2021.naacl-main.45
-
[18]
Xiong, X
W. Xiong, X. L. Li, S. Iyer, J. Du, P. Lewis, W. Y. Wang, Y. Mehdad, W.-t. Yih, S. Riedel, D. Kiela, and B. Oguz. Answering complex open-domain questions with multi-hop dense retrieval. InInternational Conference on Learning Representations, 2021
2021
-
[19]
G. Izacard and E. Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, pages 874–880, 2021. doi: 10.18653/v1/ 2021.eacl-main.74
-
[20]
Jiang, D
R. Jiang, D. Fu, C. Jiang, T. Yang, Z. Wang, Y. Wu, Y. Ban, Y. Mao, and Q. Li. Agentic Hybrid RAG for Evidence-Grounded Muon Collider Analysis. 6 2026
2026
-
[21]
O. Khattab and M. Zaharia. ColBERT: Efficient and effective passage search via contextu- alized late interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 39–48, 2020. doi: 10.1145/3397271.3401075
-
[22]
D. Wadden, S. Lin, K. Lo, L. L. Wang, M. van Zuylen, A. Cohan, and H. Hajishirzi. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 7534–7550, 2020. doi: 10.18653/v1/2020. emnlp-main.609
-
[23]
SPECTER : Document-level Representation Learning using Citation-informed Transformers
A. Cohan, S. Feldman, I. Beltagy, D. Downey, and D. S. Weld. SPECTER: Document-level representation learning using citation-informed transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2270–2282, 2020. doi: 10.18653/v1/2020.acl-main.207. 21
-
[24]
Tsatsaronis et al
G. Tsatsaronis et al. An overview of the BioASQ large-scale biomedical semantic indexing and question answering competition.BMC Bioinformatics, 16:138, 2015. doi: 10.1186/ s12859-015-0564-6
2015
-
[25]
P. Lopez. GROBID: Combining automatic bibliographic data recognition and term extraction for scholarship publications. InResearch and Advanced Technology for Digital Libraries, pages 473–474, 2009. doi: 10.1007/978-3-642-04346-8 62
-
[26]
Billion-Scale Similarity Search with GPUs ,
J. Johnson, M. Douze, and H. J´ egou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021. doi: 10.1109/TBDATA.2019.2921572
-
[27]
M. Mager. ALPIDE, the monolithic active pixel sensor for the ALICE ITS upgrade. Nuclear Instruments and Methods in Physics Research Section A, 824:434–438, 2016. doi: 10.1016/j.nima.2015.09.057
-
[28]
Poikela, J
T. Poikela, J. Plosila, T. Westerlund, M. Campbell, M. De Gaspari, X. Llopart, V. Gromov, R. Kluit, M. van Beuzekom, F. Zappon, et al. Timepix3: A 65k channel hybrid pixel readout chip with simultaneous ToA/ToT and sparse readout.Journal of Instrumentation, 9:C05013,
-
[29]
doi: 10.1088/1748-0221/9/05/C05013
-
[30]
S. Spannagel et al. Allpix squared: A modular simulation framework for silicon detectors. Nuclear Instruments and Methods in Physics Research Section A, 901:164–172, 2018. doi: 10.1016/j.nima.2018.06.020
-
[31]
S. Agostinelli et al. GEANT4: A simulation toolkit.Nuclear Instruments and Methods in Physics Research Section A, 506(3):250–303, 2003. doi: 10.1016/S0168-9002(03)01368-8. Appendix A Grounding and Abstention Prompt The grounded generation component receives the user query together with the retrieved evidence passages and associated source metadata. The mo...
-
[32]
Do not use external knowledge
-
[33]
Cite supporting passages when answering
-
[34]
If the evidence is insufficient, return ABSTAIN
-
[35]
Time resolution of irradiated LGAD sensors
Do not infer detector performance beyond what is explicitly stated. Question: {query} Retrieved Evidence: 22 {retrieved_chunks} Answer: For negative-query evaluation, the model is expected to return the predefined token ABSTAIN when no retrieved passage directly supports the queried detector-domain claim. B Retrieval Metrics The primary evaluation metrics...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.