BashCoder-R1: Towards Robust and Explainable Bash Code Generation with Robustness-Aware Group Relative Policy Optimization
Pith reviewed 2026-06-29 04:11 UTC · model grok-4.3
The pith
BashCoder-R1 reaches 90 percent full success on single-line Bash tasks and 73 percent on multi-line by combining pre-training, reasoning fine-tuning, and robustness-focused reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
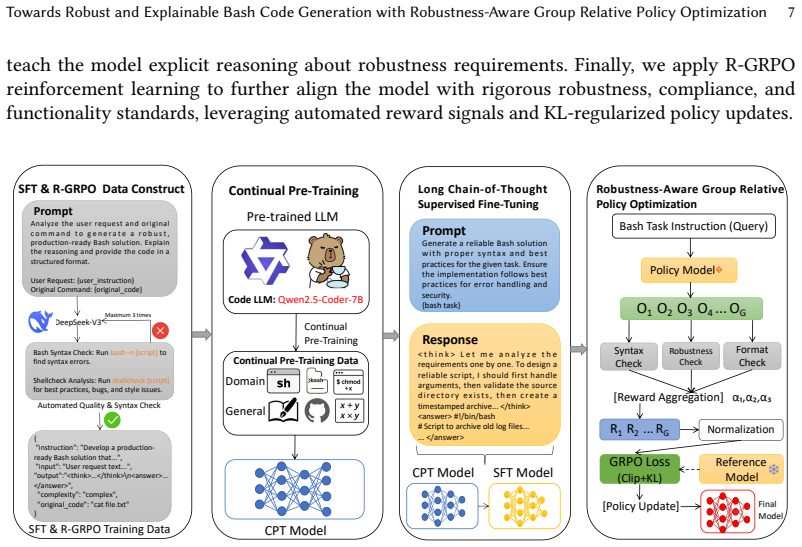
BashCoder-R1 combines continual pre-training on Bash paradigms, long chain-of-thought supervised fine-tuning on expert-validated reasoning-and-code samples, and Robustness-Aware Group Relative Policy Optimization that optimizes a weighted reward for syntax correctness, robustness measured by shellcheck, and format correctness, yielding SyntaxPass of 100.00 percent and 94.97 percent, RobustPass of 95.99 percent and 79.33 percent, and FullRate of 90.04 percent and 73.18 percent on single-line and multi-line tasks.
What carries the argument
Robustness-Aware Group Relative Policy Optimization (R-GRPO), a reinforcement learning phase that optimizes a weighted reward combining syntax correctness, robustness via shellcheck, and format correctness.
If this is right
- BashCoder-R1 achieves SyntaxPass of 100.00 percent and 94.97 percent, RobustPass of 95.99 percent and 79.33 percent, and FullRate of 90.04 percent and 73.18 percent on single-line and multi-line tasks.
- BashCoder-R1 outperforms the strongest baseline DeepSeek-V3.2 (Reasoning) by 37.82 percent and 20.18 percent in FullRate on single-line and multi-line tasks.
- Human evaluation rates BashCoder-R1 highest on Functionality, Robustness, and Clarity compared with baselines.
Where Pith is reading between the lines
- The same staged pipeline could be applied to code generation in other scripting languages that share similar syntax and security concerns.
- Adoption in DevOps tooling could reduce the frequency of script-induced system failures during automated administration.
- The long reasoning chains produced during fine-tuning could be studied separately to test whether they help human operators audit or debug generated scripts more quickly.
Load-bearing premise
The new BashBench tasks and the shellcheck-based robustness metrics accurately reflect real-world robustness and that no data leakage or benchmark-specific overfitting occurred during training or evaluation.
What would settle it
Running BashCoder-R1 generated scripts inside multiple production server environments and measuring whether the rate of robustness failures matches or exceeds the rates seen with the strongest baseline model.
Figures


read the original abstract
Bash scripts are the cornerstone of system administration and DevOps automation, where code quality directly impacts system stability and security. In automated Bash script generation using Large Language Models (LLMs), two interconnected failures emerge: unauditable "black box" reasoning and critical robustness vulnerabilities in generated code. To address both, we propose BashCoder-R1, a novel framework for robust and explainable Bash script generation. Our pipeline combines: (1) Continual Pre-training (CPT) to specialize the model on Bash paradigms; (2) Long Chain-of-Thought Supervised Fine-Tuning (L-CoT SFT) on expert-validated reasoning-and-code samples to emulate proactive risk-aware thinking; and (3) Robustness-Aware Group Relative Policy Optimization (R-GRPO), a reinforcement learning phase optimizing a weighted reward for syntax correctness, robustness (via shellcheck), and format correctness. We evaluate on BashBench, a new benchmark of 952 real-world tasks (773 single-line, 179 multi-line). BashCoder-R1 achieves SyntaxPass (100.00%/94.97%), RobustWarnRate (4.01%/16.47%), RobustPass (95.99%/79.33%), FuncRate (93.01%/93.85%), and FullRate (90.04%/73.18%) for single-line/multi-line tasks, outperforming the strongest baseline DeepSeek-V3.2 (Reasoning) by 37.82% and 20.18% in FullRate. Human evaluation on Functionality, Robustness, and Clarity further confirms BashCoder-R1 achieves the highest quality ratings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BashCoder-R1, a three-stage pipeline (continual pre-training on Bash paradigms, long chain-of-thought supervised fine-tuning on expert reasoning-and-code samples, and robustness-aware group relative policy optimization with weighted rewards for syntax, shellcheck robustness, and format) for generating explainable and robust Bash scripts. It introduces the new BashBench benchmark of 952 tasks (773 single-line, 179 multi-line) and reports large gains over baselines such as DeepSeek-V3.2 (Reasoning), including FullRate improvements of 37.82% and 20.18%, with supporting human evaluations on functionality, robustness, and clarity.
Significance. If the benchmark proves free of leakage and the experimental controls are adequate, the multi-stage specialization-plus-RL approach could offer a practical template for improving robustness in LLM-generated shell scripts, an area with direct implications for DevOps reliability. The explicit use of shellcheck in both reward and evaluation is a concrete design choice that merits scrutiny, but the absence of benchmark provenance and decontamination details prevents a clear assessment of whether the headline gains reflect genuine generalization.
major comments (3)
- [BashBench benchmark description] BashBench benchmark (evaluation section introducing the 952-task suite): The paper presents BashBench as a collection of real-world tasks but provides no description of task sourcing, collection process, validation methodology, train/test partitioning, or any decontamination procedure (e.g., n-gram overlap or embedding similarity checks) against the CPT and SFT corpora. Because the training pipeline ingests substantial Bash data, the reported SyntaxPass, RobustPass, and FullRate figures cannot be interpreted as evidence of generalization without this information.
- [R-GRPO and evaluation metrics] Robustness metrics and reward design (R-GRPO section and evaluation): RobustWarnRate and RobustPass are computed via shellcheck, the same tool used to generate the robustness component of the R-GRPO reward. This creates a direct dependence between the training objective and the reported evaluation metrics; the manuscript must clarify whether evaluation employs identical or independent shellcheck invocations and whether any held-out validation set was used.
- [Experimental setup and results] Experimental controls and statistical reporting (results and experimental setup): The abstract and results tables present point estimates (e.g., 90.04%/73.18% FullRate, 37.82%/20.18% gains) with no information on baseline training details, number of runs, variance, statistical significance tests, or how the 952-task benchmark was constructed and validated. These omissions are load-bearing for any claim of outperformance.
minor comments (1)
- [Abstract] The abstract introduces metric names (SyntaxPass, FuncRate, FullRate) without definitions or references to their precise computation; these should be defined on first use or cross-referenced to a methods subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional transparency will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested information and clarifications.
read point-by-point responses
-
Referee: [BashBench benchmark description] BashBench benchmark (evaluation section introducing the 952-task suite): The paper presents BashBench as a collection of real-world tasks but provides no description of task sourcing, collection process, validation methodology, train/test partitioning, or any decontamination procedure (e.g., n-gram overlap or embedding similarity checks) against the CPT and SFT corpora. Because the training pipeline ingests substantial Bash data, the reported SyntaxPass, RobustPass, and FullRate figures cannot be interpreted as evidence of generalization without this information.
Authors: We agree that the current version of the manuscript omits critical details on BashBench construction. In the revised manuscript we will add a dedicated subsection that describes: (1) sourcing of the 952 tasks from public DevOps repositories, Stack Overflow threads, and system administration forums; (2) the curation and filtering pipeline; (3) expert validation for task correctness and diversity; (4) the explicit train/test partitioning (with the 952 tasks held completely out of CPT and SFT data); and (5) decontamination steps consisting of both 13-gram overlap checks and embedding-based similarity filtering against the CPT and L-CoT SFT corpora. These additions will enable readers to assess generalization. revision: yes
-
Referee: [R-GRPO and evaluation metrics] Robustness metrics and reward design (R-GRPO section and evaluation): RobustWarnRate and RobustPass are computed via shellcheck, the same tool used to generate the robustness component of the R-GRPO reward. This creates a direct dependence between the training objective and the reported evaluation metrics; the manuscript must clarify whether evaluation employs identical or independent shellcheck invocations and whether any held-out validation set was used.
Authors: We will revise the R-GRPO and Evaluation sections to state explicitly that the identical shellcheck tool and rule set are used for both the reward signal and the reported metrics; this is by design so that the evaluation directly measures the effect of the robustness component of the reward. All metric computations are performed on the held-out BashBench test set, which was never seen during CPT, L-CoT SFT, or R-GRPO training. The shellcheck invocations for evaluation are separate runs executed after training completes. No held-out validation split was used for hyper-parameter selection during RL; BashBench functions solely as the final out-of-distribution test. revision: yes
-
Referee: [Experimental setup and results] Experimental controls and statistical reporting (results and experimental setup): The abstract and results tables present point estimates (e.g., 90.04%/73.18% FullRate, 37.82%/20.18% gains) with no information on baseline training details, number of runs, variance, statistical significance tests, or how the 952-task benchmark was constructed and validated. These omissions are load-bearing for any claim of outperformance.
Authors: We acknowledge that the experimental reporting is currently insufficient. In the revision we will expand the Experimental Setup section with: (a) precise prompting templates and training hyperparameters used for every baseline, including DeepSeek-V3.2 (Reasoning); (b) a statement that all numbers are from single runs with fixed random seeds for reproducibility; and (c) an explicit note that multiple independent runs were not performed owing to computational cost. We will also move the benchmark construction details (already addressed in response to the first comment) into the main experimental narrative and add a limitations paragraph discussing the lack of variance estimates and statistical tests. The benchmark validation methodology will be described as noted above. revision: partial
Circularity Check
No significant circularity in empirical pipeline or metrics
full rationale
The paper describes an empirical training pipeline (CPT + L-CoT SFT + R-GRPO with shellcheck rewards) and reports direct performance numbers on the introduced BashBench benchmark. No equations, derivations, or self-referential definitions appear that would reduce any claimed result to its inputs by construction. Performance figures are presented as measured outcomes rather than fitted quantities relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The evaluation is self-contained as standard RL optimization against explicitly defined rewards and metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Miltiadis Allamanis. 2019. The adverse effects of code duplication in machine learning models of code. InProceedings of the 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software. 143–153
2019
-
[2]
Anthropic. 2025. Introducing Claude Sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5
2025
-
[3]
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078(2014)
Pith/arXiv arXiv 2014
-
[4]
Stack Overflow Community. 2025. Newest ’bash’ Questions - Stack Overflow. https://stackoverflow.com/questions/ tagged/bash
2025
-
[5]
Stack Overflow Community. 2025. Newest ’shell’ Questions - Stack Overflow. https://stackoverflow.com/questions/ tagged/shell
2025
-
[6]
Yiwen Dong, Zheyang Li, Yongqiang Tian, Chengnian Sun, Michael W Godfrey, and Meiyappan Nagappan. 2023. Bash in the wild: Language usage, code smells, and bugs.ACM Transactions on Software Engineering and Methodology32, 1 (2023), 1–22
2023
-
[7]
Lishui Fan, Yu Zhang, Mouxiang Chen, and Zhongxin Liu. 2025. Posterior-GRPO: Rewarding Reasoning Processes in Code Generation.arXiv preprint arXiv:2508.05170(2025)
Pith/arXiv arXiv 2025
-
[8]
Quchen Fu, Zhongwei Teng, Marco Georgaklis, Jules White, and Douglas C Schmidt. 2023. Nl2cmd: An updated workflow for natural language to bash commands translation.arXiv preprint arXiv:2302.07845(2023)
arXiv 2023
-
[9]
Mingyang Geng, Shangwen Wang, Dezun Dong, Haotian Wang, Ge Li, Zhi Jin, Xiaoguang Mao, and Xiangke Liao
-
[10]
In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering
Large language models are few-shot summarizers: Multi-intent comment generation via in-context learning. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[12]
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor OK Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning.arXiv preprint arXiv:1603.06393(2016). , Vol. 1, No. 1, Article . Publication date: June 2024. 20 Yu et al
Pith/arXiv arXiv 2016
-
[13]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
Pith/arXiv arXiv 2024
-
[15]
Vidar Holen et al. 2012. ShellCheck: A shell script static analysis tool. (2012)
2012
-
[16]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. 2025. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749 (2025)
Pith/arXiv arXiv 2025
-
[17]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
Pith/arXiv arXiv 2024
-
[18]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han
-
[19]
arXiv preprint arXiv:2503.00223(2025)
Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning. arXiv preprint arXiv:2503.00223(2025)
arXiv 2025
-
[20]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han
-
[21]
Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516(2025)
Pith/arXiv arXiv 2025
-
[22]
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svy- atkovskiy, Shengyu Fu, et al. 2022. Automating code review activities by large-scale pre-training. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1035–1047
2022
-
[23]
Xi Victoria Lin, Chenglong Wang, Deric Pang, Kevin Vu, and Michael D Ernst. 2017. Program synthesis from natural language using recurrent neural networks.University of Washington Department of Computer Science and Engineering, Seattle, W A, USA, Tech. Rep. UW-CSE-17-031 (2017), 1–12
2017
-
[24]
Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D Ernst. 2018. NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System. InProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)
2018
-
[25]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
Pith/arXiv arXiv 2025
-
[26]
Fang Liu, Yang Liu, Lin Shi, Houkun Huang, Ruifeng Wang, Zhen Yang, Li Zhang, Zhongqi Li, and Yuchi Ma. 2024. Exploring and evaluating hallucinations in llm-powered code generation.arXiv preprint arXiv:2404.00971(2024)
arXiv 2024
-
[27]
Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, et al. 2025. Fin-r1: A large language model for financial reasoning through reinforcement learning.arXiv preprint arXiv:2503.16252(2025)
arXiv 2025
-
[28]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101(2017)
Pith/arXiv arXiv 2017
-
[29]
Junyi Lu, Lei Yu, Xiaojia Li, Li Yang, and Chun Zuo. 2023. Llama-reviewer: Advancing code review automation with large language models through parameter-efficient fine-tuning. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 647–658
2023
-
[30]
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. 2025. UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning.arXiv preprint arXiv:2503.21620(2025)
Pith/arXiv arXiv 2025
-
[31]
Run Luo, Lu Wang, Wanwei He, and Xiaobo Xia. 2025. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458(2025)
Pith/arXiv arXiv 2025
-
[32]
Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, and Jian Guo. 2025. Sql-r1: Training natural language to sql reasoning model by reinforcement learning.arXiv preprint arXiv:2504.08600(2025)
arXiv 2025
-
[33]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
2024
-
[34]
O’Reilly Media, Inc
Cameron Newham. 2005.Learning the bash shell: Unix shell programming. " O’Reilly Media, Inc. "
2005
-
[35]
Zhenyu Pan and Han Liu. 2025. Metaspatial: Reinforcing 3d spatial reasoning in vlms for the metaverse.arXiv preprint arXiv:2503.18470(2025)
arXiv 2025
-
[36]
Sameer Pimparkhede, Mehant Kammakomati, Srikanth Tamilselvam, Prince Kumar, Ashok Kumar, and Pushpak Bhattacharyya. 2024. DocCGen: Document-based Controlled Code Generation. InConference on Empirical Methods in Natural Language Processing. , Vol. 1, No. 1, Article . Publication date: June 2024. Towards Robust and Explainable Bash Code Generation with Robu...
2024
-
[37]
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thomas Back. 2024. Reasoning with large language models, a survey.arXiv preprint arXiv:2407.11511(2024)
arXiv 2024
-
[38]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3505–3506
2020
-
[39]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
Pith/arXiv arXiv 2023
-
[40]
Yiheng Shen, Xiaolin Ju, Xiang Chen, and Guang Yang. 2024. Bash comment generation via data augmentation and semantic-aware CodeBERT.Automated Software Engineering31, 1 (2024), 30
2024
-
[41]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems. 1279–1297
2025
-
[42]
André Storhaug, Jingyue Li, and Tianyuan Hu. 2023. Efficient avoidance of vulnerabilities in auto-completed smart contract code using vulnerability-constrained decoding. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 683–693
2023
-
[43]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks.Advances in neural information processing systems27 (2014)
2014
-
[44]
Qwen Team. 2025. QwQ-32B: Embracing the Power of Reinforcement Learning. https://qwenlm.github.io/blog/qwq- 32b/
2025
-
[45]
Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, and Yangqiu Song. 2024. Rethinking the bounds of llm reasoning: Are multi-agent discussions the key?arXiv preprint arXiv:2402.18272(2024)
arXiv 2024
-
[46]
Sijie Wang, Quanjiang Guo, Kai Zhao, Yawei Zhang, Xin Li, Xiang Li, Siqi Li, Rui She, Shangshu Yu, and Wee Peng Tay. 2025. CodeBoost: Boosting Code LLMs by Squeezing Knowledge from Code Snippets with RL.arXiv preprint arXiv:2508.05242(2025)
arXiv 2025
-
[47]
Zengzhi Wang, Fan Zhou, Xuefeng Li, and Pengfei Liu. 2025. Octothinker: Mid-training incentivizes reinforcement learning scaling.arXiv preprint arXiv:2506.20512(2025)
arXiv 2025
-
[48]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[49]
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I Wang. 2025. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449(2025)
Pith/arXiv arXiv 2025
-
[50]
Jiaer Xia, Yuhang Zang, Peng Gao, Yixuan Li, and Kaiyang Zhou. 2025. Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning.arXiv preprint arXiv:2505.14677(2025)
arXiv 2025
-
[51]
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. 2025. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2502.14768 (2025)
Pith/arXiv arXiv 2025
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[53]
Chi Yu, Guang Yang, Xiang Chen, Ke Liu, and Yanlin Zhou. 2022. Bashexplainer: Retrieval-augmented bash code comment generation based on fine-tuned codebert. In2022 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 82–93
2022
-
[54]
Lei Yu, Shiqi Chen, Hang Yuan, Peng Wang, Zhirong Huang, Jingyuan Zhang, Chenjie Shen, Fengjun Zhang, Li Yang, and Jiajia Ma. 2024. Smart-LLaMA: two-stage post-training of large language models for smart contract vulnerability detection and explanation.arXiv preprint arXiv:2411.06221(2024)
arXiv 2024
-
[55]
Lei Yu, Zhirong Huang, Hang Yuan, Shiqi Cheng, Li Yang, Fengjun Zhang, Chenjie Shen, Jiajia Ma, Jingyuan Zhang, Junyi Lu, et al. 2025. Smart-LLaMA-DPO: Reinforced Large Language Model for Explainable Smart Contract Vulnerability Detection.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 182–205
2025
-
[56]
Lei Yu, Jingyuan Zhang, Xin Wang, Jiajia Ma, Li Yang, and Fengjun Zhang. 2025. Towards Secure and Explainable Smart Contract Generation with Security-Aware Group Relative Policy Optimization.arXiv preprint arXiv:2509.09942 (2025)
arXiv 2025
-
[57]
Jipeng Zhang, Jianshu Zhang, Yuanzhe Li, Renjie Pi, Rui Pan, Runtao Liu, Ziqiang Zheng, and Tong Zhang. 2024. Bridge- Coder: Unlocking LLMs’ Potential to Overcome Language Gaps in Low-Resource Code.arXiv preprint arXiv:2410.18957 (2024)
arXiv 2024
-
[58]
Junsan Zhang, Yang Zhu, Ao Lu, Yudie Yan, and Yao Wan. 2025. Bash command comment generation via multi-scale heterogeneous feature fusion.Automated Software Engineering32, 1 (2025), 28. , Vol. 1, No. 1, Article . Publication date: June 2024. 22 Yu et al
2025
-
[59]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. 2024. Llamafactory: Unified efficient fine-tuning of 100+ language models.arXiv preprint arXiv:2403.13372(2024). , Vol. 1, No. 1, Article . Publication date: June 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.