ACAT: A Collaborative Platform for Efficient Aspect-Based Sentiment Dataset Annotation
Pith reviewed 2026-06-28 09:55 UTC · model grok-4.3
The pith
ACAT automates alignment of multi-annotator ABSA data and computes IAA metrics at export to produce training-ready datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
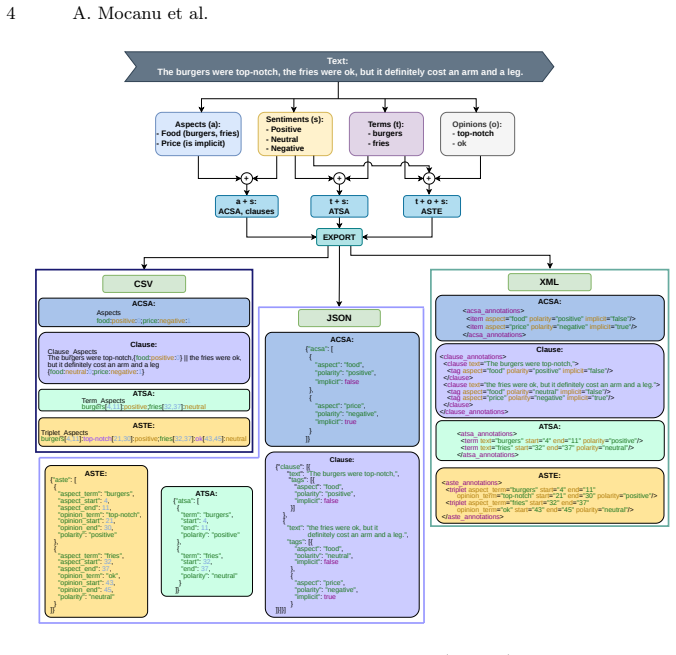
ACAT natively supports four ABSA workflows: Aspect-Category Sentiment Analysis, Clause-Level Segmentation, Aspect-Term Sentiment Analysis with character-level position tracking, and Aspect Sentiment Triplet Extraction with dual span offset preservation. Its core contribution is an automated Extract, Transform, Load (ETL) pipeline that aligns collaborative annotations and computes Inter-Annotator Agreement (IAA) metrics directly at export, yielding training-ready datasets.
What carries the argument
The automated Extract, Transform, Load (ETL) pipeline that aligns annotations from multiple users and computes IAA metrics directly at export time.
If this is right
- Researchers receive training-ready datasets without writing custom consolidation scripts.
- The platform supports four distinct ABSA workflows with preserved relational structures and position data.
- Median annotation time reaches 31.58 seconds per review in the reported validation.
- Raw IAA scores between 0.78 and 0.86 are obtained across tasks with annotators of differing expertise.
Where Pith is reading between the lines
- The ETL approach could be adapted to reduce manual work in dataset creation for other NLP annotation tasks.
- Built-in IAA reporting at export may increase consistency in how agreement is documented for published datasets.
- Workflow-specific span tracking suggests the platform could support extensions to related extraction problems like opinion triplets.
Load-bearing premise
The automated ETL pipeline correctly and completely aligns multi-annotator data and computes accurate IAA values without manual verification or adjustments.
What would settle it
A test export of annotations from multiple users that produces misaligned data structures or incorrect IAA scores requiring manual fixes.
Figures
read the original abstract
Aspect-Based Sentiment Analysis (ABSA) requires high-quality datasets to train reliable models. However, existing annotation tools treat output as flat files, leaving researchers to manually consolidate multi-annotator data, reconstruct relational structures, and compute reliability metrics through custom scripts. This paper introduces ACAT (Aspect-based sentiment analysis Collaborative Annotation Tool), a web-based platform natively supporting four ABSA workflows: (1) Aspect-Category Sentiment Analysis, (2) Clause-Level Segmentation, (3) Aspect-Term Sentiment Analysis with character-level position tracking, and (4) Aspect Sentiment Triplet Extraction with dual span offset preservation. Its core contribution is an automated Extract, Transform, Load (ETL) pipeline that aligns collaborative annotations and computes Inter-Annotator Agreement (IAA) metrics directly at export, yielding training-ready datasets. In a preliminary validation on 1,002 restaurant reviews with two annotators of differing expertise, ACAT achieves a median annotation time of 31.58 seconds and a raw IAA ranging from 0.78 to 0.86 across all tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ACAT, a web-based collaborative annotation platform for Aspect-Based Sentiment Analysis (ABSA) that natively supports four workflows: Aspect-Category Sentiment Analysis, Clause-Level Segmentation, Aspect-Term Sentiment Analysis with character-level position tracking, and Aspect Sentiment Triplet Extraction with dual span offset preservation. Its central claim is that an automated Extract, Transform, Load (ETL) pipeline aligns multi-annotator data (including spans and offsets) and computes Inter-Annotator Agreement (IAA) metrics directly at export to produce training-ready datasets. A preliminary validation on 1,002 restaurant reviews with two annotators reports a median annotation time of 31.58 seconds and raw IAA ranging from 0.78 to 0.86 across tasks.
Significance. If the ETL pipeline is correctly implemented for span-based and relational ABSA tasks, ACAT could reduce manual post-processing effort for multi-annotator datasets and provide reliable IAA metrics out of the box, addressing a practical gap in ABSA data preparation. The reported annotation times and IAA values suggest efficiency gains, but the absence of implementation details prevents determining whether these results are reproducible or generalizable.
major comments (1)
- [ETL pipeline description (Methods/System section)] The manuscript's core contribution—the automated ETL pipeline that aligns collaborative annotations (including character-level spans and dual offsets) and computes IAA metrics—is stated without any algorithm, pseudocode, matching rules for partial overlaps, handling of the four workflows, or error analysis. This directly undermines evaluation of the reported IAA values (0.78–0.86) and the claim that the pipeline yields training-ready datasets without additional verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The point regarding the ETL pipeline description is well-taken and we address it directly below.
read point-by-point responses
-
Referee: [ETL pipeline description (Methods/System section)] The manuscript's core contribution—the automated ETL pipeline that aligns collaborative annotations (including character-level spans and dual offsets) and computes IAA metrics—is stated without any algorithm, pseudocode, matching rules for partial overlaps, handling of the four workflows, or error analysis. This directly undermines evaluation of the reported IAA values (0.78–0.86) and the claim that the pipeline yields training-ready datasets without additional verification.
Authors: We agree that the manuscript presents the ETL pipeline at a high level without algorithms, pseudocode, explicit matching rules, per-workflow handling details, or error analysis. This limits assessment of the IAA figures and the training-ready claim. In revision we will expand the Methods/System section with: pseudocode for the alignment, transformation, and export steps; rules for span matching (exact, partial overlap via character offset or IoU threshold); workflow-specific logic for the four ABSA tasks; and a short error analysis of the IAA computation. These additions will make the pipeline reproducible and allow readers to evaluate the reported results. revision: yes
Circularity Check
No circularity: descriptive tool paper with no derivations or load-bearing self-citations
full rationale
The manuscript presents a software platform and reports empirical annotation times and IAA values from a small validation set. No equations, parameter fits, uniqueness theorems, or derivation steps appear in the abstract or described content. The central claim (automated ETL alignment and IAA computation) is asserted as an engineering contribution without any mathematical reduction to prior inputs or self-citations that would create circularity. This is a standard non-circular descriptive account of a tool.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
human annotators: A comprehensive analysis of chatgpt for text annotation
Aldeen,M.,Luo,J.,Lian,A.,Zheng,V.,Hong,A.,Yetukuri,P.,Cheng,L.:Chatgpt vs. human annotators: A comprehensive analysis of chatgpt for text annotation. In: International Conference on Machine Learning and Applications. pp. 602–609. IEEE (2023). https://doi.org/10.1109/ICMLA58977.2023.00089
-
[2]
Knowledge-Based Systems 326, 113987 (2025)
Apostol, E.S., Pisică, A.G., Truică, C.O.: ATESA-BÆRT: A heterogeneous ensem- ble learning model for aspect-based sentiment analysis. Knowledge-Based Systems 326, 113987 (2025). https://doi.org/10.1016/j.knosys.2025.113987 6 A. Mocanu et al
-
[3]
Educational and psychological measurement20(1), 37–46 (1960)
Cohen, J.: A coefficient of agreement for nominal scales. Educational and psychological measurement20(1), 37–46 (1960). https://doi.org/10.1177/ 001316446002000104
1960
-
[4]
In: International Con- ference on Complex, Intelligent, and Software Intensive Systems
Colucci Cante, L., D’Angelo, S., Di Martino, B., Graziano, M.: Text annotation tools: A comprehensive review and comparative analysis. In: International Con- ference on Complex, Intelligent, and Software Intensive Systems. pp. 353–362. Springer (2024). https://doi.org/10.1007/978-3-031-70011-8_33
-
[5]
Psychological bulletin76(5), 378 (1971)
Fleiss, J.L.: Measuring nominal scale agreement among many raters. Psychological bulletin76(5), 378 (1971). https://doi.org/10.1037/h0031619
-
[6]
EduRABSA: An Education Review Dataset for Aspect-based Sentiment Analysis Tasks
Hua, Y.C., Denny, P., Wicker, J., Taskova, K.: EduRABSA: An Education Review Dataset for Aspect-based Sentiment Analysis Tasks. arXiv preprint arXiv:2508.17008 (2025). https://doi.org/10.48550/arXiv.2508.17008
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.17008 2025
-
[7]
Li, Maxwell Nye, and Jacob Andreas
Li, B.Z., Nye, M., Andreas, J.: Implicit representations of meaning in neural lan- guage models. In: Annual Meeting of the ACL and IJCNLP. pp. 1813–1827 (2021). https://doi.org/10.18653/v1/2021.acl-long.143
-
[8]
Journal of Information Science Theory and Practice3, 6–23 (2015)
Na, J.C., Kyaing, W.: Sentiment analysis of user-generated content on drug review websites. Journal of Information Science Theory and Practice3, 6–23 (2015). https: //doi.org/10.1633/JISTaP.2015.3.1.1
-
[9]
Nakayama, H., Kubo, T., Kamura, J., Taniguchi, Y., Liang, X.: doccano: Text annotation tool for human (2018), https://github.com/doccano/doccano
2018
-
[10]
Pang, B., Lee, L.: Opinion mining and sentiment analysis. Comput. Linguist35(2), 311–312 (2009). https://doi.org/10.1561/1500000011
-
[11]
In: AAAI conference on artificial intelligence
Peng, H., et al.: Knowing what, how and why: A near complete solution for aspect- based sentiment analysis. In: AAAI conference on artificial intelligence. pp. 8600– 8607 (2020). https://doi.org/10.1609/aaai.v34i05.6383
-
[12]
In: Conference on Empirical Meth- ods in Natural Language Processing
Perry, T.: LightTag: Text Annotation Platform. In: Conference on Empirical Meth- ods in Natural Language Processing. pp. 20–27 (2021). https://doi.org/10.18653/ v1/2021.emnlp-demo.3
2021
-
[13]
Petrescu, A., Truică, C.O., Apostol, E.S., Paschke, A.: EDSA-Ensemble: An Event Detection Sentiment Analysis Ensemble Architecture. IEEE Transactions on Affec- tiveComputing16(2),555–572(2025).https://doi.org/10.1109/taffc.2024.3434355
-
[14]
In: International Workshop on Semantic Evaluation
Pontiki, M., et al.: SemEval-2014 task 4: Aspect based sentiment analysis. In: International Workshop on Semantic Evaluation. pp. 27–35 (2014). https://doi. org/10.3115/v1/S14-2004
-
[15]
In: Inter- national Conference on Computational Linguistics
Saeidi, M., Bouchard, G., Liakata, M., Riedel, S.: SentiHood: Targeted As- pect Based Sentiment Analysis Dataset for Urban Neighbourhoods. In: Inter- national Conference on Computational Linguistics. pp. 1546–1556 (2016), https: //aclanthology.org/C16-1146/
2016
-
[16]
In: European Chapter of the ACL
Stenetorp, P., Pyysalo, S., Topić, G., Ohta, T., Ananiadou, S., Tsujii, J.: brat: a Web-based Tool for NLP-Assisted Text Annotation. In: European Chapter of the ACL. pp. 102–107 (2012), https://aclanthology.org/E12-2021/
2012
-
[17]
Sun, Y., Huang, Q., Tung, A.K., Yu, J.: Text embeddings should capture implicit semantics,notjustsurfacemeaning.arXivpreprintarXiv:2506.08354(2025).https: //doi.org/10.48550/arXiv.2506.08354
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.08354 2025
-
[18]
Tkachenko, M., Malyuk, M., Holmanyuk, A., Liubimov, N.: Label Studio: Data labeling software (2020-2025), https://github.com/HumanSignal/label-studio
2020
-
[19]
UPB Scientific Bulletin - Series C79(4), 69–84 (2017)
Truică, C.O., Leordeanu, C.A.: Classification of an imbalanced data set using de- cision tree algorithms. UPB Scientific Bulletin - Series C79(4), 69–84 (2017)
2017
-
[20]
In: ACL 2018, System Demonstrations
Yang, J., Zhang, Y., Li, L., Li, X.: YEDDA: A Lightweight Collaborative Text Span Annotation Tool. In: ACL 2018, System Demonstrations. pp. 31–36 (2018). https://doi.org/10.18653/v1/P18-4006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.