Null-Space Constrained Low-Rank Adaptation for Response-Specified Large Language Model Unlearning
Pith reviewed 2026-06-27 13:33 UTC · model grok-4.3
The pith
NSRU confines LoRA updates to the null space of retain subspaces for response-specified LLM unlearning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
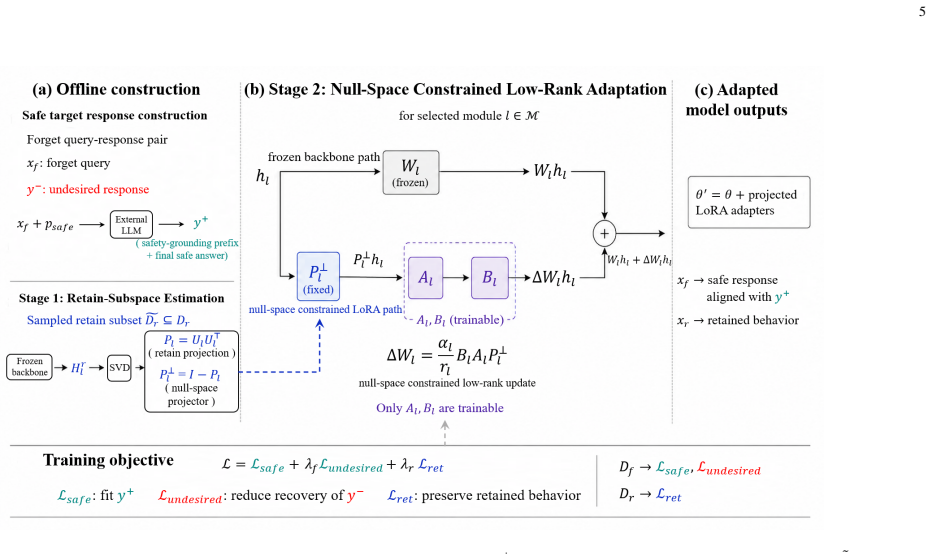
NSRU estimates per-module retain subspaces from benign hidden representations and applies an orthogonal-projected low-rank parameterization that confines updates to the null space of those subspaces. The resulting objective jointly optimizes safe-target learning for each forget query, undesired-response suppression, and retention preservation. Local first-order analysis shows the projected update reduces retain-side perturbations while preserving editable directions for shaping forget-query behavior. On TOFU this yields effective suppression of extractable forget-set knowledge with improved retain QA performance, model utility, and safe-target alignment; on WMDP it keeps hazardous-domain acc
What carries the argument
Orthogonal projection of LoRA updates into the null space of per-module retain subspaces estimated from benign hidden representations.
If this is right
- The constrained parameterization suppresses extractable forget-set knowledge on TOFU while improving retain QA performance, model utility, and safe-target alignment over baselines.
- On WMDP the method keeps hazardous-domain accuracy near the random-choice region while preserving broad and domain-adjacent MMLU utility.
- Ablation studies establish complementary roles for safe-target supervision, undesired-response suppression, retention loss, and null-space projected updates.
- Sensitivity analyses indicate stable behavior across tested hyperparameter and prompt variations.
Where Pith is reading between the lines
- The same null-space projection technique could be applied to other parameter-efficient adaptation methods beyond LoRA.
- If retain subspaces can be estimated from a small set of benign examples, the approach may extend to continual unlearning settings where new forget targets arrive over time.
- The local first-order analysis could be extended to quantify how much editable capacity remains for forget queries after projection, guiding hyperparameter choices.
Load-bearing premise
Per-module retain subspaces estimated from benign hidden representations accurately identify the directions that must remain unchanged.
What would settle it
If NSRU applied to TOFU fails to suppress extractable forget-set knowledge below baseline levels or degrades retain QA performance relative to unprojected LoRA variants, the central claim would not hold.
Figures


read the original abstract
Large language model unlearning aims to suppress designated undesirable knowledge while preserving benign capabilities. Many unlearning objectives focus on suppressing undesired answers, while recent target-guided variants specify replacement behavior but still leave update locality largely unconstrained. This paper introduces \emph{Null-Space Constrained Response-Specified Unlearning} (NSRU), a projection-constrained low-rank framework for controlled LLM unlearning. NSRU uses an explicitly structured safe target response to specify the desired behavior for each forget query, while suppressing the original undesired content. To localize adaptation, NSRU estimates per-module retain subspaces from benign hidden representations and uses an orthogonal-projected low-rank parameterization to confine LoRA updates to the null space of the retain subspace. The resulting objective jointly optimizes safe-target learning, undesired-response suppression, and retention preservation under this constrained parameterization. We provide a local first-order analysis showing that the projected update reduces retain-side perturbations while preserving editable directions for shaping forget-query behavior. Experiments on TOFU show that NSRU effectively suppresses extractable forget-set knowledge while improving retain QA performance, model utility, and safe-target alignment over representative baselines. On WMDP, NSRU keeps hazardous-domain accuracy near the random-choice region while preserving broad and domain-adjacent MMLU utility. Ablation studies support the complementary roles of safe-target supervision, undesired-response suppression, retention loss, and null-space projected updates, while sensitivity and robustness analyses indicate stable behavior across the tested hyperparameter and prompt variations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Null-Space Constrained Response-Specified Unlearning (NSRU), a LoRA-based framework that specifies safe target responses for forget queries while using per-module retain subspaces (estimated from benign hidden states) to orthogonally project updates into their null space. A local first-order analysis argues that this reduces retain-side perturbations while preserving editable directions for forget behavior. The joint objective combines safe-target learning, undesired-response suppression, and retention preservation. Experiments on TOFU report effective forget-set suppression with gains in retain QA, model utility, and safe-target alignment over baselines; on WMDP, hazardous accuracy stays near random while preserving MMLU utility. Ablations and sensitivity checks are included.
Significance. If the projection mechanism reliably localizes updates in practice, the approach supplies an explicit, structured way to enforce locality in response-specified unlearning without relying solely on regularization, which could strengthen controllability claims in LLM editing. The multi-term objective and per-module subspace construction are clearly stated strengths.
major comments (1)
- [local first-order analysis] The local first-order analysis (method overview and associated derivation): the argument that the orthogonal projection confines updates to the null space of retain subspaces while preserving editable directions for forget-query behavior rests on the assumption that first-order perturbations dominate and that the estimated subspaces remain invariant under the non-linear forward pass of transformer layers. No empirical verification or higher-order bounds are supplied showing that the subspaces estimated from benign representations stay effective throughout the actual training trajectory; this directly underpins the central claim that retain perturbations are reduced without over-constraining forget editing.
minor comments (2)
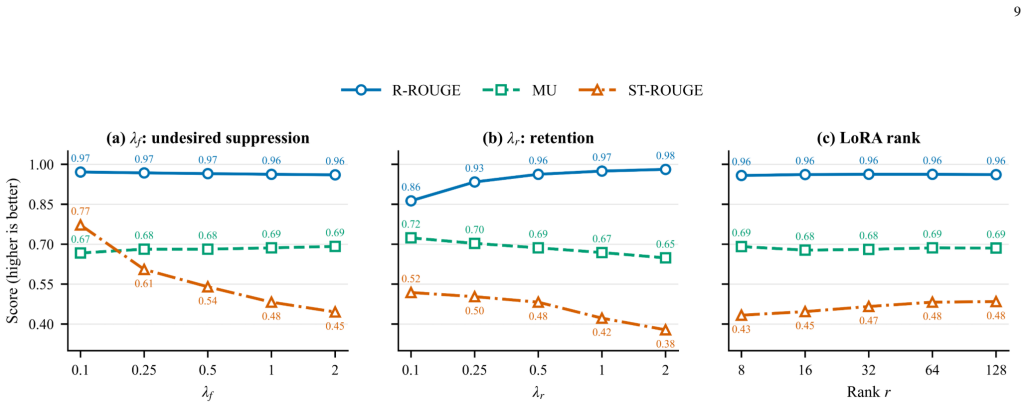
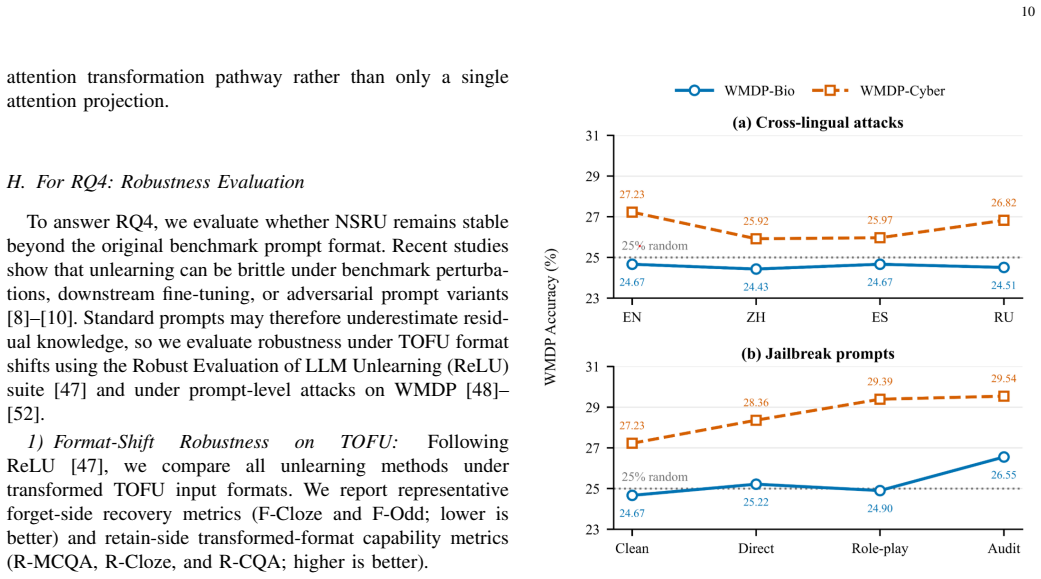
- [experiments] The abstract and experiments section reference sensitivity and robustness analyses across hyperparameter and prompt variations, but the specific ranges and prompt templates used are not enumerated, making it difficult to assess the scope of the reported stability.
- [method] Notation for the retain subspace estimation and the projection operator could be introduced with an explicit equation early in the method section to improve readability before the analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the paper's significance. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [local first-order analysis] The local first-order analysis (method overview and associated derivation): the argument that the orthogonal projection confines updates to the null space of retain subspaces while preserving editable directions for forget-query behavior rests on the assumption that first-order perturbations dominate and that the estimated subspaces remain invariant under the non-linear forward pass of transformer layers. No empirical verification or higher-order bounds are supplied showing that the subspaces estimated from benign representations stay effective throughout the actual training trajectory; this directly underpins the central claim that retain perturbations are reduced without over-constraining forget editing.
Authors: We agree that the local first-order analysis relies on the stated assumptions without direct empirical verification of subspace invariance over the full training trajectory or higher-order bounds. While the derivation establishes the intended localization property under the first-order regime, the referee correctly identifies that this leaves open whether the estimated retain subspaces remain sufficiently stable in practice under the non-linear dynamics. In the revised manuscript we will add a dedicated empirical verification subsection (in Section 4) that tracks subspace alignment (via principal angle metrics) and projection effectiveness at multiple checkpoints during training on TOFU. We will also report the evolution of retain-side perturbation norms with and without the null-space constraint to provide concrete support for the analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines NSRU via an explicit orthogonal projection of LoRA updates onto the null space of per-module retain subspaces (estimated from benign hidden states) together with a multi-term objective combining safe-target supervision, undesired-response suppression, and retention preservation. The local first-order analysis simply restates the geometric consequence of that orthogonal projection (reduced retain perturbations by construction) without introducing a separate prediction or fitted quantity that is then re-derived as output. Experimental claims rest on TOFU and WMDP benchmarks rather than any self-referential reduction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided text; the method and analysis remain self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retain subspaces estimated from benign hidden representations correctly capture directions that should remain unperturbed
Reference graph
Works this paper leans on
-
[1]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” inProceedings of the 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 141–159
2021
-
[2]
Large language model unlearning,
Y . Yao, X. Xu, and Y . Liu, “Large language model unlearning,” in Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[3]
Tofu: A task of fictitious unlearning for llms,
P. Maini, Z. Feng, A. Schwarzschild, Z. C. Lipton, and J. Z. Kolter, “Tofu: A task of fictitious unlearning for llms,” inProceedings of the First Conference on Language Modeling (COLM), 2024
2024
-
[4]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
R. Zhang, L. Lin, Y . Bai, and S. Mei, “Negative preference optimization: From catastrophic collapse to effective unlearning,”arXiv preprint arXiv:2404.05868, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rethinking machine unlearning for large language models,
S. Liu, Y . Yao, J. Jia, S. Casper, N. Baracaldo, P. Hase, Y . Yao, C. Y . Liu, X. Xu, H. Liet al., “Rethinking machine unlearning for large language models,”Nature Machine Intelligence, 2025
2025
-
[6]
Muse: Machine unlearning six-way evaluation for language models,
W. Shi, J. Lee, Y . Huang, S. Malladi, J. Zhao, A. Holtzman, D. Liu, L. Zettlemoyer, N. A. Smith, and C. Zhang, “Muse: Machine unlearning six-way evaluation for language models,” inProceedings of the Inter- national Conference on Learning Representations (ICLR), 2025. 11
2025
-
[7]
Openunlearning: Accelerating llm unlearning via unified benchmarking of methods and metrics,
V . Dorna, A. Mekala, W. Zhao, A. McCallum, Z. C. Lipton, J. Z. Kolter, and P. Maini, “Openunlearning: Accelerating llm unlearning via unified benchmarking of methods and metrics,” inNeurIPS 2025 Datasets and Benchmarks Track, 2025
2025
-
[8]
Position: LLM unlearning benchmarks are weak measures of progress,
P. Thaker, S. Hu, N. Kale, Y . Maurya, Z. S. Wu, and V . Smith, “Position: LLM unlearning benchmarks are weak measures of progress,” in2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 520–533. [Online]. Available: https://arxiv.org/abs/2410.02879
-
[9]
Invariance makes LLM unlearning resilient even to unanticipated downstream fine-tuning,
C. Wang, Y . Zhang, J. Jia, P. Ram, D. Wei, Y . Yao, S. Pal, N. Baracaldo, and S. Liu, “Invariance makes LLM unlearning resilient even to unanticipated downstream fine-tuning,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 65 464–65 479. [Online]. Available:...
2025
-
[10]
Auditing language model unlearning via information decomposition,
A. Goel, A. Ritter, and I. Gurevych, “Auditing language model unlearning via information decomposition,” inProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). Rabat, Morocco: Association for Computational Linguistics, 2026, pp. 808–826. [Online]. Available: https://aclantholo...
2026
-
[11]
Explainable llm unlearning through reasoning,
J. Liao, Q. Wang, S. Ye, X. Yu, L. Chen, and Z. Fang, “Explainable llm unlearning through reasoning,” inProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[12]
Alternate preference optimization for unlearning factual knowledge in large language models,
A. Mekala, V . Dorna, S. Dubey, A. Lalwani, D. Koleczek, M. Rungta, S. Hasan, and E. Lobo, “Alternate preference optimization for unlearning factual knowledge in large language models,” inProceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE: Association for Computational Linguistics, 2025, pp. 3732–3752
2025
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Lora learns less and forgets less,
D. Biderman, J. Portes, J. J. Gonzalez Ortiz, M. Paul, P. Greengard, C. Jennings, D. King, S. Havens, V . Chiley, J. Frankle, C. Blakeney, and J. P. Cunningham, “Lora learns less and forgets less,”Transactions on Machine Learning Research, 2024
2024
-
[15]
H. Lu, C. Zhao, J. Xue, L. Yao, K. Moore, and D. Gong, “Adaptive rank, reduced forgetting: Knowledge retention in continual learning vision- language models with dynamic rank-selective lora,”arXiv preprint arXiv:2412.01004, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
OPLoRA: Orthogonal projection LoRA prevents catastrophic forgetting during parameter-efficient fine-tuning,
Y . Xiong and X. Xie, “OPLoRA: Orthogonal projection LoRA prevents catastrophic forgetting during parameter-efficient fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 40, 2026, pp. 34 088–34 096. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/40703
2026
- [17]
-
[18]
Large language model unlearning,
Y . Yao, X. Xu, and Y . Liu, “Large language model unlearning,” in Advances in Neural Information Processing Systems, 2024
2024
-
[19]
Machine unlearning of pre-trained large language models,
J. Yao, E. Chien, M. Du, X. Niu, T. Wang, Z. Cheng, and X. Yue, “Machine unlearning of pre-trained large language models,” inProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics, 2024, pp. 8403–8419
2024
-
[20]
Simplicity prevails: Rethinking negative preference optimization for llm unlearn- ing,
C. Fan, J. Liu, L. Lin, J. Jia, R. Zhang, S. Mei, and S. Liu, “Simplicity prevails: Rethinking negative preference optimization for llm unlearn- ing,” inInternational Conference on Learning Representations, 2025
2025
-
[21]
ReLearn: Unlearning via learning for large language models,
H. Xu, N. Zhao, L. Yang, S. Zhao, S. Deng, M. Wang, B. Hooi, N. Oo, H. Chen, and N. Zhang, “ReLearn: Unlearning via learning for large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025, pp. 5967–5987. [Online]...
2025
-
[22]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[23]
R-tofu: Unlearning in large reasoning models,
S. Yoon, W. Jeung, and A. No, “R-tofu: Unlearning in large reasoning models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, 2025, pp. 5239–5258
2025
-
[24]
The wmdp benchmark: Measuring and reducing malicious use with unlearning,
N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, L. Phanet al., “The wmdp benchmark: Measuring and reducing malicious use with unlearning,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[25]
On effects of steering latent representation for large language model unlearning,
H.-T. Dang, T.-T. Pham, T.-T. Hoang, and N. Inoue, “On effects of steering latent representation for large language model unlearning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 733–23 742
2025
-
[26]
LLM unlearning via neural activation redirection,
W. F. Shen, X. Qiu, M. Kurmanji, A.-A. Iacob, L. Sani, Y . Chen, N. Cancedda, and N. D. Lane, “LLM unlearning via neural activation redirection,” inAdvances in Neural Information Processing Systems,
-
[27]
Available: https://openreview.net/forum?id=teB4aqJsNP
[Online]. Available: https://openreview.net/forum?id=teB4aqJsNP
-
[28]
Lock on target! precision unlearning via directional control,
Y . Wen, R. Feng, F. Guo, Y . Wang, R. Le, Y . Song, S. Gao, and S. Shang, “Lock on target! precision unlearning via directional control,” inFindings of the Association for Computational Linguistics: EMNLP 2025. Suzhou, China: Association for Computational Linguistics, 2025, pp. 18 782–18 794. [Online]. Available: https: //aclanthology.org/2025.findings-e...
2025
-
[29]
Towards robust and parameter- efficient knowledge unlearning for llms,
S. Cha, S. Cho, D. Hwang, and M. Lee, “Towards robust and parameter- efficient knowledge unlearning for llms,” inProceedings of the Interna- tional Conference on Learning Representations (ICLR), 2025
2025
-
[30]
Unified parameter-efficient unlearning for llms,
C. Ding, J. Wu, Y . Yuan, J. Lu, K. Zhang, A. Su, X. Wang, and X. He, “Unified parameter-efficient unlearning for llms,” inProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[31]
Lune: Efficient llm unlearning via lora fine-tuning with negative examples,
Y . Liu, H. Chen, W. Huang, Y . Ni, and M. Imani, “Lune: Efficient llm unlearning via lora fine-tuning with negative examples,” inSocially Responsible and Trustworthy Foundation Models at NeurIPS 2025, 2025
2025
-
[32]
Quantization-Robust LLM Unlearning via Low-Rank Adaptation
J. V . B. Abitante, J. M. Pasquali, L. F. Garcia, E. de Oliveira, T. da Silva Paula, R. C. Barros, and L. S. Kupssinsk ¨u, “Quantization- robust llm unlearning via low-rank adaptation,”arXiv preprint arXiv:2602.13151, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics, 2022, pp. 8493–8502
2022
-
[34]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,”Advances in Neural Information Processing Systems, vol. 35, 2022
2022
-
[35]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inInternational Conference on Learning Rep- resentations, 2022
2022
-
[36]
Mass-editing memory in a transformer,
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,” inInternational Conference on Learning Representations, 2023
2023
-
[37]
Continual learning of context- dependent processing in neural networks,
G. Zeng, Y . Chen, B. Cui, and S. Yu, “Continual learning of context- dependent processing in neural networks,”Nature Machine Intelligence, vol. 1, no. 8, pp. 364–372, 2019
2019
-
[38]
Efficient lifelong learning with A-GEM,
A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny, “Efficient lifelong learning with A-GEM,” inInternational Conference on Learning Representations, 2019
2019
-
[39]
Training networks in null space of feature covariance for continual learning,
S. Wang, X. Li, J. Sun, and Z. Xu, “Training networks in null space of feature covariance for continual learning,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2021, pp. 184–193
2021
-
[40]
Alphaedit: Null-space constrained knowledge editing for language models,
J. Fang, H. Jiang, K. Wang, Y . Ma, X. Wang, X. He, and T.-S. Chua, “Alphaedit: Null-space constrained knowledge editing for language models,” inProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[41]
Model unlearning via sparse autoencoder subspace guided projections,
X. Wang, Z. Li, B. Wang, Y . Hu, and D. Zou, “Model unlearning via sparse autoencoder subspace guided projections,” inICML 2025 Workshop on Machine Unlearning for Generative AI, 2025
2025
-
[42]
Less is More: Geometric Unlearning for LLMs with Minimal Data Disclosure
C. Tan, X. Li, S. Cui, Y . Qu, C. Chen, and L. Gao, “Less is more: Geometric unlearning for LLMs with minimal data disclosure,”arXiv preprint arXiv:2605.01735, 2026. [Online]. Available: https://arxiv.org/abs/2605.01735
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
The approximation of one matrix by another of lower rank,
C. Eckart and G. Young, “The approximation of one matrix by another of lower rank,”Psychometrika, vol. 1, no. 3, pp. 211–218, 1936
1936
-
[44]
Symmetric gauge functions and unitarily invariant norms,
L. Mirsky, “Symmetric gauge functions and unitarily invariant norms,” The Quarterly Journal of Mathematics, vol. 11, no. 1, pp. 50–59, 1960
1960
-
[45]
Finding structure with randomness: Probabilistic algorithms for constructing approximate ma- trix decompositions,
N. Halko, P.-G. Martinsson, and J. A. Tropp, “Finding structure with randomness: Probabilistic algorithms for constructing approximate ma- trix decompositions,”SIAM Review, vol. 53, no. 2, pp. 217–288, 2011
2011
-
[46]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Zephyr: Direct Distillation of LM Alignment
L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y . Belkada, S. Huang, L. V on Werra, C. Fourrier, N. Habibet al., “Zephyr: Direct distillation of lm alignment,”arXiv preprint arXiv:2310.16944, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Towards robust evaluation of unlearning in LLMs via data transformations,
A. Joshi, S. Saha, D. Shukla, S. Vema, H. Jhamtani, M. Gaur, and A. Modi, “Towards robust evaluation of unlearning in LLMs via data transformations,” inFindings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, November 2024, pp. 12 100–12 119. [Online]. Available: https://aclanth...
2024
-
[49]
Multilingual jailbreak challenges in large language models,
Y . Deng, W. Zhang, S. J. Pan, and L. Bing, “Multilingual jailbreak challenges in large language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=vESNKdEMGp
2024
-
[50]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Sehwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Tram `er, H. Hassani, and E. Wong, “Jailbreakbench: An open robustness benchmark for jailbreaking large language models,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, datasets and Benchmarks Track. [Online]. Avail...
2024
-
[51]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Ko...
-
[52]
35 181–35 224
PMLR, 21–27 Jul 2024, pp. 35 181–35 224. [Online]. Available: https://proceedings.mlr.press/v235/mazeika24a.html
2024
-
[53]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, ““Do Anything Now”: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models,” inProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security. New York, NY , USA: Association for Computing Machinery, 2024, pp. 1671–1685. [Online]. Available: https://...
-
[54]
Don’t listen to me: Understanding and exploring jailbreak prompts of large language models,
Z. Yu, X. Liu, S. Liang, Z. Cameron, C. Xiao, and N. Zhang, “Don’t listen to me: Understanding and exploring jailbreak prompts of large language models,” in33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA: USENIX Association, August 2024, pp. 4675–4692. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity24/presentat...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.