How to Allocate Your Tokens? Scaling Laws with Training Steps and Batch Size
Pith reviewed 2026-07-03 21:00 UTC · model grok-4.3
The pith
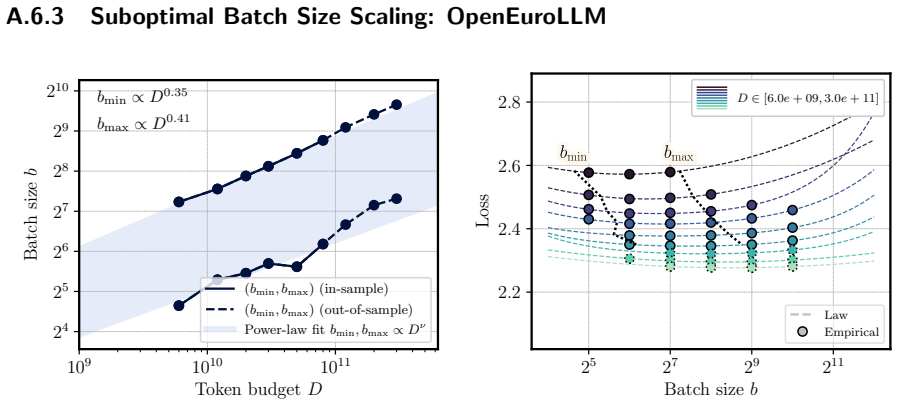
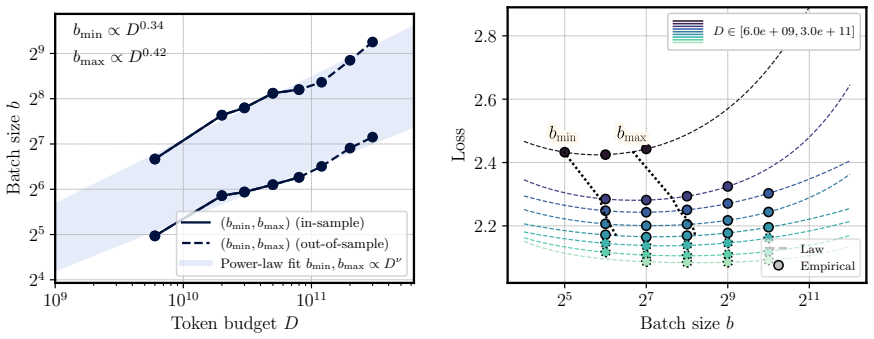
A three-term scaling law separates training steps from batch size to recover optimal allocation scaling from suboptimal runs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
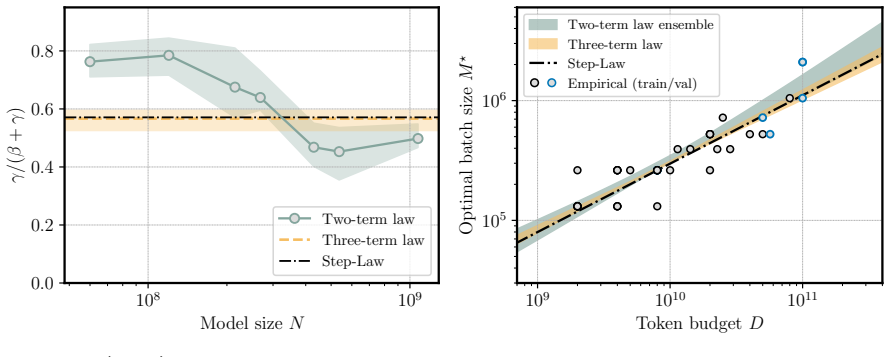
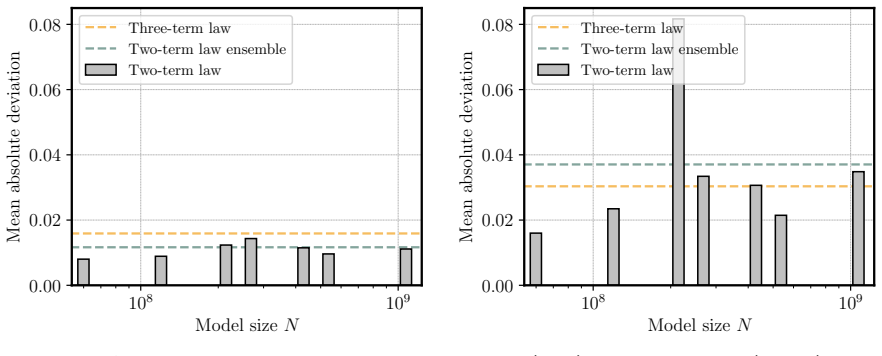
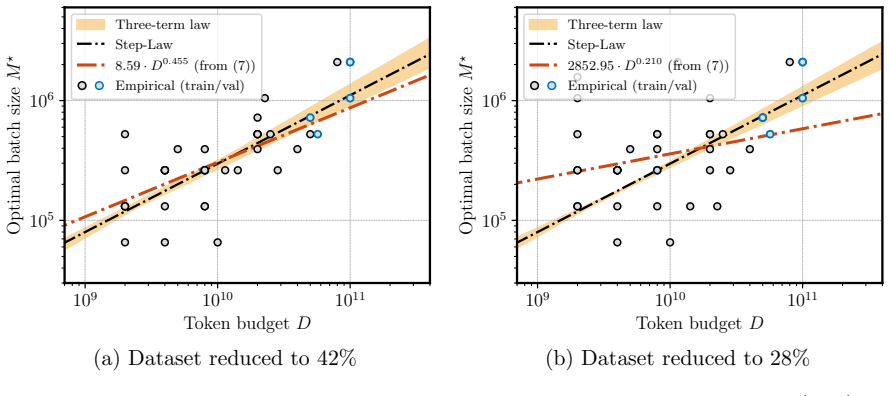
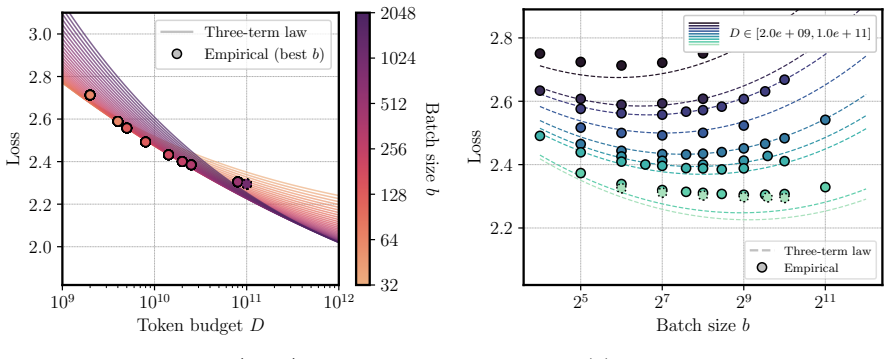
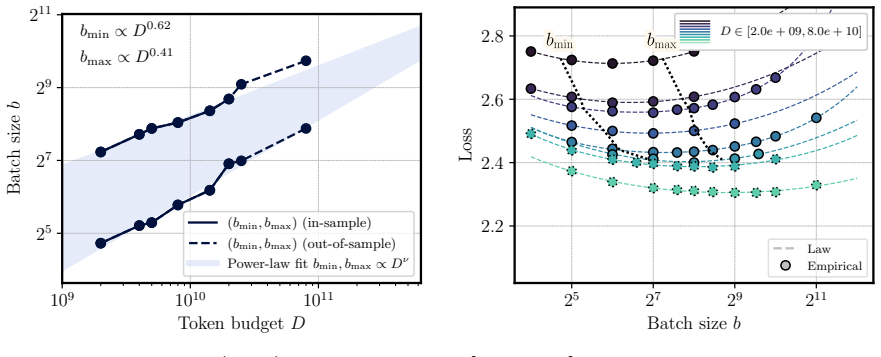
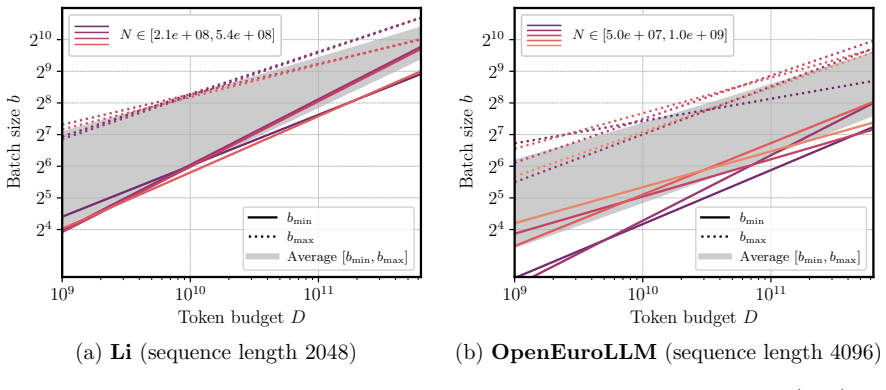
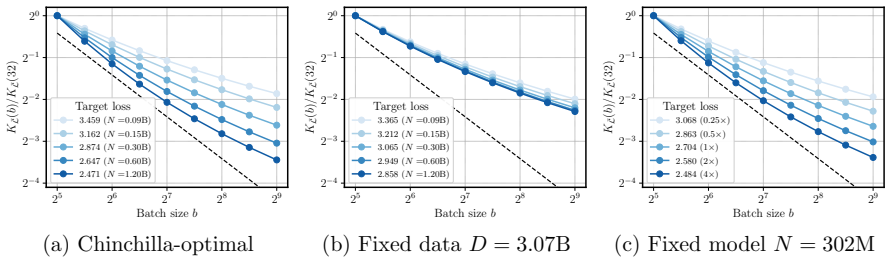
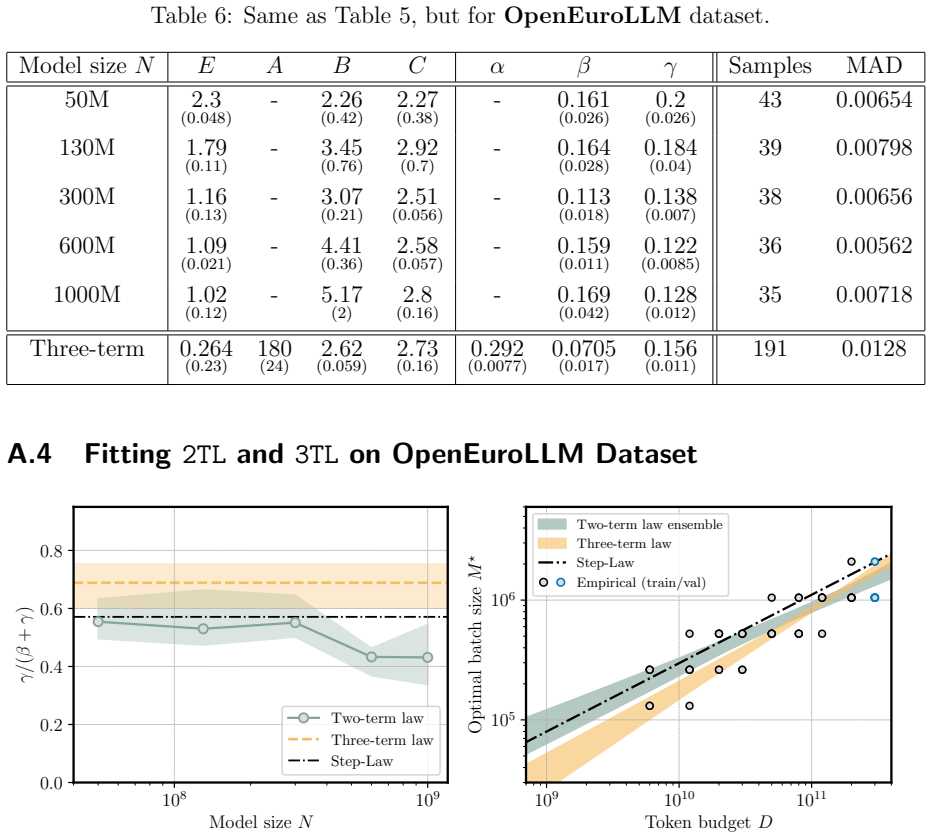
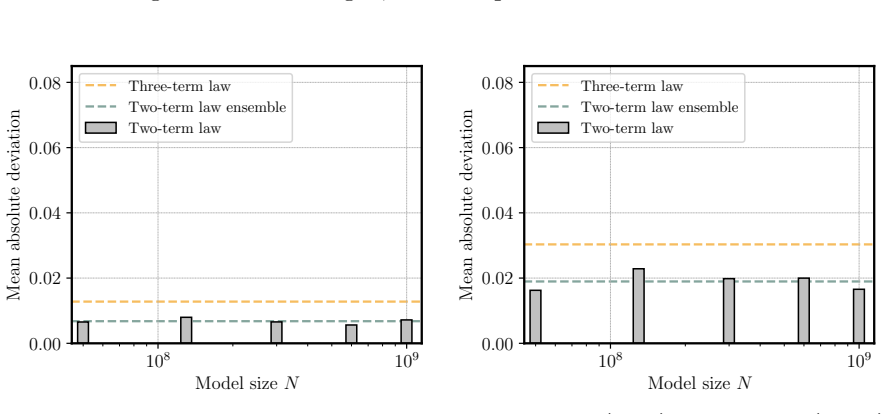
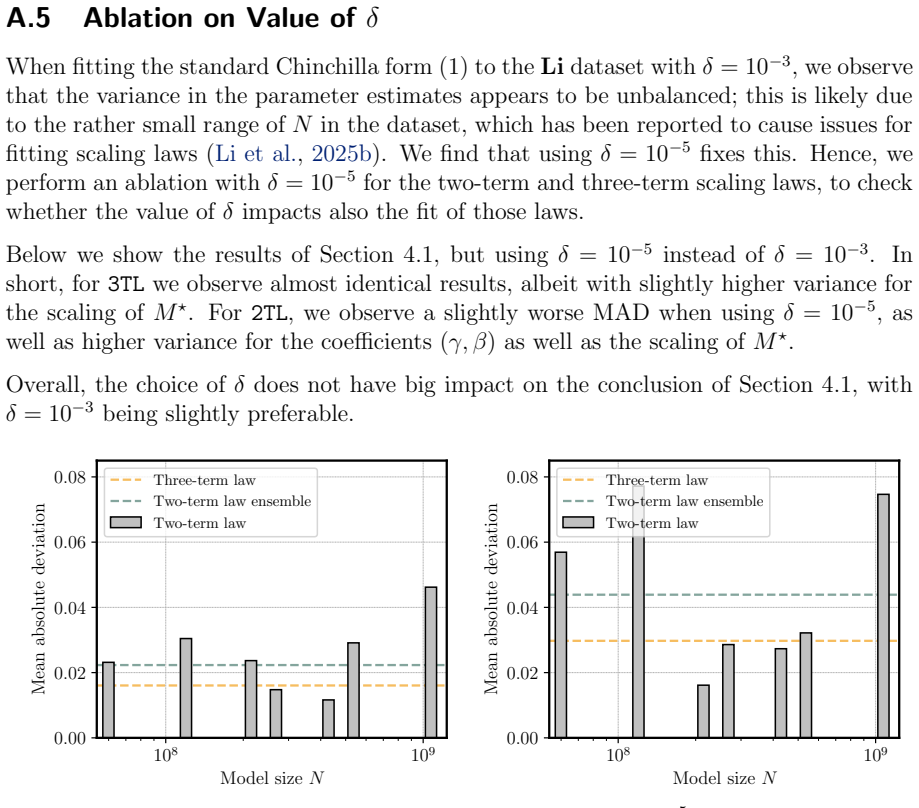
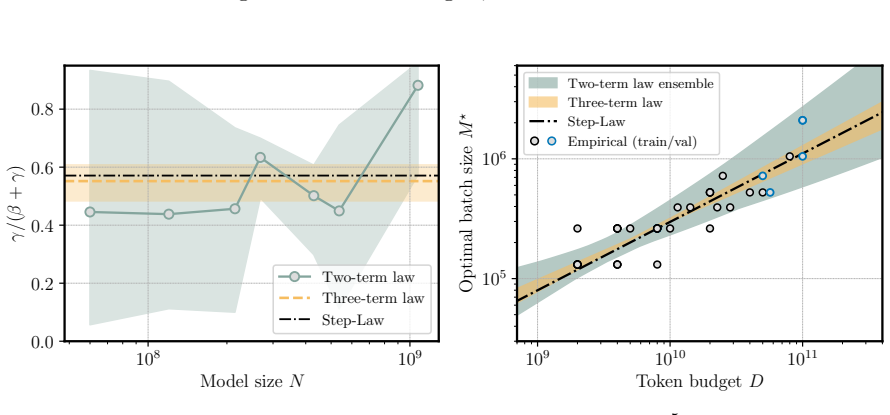
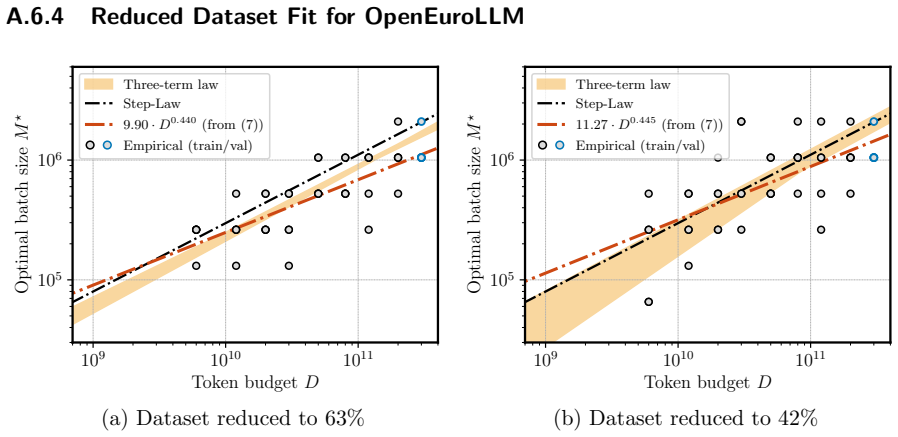
We propose a scaling law that takes into account model size and training data while explicitly splitting the latter into training steps and batch size (called three-term law). Fitting the proposed law on a large set of training runs, we find that it correctly recovers the scaling of the optimal batch size. Moreover, because it makes use of training runs with suboptimal batch size, our proposed law can be robustly fit with a significantly smaller amount of training runs. We further show that the three-term law can be used to derive scaling laws for suboptimal batch sizes, and that it matches previous empirical findings related to the critical batch size.
What carries the argument
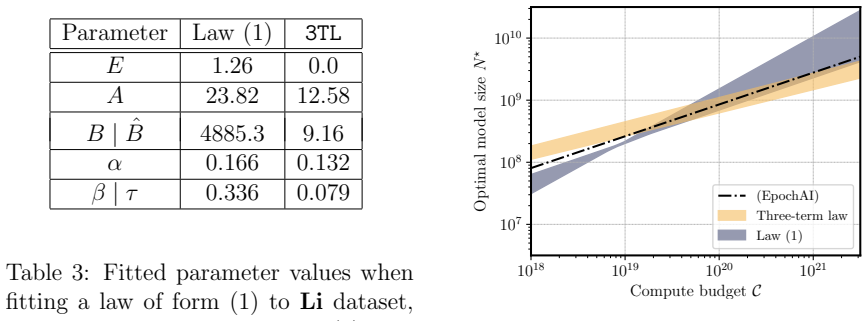
The three-term scaling law, which expresses loss as a joint function of model size, training steps, and batch size treated as independent variables.
If this is right
- The law recovers the scaling of optimal batch size with model size and data volume.
- Robust fitting is possible with significantly fewer training runs by including suboptimal batch sizes.
- Scaling laws for any fixed suboptimal batch size can be derived from the three-term form.
- The law reproduces prior empirical observations on critical batch size.
Where Pith is reading between the lines
- Token budgets could be allocated more efficiently by first fitting the law on cheap suboptimal runs and then predicting the best batch size.
- The separation of steps and batch size may let the same functional form guide choices for other training hyperparameters such as learning-rate schedules.
- Testing the law on architectures or data modalities outside the original runs would show whether the three-term structure is broadly applicable.
Load-bearing premise
A single three-term functional form fitted to runs with varying batch sizes will correctly extrapolate to the optimal batch size regime without requiring separate data from optimal runs.
What would settle it
Dedicated experiments run at the batch sizes predicted to be optimal by the fitted law show loss values or scaling exponents that differ substantially from the law's forecasts.
Figures
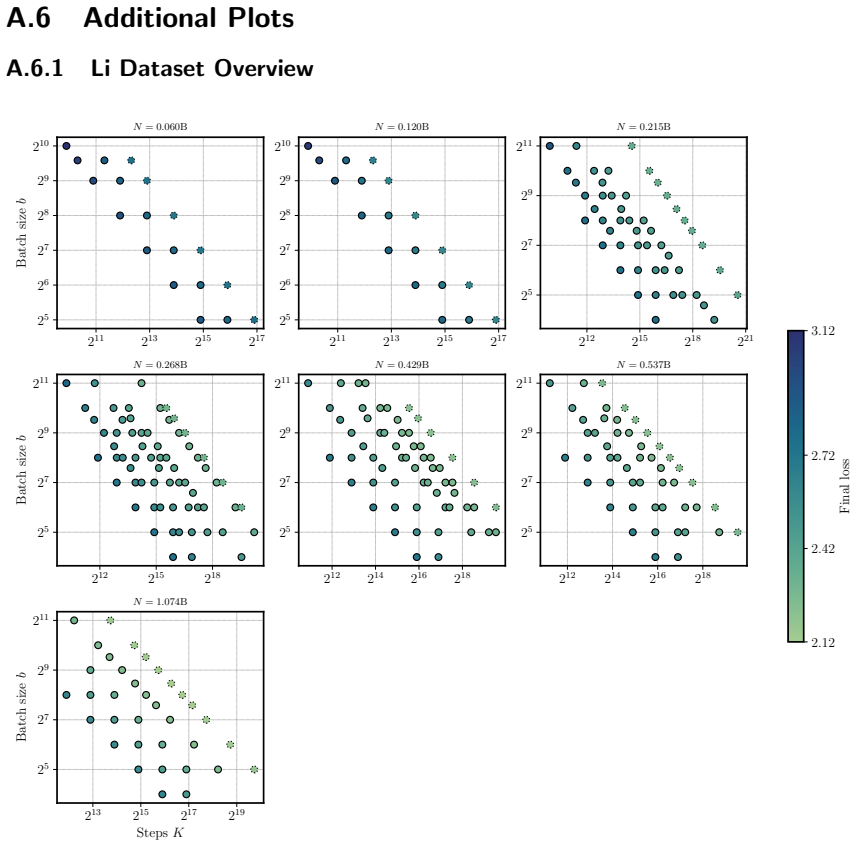
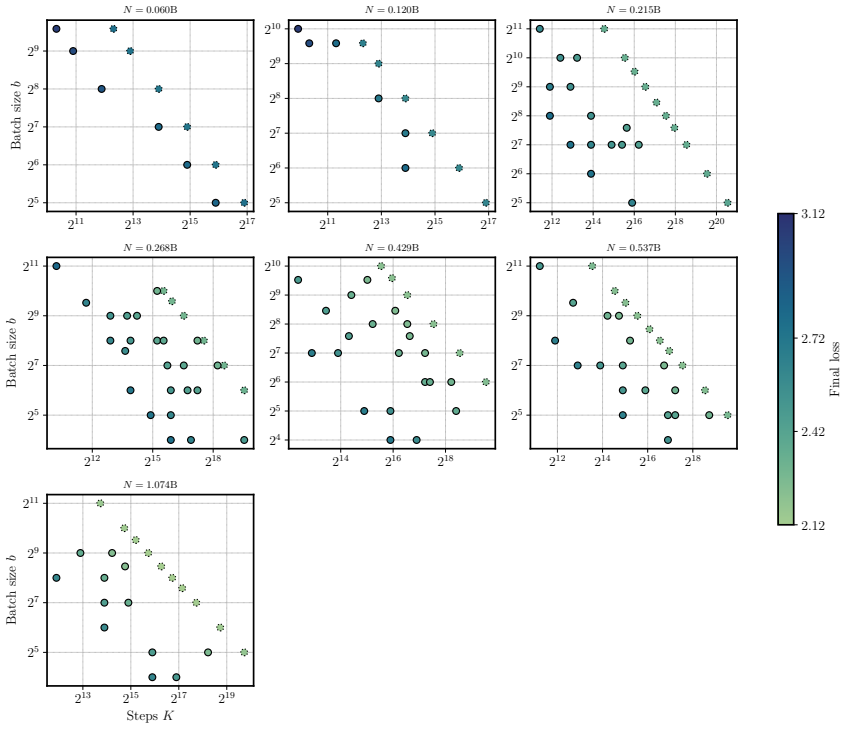

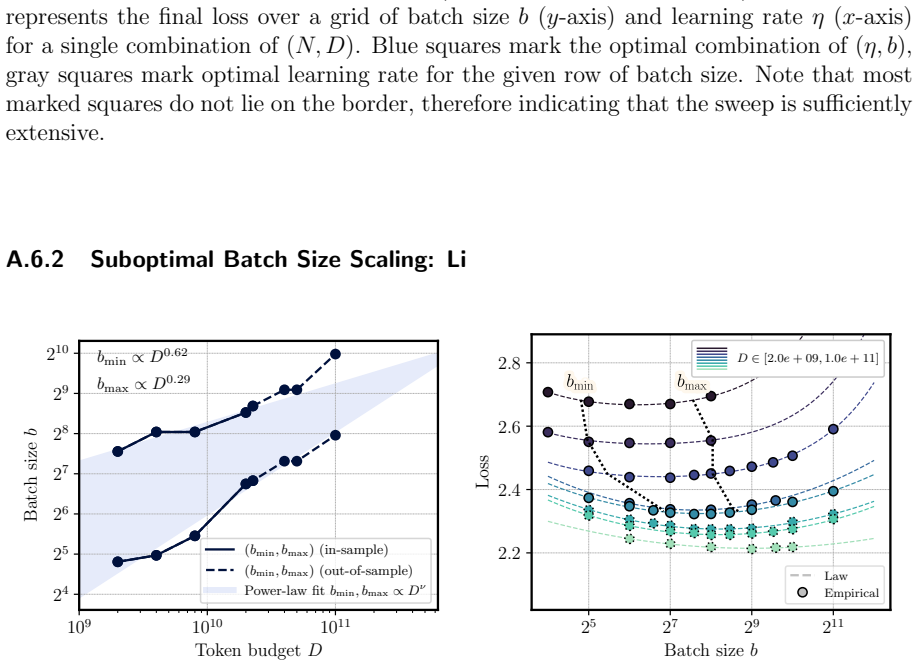
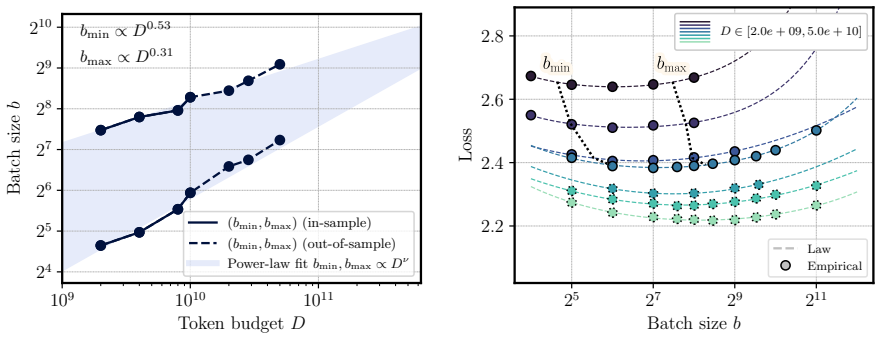
read the original abstract
We propose a scaling law that takes into account model size and training data while explicitly splitting the latter into training steps and batch size (called three-term law). Fitting the proposed law on a large set of training runs, we find that it correctly recovers the scaling of the optimal batch size. Moreover, because it makes use of training runs with suboptimal batch size, our proposed law can be robustly fit with a significantly smaller amount of training runs. We further show that the three-term law can be used to derive scaling laws for suboptimal batch sizes, and that it matches previous empirical findings related to the critical batch size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a three-term scaling law that decomposes the training data term into separate contributions from training steps and batch size (in addition to model size). Fitting this functional form to a collection of runs that include suboptimal batch sizes is claimed to recover the scaling of the optimal batch size, to enable robust fitting with substantially fewer runs than would otherwise be required, to yield derived scaling laws for suboptimal regimes, and to match prior empirical results on critical batch size.
Significance. If the extrapolation from suboptimal to optimal regimes holds without regime-dependent misspecification, the approach would reduce the experimental cost of mapping optimal token allocation by allowing existing suboptimal runs to contribute to the fit, thereby extending the practical reach of scaling-law methodology.
major comments (2)
- [Abstract] Abstract: the central claim that the fitted law 'correctly recovers the scaling of the optimal batch size' is presented without any description of the fitting procedure, error bars, data-exclusion criteria, or confirmation that the functional form was not selected after inspection of the same data; these omissions make it impossible to evaluate whether the reported recovery is an independent prediction or a tautological consequence of the fit.
- [Experiments / fitting results] The manuscript provides no held-out validation or regime-specific stress test demonstrating that the three-term functional form remains an accurate local approximation when batch size approaches the critical regime; without such a test, the extrapolation from the mixture of suboptimal runs to the optimal-batch-size scaling cannot be taken as established.
minor comments (2)
- [Method] The exact algebraic expression for the three-term law (how the steps and batch-size terms are combined with the model-size term) should be stated explicitly, preferably as an equation in the main text.
- [Figures] Figure captions and axis labels should indicate whether plotted points are individual runs or aggregated statistics and whether error bars represent run-to-run variance or fit uncertainty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The three-term scaling law is motivated by a decomposition of the data term that is independent of any particular dataset, and we address the concerns about presentation and validation below by clarifying the fitting details and committing to additional checks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the fitted law 'correctly recovers the scaling of the optimal batch size' is presented without any description of the fitting procedure, error bars, data-exclusion criteria, or confirmation that the functional form was not selected after inspection of the same data; these omissions make it impossible to evaluate whether the reported recovery is an independent prediction or a tautological consequence of the fit.
Authors: We agree that the abstract is too terse on these points. The functional form follows directly from splitting the standard Chinchilla-style data term into separate step and batch-size contributions, a decomposition already implicit in prior critical-batch-size literature; it was not chosen by inspecting the current runs. In revision we will expand the abstract by one sentence to note that the fit uses ordinary least-squares on log-loss with the full set of runs (including suboptimal batch sizes), with error bars obtained via bootstrap, and will add a short methods paragraph summarizing the exact procedure, exclusion criteria (runs that failed to converge), and pre-specification of the form. The main text already contains the full fitting details and will be cross-referenced. revision: yes
-
Referee: [Experiments / fitting results] The manuscript provides no held-out validation or regime-specific stress test demonstrating that the three-term functional form remains an accurate local approximation when batch size approaches the critical regime; without such a test, the extrapolation from the mixture of suboptimal runs to the optimal-batch-size scaling cannot be taken as established.
Authors: This is a fair criticism. While the current experiments already span a wide range of batch sizes (including some near the critical regime), we did not perform an explicit held-out stress test restricted to near-optimal batch sizes. In the revised manuscript we will add such a validation: we will reserve a subset of runs whose batch sizes are within a factor of two of the fitted critical batch size, refit the three-term law on the remaining data, and report the extrapolation error on the held-out near-optimal points. We will also include a regime-specific plot of residuals versus distance to the critical batch size. If the added test reveals systematic misspecification we will qualify the claims accordingly. revision: yes
Circularity Check
No significant circularity in the three-term scaling law derivation
full rationale
The paper proposes an empirical three-term functional form incorporating model size, steps, and batch size, fits its parameters to a collection of training runs (explicitly including suboptimal batch sizes), and then uses the resulting fit to recover the scaling of optimal batch size, which is reported to match prior independent empirical results on critical batch size. No quoted equation or section reduces the optimal-batch-size prediction to a quantity already fixed by the fitted parameters themselves, nor does any step rely on a self-citation chain or imported uniqueness theorem that would make the central claim tautological. The extrapolation claim is therefore an empirical assertion subject to external validation rather than a self-contained re-expression of the input data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
First-order methods in optimization , volume =
Beck, Amir , mrclass =. First-order methods in optimization , volume =. 2017 , z_doi =
2017
-
[2]
Power Lines: Scaling laws for weight decay and batch size in
Bergsma, Shane and Dey, Nolan and Gosal, Gurpreet and Gray, Gavia and Soboleva, Daria and Hestness, Joel , booktitle =. Power Lines: Scaling laws for weight decay and batch size in. 2025 , z_editor =
2025
-
[3]
arXiv , author =:2404.10102 , file =
Chinchilla Scaling: A replication attempt , year =. arXiv , author =:2404.10102 , file =
-
[4]
arXiv , author =:2409.19913 , file =
Scaling Optimal LR Across Token Horizons , year =. arXiv , author =:2409.19913 , file =
-
[5]
arXiv , author =:2405.13063 , file =
A Foundation Model for the Earth System , year =. arXiv , author =:2405.13063 , file =
-
[6]
Stochastic model-based minimization of weakly convex functions , volume =
Davis, Damek and Drusvyatskiy, Dmitriy , fjournal =. Stochastic model-based minimization of weakly convex functions , volume =. SIAM Journal on Optimization , mrclass =. 2019 , z_doi =
2019
-
[7]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Deep. 2024 , z_doi =. arXiv , author =:2401.02954 , file =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
arXiv , author =:2410.05838 , file =
Time Transfer: On Optimal Learning Rate and Batch Size In The Infinite Data Limit , year =. arXiv , author =:2410.05838 , file =
-
[9]
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations , volume =
H\". Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations , volume =. Advances in Neural Information Processing Systems , pages =. 2024 , z_editor =
2024
-
[10]
An empirical analysis of compute-optimal large language model training , volume =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Thomas and Noland, Eric and Millican, Katherine and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and...
2022
-
[11]
arXiv , author =:2603.21191 , file =
On the Role of Batch Size in Stochastic Conditional Gradient Methods , year =. arXiv , author =:2603.21191 , file =
-
[12]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , year =. arXiv , author =:2001.08361 , file =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
arXiv , author =:2503.12645 , file =
Understanding Gradient Orthogonalization for Deep Learning via Non-Euclidean Trust-Region Optimization , year =. arXiv , author =:2503.12645 , file =
-
[14]
arXiv , author =:2503.04715 , file =
Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining , year =. arXiv , author =:2503.04715 , file =
-
[15]
Margaret Li and Sneha Kudugunta and Luke Zettlemoyer , bibsource =. (. International Conference on Learning Representations , timestamp =. 2025 , z_publisher =
2025
-
[16]
Evolutionary-scale prediction of atomic-level protein structure with a language model , volume =
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan dos Santos Costa and Maryam Fazel-Zarandi and Tom Sercu and Salvatore Candido and Alexander Rives , eprint =. Evolutionary-scale prediction of atomic-level protein structure with a languag...
2023
-
[17]
An Empirical Model of Large-Batch Training
An Empirical Model of Large-Batch Training , year =. arXiv , author =:1812.06162 , file =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Resolving Discrepancies in Compute-Optimal Scaling of Language Models , volume =
Porian, Tomer and Wortsman, Mitchell and Jitsev, Jenia and Schmidt, Ludwig and Carmon, Yair , booktitle =. Resolving Discrepancies in Compute-Optimal Scaling of Language Models , volume =. 2024 , z_editor =
2024
-
[19]
International Conference on Learning Representations , title =
Dimitri von R. International Conference on Learning Representations , title =. 2026 , z_url =
2026
-
[20]
Topics in Stochastic Optimization: Learning with Implicit and Adaptive Steps , year =
Schaipp, Fabian , groups =. Topics in Stochastic Optimization: Learning with Implicit and Adaptive Steps , year =
-
[21]
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training , volume =
Schaipp, Fabian and H\". The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training , volume =. International Conference on Machine Learning , pages =. 2025 , z_editor =
2025
-
[22]
arXiv , author =:2408.13359 , file =
Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler , year =. arXiv , author =:2408.13359 , file =
-
[23]
arXiv , author =:2603.15958 , file =
Deriving Hyperparameter Scaling Laws via Modern Optimization Theory , year =. arXiv , author =:2603.15958 , file =
-
[24]
How to set
Wang, Xi and Aitchison, Laurence , booktitle =. How to set. 2025 , z_editor =
2025
-
[25]
Scaling Vision Transformers , year =
Zhai, Xiaohua and Kolesnikov, Alexander and Houlsby, Neil and Beyer, Lucas , booktitle =. Scaling Vision Transformers , year =
-
[26]
Foster and Sham M
Hanlin Zhang and Depen Morwani and Nikhil Vyas and Jingfeng Wu and Difan Zou and Udaya Ghai and Dean P. Foster and Sham M. Kakade , bibsource =. How Does Critical Batch Size Scale in Pre-training? , year =. International Conference on Learning Representations , timestamp =
-
[27]
arXiv , author =:2602.10300 , file =
Configuration-to-Performance Scaling Law with Neural Ansatz , year =. arXiv , author =:2602.10300 , file =
-
[28]
Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model , z_url =
Zhang, Guodong and Li, Lala and Nado, Zachary and Martens, James and Sachdeva, Sushant and Dahl, George and Shallue, Chris and Grosse, Roger B , booktitle =. Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model , z_url =
-
[29]
Measuring the Effects of Data Parallelism on Neural Network Training , author=. J. Mach. Learn. Res. , year=
-
[30]
2025 , z_month = may, archiveprefix =
Practical Efficiency of. 2025 , z_month = may, archiveprefix =. 2505.02222 , keywords =
-
[31]
Muon: An optimizer for hidden layers in neural networks , year =
Keller Jordan and Yuchen Jin and Vlado Boza and You Jiacheng and Franz Cesista and Laker Newhouse and Jeremy Bernstein , note =. Muon: An optimizer for hidden layers in neural networks , year =
-
[32]
Decoupled Weight Decay Regularization , year =
Ilya Loshchilov and Frank Hutter , booktitle =. Decoupled Weight Decay Regularization , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.