Rotation-Aware Point-Cloud Embeddings for Vision-Based In-Hand Reorientation
Pith reviewed 2026-06-26 13:52 UTC · model grok-4.3
The pith
A learned embedding makes Euclidean distance between point clouds equal the SO(3) geodesic rotation error, letting model-free RL policies reorient objects from raw current and goal clouds alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We close this gap by learning a rotation-aware point-cloud embedding whose Euclidean latent distance is calibrated to the SO(3) geodesic error between object orientations. The resulting representation turns current-goal comparison into a smooth control signal, allowing a model-free RL policy to act from current and goal point-cloud embeddings, proprioception, and centroid metadata, without object pose, relative pose, dense flow, or teacher-action supervision. In in-hand reorientation experiments, this interface matches privileged-state and distillation-based baselines while avoiding brittle test-time computation of structured pose or flow inputs. These results suggest that point-cloud goals
What carries the argument
The rotation-aware point-cloud embedding: a neural network trained so its output Euclidean distance equals the geodesic rotation error on SO(3) for any pair of object point clouds.
If this is right
- Model-free RL policies can solve in-hand reorientation directly from current and goal point clouds without any pose estimation or flow module at test time.
- The same embedding supplies a usable policy gradient signal that matches the performance of methods relying on privileged state or teacher distillation.
- Generic visual pretraining on point clouds is not enough, because it preserves shape but discards the rotation state required for goal comparison.
- Point-cloud goals become a practical interface once the representation itself carries the rotation geometry instead of external structure.
Where Pith is reading between the lines
- The same calibrated-distance idea could be tested on other rotation-heavy tasks such as peg insertion or lid opening by swapping the object class.
- If the embedding generalizes across object shapes, it would let a single policy handle families of objects without per-object pose frames.
- Replacing external pose solvers with an end-to-end learned metric reduces the number of brittle components that must be maintained at deployment.
Load-bearing premise
A neural network can be trained so that its latent Euclidean distance reliably equals the true SO(3) geodesic rotation error across arbitrary sampled point clouds of the object.
What would settle it
Train the embedding and then measure the correlation between its latent distances and actual rotation angles on a large held-out set of point-cloud pairs; if the correlation is near zero or the RL policy using the embedding fails to reach reorientation success rates above random, the central claim is false.
Figures



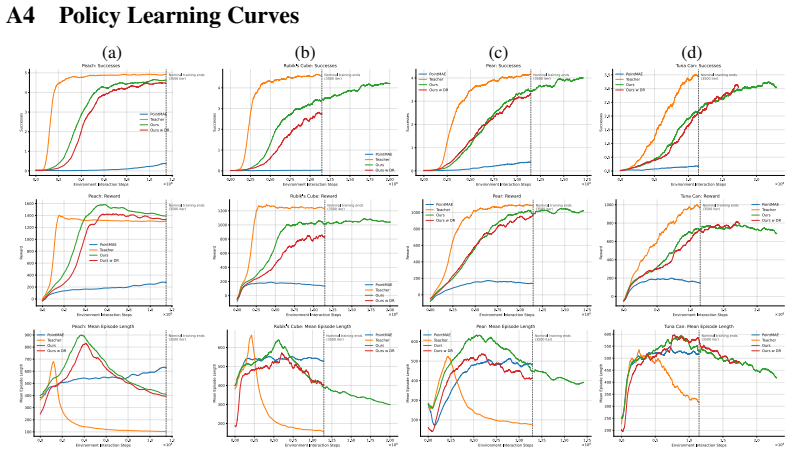
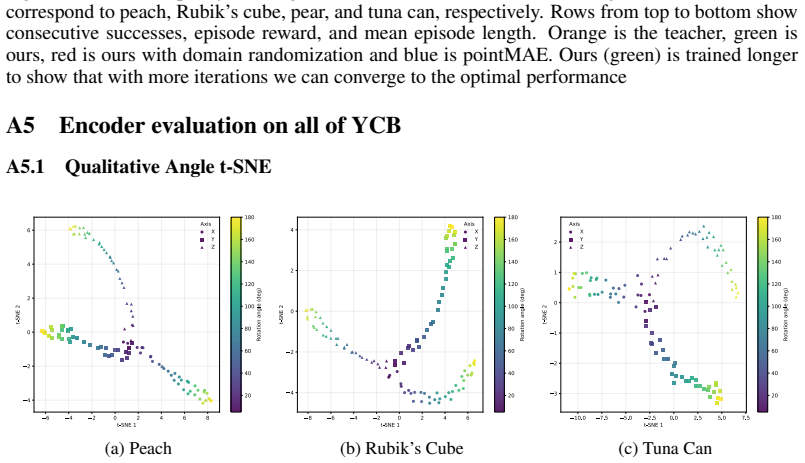
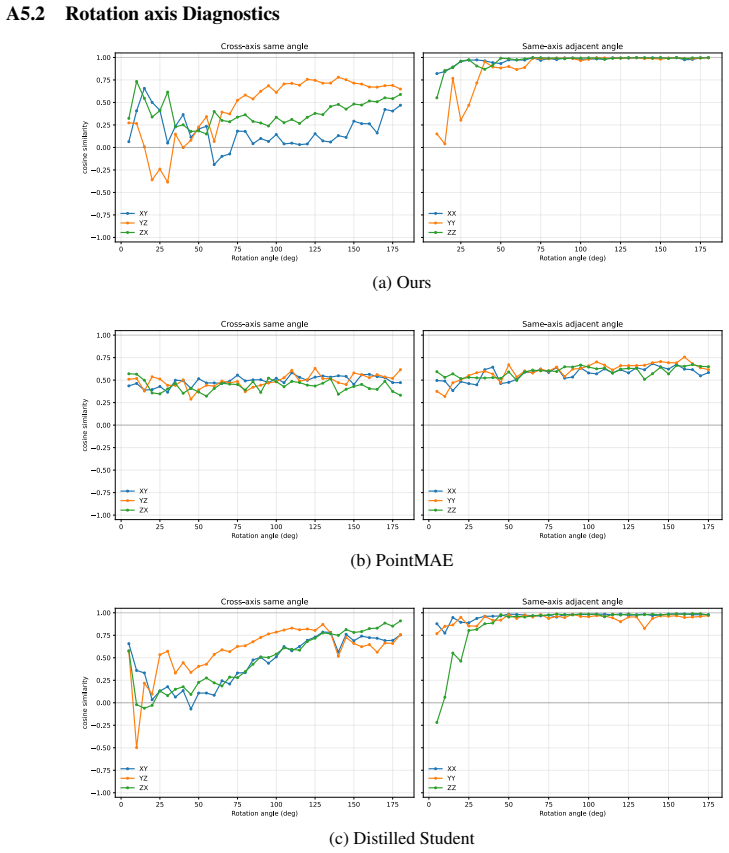
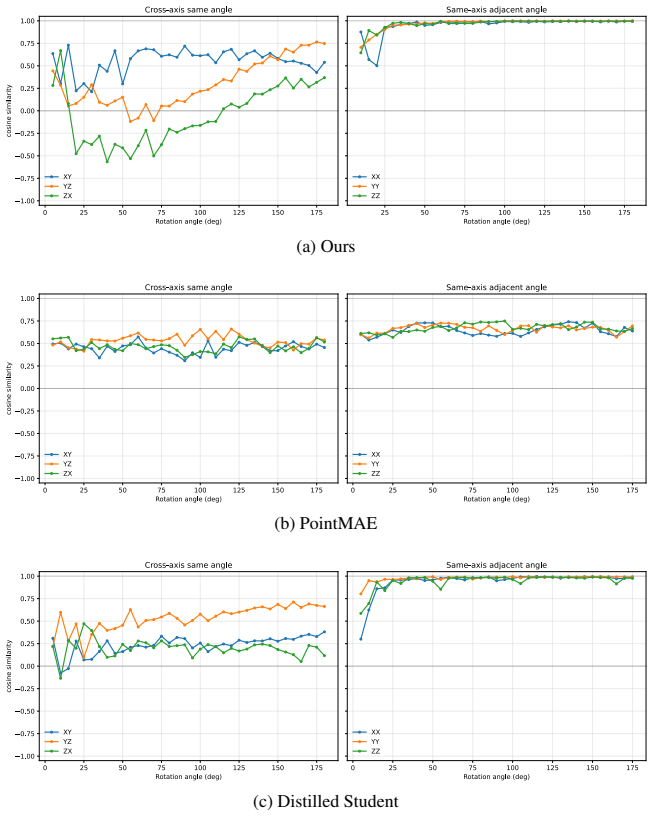
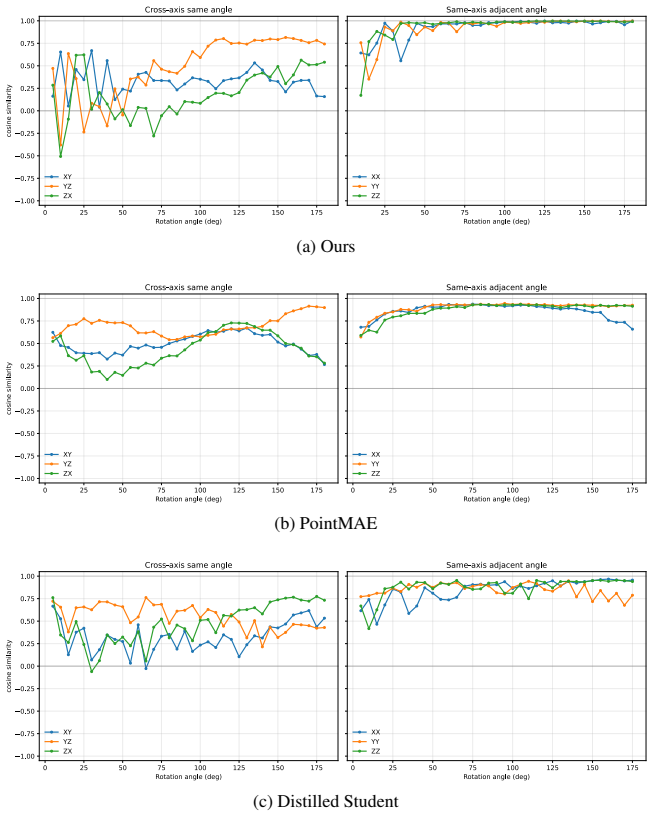
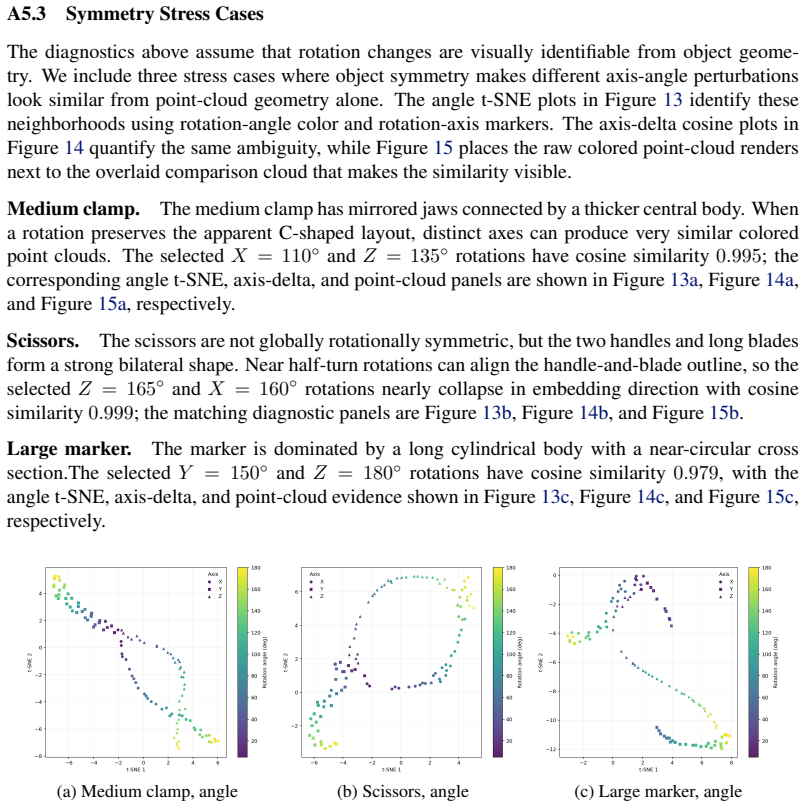
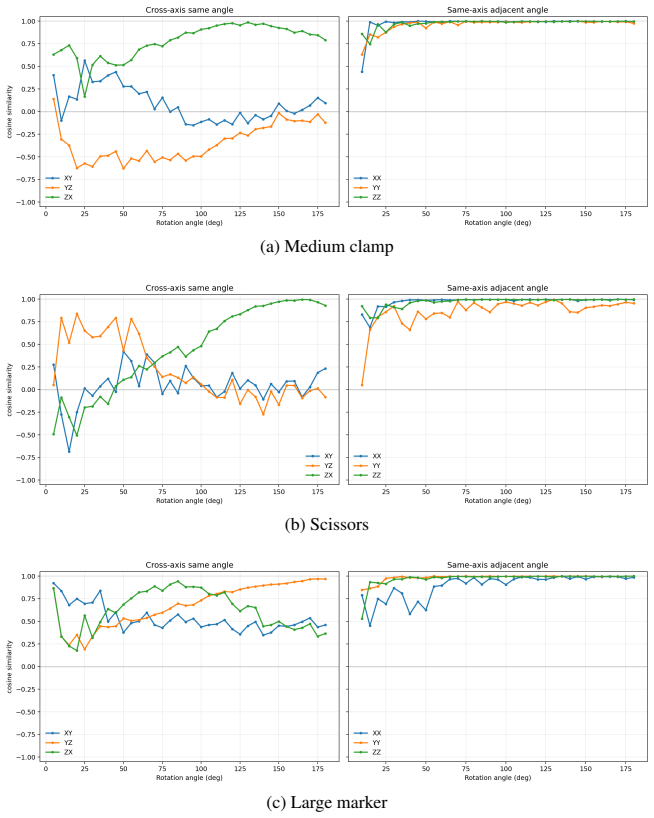

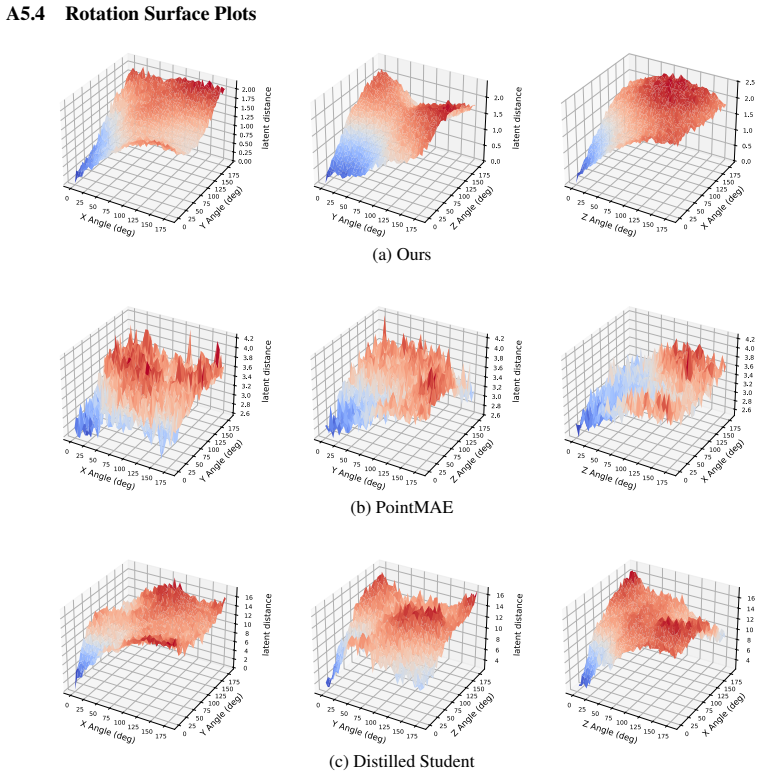
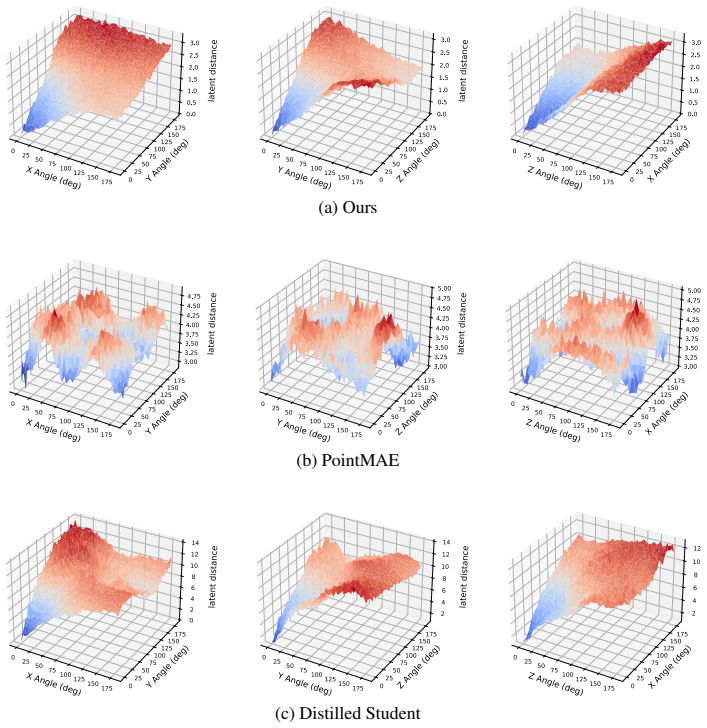
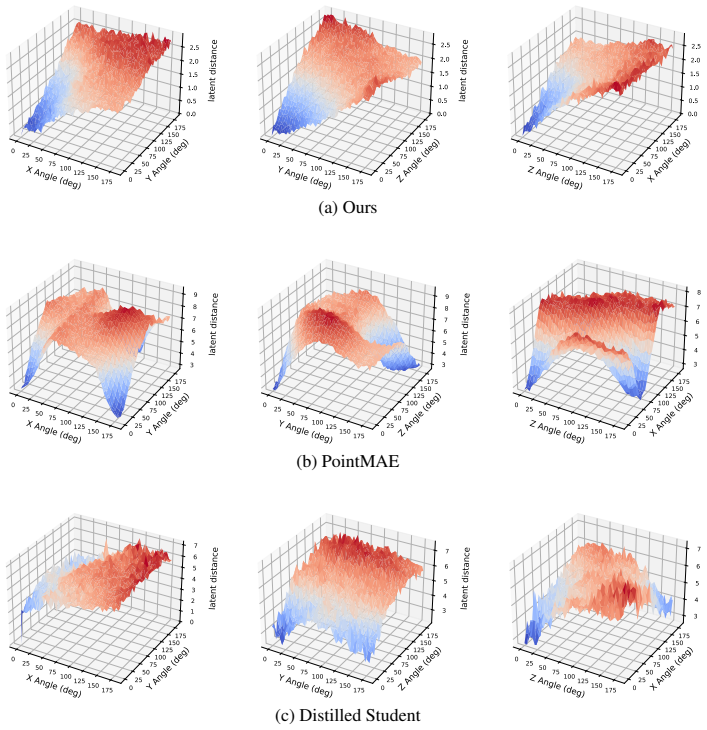
read the original abstract
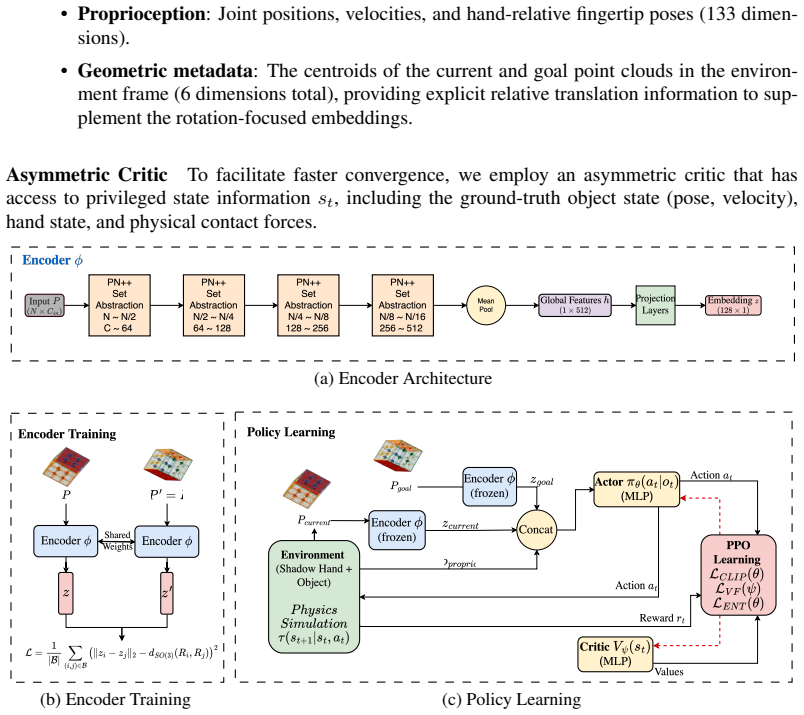
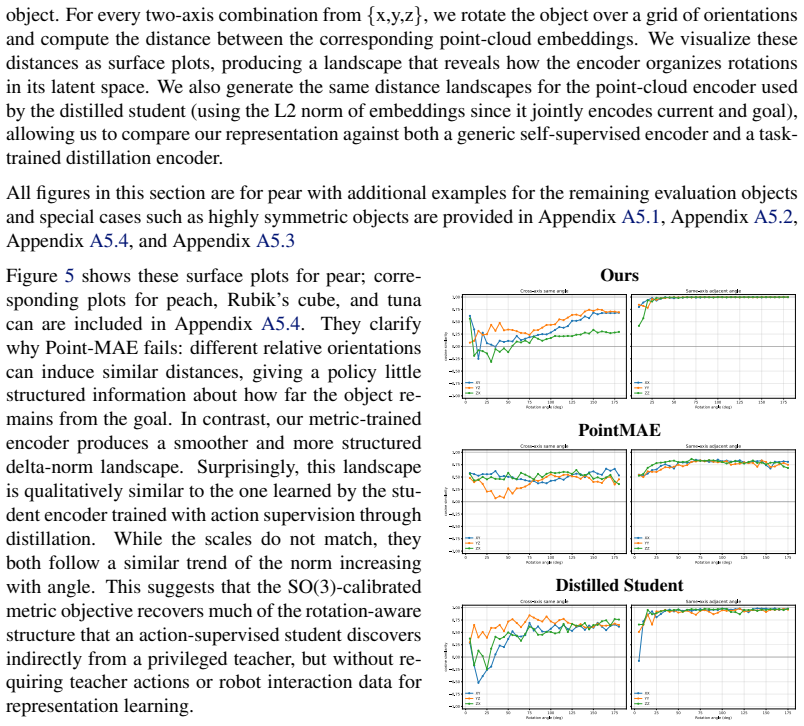
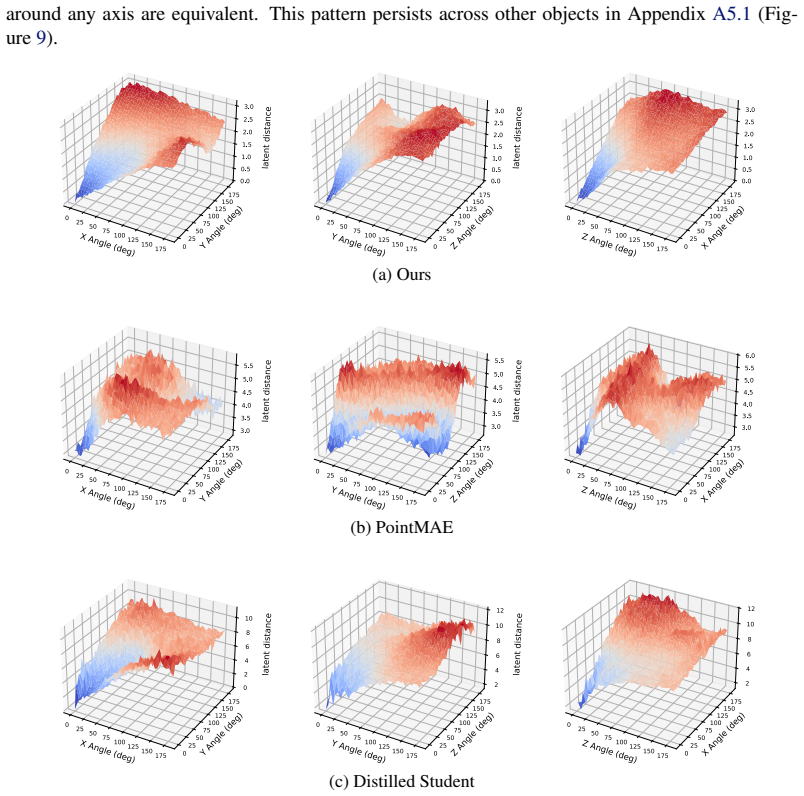
Point-cloud goals provide a direct way to specify dexterous in-hand reorientation: instead of defining an object-specific pose frame or estimating 6D pose at test time, the policy is given the desired 3D geometry of the object. Yet raw point-cloud goal conditioning is poorly conditioned for policy learning. Current and goal clouds are unordered, independently sampled, and often visibility-dependent, so their discrepancy entangles object rotation with permutation, resampling, and unstable correspondence structure. For this reason, prior point-cloud manipulation methods typically add structure outside the representation itself, such as explicit pose or relative-pose inputs, dense flow features, or distillation from privileged teachers. We close this gap by learning a rotation-aware point-cloud embedding whose Euclidean latent distance is calibrated to the SO(3) geodesic error between object orientations. The resulting representation turns current-goal comparison into a smooth control signal, allowing a model-free RL policy to act from current and goal point-cloud embeddings, proprioception, and centroid metadata, without object pose, relative pose, dense flow, or teacher-action supervision. In in-hand reorientation experiments, this interface matches privileged-state and distillation-based baselines while avoiding brittle test-time computation of structured pose or flow inputs. These results suggest that point-cloud goals become practical for this task when the representation, rather than an external module, encodes the task-relevant geometry of rotation. We also show evidence that generic visual point-cloud pretraining is insufficient for such a current-goal comparison because it discards the task-relevant state and preserves only shape features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to close a gap in vision-based in-hand reorientation by learning a rotation-aware point-cloud embedding f such that the Euclidean distance ||f(P) - f(Q)|| is calibrated to the SO(3) geodesic rotation error between object orientations. This calibrated representation supplies a smooth control signal for a model-free RL policy that takes current/goal embeddings, proprioception, and centroid metadata as input, without requiring object pose, relative pose, dense flow, or teacher-action supervision. Experiments on in-hand reorientation tasks show performance matching privileged-state and distillation baselines, while also demonstrating that generic point-cloud pretraining is insufficient because it discards task-relevant rotation state.
Significance. If the calibration result holds under independent sampling, the work would make point-cloud goals practical for dexterous manipulation by moving the necessary structure into the learned representation rather than external modules. The explicit demonstration that generic pretraining fails for current-goal comparison is a useful negative result that clarifies the requirements for task-specific embeddings.
major comments (1)
- [§3] §3 (distance-calibration loss): the central claim requires that ||f(P)-f(Q)|| equals the SO(3) geodesic even when P and Q are independently sampled point clouds with different visibility and point density. The skeptic concern is load-bearing: any residual permutation or density variance orthogonal to rotation would inject spurious components into the latent distance and undermine the claim that the embedding alone supplies a usable, smooth policy gradient without correspondence structure. The manuscript must either provide quantitative bounds on how well the task-specific loss overcomes sampling variance or show ablations that isolate this factor.
minor comments (1)
- The abstract states that the embedding 'turns current-goal comparison into a smooth control signal,' but the precise form of the RL reward or policy input that uses this distance should be stated explicitly in the methods for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify the robustness of the distance calibration. We address the concern about independent sampling variance below.
read point-by-point responses
-
Referee: [§3] §3 (distance-calibration loss): the central claim requires that ||f(P)-f(Q)|| equals the SO(3) geodesic even when P and Q are independently sampled point clouds with different visibility and point density. The skeptic concern is load-bearing: any residual permutation or density variance orthogonal to rotation would inject spurious components into the latent distance and undermine the claim that the embedding alone supplies a usable, smooth policy gradient without correspondence structure. The manuscript must either provide quantitative bounds on how well the task-specific loss overcomes sampling variance or show ablations that isolate this factor.
Authors: The embedding is trained precisely on pairs (P, Q) that are independently sampled from the object mesh at random orientations, with randomized point counts (500–2000), density variation, and partial visibility to simulate sensor conditions. The loss directly regresses the latent Euclidean distance to the SO(3) geodesic on these pairs. Experiments already evaluate calibration on held-out independently sampled test pairs and show strong correlation. To directly address the request, the revision will add (i) an ablation isolating sampling variance by comparing calibration error of the task-specific loss versus a generic point-cloud autoencoder (confirming the latter fails to calibrate under density/visibility changes) and (ii) quantitative bounds via mean absolute deviation |‖f(P)−f(Q)‖ − geodesic| stratified by point density and visibility level. revision: yes
Circularity Check
No circularity; empirical training result with no self-referential derivation
full rationale
The provided abstract and description contain no equations, no derivation chain, and no load-bearing self-citations. The central claim is an empirical statement that a neural embedding can be trained such that its Euclidean distance approximates SO(3) geodesic error; this is presented as the outcome of a distance-calibration loss rather than a mathematical reduction that equals its own inputs by construction. No fitted parameter is renamed as a prediction, no uniqueness theorem is invoked from prior self-work, and no ansatz is smuggled via citation. The paper is therefore self-contained as a standard empirical result evaluated against baselines, warranting a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
W. Zhou, B. Jiang, F. Yang, C. Paxton, and D. Held. Hacman: Learning hybrid actor-critic maps for 6d non-prehensile manipulation.arXiv preprint arXiv:2305.03942, 2023
arXiv 2023
-
[3]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects, 2024. URLhttps://arxiv.org/abs/2312.08344
arXiv 2024
-
[4]
Hodan, F
T. Hodan, F. Michel, E. Brachmann, W. Kehl, A. GlentBuch, D. Kraft, B. Drost, J. Vidal, S. Ihrke, X. Zabulis, et al. Bop: Benchmark for 6d object pose estimation. InProceedings of the European conference on computer vision (ECCV), pages 19–34, 2018
2018
-
[5]
T. Chen, M. Tippur, S. Wu, V . Kumar, E. Adelson, and P. Agrawal. Visual dexterity: In-hand reorientation of novel and complex object shapes.Science Robotics, 8(84):eadc9244, 2023
2023
-
[6]
T. Chen, J. Xu, and P. Agrawal. A system for general in-hand object re-orientation.Conference on Robot Learning, 2021
2021
-
[7]
Kaya and H
M. Kaya and H. S ¸. Bilge. Deep metric learning: A survey.Symmetry, 11(9):1066, 2019
2019
-
[8]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
2017
-
[9]
Bromley, I
J. Bromley, I. Guyon, Y . LeCun, E. S ¨ackinger, and R. Shah. Signature verification using a” siamese” time delay neural network.Advances in neural information processing systems, 6, 1993
1993
-
[10]
Calli, A
B. Calli, A. Singh, J. Bruce, A. Walsman, K. Konolige, S. Srinivasa, P. Abbeel, and A. M. Dol- lar. Yale-cmu-berkeley dataset for robotic manipulation research.The International Journal of Robotics Research, 36(3):261–268, 2017
2017
-
[11]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, H...
Pith/arXiv arXiv 2025
-
[12]
https://www.shadowrobot.com/dexterous-hand-series/
Shadow Dexterous Hand Series - Research and Development Tool — shadowrobot.com. https://www.shadowrobot.com/dexterous-hand-series/. [Accessed 27-05-2026]
2026
-
[13]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[14]
Szeliski.Computer vision: algorithms and applications
R. Szeliski.Computer vision: algorithms and applications. Springer Nature, 2022. 9
2022
-
[15]
[Accessed 28-05-2026]
Colored point cloud registration - Open3D primary (unknown) documentation — open3d.org.https://www.open3d.org/docs/latest/tutorial/pipelines/colored_ pointcloud_registration.html. [Accessed 28-05-2026]
2026
-
[16]
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
arXiv 2025
-
[17]
Y . Pang, W. Wang, F. E. Tay, W. Liu, Y . Tian, and L. Yuan. Masked autoencoders for point cloud self-supervised learning. InComputer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part II, pages 604–621. Springer, 2022
2022
-
[18]
Van der Maaten and G
L. Van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[19]
A. V . Nair, V . Pong, M. Dalal, S. Bahl, S. Lin, and S. Levine. Visual reinforcement learning with imagined goals. volume 31, 2018
2018
-
[20]
V . H. Pong, M. Dalal, S. Lin, A. Nair, S. Bahl, and S. Levine. Skew-fit: State-covering self- supervised reinforcement learning.arXiv preprint arXiv:1903.03698, 2019
arXiv 1903
-
[21]
Andrychowicz, F
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. Pieter Abbeel, and W. Zaremba. Hindsight experience replay. volume 30, 2017
2017
-
[22]
Z. Ren, K. Dong, Y . Zhou, Q. Liu, and J. Peng. Exploration via hindsight goal generation. volume 32, 2019
2019
-
[23]
Eysenbach, T
B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov. Contrastive learning as goal- conditioned reinforcement learning. volume 35, pages 35603–35620, 2022
2022
-
[24]
Mendonca, O
R. Mendonca, O. Rybkin, K. Daniilidis, D. Hafner, and D. Pathak. Discovering and achieving goals via world models. volume 34, pages 24379–24391, 2021
2021
-
[25]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE inter- national conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[26]
Ebert, S
F. Ebert, S. Dasari, A. X. Lee, S. Levine, and C. Finn. Robustness via retrying: Closed-loop robotic manipulation with self-supervised learning. InConference on robot learning, pages 983–993. PMLR, 2018
2018
-
[27]
A. Xie, F. Ebert, S. Levine, and C. Finn. Improvisation through physical understanding: Using novel objects as tools with visual foresight. 2019
2019
-
[28]
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welin- der, L. Weng, and W. Zaremba. Learning dexterous in-hand manipulation, 2019. URL https://arxiv.org/abs/1808.00177
Pith/arXiv arXiv 2019
-
[29]
Myers, A
V . Myers, A. W. He, K. Fang, H. R. Walke, P. Hansen-Estruch, C.-A. Cheng, M. Jalobeanu, A. Kolobov, A. Dragan, and S. Levine. Goal representations for instruction following: A semi-supervised language interface to control. pages 3894–3908, 2023
2023
-
[30]
S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y . Chebotar, D. Dwibedi, and D. Sadigh. Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823, 2024
Pith/arXiv arXiv 2024
-
[31]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[32]
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023. 10
Pith/arXiv arXiv 2023
-
[33]
S. Chen, R. Garcia, C. Schmid, and I. Laptev. Polarnet: 3d point clouds for language-guided robotic manipulation.arXiv preprint arXiv:2309.15596, 2023
arXiv 2023
-
[34]
Gervet, Z
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki. Act3d: 3d feature field transformers for multi-task robotic manipulation. InConference on Robot Learning (CoRL), 2023
2023
-
[35]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations.arXiv preprint arXiv:2402.10885, 2024
Pith/arXiv arXiv 2024
-
[36]
T.-W. Ke, N. Gkanatsios, J. Xu, and K. Fragkiadaki. Bi3d diffuser actor: 3d policy diffusion for bi-manual robot manipulation. InCoRL 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data, 2024
2024
-
[37]
J. Wan, X. Liu, and Y . Dong. Dexremoe: In-hand reorientation of general object via mixtures of experts.arXiv preprint arXiv:2508.01695, 2025
arXiv 2025
-
[38]
H. Zhu, Y . Wang, D. Huang, W. Ye, W. Ouyang, and T. He. Point cloud matters: Rethinking the impact of different observation spaces on robot learning.Advances in Neural Information Processing Systems, 37:77799–77830, 2024
2024
-
[39]
Bartsch, A
A. Bartsch, A. Car, C. Avra, and A. B. Farimani. Sculptdiff: Learning robotic clay sculpting from humans with goal conditioned diffusion policy. In2024 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), pages 7307–7314. IEEE, 2024. 11 Appendix A1 Evidence for Sim-to-Real Transfer Our experiments are implemented in IsaacLab with ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.