CrossFlow: One-Step Generation Across Latent and Pixel Spaces
Pith reviewed 2026-06-26 18:30 UTC · model grok-4.3
The pith
CrossFlow maps noisy latent inputs directly to pixel images in one step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
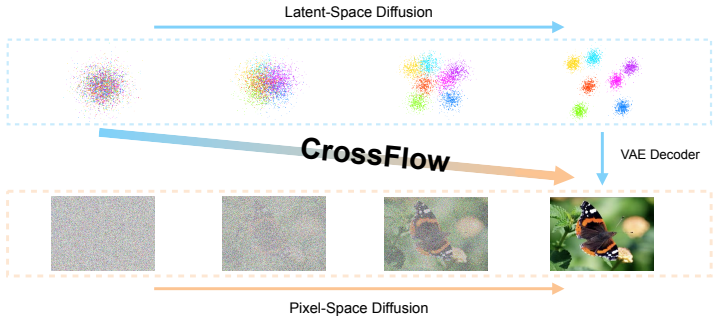
CrossFlow defines a velocity-free one-step objective in which the latent trajectory supplies the training path while the supervised target is a pixel-space image rather than a latent displacement, allowing a single network to generate directly from noisy latents to pixels and to replace the decoder in latent diffusion pipelines.
What carries the argument
velocity-free one-step objective that uses the latent trajectory for the path but supervises pixel-image prediction
If this is right
- One trained network replaces both the latent-space generator and the separate decoder at inference time.
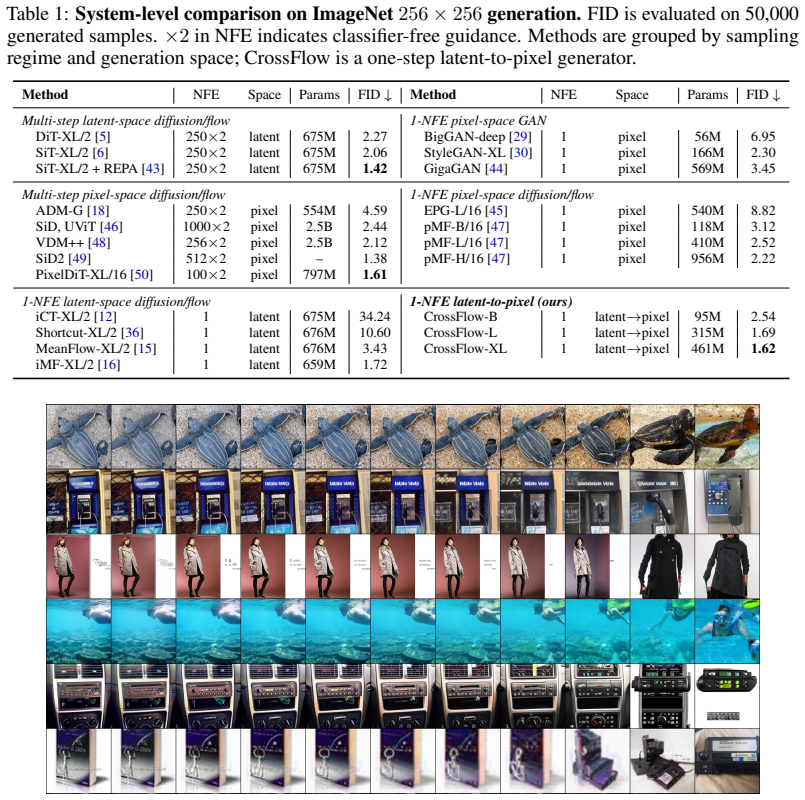
- Class-conditional ImageNet-1k 256 by 256 generation reaches 1.62 FID with a single function evaluation.
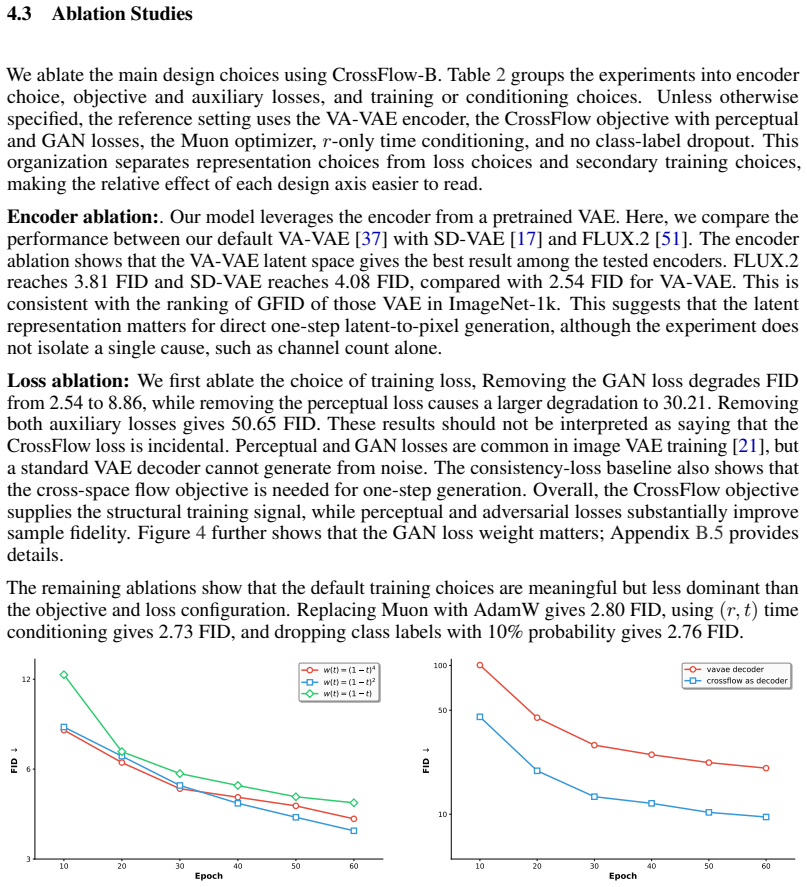
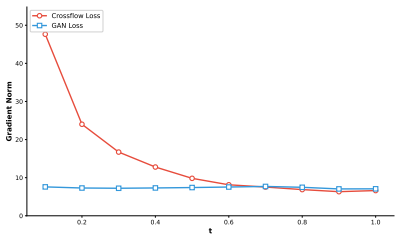
- Pixel perceptual and adversarial losses, when paired with the latent encoder, become essential for maintaining output fidelity.
- The same cross-space objective can be inserted into existing latent diffusion pipelines without retraining the upstream components.
Where Pith is reading between the lines
- Training pipelines could drop the separate decoder stage entirely, reducing the number of models that must be optimized and stored.
- Direct pixel-space supervision during flow training might allow perceptual metrics to influence the generative path more tightly than post-hoc decoding permits.
- The formulation could be tested on video or audio by swapping the latent encoder for a modality-specific compressor while keeping the pixel-level (or waveform-level) supervision.
Load-bearing premise
The latent trajectory can define the training path while the supervised target remains a full pixel image without introducing new mismatches that need extra correction terms.
What would settle it
Running a standard latent diffusion model plus its trained decoder on the same one-step budget and showing that its FID on ImageNet-1k 256 by 256 exceeds 1.62 while CrossFlow outputs exhibit visible artifacts or lower perceptual scores.
Figures


read the original abstract
Most diffusion and flow-matching generators define the prior, probability path, and prediction target in the same representation space. Latent diffusion improves efficiency by moving this path into an autoencoder latent space, but the final sample is still produced by a separately trained decoder. This separation creates a mismatch: the generator is optimized for latent-space prediction, while final quality depends on how the decoder handles generated latents that may differ from clean encoder outputs. We introduce CrossFlow, a cross-space flow formulation that maps noisy latent inputs directly to pixel-space images. The key technical step is a velocity-free one-step objective: the latent trajectory defines the training path, but the supervised prediction is an image rather than a latent displacement. This lets one model act both as a one-step latent-to-pixel generator and as a decoder replacement for latent diffusion pipelines. On class-conditional ImageNet-1k at $256\times256$, CrossFlow-XL achieves 1.62 FID with one function evaluation. Ablations show that the latent encoder and pixel-space perceptual and adversarial losses are important for fidelity. These results indicate that cross-space flow objectives can combine the efficiency of latent representations with direct pixel-space supervision, without requiring a separate decoder at inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CrossFlow, a cross-space flow model that maps noisy latent inputs directly to pixel-space images via a velocity-free one-step objective. The latent encoder trajectory defines the training path while the supervised target is a full pixel image rather than a latent displacement. This design is claimed to let a single model serve as both a one-step latent-to-pixel generator and a decoder replacement for latent diffusion pipelines. On class-conditional ImageNet-1k at 256×256, CrossFlow-XL reports 1.62 FID with one function evaluation; ablations indicate that the latent encoder and pixel-space perceptual/adversarial losses are important.
Significance. If the alignment between training and inference latent distributions holds without additional correction terms, the approach would combine latent-space efficiency with direct pixel supervision and eliminate the separate decoder stage, which is a meaningful simplification for generative pipelines. The reported one-step FID is competitive and the dual-use capability would be a clear strength if demonstrated rigorously.
major comments (1)
- [Abstract / §3] Abstract and §3 (method): the velocity-free one-step objective trains on paths defined by the latent encoder but supervises directly on pixel images. For the model to function as a decoder replacement at inference, generated latents must lie on the same distribution as the encoder outputs used during training. No derivation, alignment proof, or quantitative analysis is provided showing why this cross-space mapping preserves the required distribution without introducing mismatches that would necessitate correction terms or multi-step refinement—the central claim of the paper.
minor comments (2)
- [Results] The abstract reports an FID value and ablation importance but provides no error bars, full experimental protocol, training details, or comparison tables; these should be added to the results section for reproducibility.
- [§3] Notation for the velocity-free objective and the cross-space mapping should be formalized with explicit equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and outline revisions to improve clarity on the distribution alignment aspect of the method.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the velocity-free one-step objective trains on paths defined by the latent encoder but supervises directly on pixel images. For the model to function as a decoder replacement at inference, generated latents must lie on the same distribution as the encoder outputs used during training. No derivation, alignment proof, or quantitative analysis is provided showing why this cross-space mapping preserves the required distribution without introducing mismatches that would necessitate correction terms or multi-step refinement—the central claim of the paper.
Authors: We agree that the manuscript provides no formal derivation or theoretical proof of distribution alignment between training and inference latents. The work is primarily empirical: the velocity-free objective uses the encoder trajectory to define the input noise path while supervising on pixel targets, and the reported results (1.62 FID in one step) demonstrate that the trained model produces high-quality outputs when applied to latents drawn from the same encoder distribution. We do not claim a general guarantee that mismatches are always absent; rather, the design and pixel-space losses are intended to make the mapping robust in practice. To address the comment, we will revise §3 to add an explicit discussion of this assumption and include new quantitative analysis (e.g., measuring latent-space statistics or reconstruction error on generated vs. encoder latents) in the experiments section. This revision will clarify the empirical basis without overstating theoretical guarantees. revision: yes
Circularity Check
No circularity: cross-space objective is independently defined
full rationale
The paper introduces a velocity-free one-step objective where the training path is defined by the latent encoder trajectory but the supervised target is a pixel image. This formulation is presented as a new technical step without any equations or claims that reduce the reported FID result or the model's dual role to a fitted parameter, self-citation chain, or input by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no renaming of known results occurs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, 2020
2020
-
[2]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inICLR, 2021
2021
-
[3]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”ICLR, 2023
2023
-
[4]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, and M. Nickel, “Flow matching for generative modeling,”ICLR, 2023
2023
-
[5]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,”ICCV, 2023
2023
-
[6]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers,
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie, “Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers,”ECCV, 2024
2024
-
[7]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. K. andreas Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, and et al, “Scaling rectified flow transformers for high-resolution image synthesis,”ICML, 2024
2024
-
[8]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
2024
-
[9]
Sana: Efficient high-resolution image synthesis with linear diffusion transformers,
E. Xie, J. Chen, J. Chen, H. Cai, Y . Lin, Z. Zhang, M. Li, Y . Lu, and S. Han, “Sana: Efficient high-resolution image synthesis with linear diffusion transformers,”ICLR, 2025
2025
-
[10]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
2021
-
[11]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,”ICML, 2023
2023
-
[12]
Improved techniques for training consistency models,
Y . Song and P. Dhariwal, “Improved techniques for training consistency models,”ICML, 2024
2024
-
[13]
Progressive distillation for fast sampling of diffusion models,
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,”ICLR, 2022
2022
-
[14]
One-step diffusion with distribution matching distillation,
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park, “One-step diffusion with distribution matching distillation,”CVPR, 2024
2024
-
[15]
Mean flows for one-step generative modeling,
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,” NeurIPS, 2025
2025
-
[16]
Improved mean flows: On the challenges of fastforward generative models, 2025b,
Z. Geng, Y . Lu, Z. Wu, E. Shechtman, J. Z. Kolter, and K. He, “Improved mean flows: On the challenges of fastforward generative models, 2025b,” 2026
2026
-
[17]
High-resolution image synthesis with latent diffusion models,
R. R. andreas Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,”CVPR, 2022
2022
-
[18]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Q. Nichol, “Diffusion models beat gans on image synthesis,” inNeurIPS, 2021
2021
-
[19]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. L. andreas Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”ICLR, 2023
2023
-
[20]
Neural discrete representation learning,
A. V . D. Oord, O. Vinyals, and et al, “Neural discrete representation learning,”NeurIPS, 2017
2017
-
[21]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,”CVPR, 2021
2021
-
[22]
Deep compression autoencoder for efficient high-resolution diffusion models,
J. Chen, H. Cai, J. Chen, E. Xie, S. Yang, H. Tang, M. Li, Y . Lu, and S. Han, “Deep compression autoencoder for efficient high-resolution diffusion models,”ICLR, 2025
2025
-
[23]
Score-based generative modeling in latent space,
A. Vahdat, K. Kreis, and J. Kautz, “Score-based generative modeling in latent space,” 2021
2021
-
[24]
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers,
X. Leng, J. Singh, Y . Hou, Z. Xing, S. Xie, and L. Zheng, “Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers,”ICCV, 2025
2025
-
[25]
Diffusion as self-distillation: End-to-end latent diffusion in one model,
X. Wang and M. Zhang, “Diffusion as self-distillation: End-to-end latent diffusion in one model,”CoRR, vol. abs/2511.14716, 2025
arXiv 2025
-
[26]
Unified latents (ul): How to train your latents,
J. Heek, E. Hoogeboom, T. Mensink, and T. Salimans, “Unified latents (ul): How to train your latents,” arXiv:2602.17270, 2026. 11
arXiv 2026
-
[27]
End-to-end training for unified tokenization and latent denoising,
S. Duggal, X. Bai, Z. Wu, R. Zhang, E. Shechtman, A. Torralba, P. Isola, and W. T. Freeman, “End-to-end training for unified tokenization and latent denoising,”CoRR, vol. abs/2603.22283, 2026
arXiv 2026
-
[28]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y . Bengio, “Generative adversarial nets,”NeurIPS, 2014
2014
-
[29]
Large scale GAN training for high fidelity natural image synthesis,
A. Brock, J. Donahue, and K. Simonyan, “Large scale GAN training for high fidelity natural image synthesis,” inICLR, 2019
2019
-
[30]
StyleGAN-XL: Scaling StyleGAN to large diverse datasets,
A. Sauer, K. Schwarz, and A. Geiger, “StyleGAN-XL: Scaling StyleGAN to large diverse datasets,” in SIGGRAPH, 2022
2022
-
[31]
Variational inference with normalizing flows,
D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,”ICML, 2015
2015
-
[32]
Density estimation using real nvp,
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real nvp,”ICLR, 2017
2017
-
[33]
Augmented normalizing flows: Bridging the gap between generative flows and latent variable models,
C. Huang, L. Dinh, and A. C. Courville, “Augmented normalizing flows: Bridging the gap between generative flows and latent variable models,”ICML, 2020
2020
-
[34]
Lifting architectural constraints of injective flows,
P. Sorrenson, F. Roth, K. Dreczkowski, V . Stimper, and F. Noé, “Lifting architectural constraints of injective flows,”ICLR, 2024
2024
-
[35]
Consistency trajectory models: Learning probability flow ODE trajectory of diffusion,
D. Kim, C. Lai, W. Liao, N. Murata, Y . Takida, T. Uesaka, Y . He, Y . Mitsufuji, and S. Ermon, “Consistency trajectory models: Learning probability flow ODE trajectory of diffusion,” inICLR, 2024
2024
-
[36]
One step diffusion via shortcut models,
K. Frans, D. Hafner, S. Levine, and P. Abbeel, “One step diffusion via shortcut models,” inICLR, 2025
2025
-
[37]
Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models,
J. Yao, B. Yang, and X. Wang, “Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models,” inCVPR, 2025
2025
-
[38]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. IEEE, 2009, pp. 248–255
2009
-
[39]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[40]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
2021
-
[41]
Muon: An optimizer for hidden layers in neural networks,
K. Jordan, Y . Jin, V . Boza, Y . Jiacheng, F. Cesista, L. Newhouse, and J. Bernstein, “Muon: An optimizer for hidden layers in neural networks,” 2024. [Online]. Available: https://kellerjordan.github.io/posts/muon/
2024
-
[42]
Muon is scalable for LLM training,
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yan, Y . Chen, H. Zheng, Y . Liu, S. Liu, B. Yin, W. He, H. Zhu, Y . Wang, J. Wang, M. Dong, Z. Zhang, Y . Kang, H. Zhang, X. Xu, Y . Zhang, Y . Wu, X. Zhou, and Z. Yang, “Muon is scalable for LLM training,”Arxiv abs/2502.16982, 2025
Pith/arXiv arXiv 2025
-
[43]
Representation alignment for generation: Training diffusion transformers is easier than you think,
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Representation alignment for generation: Training diffusion transformers is easier than you think,”ICLR, 2025
2025
-
[44]
Scaling up GANs for text-to-image synthesis,
M. Kang, J.-Y . Zhu, R. Zhang, J. Park, E. Shechtman, S. Paris, and T. Park, “Scaling up GANs for text-to-image synthesis,” inCVPR, 2023
2023
-
[45]
There is no V AE: End-to-end pixel-space generative modeling via self-supervised pre-training,
J. Lei, K. Liu, J. Berner, H. Yu, H. Zheng, J. Wu, and X. Chu, “There is no V AE: End-to-end pixel-space generative modeling via self-supervised pre-training,” inICLR, 2026
2026
-
[46]
Simple diffusion: End-to-end diffusion for high resolution images,
E. Hoogeboom, J. Heek, and T. Salimans, “Simple diffusion: End-to-end diffusion for high resolution images,” inICML, 2023
2023
-
[47]
One-step latent-free image generation with pixel mean flows,
Y . Lu, S. Lu, Q. Sun, H. Zhao, Z. Jiang, X. Wang, T. Li, Z. Geng, and K. He, “One-step latent-free image generation with pixel mean flows,”arXiv:2601.22158, 2026
Pith/arXiv arXiv 2026
-
[48]
Understanding diffusion objectives as the ELBO with simple data augmentation,
D. P. Kingma and R. Gao, “Understanding diffusion objectives as the ELBO with simple data augmentation,” inNeurIPS, 2023
2023
-
[49]
Simpler diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion,
E. Hoogeboom, T. Mensink, J. Heek, K. Lamerigts, R. Gao, and T. Salimans, “Simpler diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion,” inCVPR, 2025. 12
2025
-
[50]
PixelDiT: Pixel diffusion transformers for image generation,
Y . Yu, W. Xiong, W. Nie, Y . Sheng, S. Liu, and J. Luo, “PixelDiT: Pixel diffusion transformers for image generation,”arXiv preprint arXiv:2511.20645, 2025
Pith/arXiv arXiv 2025
-
[51]
FLUX.2: Frontier Visual Intelligence,
B. F. Labs, “FLUX.2: Frontier Visual Intelligence,” https://bfl.ai/blog/flux-2, 2025
2025
-
[52]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in NeurIPS, 2019
2019
-
[53]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of-the-art natural language processing,” inEMNLP, 2020
2020
-
[54]
Pytorch image models,
R. Wightman, “Pytorch image models,” 2019
2019
-
[55]
High-fidelity performance metrics for generative models in pytorch,
A. Obukhov, M. Seitzer, P.-W. Wu, S. Zhydenko, J. Kyl, and E. Y .-J. Lin, “High-fidelity performance metrics for generative models in pytorch,” 2020. [Online]. Available: https://github.com/toshas/torch-fidelity
2020
-
[56]
Is noise conditioning necessary for denoising generative models?
Q. Sun, Z. Jiang, H. Zhao, and K. He, “Is noise conditioning necessary for denoising generative models?” inICML, 2025
2025
-
[57]
Diffusion transformers with representation autoencoders,
B. Zheng, N. Ma, S. Tong, and S. Xie, “Diffusion transformers with representation autoencoders,”ICLR, 2026
2026
-
[58]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. E. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. Jégou, P. Labatut, and P. Bojanowski, “Dinov3,”Arxiv abs/2508.10104, 2025. 13...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.