OR-Action: Multi-Role Video Understanding with Fine-Grained Actions
Pith reviewed 2026-06-27 07:29 UTC · model grok-4.3
The pith
A vision-only temporal model outperforms graph-based methods on fine-grained multi-role operating room actions using full egocentric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a vision-only temporal model, supplied with complete egocentric video, models the temporal dynamics of multi-role actions more effectively than relational graph-based predictors, and that a multi-to-single-view feature alignment strategy transfers this advantage to single-view settings on the introduced benchmark.
What carries the argument
Vision-only temporal model for action recognition, paired with multi-to-single-view feature alignment strategy that transfers performance gains from full egocentric input to single-view recognition.
If this is right
- Improved temporal modeling supports workflow-aware assistance systems in operating rooms.
- Single-view performance gains reduce the practical requirement for simultaneous multi-camera egocentric recording.
- Benchmark enables direct temporal evaluation of OR understanding methods beyond frame-wise scene graph metrics.
- Multi-role action recognition becomes feasible in cluttered, occluded environments where graph relations alone are insufficient.
Where Pith is reading between the lines
- The alignment technique could extend to other multi-camera video domains that mix egocentric and exocentric views.
- The benchmark construction method may apply to other environments where scene graphs already exist but action labels do not.
- Single-view improvements suggest the model learns view-invariant temporal features that generalize beyond the training camera setup.
Load-bearing premise
Dense action segments distilled from ground-truth scene graph state changes produce an accurate fine-grained multi-role action taxonomy without substantial labeling noise or temporal misalignment.
What would settle it
A side-by-side comparison in which independent human annotators label the same video clips and produce action boundaries or role assignments that differ substantially in timing or content from the distilled segments.
Figures
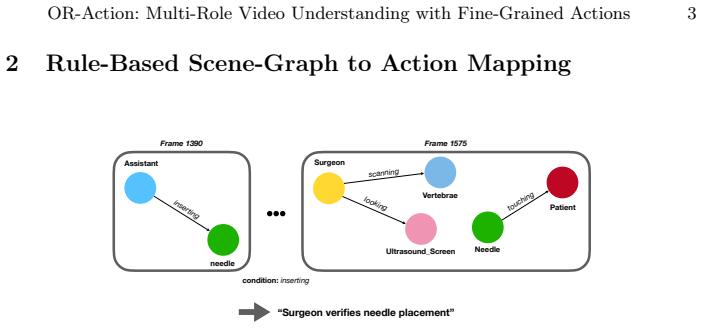
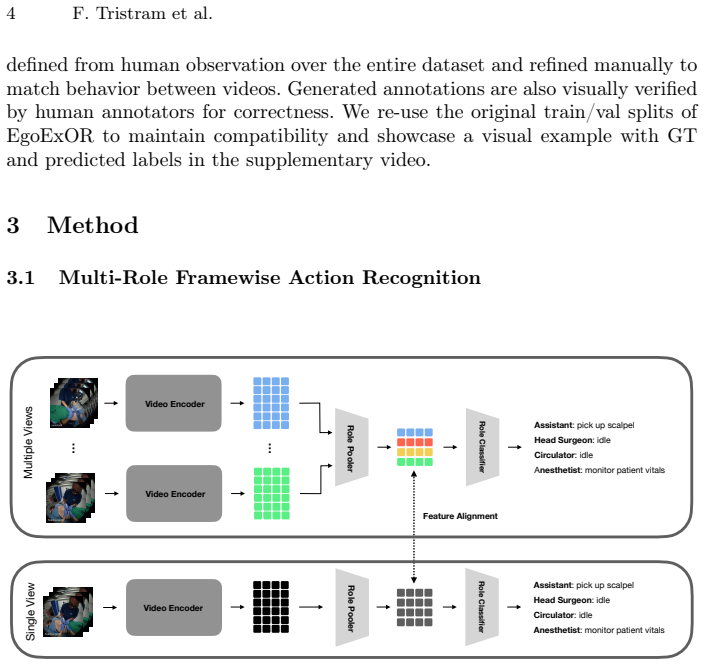

read the original abstract
Fine-grained understanding of operating room (OR) activity could enable workflow-aware assistance, yet remains difficult due to clutter, occlusions, and limited sensing. The prevailing approach to model this environment is scene graphs as an interpretable representation of OR interactions. Converting their frame-wise relational predictions into temporally extended, fine-grained actions however, is challenging without explicit temporal modeling. To enable a principled temporal evaluation of current OR understanding methods, we introduce the first action-centric benchmark built on a publicly available ego-exocentric OR dataset by defining a fine-grained, multi-role action taxonomy and generating dense action segments via distillation from ground-truth scene graph state changes. Experiments on this benchmark show that current scene graph prediction methods struggle to model temporal structure, even when adding explicit modeling through Graph Neural Networks. We therefore introduce a vision-only temporal model that outperforms graph-based methods significantly when using all available egocentric video as input. Building on this model we also introduce a novel multi- to single-view feature alignment strategy that improves single-view performance on multi-role action recognition, mitigating the need for extensive egocentric video capture. Benchmark and code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OR-Action, the first action-centric benchmark for fine-grained multi-role video understanding in operating rooms, constructed from a public ego-exocentric dataset. It defines a multi-role action taxonomy and generates dense action segments via distillation from ground-truth scene graph state changes. Experiments demonstrate that scene graph prediction methods (even augmented with GNNs) struggle to capture temporal structure. The authors propose a vision-only temporal model that significantly outperforms graph-based baselines when using full egocentric video input, along with a multi- to single-view feature alignment strategy that boosts single-view multi-role action recognition performance, reducing reliance on extensive egocentric capture. The benchmark and code are to be released.
Significance. If the distillation process yields a reliable benchmark and the reported outperformance holds under scrutiny, this would supply a much-needed temporal evaluation framework for OR activity understanding and highlight practical advantages of vision-only models. The public release of the benchmark and code strengthens reproducibility and utility for the community. The work addresses real challenges in cluttered, occluded OR environments but its impact depends on validation of the core benchmark construction step.
major comments (2)
- [Abstract, §3] Abstract and §3 (Benchmark Construction): The central claim that distillation from ground-truth scene graph state changes produces an 'accurate' fine-grained multi-role action taxonomy and dense segments is load-bearing for all downstream results, yet no fidelity metrics, temporal alignment error analysis, role-assignment validation, or human evaluation of the generated segments are described. This directly affects the reliability of comparisons showing the vision-only model outperforming graph-based methods.
- [§4, results tables] §4 (Experiments) and Table 1 (or equivalent results table): The assertion of 'significant' outperformance by the vision-only temporal model lacks reported error bars, statistical tests, dataset split statistics, or ablation on the distillation noise level, making it impossible to assess whether the gains are robust or sensitive to benchmark construction artifacts.
minor comments (2)
- [§3, §5] Notation for 'multi-role' vs. 'multi-view' is used interchangeably in places; clarify the distinction in the taxonomy definition and alignment strategy description.
- [Abstract] The abstract states benchmark and code 'will be released upon acceptance' but provides no link or placeholder; include a footnote or repository URL in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of benchmark reliability and experimental rigor. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Benchmark Construction): The central claim that distillation from ground-truth scene graph state changes produces an 'accurate' fine-grained multi-role action taxonomy and dense segments is load-bearing for all downstream results, yet no fidelity metrics, temporal alignment error analysis, role-assignment validation, or human evaluation of the generated segments are described. This directly affects the reliability of comparisons showing the vision-only model outperforming graph-based methods.
Authors: We agree that explicit validation of the distillation process would strengthen the manuscript. The segments are generated deterministically from ground-truth scene graph state changes in the public dataset, providing a direct mapping without additional inference noise. However, we acknowledge the absence of reported fidelity metrics or human validation in the current version. In the revision we will expand §3 with a quantitative description of the distillation procedure, including temporal alignment statistics between state changes and action segments, and add a limited human evaluation of segment quality on a subset of the data. revision: yes
-
Referee: [§4, results tables] §4 (Experiments) and Table 1 (or equivalent results table): The assertion of 'significant' outperformance by the vision-only temporal model lacks reported error bars, statistical tests, dataset split statistics, or ablation on the distillation noise level, making it impossible to assess whether the gains are robust or sensitive to benchmark construction artifacts.
Authors: We agree that the current results presentation would benefit from additional statistical detail. The reported numbers reflect single-run performance on the fixed train/val/test splits of the underlying public dataset. In the revised manuscript we will add dataset split statistics, report standard deviations where multiple random seeds are feasible, include a basic statistical significance test between the vision-only model and the strongest graph baseline, and provide a short discussion of sensitivity to potential noise in the distilled labels. revision: yes
Circularity Check
No circularity; benchmark and model are independently constructed from external ground-truth
full rationale
The paper defines a new action taxonomy and benchmark by distilling dense segments from ground-truth scene graph state changes in a publicly available external dataset, then evaluates prior scene-graph methods and introduces a vision-only temporal model plus a multi-to-single-view alignment strategy. No derivation step reduces by construction to fitted parameters, self-defined quantities, or load-bearing self-citations; the ground-truth inputs are independent of the proposed model, and performance claims rest on direct comparison rather than tautological renaming or prediction-from-fit. The central results therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scene graph state changes can be distilled into accurate dense fine-grained multi-role action segments
invented entities (2)
-
Multi-role action taxonomy
no independent evidence
-
Multi- to single-view feature alignment strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.09985 (2025)
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
Pith/arXiv arXiv 2025
-
[2]
Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization 11(4), 1113–1121 (2023)
Bastian, L., Czempiel, T., Heiliger, C., Karcz, K., Eck, U., Busam, B., Navab, N.: Know your sensors—a modality study for surgical action classification. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization 11(4), 1113–1121 (2023)
2023
-
[3]
In: Proceedings of the European conference on computer vision (ECCV)
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., et al.: Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European conference on computer vision (ECCV). pp. 720–736 (2018)
2018
-
[4]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 18995–19012 (2022)
2022
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024)
2024
-
[6]
arXiv preprint arXiv:2012.12453 (2020)
Hong, W.Y., Kao, C.L., Kuo, Y.H., Wang, J.R., Chang, W.L., Shih, C.S.: Cholec- seg8k: a semantic segmentation dataset for laparoscopic cholecystectomy based on cholec80. arXiv preprint arXiv:2012.12453 (2020)
arXiv 2012
-
[7]
Ji, J., Krishna, R., Fei-Fei, L., Niebles, J.C.: Action genome: Actions as composi- tionsofspatio-temporalscenegraphs.In:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition. pp. 10236–10247 (2020)
2020
-
[8]
Nature Biomedical Engineering1(9), 691–696 (2017)
Maier-Hein, L., Vedula, S.S., Speidel, S., Navab, N., Kikinis, R., Park, A., Eisen- mann, M., Feussner, H., Forestier, G., Giannarou, S., et al.: Surgical data science for next-generation interventions. Nature Biomedical Engineering1(9), 691–696 (2017)
2017
-
[9]
arXiv preprint arXiv:2505.24287 (2025) 10 F
Özsoy, E., Mamur, A., Tristram, F., Pellegrini, C., Wysocki, M., Busam, B., Navab, N.: Egoexor: An ego-exo-centric operating room dataset for surgical activity un- derstanding. arXiv preprint arXiv:2505.24287 (2025) 10 F. Tristram et al
arXiv 2025
-
[10]
In: International conference on med- ical image computing and computer-assisted intervention
Özsoy, E., Örnek, E.P., Eck, U., Czempiel, T., Tombari, F., Navab, N.: 4d-or: Se- mantic scene graphs for or domain modeling. In: International conference on med- ical image computing and computer-assisted intervention. pp. 475–485. Springer (2022)
2022
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Özsoy, E., Pellegrini, C., Czempiel, T., Tristram, F., Yuan, K., Bani-Harouni, D., Eck, U., Busam, B., Keicher, M., Navab, N.: Mm-or: A large multimodal operating room dataset for semantic understanding of high-intensity surgical environments. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19378–19389 (2025)
2025
-
[12]
arXiv preprint arXiv:2511.06549 (2025)
Rueckert, T., Maerkl, R., Rauber, D., Klausmann, L., Gutbrod, M., Rueckert, D., Feussner, H., Wilhelm, D., Palm, C.: Video dataset for surgical phase, key- point, and instrument recognition in laparoscopic surgery (phakir). arXiv preprint arXiv:2511.06549 (2025)
arXiv 2025
-
[13]
In: International confer- ence on medical image computing and computer-assisted intervention
Schmidt, A., Sharghi, A., Haugerud, H., Oh, D., Mohareri, O.: Multi-view surgical video action detection via mixed global view attention. In: International confer- ence on medical image computing and computer-assisted intervention. pp. 626–635. Springer (2021)
2021
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21096–21106 (2022)
2022
-
[15]
arXiv preprint arXiv:1808.08180 (2018)
Srivastav, V., Issenhuth, T., Kadkhodamohammadi, A., de Mathelin, M., Gangi, A., Padoy, N.: Mvor: A multi-view rgb-d operating room dataset for 2d and 3d human pose estimation. arXiv preprint arXiv:1808.08180 (2018)
arXiv 2018
-
[16]
IEEE transactions on medical imaging36(1), 86–97 (2016)
Twinanda, A.P., Shehata, S., Mutter, D., Marescaux, J., De Mathelin, M., Padoy, N.: Endonet: a deep architecture for recognition tasks on laparoscopic videos. IEEE transactions on medical imaging36(1), 86–97 (2016)
2016
-
[17]
Medical image analysis86, 102770 (2023)
Wagner, M., Müller-Stich, B.P., Kisilenko, A., Tran, D., Heger, P., Mündermann, L., Lubotsky, D.M., Müller, B., Davitashvili, T., Capek, M., et al.: Comparative validation of machine learning algorithms for surgical workflow and skill analysis with the heichole benchmark. Medical image analysis86, 102770 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.