Towards Engineering Scaling Laws with Pretraining Data Composition
Pith reviewed 2026-06-26 15:31 UTC · model grok-4.3
The pith
Composing pretraining data with greater diversity and task alignment shifts neural scaling laws in jet classification toward needing more data rather than larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
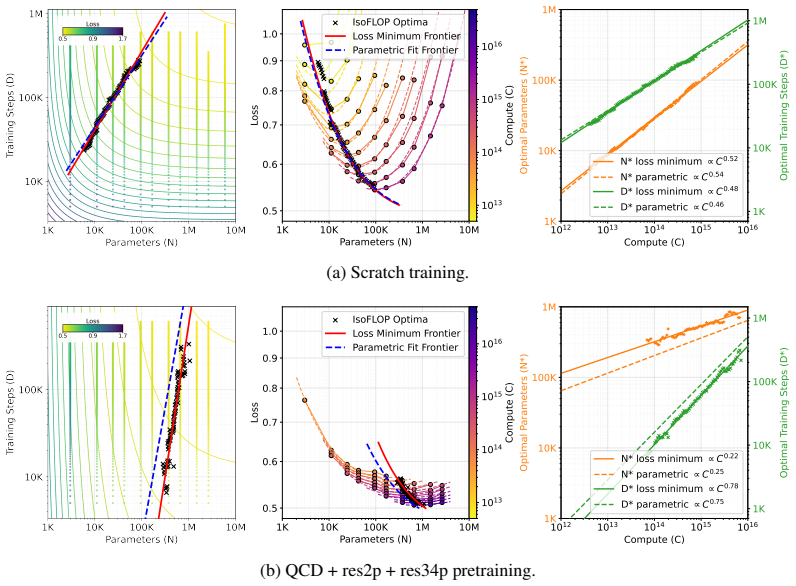
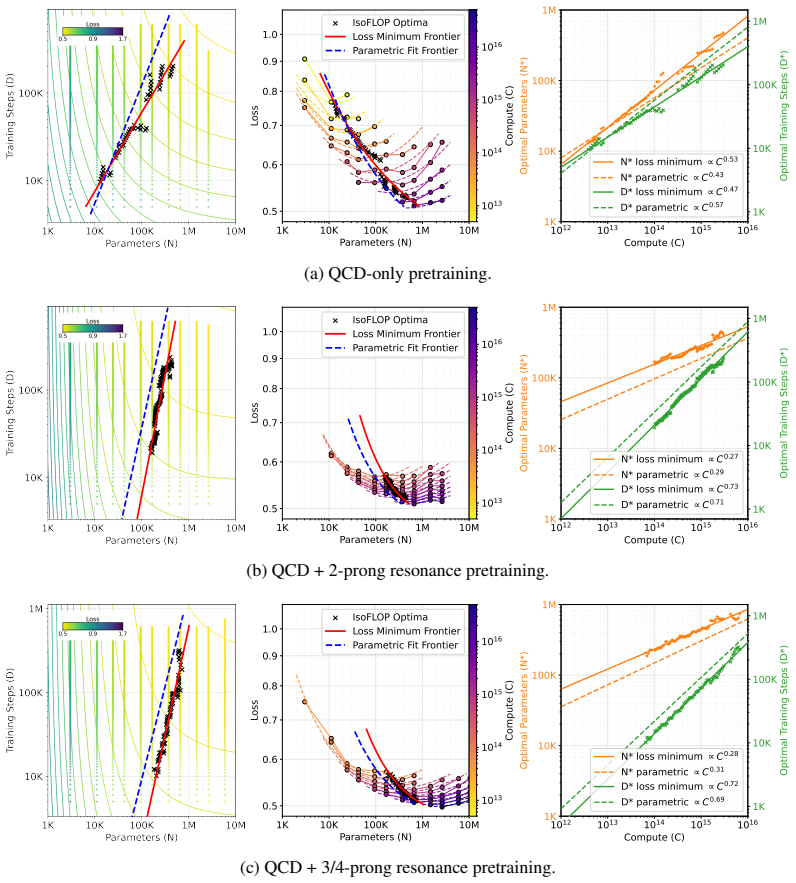
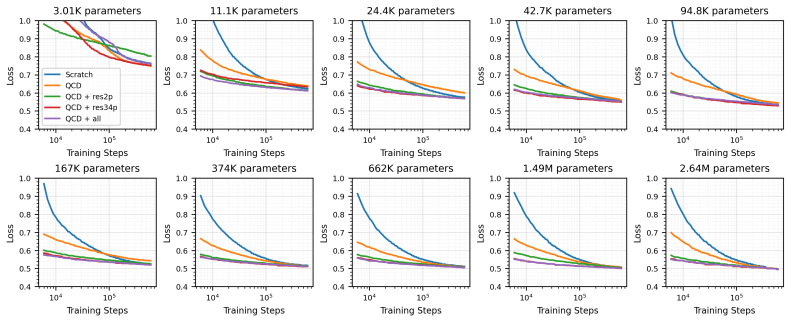
For the task of classifying hadronic jets produced in collisions of high-energy particle beams, the scaling behavior can be engineered towards requiring more data rather than larger models by inclusion of pretraining data which is more diverse and better aligned with the downstream classification task.
What carries the argument
Pretraining data composition, whose diversity and alignment with the downstream classification task modify the scaling exponents that relate performance to model size versus dataset size.
If this is right
- Jet classification performance can be improved by scaling dataset size rather than parameter count when pretraining data is chosen appropriately.
- High-fidelity simulators enable deliberate engineering of the pretraining set to control whether data or models dominate the scaling regime.
- The same power-law form persists, but the relative strength of the data-size and model-size terms becomes tunable through data selection.
- Resource allocation in physics machine learning can favor data generation over model enlargement under the right pretraining composition.
Where Pith is reading between the lines
- The same data-composition lever could be tested on other downstream tasks that also possess cheap synthetic data sources.
- If alignment proves decisive, then metrics for quantifying task alignment between pretraining and downstream sets would become useful design tools.
- Smaller models trained on carefully composed data might reach target accuracy at lower total compute than larger models trained on generic pretraining sets.
Load-bearing premise
Observed shifts in scaling exponents are produced by the diversity and alignment properties of the pretraining data rather than by differences in model architecture, training procedure, or downstream dataset construction.
What would settle it
Recompute the scaling exponents after swapping in pretraining datasets that hold diversity fixed while changing alignment (or vice versa) and observe whether the exponents stay the same.
Figures
read the original abstract
Neural scaling laws describe how model performance improves as a power law in compute, model size, and dataset size. While well-established for large language models, these relationships are emerging for large models in particle physics. As with language, empirical studies show that the performance scales as a power law. However, unlike natural language or image domains, fundamental physics has high-fidelity simulators that produce synthetic data cheaply. This favors scaling regimes where additional data is cheaper than additional parameters, and allows the pretraining dataset itself to be engineered to influence the scaling. For the task of classifying hadronic jets produced in collisions of high-energy particle beams, we show that the scaling behavior can be engineered towards requiring more data rather than larger models by inclusion of pretraining data which is more diverse and better aligned with the downstream classification task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines neural scaling laws for the task of classifying hadronic jets from high-energy particle collisions. It claims that the scaling behavior can be engineered to favor increases in dataset size over model size by composing the pretraining dataset from data that is more diverse and better aligned with the downstream classification task, taking advantage of inexpensive synthetic data generated by high-fidelity simulators.
Significance. If the central empirical result is shown to hold after isolating data-composition effects from other variables, the work would be significant for particle-physics applications of large models. It would demonstrate a practical route to shifting scaling exponents in a domain where data generation cost is low, thereby informing compute allocation decisions that differ from those in language or vision domains.
major comments (2)
- [Abstract] Abstract: the claim that scaling can be engineered 'towards requiring more data rather than larger models' by data diversity and alignment is presented without any reported scaling exponents, performance metrics, error bars, or quantitative comparison between regimes.
- The attribution of observed scaling shifts to pretraining-data properties requires that model architecture, optimizer, training schedule, tokenization, and downstream dataset construction remain fixed while only data composition is varied. No description of such controls appears in the manuscript, so the causal link between data properties and the reported change in scaling behavior cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that scaling can be engineered 'towards requiring more data rather than larger models' by data diversity and alignment is presented without any reported scaling exponents, performance metrics, error bars, or quantitative comparison between regimes.
Authors: The abstract is intended as a concise summary. Detailed scaling exponents, performance metrics with error bars, and quantitative comparisons across data-composition regimes are reported in the results section and associated figures. To address the concern, we will revise the abstract to include key scaling exponents and a brief quantitative comparison between regimes. revision: yes
-
Referee: The attribution of observed scaling shifts to pretraining-data properties requires that model architecture, optimizer, training schedule, tokenization, and downstream dataset construction remain fixed while only data composition is varied. No description of such controls appears in the manuscript, so the causal link between data properties and the reported change in scaling behavior cannot be assessed.
Authors: We agree that explicit documentation of controls is required to establish the causal attribution to data composition. In the experiments, model architecture, optimizer, training schedule, tokenization, and downstream dataset construction were held fixed while only pretraining data composition was varied. We will add a dedicated subsection in the methods describing these fixed controls to make the isolation of the data-composition variable explicit. revision: yes
Circularity Check
No circularity detected; empirical observation with no reduction to inputs or self-citations
full rationale
The paper presents an empirical study claiming that pretraining data composition (diversity and alignment) can shift scaling exponents to favor data over model size in jet classification. The abstract and provided text contain no equations, fitted parameters, or derivations that would make the claimed result equivalent to its inputs by construction. No self-citations are invoked as load-bearing premises, uniqueness theorems, or ansatzes. The central claim is framed as an experimental finding rather than a mathematical prediction or renamed known result, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[2]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2022
2022
-
[3]
Vinicius Mikuni and Benjamin Nachman. OmniLearn: A method to simultaneously facilitate all jet physics tasks.Physical Review D, 111:054015, 2025. doi: 10.1103/PhysRevD.111. 054015. 9
-
[4]
Wahid Bhimji, Chris Harris, Vinicius Mikuni, and Benjamin Nachman. OmniLearned: A foundation model framework for all tasks involving jet physics.Physical Review D, 113: 032020, 2026. doi: 10.1103/PhysRevD.113.032020
-
[5]
Joschka Birk, Anna Hallin, and Gregor Kasieczka. OmniJet-α: The first cross-task foundation model for particle physics.Machine Learning: Science and Technology, 5:035031, 2024. doi: 10.1088/2632-2153/ad66ad
-
[6]
Joshua Ho, Benjamin Ryan Roberts, Shuo Han, and Haichen Wang. Pretrained Event Classifi- cation Model for High Energy Physics Analysis.arXiv preprint arXiv:2412.10665, 12 2024
Pith/arXiv arXiv 2024
-
[7]
Congqiao Li, Antonios Agapitos, Jovin Drews, Javier Duarte, Dawei Fu, Leyun Gao, Raghav Kansal, Gregor Kasieczka, Louis Moureaux, Huilin Qu, Cristina Mantilla Suarez, and Qiang Li. Accelerating resonance searches via signature-oriented pre-training.arXiv preprint arXiv:2405.12972, 2024
arXiv 2024
-
[8]
Masked particle modeling on sets: towards self-supervised high energy physics foundation models.Mach
Tobias Golling, Lukas Heinrich, Michael Kagan, Samuel Klein, Matthew Leigh, Margarita Osadchy, and John Andrew Raine. Masked particle modeling on sets: towards self-supervised high energy physics foundation models.Mach. Learn. Sci. Tech., 5(3):035074, 2024. doi: 10.1088/2632-2153/ad64a8
-
[9]
Resimulation-based self-supervised learning for pretraining physics foundation models.Phys
Philip Harris, Jeffrey Krupa, Michael Kagan, Benedikt Maier, and Nathaniel Woodward. Resimulation-based self-supervised learning for pretraining physics foundation models.Phys. Rev. D, 111(3):032010, 2025. doi: 10.1103/PhysRevD.111.032010
-
[10]
Learning Symmetry-Independent Jet Representations via Jet-Based Joint Embedding Predic- tive Architecture
Subash Katel, Haoyang Li, Zihan Zhao, Farouk Mokhtar, Javier Duarte, and Raghav Kansal. Learning Symmetry-Independent Jet Representations via Jet-Based Joint Embedding Predic- tive Architecture. InPostponed: Machine Learning and the Physical Sciences: Workshop at NeurIPS 2024, 12 2024
2024
-
[11]
HEP- JEPA: A foundation model for collider physics using joint embedding predictive architecture
Jai Bardhan, Radhikesh Agrawal, Abhiram Tilak, Cyrin Neeraj, and Subhadip Mitra. HEP- JEPA: A foundation model for collider physics using joint embedding predictive architecture. arXiv preprint arXiv:2502.03933, 2 2025
arXiv 2025
-
[12]
Wildridge, Jack P
Andrew J. Wildridge, Jack P. Rodgers, Ethan M. Colbert, Yao yao, Andreas W. Jung, and Miaoyuan Liu. Bumblebee: Foundation Model for Particle Physics Discovery. InPostponed: Machine Learning and the Physical Sciences: Workshop at NeurIPS 2024, 12 2024
2024
-
[13]
Foundation models for high-energy physics.arXiv preprint arXiv:2509.21434, 2025
Anna Hallin. Foundation models for high-energy physics.arXiv preprint arXiv:2509.21434, 2025
arXiv 2025
-
[14]
FM4NPP: A scaling foundation model for nuclear and particle physics
David Park et al. FM4NPP: A scaling foundation model for nuclear and particle physics. In International Conference on Learning Representations (ICLR), 2026
2026
-
[15]
Solving key challenges in collider physics with foun- dation models.Phys
Vinicius Mikuni and Benjamin Nachman. Solving key challenges in collider physics with foun- dation models.Phys. Rev. D, 111(5):L051504, 2025. doi: 10.1103/PhysRevD.111.L051504
-
[16]
Liam Parker et al. AION-1: Omnimodal Foundation Model for Astronomical Sciences.arXiv preprint arXiv:2510.17960, 10 2025
arXiv 2025
-
[17]
Wells, Salman Habib, and John Wise
Bin Xia, Nesar Ramachandra, Azton I. Wells, Salman Habib, and John Wise. Multi-modal foundation model for cosmological simulation data, 2025. URLhttps://arxiv.org/abs/ 2510.07684
arXiv 2025
-
[18]
EveNet: A Foundation Model for Particle Collision Data Analysis
Ting-Hsiang Hsu et al. EveNet: A Foundation Model for Particle Collision Data Analysis. arXiv preprint arXiv:2601.17126, 1 2026
arXiv 2026
-
[19]
Particle trajectory representation learning with masked point modeling.Mach
Samuel Young, Yeon-jae Jwa, and Kazuhiro Terao. Particle trajectory representation learning with masked point modeling.Mach. Learn. Sci. Tech., 7(2):025023, 2026. doi: 10.1088/ 2632-2153/ae47b8
2026
-
[20]
Samuel Young and Kazuhiro Terao. Panda: Self-distillation of Reusable Sensor-level Repre- sentations for High Energy Physics.arXiv preprint arXiv:2512.01324, 12 2025. 10
arXiv 2025
-
[21]
Scaling laws in jet classification.SciPost Physics Core, 8: 034, 2025
Joshua Batson and Yonatan Kahn. Scaling laws in jet classification.SciPost Physics Core, 8: 034, 2025. doi: 10.21468/SciPostPhysCore.8.1.034
-
[22]
Neural scaling laws for boosted jet tagging.arXiv preprint arXiv:2602.15781, 2026
Matthias Vigl, Nicole Hartman, Michael Kagan, and Lukas Heinrich. Neural scaling laws for boosted jet tagging.arXiv preprint arXiv:2602.15781, 2026
arXiv 2026
-
[23]
Carpe Datum: Scaling behavior of transformers for heavy hadron flavor identification
ATLAS Collaboration. Carpe Datum: Scaling behavior of transformers for heavy hadron flavor identification. Technical report, CERN, Geneva, 2026. URLhttps:// cds.cern.ch/record/2953659. All figures including auxiliary figures are available at https://atlas.web.cern.ch/Atlas/GROUPS/PHYSICS/PUBNOTES/ATL-SOFT-PUB-2026-002
arXiv 2026
-
[24]
Scaling laws for amplitude surrogates.arXiv preprint arXiv:2601.13308, 2026
Henning Bahl, Victor Bres ´o-Pla, Anja Butter, and Joaquin Iturriza Ramirez. Scaling laws for amplitude surrogates.arXiv preprint arXiv:2601.13308, 2026
arXiv 2026
-
[25]
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Morcos. Beyond neural scaling laws: Beating power law scaling via data pruning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[26]
Particle transformer for jet tagging
Huilin Qu, Congqiao Li, and Sitian Qian. Particle transformer for jet tagging. InInternational Conference on Machine Learning (ICML), 2022
2022
-
[27]
Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kia- ninejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
Pith/arXiv arXiv 2017
-
[28]
A neural scaling law from the dimension of the data mani- fold.arXiv preprint arXiv:2004.10802, 2020
Utkarsh Sharma and Jared Kaplan. A neural scaling law from the dimension of the data mani- fold.arXiv preprint arXiv:2004.10802, 2020
arXiv 2004
-
[29]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27), 2024
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27), 2024. doi: 10.1073/pnas.2311878121
-
[30]
Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
Oz Amram, Darius A. Faroughy, Tjarko Gerdes, Anna Hallin, Gregor Kasieczka, Michael Kr¨amer, Humberto Reyes-Gonzalez, and David Shih. Neural Scaling Laws for Jet Generation. arXiv preprint arXiv:2605.28940, 5 2026
Pith/arXiv arXiv 2026
-
[32]
Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
Pith/arXiv arXiv 2021
-
[33]
Scaling laws for downstream task performance in machine translation
Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, and Sanmi Koyejo. Scaling laws for downstream task performance in machine translation. In International Conference on Learning Representations (ICLR), 2025
2025
-
[34]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[35]
Quasi-local photon surfaces in general spherically symmetric spacetimes.Eur
Andrew Chappell and Leigh H. Whitehead. Application of transfer learning to neu- trino interaction classification.Eur . Phys. J. C, 82(12):1099, 2022. doi: 10.1140/epjc/ s10052-022-11066-6
-
[36]
GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Pith/arXiv arXiv 2002
-
[37]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[38]
Transforming jet flavour tagging at ATLAS.Nature Commun., 17(1): 541, 2026
ATLAS Collaboration. Transforming jet flavour tagging at ATLAS.Nature Commun., 17(1): 541, 2026. doi: 10.1038/s41467-025-65059-6
-
[39]
BSMScaling: com- panion code for ”Towards Engineering Scaling Laws with Pretraining Data Composition”
Jan-Lucas Uslu, Kevin Greif, Daniel Whiteson, and Benjamin Nachman. BSMScaling: com- panion code for ”Towards Engineering Scaling Laws with Pretraining Data Composition”. https://github.com/Jaluus/BSMScaling, 2026. 11
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.