A Neuro-Symbolic Approach to Strategy Synthesis for Strategic Logics
Pith reviewed 2026-06-26 21:56 UTC · model grok-4.3
The pith
Large language models propose candidate strategies that a model checker certifies for multi-agent strategic logics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM can act as a strategy-generation oracle for bounded strategic reasoning in NatATL; candidate strategies it produces are accepted only when certified by a conventional MAS model checker, and this architecture yields 92 percent accuracy on a newly created dataset of 4211 instances while preserving formal soundness.
What carries the argument
The generate-and-certify architecture in which the LLM proposes candidate strategies that the model checker formally validates.
If this is right
- Formal soundness is retained because only strategies certified by the model checker are accepted.
- The approach reduces the computational cost of exploring large combinatorial strategy spaces in strategic logics.
- A dataset of 4211 NatATL instances is now available for training or evaluating strategy-synthesis methods.
- Open-weight models such as Qwen3-32B can be integrated directly into existing MAS model-checking tools.
Where Pith is reading between the lines
- The same generate-and-certify pattern could be tested on other strategic logics such as ATL or SL if suitable prompting is developed.
- Fine-tuning the LLM on verified strategy examples might further increase the fraction of correct candidates it produces.
- The method could be combined with existing heuristic search techniques inside model checkers to handle still larger state spaces.
Load-bearing premise
The language model produces a useful distribution of candidate strategies that the model checker can validate efficiently rather than requiring exhaustive search.
What would settle it
An experiment on a solvable NatATL instance in which the LLM never proposes any correct strategy, so the pipeline reports failure even though a winning strategy exists.
Figures
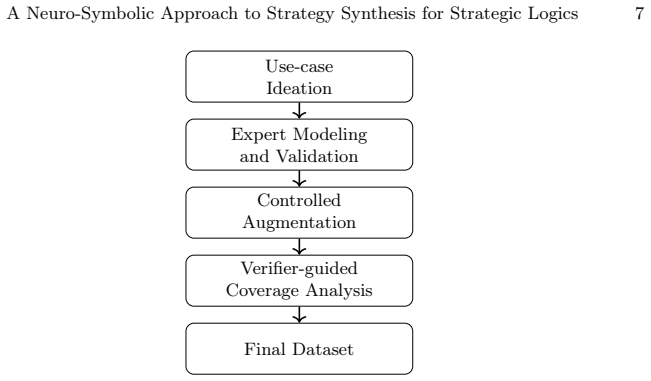
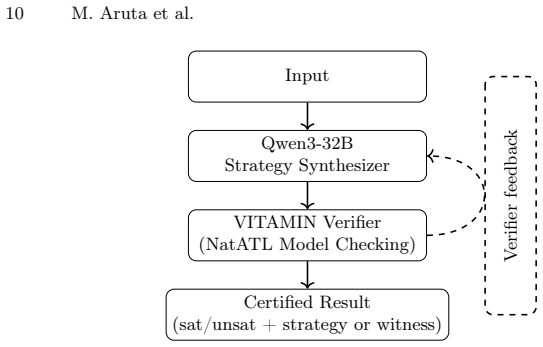
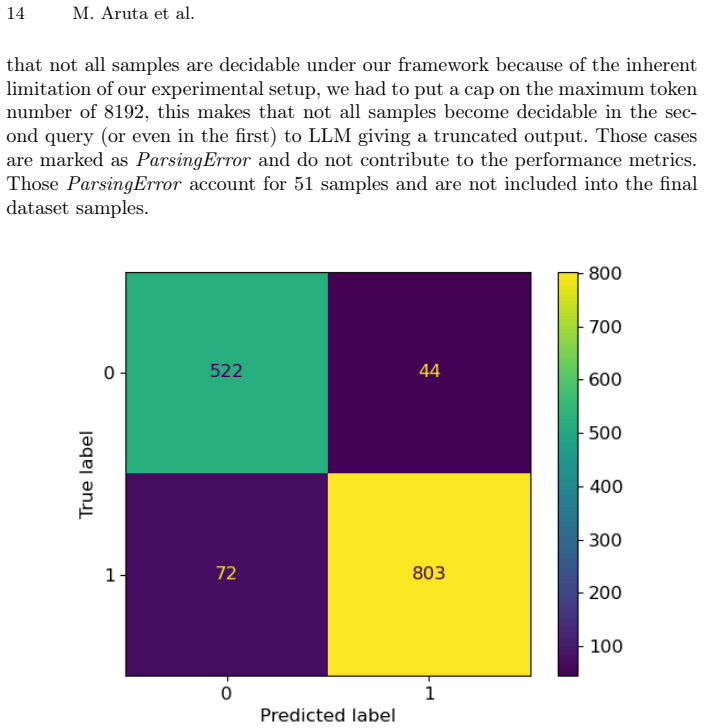
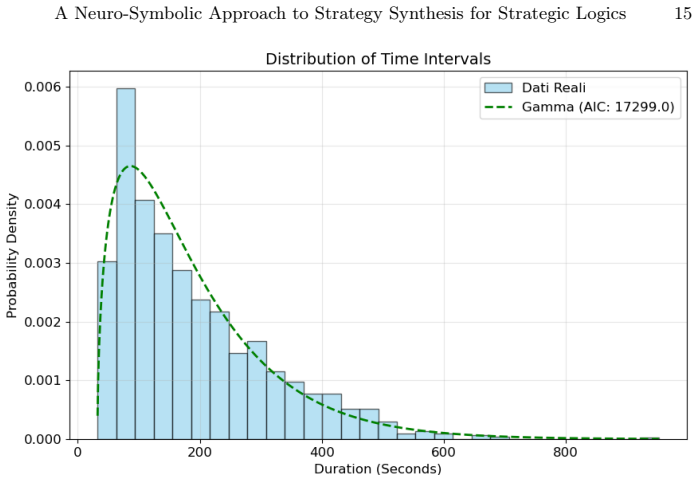
read the original abstract
Reasoning about what agents can achieve through strategic interaction is a core challenge in Multi-Agent Systems (MAS). Logics for strategic ability, such as ATL, provide rigorous methods, but their adoption is often hindered by the computational cost of strategy synthesis. We introduce a neuro-symbolic framework that integrates large language models (LLMs) into the model-checking pipeline for MAS. The LLM acts as a strategy-generation oracle, proposing candidate strategies that are then formally validated by a standard MAS model checker. This generate-and-certify architecture uses LLM guidance to navigate large combinatorial strategy spaces while preserving formal soundness: generated strategies are accepted only when certified by the verifier. We instantiate the framework for bounded strategic reasoning in NatATL and introduce the first NatATL strategy-synthesis dataset, consisting of 4211 instances. Experiments with an open-weight Qwen3-32B model show that our certified pipeline achieves 92\% accuracy on strategy-synthesis outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neuro-symbolic generate-and-certify framework for strategy synthesis in strategic logics such as NatATL. An LLM (Qwen3-32B) proposes candidate strategies that are formally validated by a standard MAS model checker; only certified strategies are accepted. The authors create the first NatATL strategy-synthesis dataset (4211 instances) and report that the pipeline achieves 92% accuracy on strategy-synthesis outcomes.
Significance. If the empirical result holds under a properly documented protocol, the work would demonstrate a practical way to scale strategy synthesis while preserving soundness. The release of the 4211-instance NatATL dataset is a concrete, reusable contribution that future work can build upon. The approach also illustrates how LLM guidance can be integrated into existing model checkers without compromising formal guarantees.
major comments (2)
- [Experimental evaluation] Experimental evaluation: the 92% accuracy figure is presented as evidence that the neuro-symbolic pipeline outperforms exhaustive enumeration, yet no ablation compares the Qwen3-32B proposal distribution against uniform random sampling or simple heuristics. Without this comparison it is impossible to determine whether the reported accuracy is attributable to the LLM or to properties of the 4211-instance dataset.
- [Dataset and experimental protocol] Dataset construction and evaluation protocol: the manuscript states that a new 4211-instance NatATL dataset was created and that accuracy was measured on strategy-synthesis outcomes, but supplies no description of how positive/negative instances were generated, how many LLM proposals are attempted per instance, or the precise success criterion used by the model checker. These details are load-bearing for interpreting the 92% claim.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a short paragraph clarifying the precise fragment of NatATL under consideration (e.g., bounded vs. unbounded strategic reasoning).
- [Framework description] Notation for the generate-and-certify loop (candidate generation, certification predicate, termination condition) should be introduced once in a single figure or algorithm box rather than scattered across prose.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional experimental comparisons and protocol details are needed to strengthen the presentation and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation: the 92% accuracy figure is presented as evidence that the neuro-symbolic pipeline outperforms exhaustive enumeration, yet no ablation compares the Qwen3-32B proposal distribution against uniform random sampling or simple heuristics. Without this comparison it is impossible to determine whether the reported accuracy is attributable to the LLM or to properties of the 4211-instance dataset.
Authors: The manuscript centers on the soundness of the generate-and-certify pipeline and the resulting accuracy, rather than claiming superiority over exhaustive search (which is infeasible for many instances). We nevertheless agree that an ablation is required to isolate the contribution of the LLM proposal distribution. In the revision we will add comparisons against uniform random sampling and simple heuristics. revision: yes
-
Referee: [Dataset and experimental protocol] Dataset construction and evaluation protocol: the manuscript states that a new 4211-instance NatATL dataset was created and that accuracy was measured on strategy-synthesis outcomes, but supplies no description of how positive/negative instances were generated, how many LLM proposals are attempted per instance, or the precise success criterion used by the model checker. These details are load-bearing for interpreting the 92% claim.
Authors: We agree that these details are essential for interpreting the results. The revised manuscript will contain a full description of how the 4211 instances (including positive and negative examples) were generated, the number of LLM proposals attempted per instance, and the precise success criterion applied by the model checker. revision: yes
Circularity Check
No circularity: empirical accuracy on newly created dataset
full rationale
The central claim is an empirical measurement of 92% accuracy on the 4211-instance NatATL dataset using a generate-and-certify pipeline. This result is obtained by running the LLM proposer plus model checker on held-out instances and counting certified outcomes; it does not reduce by definition or fitting to any input parameter, self-citation, or ansatz inside the paper. The architecture description and dataset creation are independent of the reported accuracy number.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The standard MAS model checker is sound for bounded strategic reasoning in NatATL
Reference graph
Works this paper leans on
-
[1]
Synthese 149(2), 375–407 (2006)
Ågotnes, T.: Action and knowledge in alternating-time temporal logic. Synthese 149(2), 375–407 (2006)
2006
-
[2]
In: AAMAS 2010
Alechina, N., Logan, B., Nga, N.H., Rakib, A.: Resource-bounded alternating-time temporal logic. In: AAMAS 2010. p. 481–488. IFAAMAS (2010)
2010
-
[3]
Jour- nal of the ACM (JACM)49(5), 672–713 (2002)
Alur, R., Henzinger, T.A., Kupferman, O.: Alternating-time temporal logic. Jour- nal of the ACM (JACM)49(5), 672–713 (2002)
2002
-
[4]
In: KR 2021
Aminof, B., Giacomo, G.D., Lomuscio, A., Murano, A., Rubin, S.: Synthesizing best-effort strategies under multiple environment specifications. In: KR 2021. pp. 42–51 (2021)
2021
-
[5]
Anonymous:Sourcecodeforreproducibilty.https://figshare.com/s/6234b3d6607b22f2fce5 (1 2026)
2026
-
[6]
arXiv preprint arXiv:2512.20457 (2025)
Aruta, M., Improta, F., Malvone, V., Murano, A.: When natural strategies meet fuzziness and resource-bounded actions (extended version). arXiv preprint arXiv:2512.20457 (2025)
arXiv 2025
-
[7]
arXiv preprint arXiv:2410.14374 (2024)
Aruta, M., Malvone, V., Murano, A.: A model checker for natural strategic ability. arXiv preprint arXiv:2410.14374 (2024)
arXiv 2024
-
[8]
Aruta, M., Malvone, V., Murano, A.: S4h: A tool for synthesizing human-like strategies (2025)
2025
-
[9]
arXiv preprint arXiv:2108.07732 (2021)
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.: Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021)
Pith/arXiv arXiv 2021
-
[10]
arXiv preprint arXiv:2201.09616 (2022)
Belardinelli,F.,Jamroga,W.,Malvone,V.,Mittelmann,M.,Murano,A.,Perrussel, L.: Reasoning about human-friendly strategies in repeated keyword auctions. arXiv preprint arXiv:2201.09616 (2022)
arXiv 2022
-
[11]
In: AAMAS 2024
Belardinelli, F., Jamroga, W., Mittelmann, M., Murano, A.: Verification of stochas- tic multi-agent systems with forgetful strategies. In: AAMAS 2024. pp. 160–169. IFAAMAS/ ACM (2024)
2024
-
[12]
In: AAAI 2024
Berthon, R., Katoen, J.P., Mittelmann, M., Murano, A.: Natural strategic ability in stochastic multi-agent systems. In: AAAI 2024. vol. 38, pp. 17308–17316 (2024)
2024
-
[13]
In: AAMAS 2017
Berthon, R., Maubert, B., Murano, A.: Decidability results for ATL* with imper- fect information and perfect recall. In: AAMAS 2017. pp. 1250–1258. ACM (2017)
2017
-
[14]
In: Specification and Verification of Multi-Agent Systems, pp
Bulling, N., Dix, J., Jamroga, W.: Model checking logics of strategic ability: Com- plexity. In: Specification and Verification of Multi-Agent Systems, pp. 125–159. Springer (2010)
2010
-
[15]
Autonomous Agents and Multi-Agent Systems36(1), 2 (2022)
Bulling, N., Goranko, V.: Combining quantitative and qualitative reasoning in con- current multi-player games. Autonomous Agents and Multi-Agent Systems36(1), 2 (2022)
2022
-
[16]
In: PRIMA 2024
Catta, D., Ferrando, A., Malvone, V.: Resource action-based bounded ATL: A new logic for MAS to express a cost over the actions. In: PRIMA 2024. pp. 206–223. LNCS 15395, Springer (2024)
2024
-
[17]
In: AAMAS
Catta, D., Leneutre, J., Malvone, V., Murano, A.: Obstruction alternating-time temporal logic: A strategic logic to reason about dynamic models. In: AAMAS
-
[18]
271–280 (2024) 18 M
pp. 271–280 (2024) 18 M. Aruta et al
2024
-
[19]
In: CAV 2014
Cermák, P., Lomuscio, A., Mogavero, F., Murano, A.: MCMAS-SLK: A model checker for the verification of strategy logic specifications. In: CAV 2014. pp. 525–
2014
-
[20]
LNCS 8559, Springer (2014)
2014
-
[21]
In: AAAI 2015
Cermák, P., Lomuscio, A., Murano, A.: Verifying and synthesising multi-agent systems against one-goal strategy logic specifications. In: AAAI 2015. pp. 2038–
2015
-
[22]
Information and Computation208(6), 677–693 (2010)
Chatterjee, K., Henzinger, T.A., Piterman, N.: Strategy logic. Information and Computation208(6), 677–693 (2010)
2010
-
[23]
In: TACAS 2013
Chen, T., Forejt, V., Kwiatkowska, M.Z., Parker, D., Simaitis, A.: Prism-games: A model checker for stochastic multi-player games. In: TACAS 2013. pp. 185–191. LNCS 7795, Springer (2013)
2013
-
[24]
In: FSKD 2007
Chen, T., Lu, J.: Probabilistic alternating-time temporal logic and model checking algorithm. In: FSKD 2007. pp. 35–39. IEEE Computer Society (2007)
2007
-
[25]
arXiv preprint arXiv:1102.4225 (2011)
Dima, C., Tiplea, F.L.: Model-checking atl under imperfect information and perfect recall semantics is undecidable. arXiv preprint arXiv:1102.4225 (2011)
Pith/arXiv arXiv 2011
-
[26]
In: PRIMA 2024
Ferrando, A., Luongo, G., Malvone, V., Murano, A.: Theory and practice of quan- titative ATL. In: PRIMA 2024. pp. 231–247. LNCS 15395, Springer (2024)
2024
-
[27]
In: AAMAS 2025
Ferrando, A., Malvone, V.: VITAMIN: verification of A multi agent system. In: AAMAS 2025. pp. 3023–3025. IFAAMAS (2025)
2025
-
[28]
In: ATVA 2018
Gutierrez, J., Najib, M., Perelli, G., Wooldridge, M.J.: EVE: A tool for temporal equilibrium analysis. In: ATVA 2018. pp. 551–557. LNCS 11138, Springer (2018)
2018
-
[29]
In: FOR- MATS 2006
Henzinger, T.A., Prabhu, V.S.: Timed alternating-time temporal logic. In: FOR- MATS 2006. pp. 1–17. LNCS 4202, Springer (2006)
2006
-
[30]
Artificial intelligence164(1-2), 81–119 (2005)
van der Hoek, W., Wooldridge, M.: On the logic of cooperation and propositional control. Artificial intelligence164(1-2), 81–119 (2005)
2005
-
[31]
Foundations of Artificial Intelligence3, 887–928 (2008)
Van der Hoek, W., Wooldridge, M.: Multi-agent systems. Foundations of Artificial Intelligence3, 887–928 (2008)
2008
-
[32]
In: AAAI 2014
Huang, X., van der Meyden, R.: Symbolic model checking epistemic strategy logic. In: AAAI 2014. pp. 1426–1432. AAAI Press (2014)
2014
-
[33]
In: PRIMA
Jamroga, W.: A temporal logic for stochastic multi-agent systems. In: PRIMA
-
[34]
pp. 239–250. LNCS 5357, Springer (2008)
2008
-
[35]
Jamroga, W., Konikowska, B., Kurpiewski, D., Penczek, W.: Multi-valued verifi- cation of strategic ability. Fundam. Informaticae175(1-4), 207–251 (2020)
2020
-
[36]
In: STAST 2020
Jamroga, W., Kurpiewski, D., Malvone, V.: Natural strategic abilities in voting protocols. In: STAST 2020. pp. 45–62. LNCS 12812, Springer (2020)
2020
-
[37]
In: AAMAS 2025
Jamroga, W., Kwiatkowska, M., Penczek, W., Petrucci, L., Sidoruk, T.: Proba- bilistic timed ATL. In: AAMAS 2025. pp. 1051–1059. IFAAMAS / ACM (2025)
2025
-
[38]
Jamroga, W., Malvone, V., Murano, A.: Natural strategic ability. Ar- tif. Intell.277(2019). https://doi.org/10.1016/J.ARTINT.2019.103170, https://doi.org/10.1016/j.artint.2019.103170
-
[39]
In: AAMAS 2019
Jamroga, W., Malvone, V., Murano, A.: Natural strategic ability under imperfect information. In: AAMAS 2019. pp. 962–970. IFAAMAS (2019)
2019
-
[40]
In: IJCAI 2025
Kaminski, M., Kurpiewski, D., Jamroga, W.: Natstv: Towards verification of nat- ural strategic ability. In: IJCAI 2025. pp. 16–22 (2025)
2025
-
[41]
In: AAMAS 2021
Kurpiewski, D., Pazderski, W., Jamroga, W., Kim, Y.: Stv+reductions: Towards practical verification of strategic ability using model reductions. In: AAMAS 2021. pp. 1770–1772. ACM (2021)
2021
-
[42]
Science378(6624), 1092–1097 (2022) A Neuro-Symbolic Approach to Strategy Synthesis for Strategic Logics 19
Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al.: Competition-level code generation with alphacode. Science378(6624), 1092–1097 (2022) A Neuro-Symbolic Approach to Strategy Synthesis for Strategic Logics 19
2022
-
[43]
Advances in Neural Information Pro- cessing Systems37, 23488–23515 (2024)
Li, Z., Zhou, Z., Yao, Y., Zhang, X., Li, Y.F., Cao, C., Yang, F., Ma, X.: Neuro- symbolic data generation for math reasoning. Advances in Neural Information Pro- cessing Systems37, 23488–23515 (2024)
2024
-
[44]
arXiv preprint arXiv:2502.09100 (2025)
Liu, H., Fu, Z., Ding, M., Ning, R., Zhang, C., Liu, X., Zhang, Y.: Logical reasoning in large language models: A survey. arXiv preprint arXiv:2502.09100 (2025)
arXiv 2025
-
[45]
Lomuscio, A., Qu, H., Raimondi, F.: MCMAS: an open-source model checker for the verification of multi-agent systems. Int. J. Softw. Tools Technol. Transf.19(1), 9–30 (2017)
2017
-
[46]
ACM Trans
Mogavero, F., Murano, A., Perelli, G., Vardi, M.Y.: Reasoning about strategies: On the model-checking problem. ACM Trans. Comput. Log.15(4), 34:1–34:47 (2014)
2014
-
[47]
In: EMNLP 2023
Pan, L., Albalak, A., Wang, X., Wang, W.: Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. In: EMNLP 2023. pp. 3806–3824 (2023)
2023
-
[48]
Advances in Neural Information Processing Systems36, 8634–8652 (2023)
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36, 8634–8652 (2023)
2023
-
[49]
Cambridge University Press (2008)
Shoham, Y., Leyton-Brown, K.: Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press (2008)
2008
-
[50]
In: ACL 2025
Tantakoun, M., Muise, C., Zhu, X.: Llms as planning formalizers: A survey for leveraging large language models to construct automated planning models. In: ACL 2025. pp. 25167–25188 (2025)
2025
-
[51]
John wiley & sons (2009)
Wooldridge, M.: An introduction to multiagent systems. John wiley & sons (2009)
2009
-
[52]
In: ICLR 2024
Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q.V., Zhou, D., Chen, X.: Large language models as optimizers. In: ICLR 2024. OpenReview.net (2024)
2024
-
[53]
In: ICLR 2023
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models. In: ICLR 2023. OpenRe- view.net (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.